在所有 SQL 語句基估計過程中,以 JOIN 語句的計算過程最復雜,而 JOIN 語句恰恰是進行性能優化的重點。本文主要關注的是 DB2 優化器在進行基估計時采用的相關計算方法、輸入等。
簡介
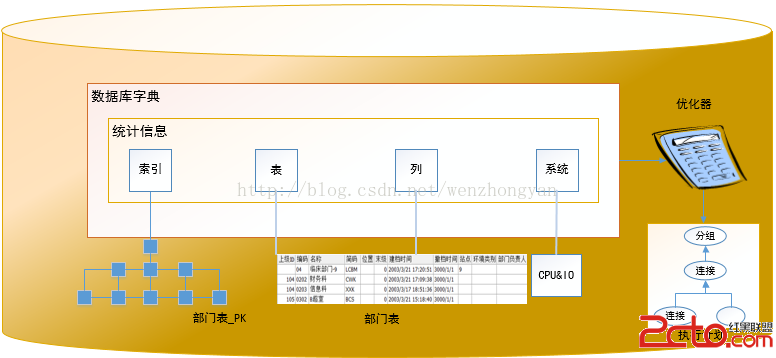
優化器是 DB2 的心髒和靈魂(可以把它類比成寶馬 730 或波音 747 的發動機引擎一樣)。它分析 SQL 語句並確定可以滿足每條語句的最有效的存取路徑。 DB2 SQL 優化器可以估計每個備選訪問計劃的執行成本,並根據其估計結果選擇一個最佳訪問計劃。
在優化器在優化一個 SQL 語句的過程中使用到兩個非常重要的概念:selectivity 和 cardinality 。 selectivity 是指一個 SQL 操作的得出結果集占原來結果集的百分比,而 cardinality 就是指一個 SQL 操作的得出結果集的行數。
為正確地確定每種訪問計劃的成本,DB2 優化器都會對每個步驟產生的結果集大小即返回的行數進行估計,這就是優化器的基估計。 DB2 優化器需要准確的基數估計值。基數估計是這樣一種過程:在應用了謂詞或執行了聚集之後,優化器使用統計信息確定部分查詢結果的大小。對於訪問計劃的每個操作符,優化器將估計該操作符的基數輸出。一個或更多謂詞的應用可以減少輸出流基數。
JOIN 謂詞
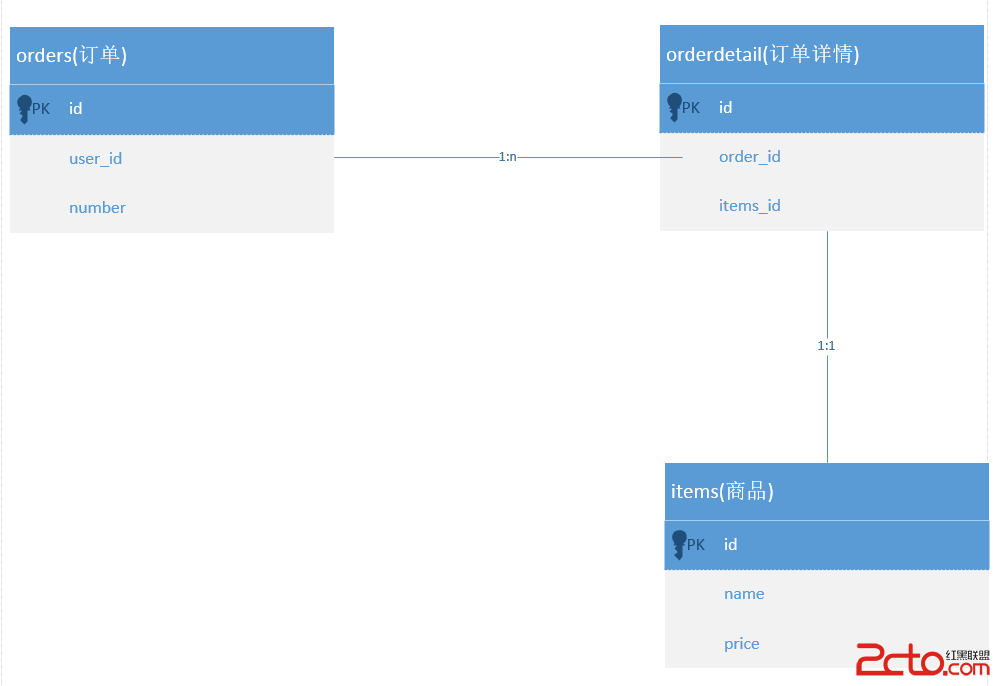
當我們在 SQL 裡面需要對多個表進行 join 的時候,DB2 會首先選擇其中的 2 個表進行 join,並獲取到一個中間的結果集,然後 DB2 可能會用這個中間的結果集和第三個表做 join,再次獲得中間的結果集(當然也可能是把另外 2 個表做 join,然後把兩個中間的結果集進行 join 操作),不管是怎麼操作,DB2 一次能夠 join 的表的個數肯定是兩個。因此當優化器在考慮 Join 如何處理的時候,join 的順序就是一個很重要的問題,因為我們總是希望能夠在最開始就把結果集控制的盡量小。
一個 JOIN 謂詞一般描述如下所示:
- T1.joincol=T2.joincol
在實際應用過程中,Where 子句中除 JOIN 謂詞外,一般都還有本地謂詞,形式如下:
- T1.joincol=T2.joincol and T1.filter=literal_1 and T2.filter=literal_2
謂詞 T1.filter=literal_1 用於對 T1 表進行過來,T2.filter=literal_2 用於多 T2 表進行過濾,然後兩個經過過濾的表進行 JOIN 操作。至於 JOIN 采用 hash join 還是 Merge Join 或者 NestLoop Join 取決於 DB2 的優化級別、參數設置以及成本估計。
DB2 Join 謂詞選擇性計算公式如下:
- Selectivity (T1.y = T2.y)= 1/max(colcard(T1. joincol), colcard(T2. joincol))
其中,colcard(T1. joincol) 指 T1 表 joincol 列的不同值的個數,colcard(T2. joincol) 指 T2 表 joincol 列的不同值的個數,兩者取較大的一個作為 Join 謂詞計算依據。此公式存在兩個假設:
包含性,即 T2. joincol 的所有取值都在 T1 joincol 取值范圍內,反之也行。
均衡性,即兩個連接列上的數據分布均勻。
DB2 優化器中針對 JOIN 語句的結果集估計
作者: 駱洪青, 出處:IT專家網論壇, 責任編輯: 陳子琪, 2009-06-24 07:00
DB2 優化器在為 SQL 語句生成執行計劃時,都會對每個步驟產生的結果集大小進行估計,這就是DB2 優化器的基估計。在所有 SQL 語句基估計過程中,以 JOIN 語句的計算過程最復雜,而 JOIN 語句恰恰是進行性能優化的重點。
DB2 Join 謂詞基估計計算公式如下:
- Join Cardinality =Join Selectivity *
- filtered cardinality(t1) *
- filtered cardinality(t2)
其中 filtered cardinality(t1) 是在 T1 表上應用本地謂詞後獲得結果集,filtered cardinality(t2) 是在 T2 表上應用本地謂詞後獲得結果集。
示例