本文主要討論可以使決策支持系統(DSS)中的大型查詢高效地執行的一些方法。這些查詢通常都是訪問較多數據的單純 select 查詢。下面是我們要討論的一些方法:
1、建立適當的參照完整性約束;
2、使用物化查詢表(MQT)將表復制到其它數據庫分區,以允許非分區鍵列上的合並連接;
3、使用多維集群(MDC);
4、使用表分區(DB2® 9 的新功能);
5、結合使用表分區和多維集群;
6、使用 MQT 預先計算聚合結果。
本文中的例子針對 Windows 平台上運行的 DB2 9。但是,其中的概念和信息對於任何平台都是有用的。由於大多數商業智能(BI)環境都使用 DB2 Database Partitioning Feature(DPF,DB2 數據庫分區特性),我們的例子也使用 DPF 將數據劃分到多個物理和邏輯分區之中。
數據庫布局和設置
本節描述用於在我們的系統上執行測試的數據庫的物理和邏輯布局。
星型模式布局
本文使用如下所示的星型模式:
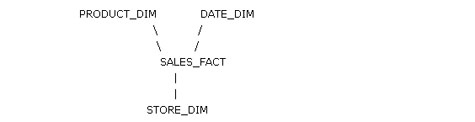
其中的表的定義如下:
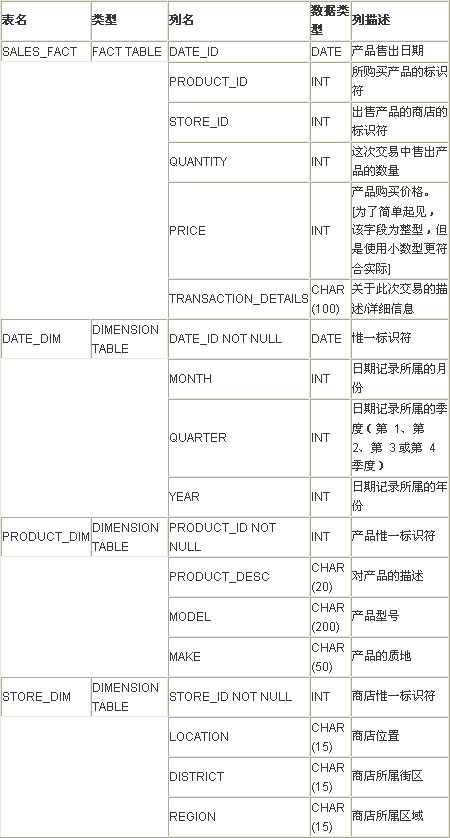
事實表 SALES_FACT 包含 2006 年的總體銷售信息。它包括產品售出日期、產品 ID、銷售該產品的商店的 ID、售出的特定產品的數量,以及產品的價格。事實表中還添加了 TRANSACTION_DETAILS 列,以便在從事實表中訪問數據時生成更多的 I/O。
1、維度表 DATE_DIM 包含商店開放期間的惟一的日期和相應的月份、季度和年份信息。
2、維度表 PRODUCT_DIM 包含公司所銷售的不同產品。每種產品有一個惟一的產品 ID 和一個產品描述、型號以及質地。
3、維度表 STORE_DIM 包含不同的商店 ID 和商店的位置、所屬街區以及所屬區域等信息。
數據庫分區信息

各表都位於它自己的分區組中。3 個維度表都比較小,所以它們位於一個數據庫分區上。而事實表則跨 4 個分區。
表空間信息

緩沖池信息
本文中的測試所使用的默認緩沖池是 IBMDEFAULTBP,該緩沖池由 1,000 個 4K 的頁面組成。在本文的測試中,所有表空間共享這個緩沖池。在通常的 BI 環境中,會創建不同的緩沖池。
主查詢
下面的查詢用於測試本文中討論的各種不同的方法。該查詢執行一個向外連接,比較二月份和十一月份 10 家商店的銷售信息。