在完成了機房收費系統數據庫需求分析、ER圖、關系模型的階段之後,就該根據關系模型來設計數據庫了,下面是我對這個階段的一個總結。
這次的關系模型有用戶、學生、卡、基本數據、電腦、賬單、工作記錄、充值、退卡、上機共10個,要由這10個關系模型來設計數據庫表,其中對於電腦(電腦名 系統時間 系統日期)這個關系,沒有必要單獨拿出來設計,其他的幾個都需要轉換成數據表,在確定了哪些關系模型需要轉換為關系表之後,就需要分析的數據表字段的明確以及數據表三范式的規范的確定。
(一)數據表中的每個字段不能有多個值或者不能有重復的屬性,符合原子性。
(二)要求實體的屬性完全依賴於主關鍵字。所謂完全依賴是指不能存在僅依賴主關鍵字一部分的屬性。
(三)在1NF基礎上,任何非主屬性不依賴於其它非主屬性[在2NF基礎上消除傳遞依賴]。
分析一張舊的數據表:

像這張表OnLine_Info,主鍵CardNo,其他字段有:cardtype,studentname,Department,sex等,而這些信息完全是和Student_Info中的內容重復,So,完全可以通過主外鍵將兩張表關聯起來,這樣這些重復的字段就不必要在不同的表裡重復出現了。
再看一張表Studetn_Info:
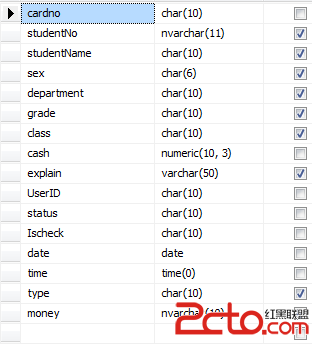
當時的表名是Student_Info,可認真分析之後發現這完全就是學生信息和卡的信息的疊加,道理上一卡對應一個人,但是當修改或刪除卡信息時,學生信息也有被修改的風險,同時由於這張表包含了太多的信息,導致查詢學生信息需要這張表、查詢卡信息需要這張表、結賬算錢需要這張表,查看是否結賬等也需要這張表,嚴重違背面向對象思想中“單一職責”原則,所以這次的設計必須改掉這些不足。
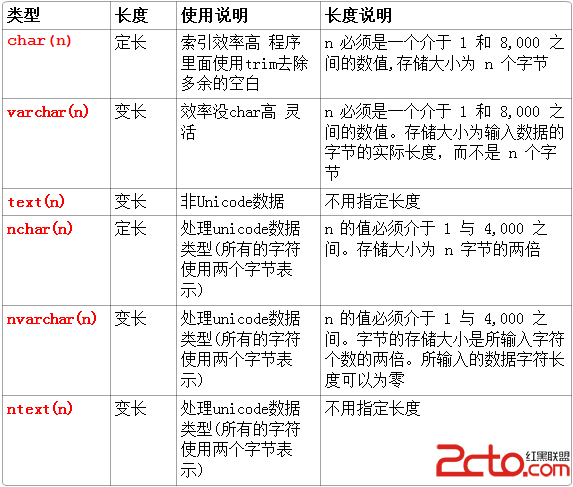
這是在查閱資料後在OneNote裡做的圖,總而言之,如果是Unicode數據類型(即含有中文或者中文英文結合)則選擇varchar或者nvarchar,如果需要變長,則選擇nchar或者nvarchar.比如當我們在登錄窗體的時候用戶名用char(10)定義之後,需要在代碼中用Trim(UserID)來傳入數據庫,為了是避免空格,當然這樣要求用戶名中不能含有空格,但是在密碼這個字段中,可能會涉及到空格,這裡就不建議使用nchar,最好使用char(n)。
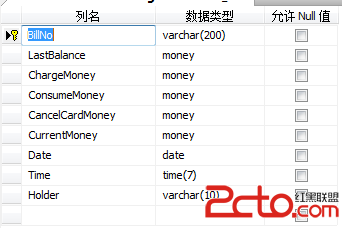
其次,這次的所有涉及到金錢類型的字段全部用到了money類型來表示,只要在代碼中用decimal(m,n)的數據類型來對應就OK了。
數據庫名稱:Restructurecharge
一共9張表:
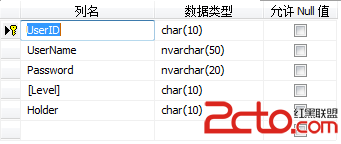
(1)User_Info
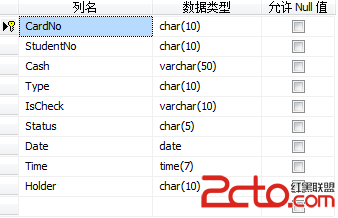
(2)Card_Info
(3)Student_Info
(4)Recharge_Info
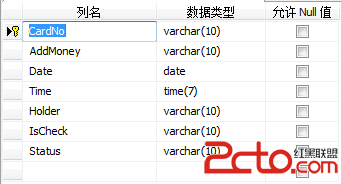
(5)Online_Info
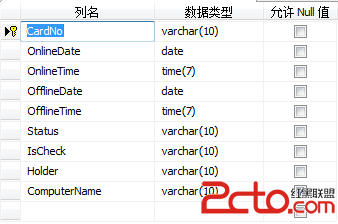
(6)LogoffCard_Info
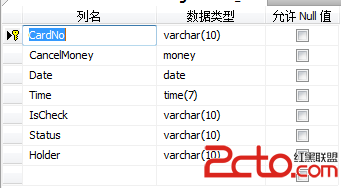
(7)Worklog_Info
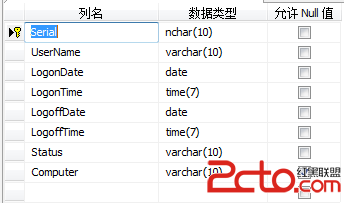
(8)BasicDate_Info
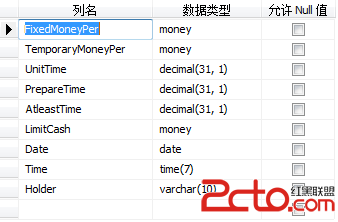
(9)Bill_Info