作為一種內存中關系數據庫,IBM solidDB 受到全球的追捧,因為它能夠提供超快的速度和超高的可用性。顧名思義,內存中數據庫完全駐留在主存中,而不是磁盤上,這使得數據訪問比傳統的基於磁盤的數據塊要快一個數量級。這種飛躍一定程度上是由於 RAM 能夠比硬盤驅動器提供更快的數據訪問。
但是,solidDB 還有專為存儲、搜索和處理主存中數據而設計的數據結構和訪問方法。因此,即使普通的基於磁盤的數據庫將數據完全緩存在內存中,solidDB 仍可以勝出一籌。有些數據庫可以提供較短的延時,但是不能處理大量的事務或並發會話。IBM solidDB 可以提供每秒數萬至數十萬事務的吞吐率,並且始終可以獲得微秒級的響應時間(或延時)。本文探索內存中數據庫與基於磁盤的數據庫在結構上的差別,以及 solidDB 如何提供超快的速度。
RDBMS 的歷史
當 20 世紀 60 年代數據管理系統剛剛出現時,磁盤驅動器是唯一可以在合理時間內存儲和訪問大量數據的地方 。RDBMS 設計者的精力主要集中於優化 I/O 和設法用驅動器的塊結構來安排數據訪問模式。設計策略常常圍繞著共享緩沖池,數據塊存放在共享緩沖池中以便重用。隨著訪問方法的發展,出現了像著名的 B+ 樹(一種塊優化索引)之類的解決方案。
與此同時,查詢優化策略注重盡可能減少頁面讀取。在對性能的激烈爭奪中,磁盤 I/O 常常是最致命的敵人,為了避免磁盤訪問,往往需要犧牲處理效率。例如,對於典型的 8 KB 或 16 KB 的頁面,頁內處理天性是連續的,CPU 效率低於隨機數據訪問。然而,它仍是減少磁盤訪問的流行方法。
當內存富足時代到來時,很多 DBA 不斷增加緩沖池,直到緩沖池大到足以容納整個數據庫,這便產生了全緩存數據庫(fully cached database)的概念。但是,在 RAM 緩沖池中, DBMS 仍受累於效率低下的、結構化的、面向塊的 I/O 策略,這種策略原本是為處理硬盤驅動器而創建的。
將塊拋開
內存中數據庫系統一個最值得注意的不同之處在於沒有大數據塊結構。 IBM solidDB 消除了這種塊。表行和索引節點獨立地存儲在內存中,所以可以直接添加數據,而不必重新組織大塊結構。內存中數據庫還放棄使用大塊索引(有時也稱叢生樹),以利於精簡結構,增加索引層數,將索引節點最小化,以避免節點內處理的成本。最常見的內存中數據庫索引策略是 T-樹。然而,IBM solidDB 卻使用一種稱作 trie(或前綴樹)的索引,這種索引最初是為文本搜索而創建的,但是最終成為極佳的內存中索引策略。trie(此名源於單詞 retrIEval)由一系列的節點組成,其中,一個給定節點的後代具有與該節點關聯的相同的字符串前綴。例如,如果單詞 “dog” 被存儲為 trIE 中的一個節點,它將是包含 “do” 的節點的後代,而後者又是包含 “d” 的節點的後代。
TrIE 索引可以減少鍵值比較,並且幾乎可以消除節點內處理,從而能夠提高性能。索引包含一個節點,該節點是一個小型的指針數組,這些指針又指向更低的層。在此,不必使用整個鍵值通過遍歷樹來進行比較,鍵值被分割為一些小塊,每個塊包含數個比特位。每個小塊便是相應層的指針數組的直接索引:最左邊的小塊指向第一層節點,第二個小塊指向第二層的節點,依此類推。因此,只需進行幾次數組元素的檢索,便可完成整個搜索。而且,每個索引節點是一個小數據塊(在 solidDB 中大約為 256 字節),這可以帶來好處,因為這種數據塊正好適合現代處理器緩存,從而可以通過有效促進緩存的使用提高處理器的效率。這些小型數據數組是現代處理器中最有效的數據結構, solidDB 經常使用它們來最大化性能。
檢查點和耐久性:提速之路
IBM solidDB 還使用其他一些技術來加快數據處理,首先便是一種獲得專利的檢查點(checkpointing)方法,這種方法產生一個快照一致性檢查點,同時並不阻塞正常的事務處理。快照一致性檢查點使數據庫只需從一個檢查點重新啟動。其他數據庫產品通常不允許那樣,而必須使用事務日志文件來重新計算一致狀態(而 solidDB 則允許必要時關閉事務日志記錄)。solidDB 解決方案之所以能夠實現,是因為做到了分配行鏡像和行影子鏡像(相同行的不同版本),而不必使用低效的塊結構。只有那些與一致性快照相符的鏡像被寫到檢查點文件,行影子使當前執行的事務可以在檢查點創建期間不受限制地運行。
而且,solidDB 查詢優化器通過以一種新的方式估計執行成本,判別內存中的表的不同性質。查詢優化集中於 CPU 密集型(CPUbound)執行路徑,而全緩存數據庫將仍然集中於優化取頁到大容量存儲器的操作,而這已不再是問題。
IBM solidDB 使用的另一種技術是放寬事務持久性(durability)。在過去,數據庫總是支持完全持久性,以保證事務提交時寫的數據持久不變。問題是,這種完全持久性會造成同步日志寫,因而需要消耗資源,降低響應速度。在很多情況下,為取得更快的響應速度,對於某些任務接受較短的持久性,這是非常值得的。對於 solidDB,可以為給定的數據庫會話乃至整個事務在運行時放寬事務持久性。
IBM solidDB 還通過幫助開發人員避免客戶端/服務器交互中的進程上下文切換,提高數據庫性能。通過使用 solidDB 提供的、包含完整查詢執行代碼的數據庫訪問驅動程序,開發人員可以有效地將應用程序與 DBMS 代碼鏈接起來,並使用共享內存在應用程序之間共享數據。
一旦應用了所有這些措施,當應用程序負載大到使傳統數據庫中需要產生大量 I/O 時,使用 solidDB 將使吞吐率有數量級的提高。而且,響應速度的提高甚至更加驚人:查詢事務的延時通常是 10 到 20 微秒,更新事務的延時通常少於 100 微秒。在傳統的基於磁盤的數據庫中,對應的時間通常是以毫秒計算的。
solidDB 的速度和威力
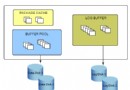
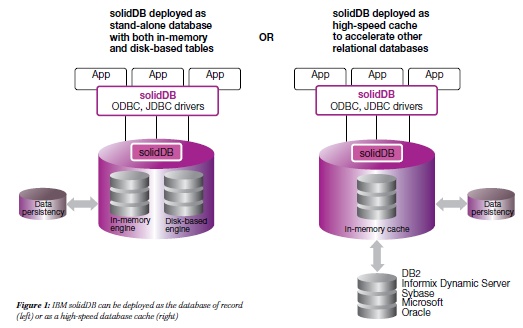
除了這些性能優點外,solidDB 還帶來其他好處。它將一個完全事務性的內存中數據庫和一個強大的、基於磁盤的數據庫組合到一個緊湊的解決方案中,並且可以透明地將同一個數據庫的一部分留在內存中,一部分留在磁盤上。而且,IBM solidDB 是市場上唯一一個可以作為幾乎任何其他基於磁盤的關系數據庫的前端高速緩存來部署的產品(見圖 1)。最後,solidDB 還提供超高的可用性,將可用時間由通常的 5 個 9 提高到 99.9999%。換句話說,如果您要尋求超快的速度,那麼將會找到 IBM solidDB,但這只是 IBM solidDB 的開端。