DB2中所謂的數據移動,包括: 1. 數據的導入(Import) 2. 數據的導出(Export) 3. 數據的裝入(Load)。導入和裝入都是利用DB2的相關命令把某種格式的文件中的數據保存到數據庫中的表中;導出是指把DB2數據庫的表中的數據保存到某種格式的文件當中去。
數據移動的作用:
如果要在不同的數據庫管理系統之間轉移數據,數據移動通常是最實用的一種方法,因為任何一種數據庫管理系統都支持常用的幾種文件格式,通過這個通用的接口,就很容易實現不同系統間數據的轉移。 本篇文章發表於www.xker.com(小新技術網)
這三個命令中,Export最簡單,因為從表中向文件轉移數據,通常不會出現錯誤,也不會有非法的數據。
在講解命令之前,首先介紹一下文件的格式,用於DB2數據移動的文件格式有四種:
1. ASC——非定界ASCII文件,是一個ASCII字符流。數據流中的行由行定界符分隔,而行中的每一列則通過起始和結束位置來定義。例如:
10 Head Office 160 Corporate New York
15 New England 50 Eastern Boston
20 Mid Atlantic 10 Eastern Washington
38 South Atlantic 30 Eastern Atlanta
42 Great Lakes 100 Midwest Chicago
51 Plains 140 Midwest Dallas
66 Pacific 270 Western San Francisco
84 Mountain 290 Western Denver
2. DEL——定界ASCII文件,也是一個ASCII字符流。數據流中的行由行定界符分隔,行中的列值由列定界符分隔。文件類型修飾符可用於修改這些定界符的默認值。例如:
10,"Head Office",160,"Corporate","New York"
15,"New England",50,"Eastern","Boston"
20,"Mid Atlantic",10,"Eastern","Washington"
38,"South Atlantic",30,"Eastern","Atlanta"
42,"Great Lakes",100,"Midwest","Chicago"
51,"Plains",140,"Midwest","Dallas"
66,"Pacific",270,"Western","San Francisco"
84,"Mountain",290,"Western","Denver"
3. WSF——(work sheet format)為工作表格式,用於與Lotus系列的軟件進行數據交換。
4. PC/IXF——是集成交換格式(Integration Exchange Format,IXF)數據交換體系結構的改編版本,由一些列可變長度的記錄構成,包括頭記錄、表記錄、表中每列的列描述符記錄以及表中每行的一條或多條數據記錄。PC/IXF 文件記錄由包含了字符數據的字段組成。
數據的導出(Export)
例一:把Org表中的所有數據導出到文件C:\ORG.TXT中。
Export to c:\org.txt of del select * from org
其中,of del表示導出到的文件的類型,在本例中導出到一個非定界文本文件中;後面的select * from org是一個SQL語句,該語句查詢出來的結果就是要導出的數據。
例二:改變del格式文件的格式控制符
export to c:\staff.txt of del modifIEd by coldel$ chardel'' decplusblank select * from staff
在該例中,modifIEd子句用於控制各種符號,coldel表示字段之間的間隔符,默認情況為逗號,現在改為$號;chardel表示字符串字段用什麼符號引用,默認情況下為一對雙引號括起來,現在改為用一對單引號括起來;decplusblank表示對於十進制數據類型,用空格代替最前面的加號,因為默認情況下會在十進制數據前面加上正負號的。
例三:以ASC格式將數據導出到文件
Export命令是不支持ASC格式文件的,所以如果想導出ASC這樣規整的格式,需要程序員自己進行轉換操作,思路是將各種數據類型都轉換成定長字符串,然後把各個要導出的字段合並成為一個字段。
例如創建如下結構的表n:
create table n(a int,b date,c time,d varchar(5),e char(4),f double)
然後插入兩條數據:
insert into n values(15,'2004-10-21','23:12:23','abc','hh',35.2)
insert into n values(5,'2004-1-21','3:12:23','bc','hhh',35.672)
要想把這兩條數據以規整的格式導出到文件中,進行如下操作:
export to c:\test.txt of del select char(a) || char(b) || char(c) || char(d,5) || e || char(f) as tmp from n
這樣導出的結果與ASC格式的文件非常類似,只是每一行的前後多出了一對雙引號,對此我們可以使用文本工具(如寫字板、記事本等)把雙引號刪除掉,也可以置之不理,在以後導入的時候直接控制格式(忽略雙引號)
在文件中的格式為:
"15 2004-10-2123.12.23abc hh 3.52E1 "
"5 2004-01-2103.12.23bc hhh 3.5672E1 "
例四:大數據的導出
export to d:\myfile.del of del lobs to d:\lob\ lobfile lobs modifIEd by lobsinfile select * from emp_photo
該命令把emp_photo表的數據導出到d:\myfile.del文件中,其結果為:
<pre>
"000130","bitmap","lobs.001.0.43690/"
"000130","gif","lobs.001.43690.29540/"
"000130","xwd","lobs.001.73230.45800/"
"000140","bitmap","lobs.001.119030.71798/"
"000140","gif","lobs.001.190828.29143/"
"000140","xwd","lobs.001.219971.73908/"
"000150","bitmap","lobs.001.293879.73438/"
"000150","gif","lobs.001.367317.39795/"
"000150","xwd","lobs.001.407112.75547/"
"000190","bitmap","lobs.001.482659.63542/"
"000190","gif","lobs.001.546201.36088/"
"000190","xwd","lobs.001.582289.65650/"
</pre>
其中第三個字段是BLOB類型,在該文件中只保存了一個標志,相當於一個指針,真正的LOB數據保存在d:\lob目錄下的lobs.001、lobs.002、......等一系列文件中。命令中lobs to 後面指定大對象數據保存在什麼路徑下(注意,該路徑必須事先已經存在,否則會報錯),lobfile 後面指定大對象數據保存在什麼文件中,不要指定擴展名,DB2會根據數據量自動追加.001、.002等擴展名,同時不要忘記加上modifIEd by lobsinfile子句。
例五:把導出信息保存在消息文件中。
export to d:\awards.ixf of ixf messages d:\msgs.txt select * from staff where dept = 20
這個例子把staff表中dept=20的數據導出到d:\awards.ixf文件中,所有的導出信息都保存在d:\msgs.txt文件中(無論是成功、警告還是失敗信息),這樣,管理員可以通過觀察信息文件找到問題所在。
例六:給導出數據列重命名。
export to d:\awards.ixf of ixf method n(c1,c2,c3,c4,c5,c6,c7) messages d:\msgs.txt select * from staff where dept=20
在默認情況下,導出的每一列數據以表中對應的字段名自動命名,我們可以通過method n子句給每一列重新命名,需要注意的是,這個子句只在ixf和wsf格式文件中有效,在文本文件中不能使用。
數據的導入
例七:把C盤根目錄下的org.txt文件中的數據導入到org表中
import from c:org.txt of del insert into org
導入命令和導出命令的格式基本上處於對應的關系,import對應export,from對應to,文件名和文件格式代表的含義相同,但是導入命令支持ASC格式的文件,而導出命令不支持。另外,在導出命令的最後是一個SQL語句,用於選擇要導出的數據,而導入命令最後不是SQL語句,而是插入數據的方式以及目標表名稱。
例八:從ASC格式文件中導入數據
import from c:org2.txt of asc method l(1 5,6 19,20 25,26 37,38 50) insert into org
其中 method l 子句用於指定文本文件中每一個字段的起始位置和終止位置,每個起始位置和終止位置間用空格分開,字段之間用逗號分開。 除了l方法之外,還有n方法和p方法,下面會敘述。
例九:利用n方法導入數據,並且創建新表。
首先導出一個用例文件:
export to d:org.ixf of ixf method n(a,b,c,d,e) select * from org
這樣org.ixf文件中有五列數據,對應的列名分別為a、b、c、d、e
然後在從該文件中導入數據到一個新表中
import from d:org.ixf of ixf method n(d,e,b) replace_create into orgtest
該命令從文件中選取三列導入到表中,順序可以不按照文件中原有的列的順序。replace_create方式的敘述見下。
插入方式有:
INSERT 方式——在表中現有數據的基礎之上追加新的數據。本篇文章發表於www.xker.com(小新技術網)
INSERT_UPDATE 方式——這種方式只能用於有主鍵的表,如果插入的數據與原有數據主鍵不沖突,則直接插入,如果主鍵沖突,則用新的數據代替原有數據。
REPLACE 方式——先把表中現有的數據都刪除,然後向空表中插入數據。
REPLACE_CREATE 方式——表示如果表存在,則先把表中的數據都刪除,然後向空表中插入數據;如果表不存在,則先根據文件中的字段創建表,然後再向表中插入數據。這種方式只能把IXF格式的文件中的數據插入到表中。
例十:利用p方法導入數據
import from d:org.ixf of ixf method p(4,5,2) replace into orgtest
該例子執行的效果和例九類似,只是把n方法換成了p方法,p方法後面的列表中指明列的序號即可,不需要指明列名。另外,此例中使用了replace方式插入數據,這會把表中現有的數據都刪除,然後向空表中插入數據。
例十一:關於空值的導入
對於ixf格式的文件,導入空值非常方便,因為裡面已經記錄了空值的信息。但是,對於ASC格式文件就有一定的難度了,因為DB2會直接插入空格,而不是空值。為此,DB2提供了一個子句進行控制:NULL INDICATORS
import from c:org2.txt of asc MODIFIED BY nullindchar=# method l(1 5,6 19,20 25,26 37,38 50) NULL INDICATORS(0,0,0,0,38 ) replace into org
在這個例子中,NULL INDICATORS子句後面是一個列表,表示前面四個字段都不會存在空值,而第五個字段從38列開始,可能存在空值,而 MODIFIED BY nullindchar=# 子句表示在文件中第五個字段如果遇到 # 號,則表示為空值。
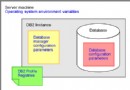
裝入(Load)
裝入命令格式與導入類似,命令關鍵字是Load,但是後面的參數比導入命令多的多,詳細用法可以自行參考DB2文檔。
裝入與導入類似,都是將輸入文件中的數據移入到目標表中,二者的不同點將在實例中逐步解釋。
在裝入之前,目標表必須已經存在。裝入的性能比導入高,原因在後面結合實例詳細解釋。裝入操作不記錄到日志中,所以不能使用日志文件進行前滾操作。
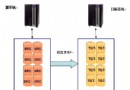
裝入分為4個階段:
1. 裝入階段
在這個階段發生兩件事:數據存儲在表中,收集索引鍵並排序。在裝入時,DBA可以指定多長時間生成一致點。它是裝入工具的檢查點。如果裝入在執行期間被打斷,它可以從最後一個一致點處開始繼續重新執行。
2. 構建階段
在構建階段,基於在裝入階段收集的索引鍵信息創建索引。如果在構建階段發生錯誤,裝入工具就重啟,它將從構建階段開始處重新開始構建。
3. 在刪除階段,所有違反唯一或主鍵約束的行都被刪除並拷貝到一個異常表(如果在語句中指定相應選項)中。當輸入行被拒絕,消息文件中就生成消息。
4. 索引拷貝階段
如果在裝入操作期間為索引創建指定了系統臨時表空間,並且選擇了 READ Access 選項,該索引數據將從系統臨時表空間拷貝到原來的表空間。
裝入過程的所有四個階段都是操作的一部分,只有在所有的四個階段都完成之後,該裝入操作才算完成。在每個階段都將生成消息,一旦其中的某個階段發生錯誤,這些消息可以幫助DBA分析並解決問題。
導入操作每次插入一行數據時都要檢查是否滿足約束條件,並且記入日志文件中。
下面我們看一些LOAD命令特有的功能,IMPORT命令也能做的就不再詳細說了。
例十二:從光標類型文件中進行裝入
定義一個cursor
declare mycur cursor for select * from org
創建一個新表,結構與cursor相容
create table org2 like org
從cursor中裝入
load from mycur of cursor insert into org2
除了可以從cursor中裝入,還可以從文件、管道、設備中進行裝入。而導入命令只能從文件中導入。
例十三:關於異常表
由用戶定義的異常表可以用於存儲不遵循唯一約束和主碼約束的行。如果裝入的時候沒有指定異常表,則違反唯一約束的行將被丟棄並且將不再有機會恢復或修改。
用SAMPLE數據庫中的STAFF表做實驗
1. 創建一個結構與STAFF表相同的表STAFF1
CREATE TABLE STAFF1 LIKE STAFF
2. 把STAFF表中的一部分數據插入到STAFF1中
INSERT INTO STAFF1 SELECT * FROM STAFF WHERE ID<=160
3. 再創建一個結構與STAFF1相同的表STAFFEXP,作為異常表
CREATE TABLE STAFFEXP LIKE STAFF1
4. 給該異常表添加一列,因為異常表和普通表相比,前面的結構都相同,就是最後多出一列或兩列(列名任意),第一列是時間戳類型,記錄異常記錄插入的時間,第二列是大文本類型(至少為32K大小),保存導致該條記錄被拒絕的特定約束信息。本例中只添加一個時間戳列。
ALTER TABLE STAFFEXP ADD COLUMN TIME TIMESTAMP
5. 為STAFF1表創建一個唯一索引
CREATE UNIQUE INDEX IDXSTAFF ON STAFF1(ID)
6. 先運行導出命令做出一個文本文件
EXPORT TO D:STAFF.TXT OF DEL SELECT * FROM STAFF
7. 然後運行裝入命令把數據再裝入到STAFF1表中
LOAD FROM D:STAFF.TXT OF DEL INSERT INTO STAFF1 FOR EXCEPTION STAFFEXP
由於表STAFF1中有唯一索引,所以會有一部分數據因為違反這個約束條件而不能插入到STAFF1表中,這些記錄就會插入到異常表STAFFEXP中。
注意一點,異常表必須自己先定義好,裝入命令不能夠自動生成異常表,如果找不到指定的異常表,就會報錯。
例十四:關於DUMP文件
格式不正確的行會被拒絕。通過指定DUMPFILE文件類型修飾符可以使這些被拒絕的記錄單獨放在指定的文件裡。
用SAMPLE數據庫中的STAFF表做實驗
1. 創建一個結構與STAFF表相同的表STAFF1
CREATE TABLE STAFF1 LIKE STAFF
2. 把STAFF表中的一部分數據插入到STAFF1中
INSERT INTO STAFF1 SELECT * FROM STAFF WHERE ID<=160
3. 再創建一個結構與STAFF1相同的表STAFFEXP,作為異常表
CREATE TABLE STAFFEXP LIKE STAFF1
4. 給該異常表添加一列
ALTER TABLE STAFFEXP ADD COLUMN TIME TIMESTAMP
5. 為STAFF1表創建一個唯一索引
CREATE UNIQUE INDEX IDXSTAFF ON STAFF1(ID)
6. 先運行導出命令做出一個文本文件
EXPORT TO D:STAFF.TXT OF DEL SELECT * FROM STAFF
到D盤上打開STAFF.TXT文件,把第一列等於320的行替換為:"abcf","aaa","sdfg"
7. 然後運行裝入命令把數據再裝入到STAFF1表中
LOAD FROM D:STAFF.TXT OF DEL MODIFIED BY DUMPFILE=d:dump INSERT INTO STAFF1 FOR EXCEPTION STAFFEXP
裝入的結果報告中會有如下一條:
SQL3118W 在行 "32" 列 "1" 中的字段值不能轉換為 SMALLINT 值,但是目標列不可為空。未裝入該行。
SQL3185W 當處理輸入文件的第 "32" 行中的數據時發生先前的錯誤。
打開D盤的dump.000文件,會看到造成異常的那一行數據:"abcf","aaa","sdfg"
通過這個例子,我們可以理解,如果一行數據的格式不正確,在裝入的時候會遭到拒絕,該行記錄會放到DUMP文件中;而如果數據格式正確,但是不滿足表的約束條件,該行記錄會放到異常表中。
例十五:限制裝入行數
用ROWCOUNT選項可以指定從文件開始處裝入的記錄數
LOAD FROM D:STAFF.TXT OF DEL ROWCOUNT 3 INSERT INTO STAFF1
例十六:出現警告信息時強令裝入操作失敗
在某些情況下,文件中的數據必須全部成功輸入到目標表中才算成功,即使有一條記錄出錯也不行。在這種情況下,可以使用WARNINGCOUNT選項。
到D盤上打開STAFF.TXT文件,把第一列等於320的行替換為:"abcf","aaa","sdfg"
LOAD FROM D:STAFF.TXT OF DEL WARNINGCOUNT 1 INSERT INTO STAFF1
運行結果包含下面的警告:
SQL3118W 在行 "32" 列 "1" 中的字段值不能轉換為 SMALLINT值,但是目標列不可為空。未裝入該行。
SQL3185W 當處理輸入文件的第 "32" 行中的數據時發生先前的錯誤。
SQL3502N 實用程序遇到了 "1" 個警告,它超過了允許的最大警告數。
此時無法對表STAFF1進行操作,例如
SELECT * FROM STAFF1
會返回:
ID NAME DEPT JOB YEARS SALARY COMM
------ --------- ------ ----- ------ --------- ---------
SQL0668N 由於表 "USER.STAFF1" 上的原因代碼 "3",所以不允許操作。
SQLSTATE=57016
原因是:表處於“裝入掛起”狀態。對此表的先前的 LOAD 嘗試失敗。在重新啟動或終止 LOAD 操作之前不允許對表進行存取。
解決方法為:通過分別發出帶有 RESTART 或 TERMINATER 選項的 LOAD 來重新啟動或終止先前失敗的對此表的 LOAD 操作。
包含TERMINATER的LOAD命令可以終止裝入進程,使目標表恢復正常可用狀態:
LOAD FROM D:STAFF.TXT OF DEL TERMINATE INTO STAFF1
包含RESTART的LOAD命令可以在源文件修改正確的時候使用,使裝入進程重新開始:
LOAD FROM D:STAFF.TXT OF DEL RESTART INTO STAFF1
例十七:防止產生警告信息
使用NOROWWARNINGS文件類型修飾符可以禁止產生警告信息,當裝入過程可能出現大量警告信息,而用戶對此又不感興趣的時候,可以使用該選項,這樣可以大大提高裝入的效率
到D盤上打開STAFF.TXT文件,把第一列等於320的行替換為:"abcf","aaa","sdfg"
LOAD FROM D:STAFF.TXT OF DEL MODIFIED BY NOROWWARNINGS INSERT INTO STAFF1
運行完的結果中,第32行出錯,該行無法裝入,但是不產生警告信息。
例十八:生成統計數據
使用STATISTICS選項可以在裝入的過程中生成統計數據,這些統計數據可以供優化器確定最有效的執行SQL語句的方式。
可以對表和索引產生不同詳細程度的統計數據:
① 對表和索引產生最詳細的統計數據:
LOAD FROM D:STAFF.TXT OF DEL REPLACE INTO STAFF1 STATISTICS YES WITH DISTRIBUTION AND DETAILED INDEXES ALL
② 對表和索引都產生簡略的統計:
LOAD FROM D:STAFF.TXT OF DEL REPLACE INTO STAFF1 STATISTICS YES AND INDEXES ALL
其它組合可以參考DB2文檔。
注意:STATISTICS選項只能和REPLACE兼容,與INSERT選項不兼容。另外,通過STATISTICS選項做完統計,我們看不到任何直接的結果,如果想查看其結果,需要到系統表中自己查詢。
例十九:解除檢查掛起狀態
1. 連接到SAMPLE數據庫上:
Connect to sample
2. 創建一個結構與staff表相同的表:
CREATE TABLE STAFF1 LIKE STAFF
3. 給該表添加一個檢查約束:
alter table staff1 add constraint chk check(dept<100)
4. 到D盤上打開STAFF.TXT文件,把最後一行數據的第三列改為150,這樣該條數據就不滿足第3步加上的檢查約
束條件了,然後用Load命令從文件中裝入數據到staff1表中:
LOAD FROM D:STAFF.TXT OF DEL INSERT INTO STAFF1
5. 此時運行查詢命令:
Select * from staff1
會得到錯誤信息:
SQL0668N 由於表 "USER.STAFF1" 上的原因代碼 "1",所以不允許操作。
SQLSTATE=57016
原因是裝入時有數據違反了檢查約束,造成表處於檢查掛起狀態。
6. 解除表的檢查掛起狀態,使用:
set integrity for staff1 check immediate unchecked
再次運行查詢命令:
Select * from staff1
發現表可以正常使用了,其中的違反檢查規則的數據也存在。
例二十:性能因素
在從文件向表導入數據的時候,當數據量特別大的情況下,裝入命令會明顯體現出優勢,原因是它不像導入命令每次插入一行,並且在每行都要檢查是否滿足約束條件,裝入命令從輸入文件讀出數據構建頁,把這些頁直接寫入數據庫,並且在每一行數據裝入時不判斷是否滿足約束,另外裝入命令不寫日志,所有這些因素都導致裝入的效率高於導入。
另外,裝入命令還有一些選項可以控制性能因素:
1. COPY YES/NO和Nonrecoverable
① Nonrecoverable(不可恢復的):指定裝入操作不可恢復,並且不能由後續的前滾操作恢復。前滾操作忽略事務並且標記正在裝入數據的表為“無效”。
② Copy No(默認選項):在這種情況下,如果表所在數據庫的歸檔日志處於啟用狀態,則裝入完成後,表所在的表空間將處於備份掛起狀態,直到數據庫或表空間備份完畢,該表空間才成為可寫表空間。原因是裝入操作造成的變化沒有被記錄,所以要恢復裝入操作完成後發生的故障,備份數據庫或表空間是必要的。
③ Copy Yes:在這種情況下,如果數據庫的歸檔日志啟用,裝入操作的改變將被保存到磁帶、目錄或TSM服務器,並且表空間將不再處於備份掛起狀態。
2. Fastparse
該文件類型修飾符用於減少數據檢查次數。它只能用於在數據已知正確的情況下,尤其適用於DEL和ASC類型的文件。
3. Anyorder
如果SAVECOUNT選項沒有使用,該參數允許不遵照輸入文件中的數據順序進行裝入,在SMP(對稱多處理機)系統上CPU_PARALLELISM選項大於1的時候,該參數會提高裝入的性能。 Data Buffer
該參數用於指定從堆棧分配得到的4K大小的內存頁面。