一般來說在連接數較少情況下,db2 的性能會比較穩定。因為這時連接的應用所產生的請求比 db2 代理池中所能產生的協調代理少,這時基本上能夠滿足每一個請求都能夠被及時的協調代理所響應處理。 在連接集中器激活(MAX_CONNECTIONS > MAX_COORDAGENTS)的情況下,如果連接數超過了協調代理,這時連接所過來的請求就會進入隊列等候協調代理服務,並發的連接數提高了,但是某些連接的性能就會顯著下降。此時應當考慮激活分區間並行 (SMP) 或多分區(MPP)特性來增加 I/O 的並行性以及多個 CPU 的並行運算。
案例分析
查詢優化案例
接下來這裡從一個試驗來看一下 DML 操作過程中優化的詳細步驟和具體數據。首先看一個查詢優化的例子,下面是試驗中的建表語句:
- CREATE TABLE MCLAIM.T1_DMS (
- C11 VARCHAR (10) NOT NULL ,
- C12 VARCHAR (15) NOT NULL ,
- C13 VARCHAR (20) NOT NULL ,
- CONSTRAINT C11_PK PRIMARY KEY ( C11) ) IN DMS_Space;
- CREATE TABLE MCLAIM.T2_DMS (
- C21 VARCHAR (15) NOT NULL ,
- C22 VARCHAR (25) NOT NULL ,
- C23 VARCHAR (30) NOT NULL ,
- CONSTRAINT C21_PK PRIMARY KEY ( C21) ) IN DMS_Space;
- CREATE TABLE MCLAIM.T3_DMS (
- C31 VARCHAR (10) NOT NULL ,
- C32 VARCHAR (25) NOT NULL ,
- C33 VARCHAR (35) NOT NULL ,
- CONSTRAINT C31_PK PRIMARY KEY ( C31) ) IN DMS_Space;
最初的環境沒有優化,表空間類型 SMS 表空間,查詢的表中沒有索引,sortheap 過小等等。在這種情況下執行下列查詢語句:
- select C12 from TESTOPT.T1_SMS,%SCHEMA%.T2_SMS,%SCHEMA%.T3_SMS
- where substr(C12,1,10)=substr(C21,1,10) and C22=C32
- order by C12 asc
在沒有優化的情況下得到的總的執行時間是 653 秒,而經過優化後得到總的執行時間是大概是 15 秒左右。在優化中采用了如下優化步驟:
選擇 DMS 表空間。
添加索引:
- CREATE UNIQUE INDEX INDEX_C12 on T1_DMS (C12 ASC);
- CREATE UNIQUE INDEX INDEX_C22 on T2_DMS (C22 ASC);
- CREATE UNIQUE INDEX INDEX_C32 on T2 _DMS (C32 ASC);
增大 sortheap 的大小
執行 runstats
選擇適當的優化級別
改進表結構,增加冗余字段。以空間換時間:
- ALTER TABLE T1 ADD C12_Red VARCHAR(10);
- ALTER TABLE T2 ADD C21_Red VARCHAR(10);
- UPDATE T1 SET C12_Red=SUBSTR(C12,1,10);
- UPDATE T2 SET C21_Red=SUBSTR(C21,1,10);
查詢語句變成:
- select C12 from TESTOPT.T1_DMS, TESTOPT.T2_DMS, TESTOPT.T3_DMS
- where C12_Red=C21_Red and C22=C32 order by C12 asc
圖 1. 查詢操作優化示意圖
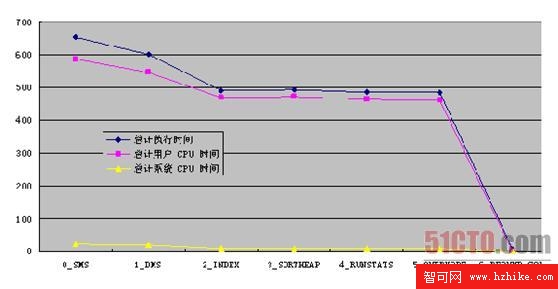
從圖中可以看出選擇好的表空間類型 ( 數據庫管理表空間 ) 和添加索引會對性能有很大的改善作用。而添加冗余字段對性能的改進作用最大。當然這會涉及表結構的變化,是需要在數據庫設計階段考慮的因素。同時代價是增加磁盤的占用空間。
寫入操作優化
接下來是一個寫操作的例子(插入)。下面是試驗的腳本:
- CONNECT TO FFTEST;
- CREATE SCHEMA TESTOPT;
- DROP TABLE TESTOPT.T3;
- CREATE TABLE TESTOPT.T3 (
- C31 VARCHAR (10) NOT NULL ,
- C32 VARCHAR (15) NOT NULL ,
- CONSTRAINT C31_A CHECK ( C31 LIKE 'A%' or C31 LIKE 'a%'));
- CREATE INDEX TESTOPT.INDEX_C31 on TESTOPT.T3 (C31 ASC);
- ALTER TABLE TESTOPT.T3 ADD CONSTRAINT C31_A CHECK (substr(C31,1,1)= ’ a ’
- or substr(C31,1,1)= ’ A ’ )
- ALTER TABLE TESTOPT.T3 APPEND OFF;
- CONNECT RESET;
最初的表沒有優化,含有索引,約束等因素,插入 4 萬條記錄大約花了 68 秒鐘,而最終優化後插入 4 萬條記錄只需 6 秒鐘。如下是優化步驟:
圖 2. 插入操作優化示意圖
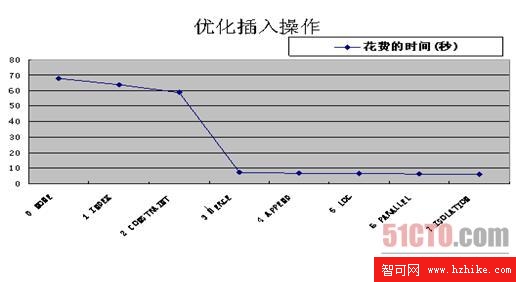
從圖中可以看出減少索引和約束可以大幅度提高插入性能,而將多條插入語句合並成一行產生的效果更加明顯。
性能調優注意事項
為了得到高性能將緩沖池調得過大,導致數據庫連不上。這對沒有經驗的用戶來說可能是個災難,這意味著數據庫可能要重建。最初我們曾經犯過這樣的錯誤。現在可以通過調節 DB2 注冊參數 DB2_OVERRIDE_BPF 來設置緩沖池的大小,從而能夠再次連接數據庫。當然最好將 STMM 激活,使內存能夠自動調整。
往往忽視 runstats 和 reorg 的作用,我們發現不止一個的性能問題,都是由於優化器選擇了錯誤的 Access plan 導致系統整體性能下降。而對外顯示的則不光是 SQL 執行慢,同時也能會表現出 I/O 瓶頸或系統響應時間長。這往往會誤導我們去分析其他地方。但究其根源,很多時間是由於優化器的錯誤。這些問題往往在重新執行 runstats 和 reorg 之後就解決了。所以這兩個命令也要特別注意。
在進行數據加載的時候往往忽略了索引因素,導致性能加載性能下降。我們遇到過這樣的一個例子,一張表導入 1000 條記錄花了 5 分鐘,檢查了很多配置找不到原因,最後發現這張表上有 1 個主鍵,還有 4 個外鍵。將他們刪除後重新導入只花了幾秒鐘。所以在進行 load 或者是 insert 的時候盡量將主外鍵或相關索引刪除,加載完成後重建相關索引。主外鍵盡量通過加載程序來保證它的數據完整性。這一點往往會被忽略,所以在加載數據前先檢查一下所有表的索引狀態及引用關系。
在修改 db2 參數的時候,一次最好修改一個參數,然後看看效果,在調節其他參數。否則一次多個參數,調好了也沒弄清楚是哪個參數起的作用。下次還得全部來一遍。還要注意,並非所有參數都是越大越好,有時可能會適得其反。
注意索引的試用,優化好的索引對查詢語句性能的提高往往會產生數十倍的性能改進。所以,調優前可以先察看一下相關語句的索引利用情況。這可以通過察看 SQL 語句和執行計劃,看一下已有索引是否被利用起來了或是否需要建立新的索引。這往往比 DB2 系統調優更重要。但切記考慮插入操作,索引也會降低插入的性能。這一點要綜合考慮。
由於 XML 數據可以跨頁存儲,在設計 XML 數據庫時要盡可能的使用較大的數據頁,這樣可以避免 XML 數據跨頁查詢,以提高查詢性能。
采用表分區:有這樣一個例子:客戶有一張表的數據量非常大,每天都會產生大約 30 萬條記錄,同時每天都會刪除五天前的記錄,所以此表大概有 150 萬條記錄,現在客戶在每天的第一次查詢時要重新對表進行索引(因為晚上會產生很多數據,所以新增加的數據都沒有建索引),導致響應非常慢!對於這種問題,後來采用了表分區,用 6 個分區表來分別裝載原來 6 天的數據。所以查詢和插入都只涉及一張表,所以響應速度得到大幅度提高。
了解 CHNGPGS_THRESH 參數,是緩沖池寫日志的閥值。有一個例子,在創建索引時比較慢,經過檢查發現 CHNGPGS_THRESH 參數過大,造成每次寫日志的時候數據量過大,造成 I/O 瓶頸,適當減小這個參數值,可以增加寫日志的次數,但數減少每次寫日志的數據量,這對於大緩沖池裡的大表上創建索引時很有效的。
在導入數據時盡量采用 load, 少用 import, 我們做過統計,用 import 花費 10 分鐘的數據,用 load 大概只需要 1 分鐘,這大大提高了工作效率。
注意 db2diag.log 的大小,當這個文件很大的時候,數據庫的所有操作,包括停啟 db2 都會特別的慢,有時甚至掛起。所以要經常看看這個文件的大小,過大時最好刪掉,重啟 db2 。當然 DIAGLEVEL 不要設得太高,除非為了診斷某個問題獲得更多信息,一般默認的 3 足夠了。