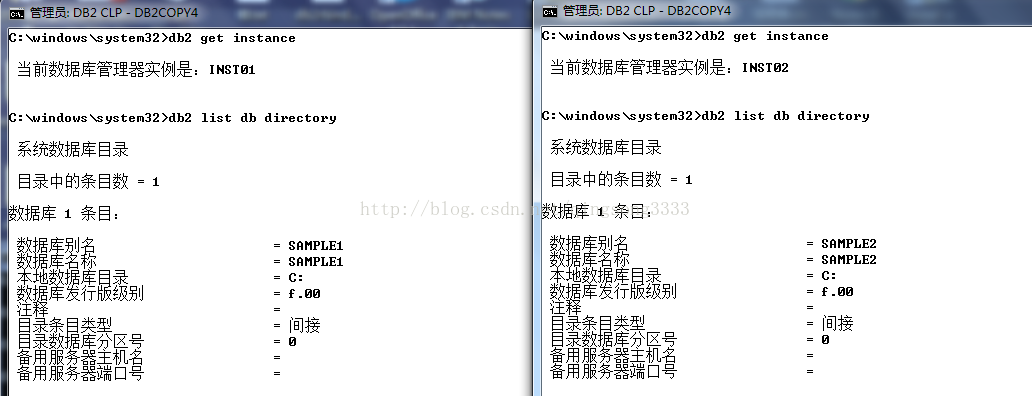
我們今天主要向大家描述的是關於Linux下的DB2數據庫CODESET,如果你對Linux下的DB2數據庫CODESET相關的實際操作有興趣的話,你就可以對以下的文章點擊觀看了,以下就是具體方案的描述,希望在你今後的學習中會有所幫助。
1.VARCHAR長度是指的是字節數,
DB的CODESET是UTF8時,漢字,假名包括小寫假名,是占3個字節的,ASCII字符集裡的字符占1個字節
DB的CODESET是IBM-943時,漢字和大寫假名是2個字節,小寫假名及ASCII字符集裡的字符占1個字節
2.linux下,DB2數據庫-tvf xx.sql 及 import 命令
不會對文件中的多字節字符做編碼轉換,若文件的編碼與數據庫的codeset不一致是,將會是亂碼
但是在windows的命令行下執行以上命令時,會自動將文件的編碼轉換為數據庫對應的編碼
文件編碼為UTF8,數據庫為UTF8,是LANG設成ja_JP.UTF8時,正常! (TTerm的送受信也為UTF8)
3.SJIS與JIS
JIS不支持漢字?
4.從ftp客戶端及telnet客戶端新建全角文件名文件時,將使用指定的送受信編碼
也只有指定了正確的送受信編碼時,才能正常顯示全角文件名
5.java客戶端程序能根據數據庫的編碼,正確識別字符型數據
6.終端的文字編碼與LANG環境變量,以及數據庫所使用的編碼。
終端的文字編碼控制顯示文字時的編碼,以及送受信時使用的編碼
LANG環境變量被系統及應用程序讀取,指定語言環境以及內存中所使用的文字編碼
數據庫所使用的編碼,保存字符型數據時所使用的編碼,包括CHARACTER,VARCHAR等
讀取文件列表時,當文件名所使用的編碼與LANG環境變量不兼容時,文件名將被轉換成問號(?)。
文件名所使用的編碼與終端的文字編碼不一致時,文件列表會顯示成亂碼
以上的相關內容就是對關於Linux下DB2數據庫CODESET2009-07-10 10:301.VARCHAR長度是指的是字節數的介紹,望你能有所收獲。