IBM 的新一代數據庫 DB2 9中第一次實現了關系型引擎與層次型引擎的結合,實現了混合數據庫。IBM將此技術稱為pureXML技術。
關系型數據庫很早就已經開始考慮對XML的支持,但傳統的技術一般還是基於關系型數據庫的基本框架,用表之間的關系去模擬XML的層次結構.僅僅是對關系型數據的一些功能性增強,而非真正去適應XML所代表的層次型結構和面向對象的數據處理方法,因而難以發揮XML的靈活性、擴展性等方面的優勢,大大限制了XML技術在數據庫的應用。
關系數據庫中的第一代 XML 支持是切分(或分解)文檔以適應關系表格,或將文檔原封不動地存儲為字符或二進制大對象(CLOB 或 BLOB)。這兩個方法中的任一種,都嘗試將 XML 模型強制轉換成關系模型。以大對象保存XML數據的方式,使得數據庫無法理解XML中的信息內容,每次對XML中任何信息的訪問都必須將整個文檔取出,然後再分解獲得相應的信息內容,效率和靈活性都存在極大的限制。
如果采用將XML文檔中的數據項都拆分到很多個對應的關系型表中的方式,首先失去了XML靈活性的優勢。由於XML的數據項與關系型表中字段的對應是固定的,所以XML的擴展和變化必然要求數據庫中對應表的結構改變;另外數據對象拆分後,已經不再有物理上對象的概念,同樣在功能和性能上都有很大的局限性。
與過去關系型數據庫的XML增強功能不同,pureXML技術第一次真正意義上提供了一種與XML層次型結構相匹配的層次型存儲方式和相對應的操作訪問方式。
在pureXML中,XML 作為一種新的數據類型。幾乎每個 DB2 組件、工具和實用程序都已得到增強,以識別和處理這種新數據類型。新的存儲模式以解析後的注釋樹形式(類似於 XML 文檔對象模型 (DOM))保留 XML,它與關系數據存儲分開。
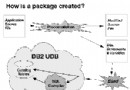
DB2 的新 XML 關系存儲模型
在兩種數據存儲(關系和 XML)的頂部是一個混合型數據庫引擎。該引擎可以處理 XQuery、Xpath、SQL和 SQL/XML。該引擎采用帶有 SQL 和 XQuery 解析程序的雙語查詢編譯器。因此,開發人員可以根據具體情況,使用相應的語言(或同時使用這兩種語言)。使用混合型 DB2 ,您可以根據信息管理的需要來靈活地選擇數據的存儲組織模式和訪問方法,實現二者之間靈活的轉換。
在數據庫管理系統中存儲關系和 XML 數據可提供靈活性和一貫快速的性能,因為數據庫管理系統在每一個級別(從客戶端到引擎,再到磁盤)都了解和支持這兩種模式。XML 數據繼承了 DB2 為關系數據提供的相同的備份與恢復、優化、可伸縮性和高可用性。最終,統一的 XML/關系數據庫通過避免對分開存儲的 XML 數據和關系數據進行集成,簡化了業務過程。