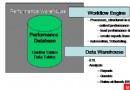
DB2數據庫性能理解的主要誤區:
邏輯設計應該總是能和物理設計完全映射
實際:DB2數據庫設計中物理設計應該盡可能的和邏輯結構相近,但是為性能做出的物理設計改變不能被忽略,因為它們並不來自於邏輯設計。
將所有東西放在一個緩沖池(BP0)中讓DB2管理
實際:就像在DB2手冊和其他地方說明的一樣,你只能在你的內存非常受限的情況下(10000 4k pages或者更少),你沒有時間去管理它,你也沒有考慮到性能的條件下,去這樣做。最好這樣說:不要放置除了DB2 catalog和目錄以外的東西進入BP0。
DSNDB07是100%順序的
實際:DSNDB07從來就不是100%順序的,因為有工作文件中的對頁面進行的隨機活動。隨即活動可能高達45%,但是通常范圍是3%到10%。
VARCHAR應該總是被放置在行末
實際:這就是總是引發問題的話。如果表總是被讀,並且非常少的更新,那麼可以,這將會減少CPU負載,但是在其它情況下這樣做就是最壞的,甚至如果表是被壓縮的。只有在頻繁更新的情況下它應該被放置在末尾,但是並不通常這樣。
程序應該以遵循邏輯過程的方式編碼
實際:偽代碼或者一個邏輯過程圖並不需要考慮性能相關的編碼方式。在OLTP交易代碼中這非常具有戲劇性。
大多數過程不在SQL中進行
實際:事實上,問題的反面往往是正確的。SQL是一個非常豐富的語言,能夠處理大多數過程。實際上最大的困難是SQL經常被用來作為I/O處理器而不是一個集合處理器。
代碼和引用表應該和DB2聲明的referential integrity(RI)一起使用
實際:RI不應該作為一個編輯有效性的快捷方式而使用,這通常屬於別的什麼,但是應該在真父子關系中使用。
表至多有一到兩個索引
實際:表應該按照性能需求擁有多個索引。
非分割索引(NPI)不應該被使用,尤其是不應該在大的表中使用
實際:這關系到數不清的問題,總體上這些都能被克服,但是NPI是對適當的訪問和性能非常必要的。
大表應該被分割
實際:因為一個表中有太多數據就意味著有性能下降,這是一個遺留的擔心。當一些表中有超過60億行數據時,這個理解已經被消除了。