數據管理員從結構化信息中創造了大量的價值。現在的挑戰在於,如何將數據從無結構世界中拉出並將其與內部數據存儲庫混合,以獲取新視野。查找要分析的無結構數據沒有問題:IBM 新興技術的首席技術官 David Boloker 估計,目前全世界每天要創造 15 PB 的數據,80% 都來自無結構源。
“該挑戰最令人畏懼的部分不是收集無結構數據,而是從中獲取價值”,Boloker 說,“以生產臨床試驗藥物的制藥公司為例。許多臨床數據都是無結構的,病人記錄都是手寫的,然後再數據化。如果有一種方式可以快速將該數據提煉為更有結構的形式,則公司可以更加便捷地確認藥物的好處,或者定位以其他方式可能會錯失的一些微小問題。”
英國國家圖書館就面臨著這樣的挑戰。面對歸檔所有出版物信息的任務,員工需要一種方法將網站和其他無結構源的大量數據轉變為可用的資源。通過與 IBM 合作,圖書館成功地實現了名為 IBM BigSheets 的原型分析技術。
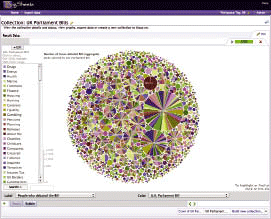
使用 IBM BigSheets 軟件,用戶能夠訪問大量數據歸檔,提交輕松搜索數據的查詢,以組織化的方式(如電子表格)分析數據,並以其他類似的可視上下文格式進行探索。例如,用戶可以在餅圖中查看搜索結果,並在標簽雲中查看數據。“作為一名數據管理員,我的問題是‘如何讓所有無結構數據變得對組織有用?’現在我知道答案了”,Boloker 說。
在底層,BigSheets 構建在 apache Hadoop 開源框架之上,可以在計算群集上進行大型數據集合並行處理,它使用 Hadoop Distributed File System (HDFS) 對應用程序數據進行高流量訪問。BigSheets 軟件從各種源應用程序中收集信息,提取數據,使用標記注解,並充實它以進行顯示。
BigSheets 已經可以支持英國國家圖書館從無結構數據中提取大量價值。但是 Boloker 期望該技術對科學、學術界和私人部門能產生廣泛的影響。“業務雲可以匹配給定 zip 代碼中的無結構數據與內部銷售數據,並查看引起向上和向下的趨勢”,他解釋道,“我們現在能夠使用原來在無結構世界中丟失的信息,將其與我們已經擁有的信息進行比較和對比。這對於數據管理員及其客戶而言真是一個新世界。”