簡介
MQT(Materialized Query Table,物化查詢表) 物化了涉及一個或多個表或昵稱的查詢的預先計算結果。而後續的查詢可以通過全部或部分匹配 MQT,並由 DB2 來補償剩余的查詢功能,從而達到提高查詢性能的目的。本文將會介紹 DB2 中 MQT 匹配的基本原理,並基於此指出如何設計 MQT 從而能使得查詢獲得更高的匹配率從而提高查詢效率。
MQT 匹配原理
MQT 在 OLAP 場景下能夠有效提高復雜查詢響應時間,尤其是有下面幾類數據操作需求的查詢:
在一個或多個維度上聚合數據。
在多個表之間連接數據。
數據來自於一個常見的數據訪問子集—也就是該子集會被頻繁訪問,MQT 能夠避免重復計算。
MQT 對應用程序是完全透明的。MQT 的相關信息已經被整合進 DB2 SQL 編譯器中,它們會判斷是否 MQT 應該被用來響應一個完整查詢或者查詢的一部分。因此,用戶可以在不改變應用程序代碼的情況下,創建和刪除 MQTs,就和創建和刪除索引而不需要更改應用程序一樣。
而如何做到上面的透明性,這是由 DB2 SQL 編譯器的 MQT 匹配算法來完成。如果我們把自己作為 MQT 匹配算法的作者,最容易想到的就是 MQT 需要滿足以下條件才能夠被匹配:MQT 中包含查詢需要的所有行 (Record);MQT 中包含查詢需要的所有列 (Column);MQT 中行的冗余度與查詢結果一致。或者通過某種程度的補償能夠達到上述 3 個條件,那麼 MQT 才有可能匹配對應查詢。在 DB2 中也是遵循上述基本原理來進行匹配。其大致步驟如下:1) 在查詢重寫 (Rewrite) 階段,DB2 編譯器會針對目前所有可能被匹配的 MQT 進行分析,並選擇一個最優的 MQT 匹配執行方案和不用 MQT 的執行方案。2) 在查詢優化 (Optimizer) 階段,會計算上述兩種方案的成本,並選擇成本最優的方案作為最終執行方案。需要注意的一點是在第一步中選擇最優 MQT 匹配方案是一種啟發式的選擇 (rule/heuristic based),並沒有真正計算成本。而且在這個過程中,可能匹配的 MQT 數目越多,需要的匹配過程越復雜,對應的編譯時間越長。所以說並不是 MQT 越多越好,一方面 MQT 會占用存儲空間,同時會增加編譯時間。用戶需要針對性地創建 MQT,保證其能夠真正帶來性能上的提升。而匹配的具體算法就不在這裡詳細闡述。如果讀者有興趣,可以在參考資源 2 中找到具體細節。
根據上面介紹的原理,以下 6 種查詢可以利用 MQT 來提高性能。本文將針對每種查詢舉例加以介紹:
MQT 能夠精確匹配查詢;
查詢結果集是 MQT 的子集;
查詢中連接的表數目多於 MQT;
查詢中連接的表是 MQT 中表的子集,需滿足引用完整性 (Reference Integrity, RI);
查詢中包含 MQT 中不存在的列,需滿足功能依賴;
查詢對應的聚集級別 (aggregation level) 高於 MQT。
為了對上面的 6 種情況進行詳細介紹,先創建一些示例表以方便通過實例來闡述這些原理。如清單 1 所示,表 Product 和 Customer 是維表 (dimension table),且分別定義了唯一鍵;表 Sales 是事實表 (fact table),它通過 PROD_ID 和 CUST_ID 的外鍵約束來保證引用完整性。至於表 Product 上定義的函數依賴 (Functional Dependency),我們將在後面詳細討論。另外,在實驗的過程中人為的設置了基本表和 MQT 表的統計信息,使得編譯器在選擇查詢計劃總認為使用 MQT 的代價低。這並不影響 MQT 匹配的過程,而且簡化了討論。
清單 1. 創建示例中的表
CREATE TABLE MQTSCH.PRODUCT(PROD_ID INT NOT NULL UNIQUE,
PROD_DESC VARCHAR(64),
CAT_ID INT NOT NULL, CAT_DESC VARCHAR(64),
GROUP_ID INT NOT NULL, GROUP_DESC VARCHAR(64),
CONSTRAINT FD1 CHECK
(CAT_DESC DETERMINED BY CAT_ID)
NOT ENFORCED ENABLE QUERY OPTIMIZATION,
CONSTRAINT FD2 CHECK
(GROUP_ID DETERMINED BY CAT_ID)
NOT ENFORCED ENABLE QUERY OPTIMIZATION
);
CREATE TABLE MQTSCH.CUSTOMER(CUST_ID INT NOT NULL UNIQUE,
CUST_NAME VARCHAR(50),
CUST_ADDRESS VARCHAR(100));
CREATE TABLE MQTSCH.SALES(PROD_ID INT NOT NULL REFERENCES MQTSCH.PRODUCT(PROD_ID),
CUST_ID INT NOT NULL REFERENCES MQTSCH.CUSTOMER(CUST_ID),
SALE_DATE DATE NOT NULL,
AMOUNT DECIMAL(9,2) NOT NULL);
runstats on table MQTSCH.CUSTOMER;
runstats on table MQTSCH.PRODUCT;
runstats on table MQTSCH.SALES;
update syscat.tables set card=20 where tabname='CUSTOMER';
update syscat.tables set card=200 where tabname='PRODUCT';
update syscat.tables set card=2000 where tabname='SALES';
set current refresh age=any;
MQT 能夠精確匹配查詢
這種情況是最容易理解的。當 MQT 能夠精確匹配查詢時,通常情況下,從 MQT 中獲取數據的性能會優於執行相應查詢,故選擇 MQT 的執行方案通常會勝出。清單 2 中給出一個示例。其中 MQT SALES_PROD 基於外鍵連接事實表 Sales 與維表 Product。而查詢則是同樣的 Join 操作。這時,MQT 能匹配這個查詢。在清單 2 中可以看到 MQT 和查詢的詳細內容,並且打印出的執行計劃和拓展診斷信息明確的顯示了 SALES_PROD 在查詢匹配時被利用了。
清單 2. 精確的 MQT 匹配
--MQT definition: join for SALES and PRODUCT
CREATE TABLE MQTSCH.SALES_PROD AS
(SELECT P.PROD_ID, PROD_DESC, AMOUNT
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S
WHERE P.PROD_ID = S.PROD_ID)
DATA INITIALLY DEFERRED REFRESH DEFERRED;
refresh table MQTSCH.SALES_PROD;
--artifical statistics
runstats on table MQTSCH.SALES_PROD;
update syscat.tables set card=10 where tabname='SALES_PROD';
--collect the explain information
DELETE FROM EXPLAIN_INSTANCE;
explain plan for SELECT P.PROD_ID, PROD_DESC, AMOUNT
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S
WHERE P.PROD_ID = S.PROD_ID;
!db2exfmt -1 -d mqtdb -o join.plan;
下面是 join.plan 打印出的執行計劃和診斷信息:
Access Plan:
-----------
Total Cost: 10.3414
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
10
TBSCAN
( 2)
10.3414
1
|
10
TABLE: MQTSCH
SALES_PROD
Q1
Extended Diagnostic Information:
--------------------------------
Diagnostic IdentifIEr: 1
Diagnostic Details: EXP0148W The following MQT or statistical vIEw was
considered in query matching: "MQTSCH ".
"SALES_PROD".
Diagnostic IdentifIEr: 2
Diagnostic Details: EXP0149W The following MQT was used (from those
considered) in query matching: "MQTSCH ".
"SALES_PROD".
查詢結果集是 MQT 的子集
這種情況也很容易理解。當查詢結果集是 MQT 的子集時,這意味著查詢需要的行與列在 MQT 中都能找到,而 DB2 只需要在對應 MQT 上執行剩余的謂詞 (predicate) 及計算 (head expression) 即可。如圖 2 所示,這種 MQT 只需要被計算一次就可以被多次重用。清單 3 則給出了該場景的一個具體例子。
圖 1. 查詢結果集是 MQT 子集示意圖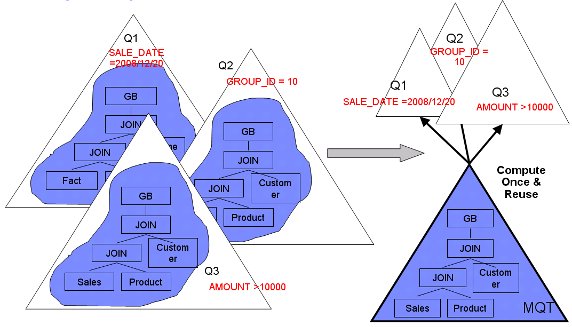
查看原圖(大圖)
清單 3. 查詢結果集是 MQT 子集匹配
--MQT definition: join for SALES and PRODUCT
CREATE TABLE MQTSCH.SALES_PROD AS
(SELECT P.PROD_ID, PROD_DESC, AMOUNT
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S
WHERE P.PROD_ID = S.PROD_ID)
DATA INITIALLY DEFERRED REFRESH DEFERRED;
refresh table MQTSCH.SALES_PROD;
--artifical statistics
runstats on table MQTSCH.SALES_PROD;
update syscat.tables set card=10 where tabname='SALES_PROD';
--collect the explain information
DELETE FROM EXPLAIN_INSTANCE;
explain plan for SELECT P.PROD_ID, PROD_DESC, AMOUNT
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S
WHERE P.PROD_ID = S.PROD_ID and AMOUNT > 10000;
!db2exfmt -1 -d mqtdb -o joinsub.plan;
下面是 join_sub.plan 打印出的執行計劃和診斷信息。有一點需要注意的是清單 2 與清單 3 中的 TBSCAN 並不完全相同。清單 3 中的 TBSCAN 包含謂詞 (10000 < Q1.AMOUNT)。
Access Plan:
-----------
Total Cost: 10.5194
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
3.33333
TBSCAN
( 2)
10.5194
1
|
10
TABLE: MQTSCH
SALES_PROD
Q1
Extended Diagnostic Information:
--------------------------------
Diagnostic IdentifIEr: 1
Diagnostic Details: EXP0148W The following MQT or statistical vIEw was
considered in query matching: "MQTSCH ".
"SALES_PROD".
Diagnostic IdentifIEr: 2
Diagnostic Details: EXP0149W The following MQT was used (from those
considered) in query matching: "MQTSCH ".
"SALES_PROD".
查詢中連接的表數目多於 MQT
根據前面介紹的 MQT 匹配原理,這種情況成立的前提是 MQT 完成所有連接後得到的結果集需要是查詢中對應表完成連接後結果集的超集。如果 MQT 包含查詢中沒有的謂詞並且過濾掉一部分結果集,則該 MQT 無法進行匹配。
圖 2. 查詢中連接的表數目多於 MQT 匹配示意圖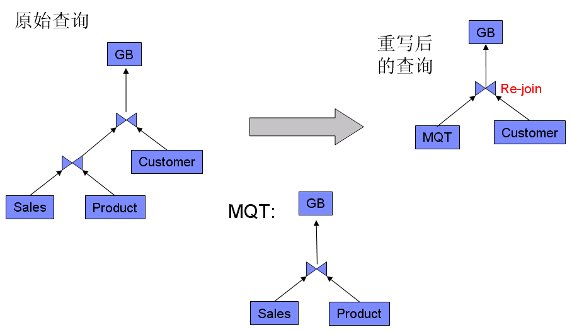
查看原圖(大圖)
清單 4. 查詢中連接的表數目多於 MQT 匹配
--MQT definition: join for SALES and PRODUCT
CREATE TABLE MQTSCH.SALES_PROD AS
(SELECT P.PROD_ID, PROD_DESC, AMOUNT, CUST_ID
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S
WHERE P.PROD_ID = S.PROD_ID)
DATA INITIALLY DEFERRED REFRESH DEFERRED;
refresh table MQTSCH.SALES_PROD;
--artifical statistics
runstats on table MQTSCH.SALES_PROD;
update syscat.tables set card=10 where tabname='SALES_PROD';
--collect the explain information
DELETE FROM EXPLAIN_INSTANCE;
explain plan for SELECT P.PROD_ID, PROD_DESC, AMOUNT, C.CUST_ID, CUST_NAME
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S, MQTSCH.CUSTOMER C
WHERE P.PROD_ID = S.PROD_ID
AND S.CUST_ID = C.CUST_ID;
!db2exfmt -1 -d mqtdb -o join_rejoin.plan;
下面是 join_rejoin.plan 打印出的執行計劃和診斷信息:
Access Plan:
-----------
Total Cost: 18.8629
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
20
^NLJOIN
( 2)
18.8629
2
/------+-------\
1 20
TBSCAN FETCH
( 3) ( 4)
9.72148 36.0967
1 4
| /---+----\
1 20 20
TABLE: MQTSCH IXSCAN TABLE: MQTSCH
SALES_PROD ( 5) CUSTOMER
Q2 35.3323 Q1
4
|
20
INDEX: SYSIBM
SQL100124231518010
Q1
Extended Diagnostic Information:
--------------------------------
Diagnostic IdentifIEr: 1
Diagnostic Details: EXP0022W Index has no statistics. The index
"SYSIBM "."SQL100124231518010" has not had
runstats run on it. This can lead to poor
cardinality and predicate filtering estimates.
Diagnostic IdentifIEr: 2
Diagnostic Details: EXP0148W The following MQT or statistical vIEw was
considered in query matching: "MQTSCH ".
"SALES_PROD".
Diagnostic IdentifIEr: 3
Diagnostic Details: EXP0149W The following MQT was used (from those
considered) in query matching: "MQTSCH ".
"SALES_PROD".
查詢中連接的表是 MQT 中的子集,需滿足 RI
前面提到,MQT 匹配的前提是 MQT 僅包含且正好包含查詢所需要的數據行。因此,如果一個 MQT 中連接 (Join) 的表多於查詢中的表,一般不能用這個 MQT 來匹配,因為額外的 Join 操作會影響 MQT 所包含的行及對應的冗余度。然而,如果額外的 Join 操作是基於 RI(引用完整性)的,那麼它不會增加或刪除任何行,編譯器能夠利用這個事實在上述情況中匹配 MQT。這種基於 RI 的 Join 操作在事實表和維表之間是很常見的。
通過例子來說明。如圖 4 所示,SALES_PROD_CUST 這個 MQT 基於外鍵連接了事實表 Sales 與兩個維表 Product 和 Customer。而查詢則是在 Sales 和 Product 的 Join 操作。這時,MQT 能匹配這個查詢。 在清單 5 中可以看到 MQT 和查詢的詳細內容,並且打印出的執行計劃和拓展診斷信息明確的顯示了 SALES_PROD_CUST 在查詢匹配時被利用了。
圖 3. 含有額外 RI-Join 時的 MQT 匹配示意圖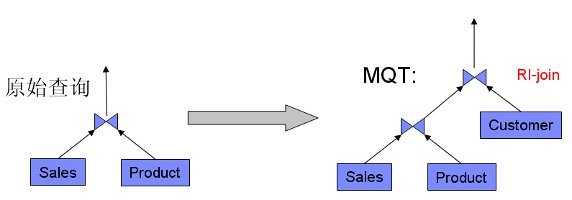
查看原圖(大圖)
清單 5. 含有額外 RI-Join 時的 MQT 匹配
--MQT definition: with extra RI-Joins
CREATE TABLE MQTSCH.SALES_PROD_CUST AS
(SELECT P.PROD_ID, CAT_DESC, AMOUNT, C.CUST_ID, CUST_NAME
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S, MQTSCH.CUSTOMER C
WHERE P.PROD_ID = S.PROD_ID
AND S.CUST_ID = C.CUST_ID )
DATA INITIALLY DEFERRED REFRESH DEFERRED;
refresh table MQTSCH.SALES_PROD_CUST;
--artifical statistics
runstats on table MQTSCH.SALES_PROD_CUST;
update syscat.tables set card=10 where tabname='SALES_PROD_CUST';
--collect the explain information
DELETE FROM EXPLAIN_INSTANCE;
explain plan for SELECT P.PROD_ID, CAT_DESC, AMOUNT
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S
WHERE P.PROD_ID = S.PROD_ID;
!db2exfmt -1 -d mqtdb -o join_redud.plan;
下面是 join_redun.plan 打印出的執行計劃和診斷信息:
Access Plan:
-----------
Total Cost: 10.3414
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
10
TBSCAN
( 2)
10.3414
1
|
10
TABLE: MQTSCH
SALES_PROD_CUST
Q1
Extended Diagnostic Information:
--------------------------------
Diagnostic IdentifIEr: 1
Diagnostic Details: EXP0148W The following MQT or statistical vIEw was
considered in query matching: "MQTSCH ".
"SALES_PROD_CUST".
Diagnostic IdentifIEr: 2
Diagnostic Details: EXP0149W The following MQT was used (from those
considered) in query matching: "MQTSCH ".
"SALES_PROD_CUST".
查詢中包含 MQT 中不存在的列,需滿足功能依賴
在開始介紹接下來的 MQT 匹配原理之前,有必要先簡單介紹一下功能依賴 (Functional Dependency) 這個概念。Y 功能依賴於 X,是指 Y 的值由 X 決定,即每個 X 的值精確的對應著一個 Y 的值,記作 X -> Y。
根據定義,關系表上的所有列都功能依賴於主鍵或唯一鍵。例如,清單 1 中 Product 表,PROD_ID ->CAT_ID。對於非鍵列之間的功能依賴,DB2 通過定義一個參考約束 (informational constraint) 來實現。如清單 1 中在 Product 表上 FD1 和 FD2,分別定義了 CAT_ID -> CAT_DESC 和 CAT_ID -> GROUP_ID 這兩個函數依賴。在參考約束定義中:
關鍵字 DETERMETED BY 准確地表達了函數依賴的含義;
NOT ENFORCED 表示在執行增刪改時 DB2 並不驗證數據來保證約束的完整性;
ENABLE QUERY OPTIMIZATION 告訴編譯器可以利用這個函數依賴來重寫和優化查詢。
由於 DB2 並不強制函數依賴的這種約束的完整性,根據這個函數依賴優化的查詢結果可能是錯誤的,因此,需要注意函數依賴的定義和維護。
繼續 MQT 匹配的討論。我們知道,MQT 匹配時,要求查詢中需要的列都能從 MQT 中找到。那麼如果查詢中包含 MQT 不存在的列呢?函數依賴讓這種匹配也變成可能。DB2 根據這些函數依賴重寫查詢,通過 MQT 和基本表的 re-join 來獲得 MQT 缺少的列。
在清單 6 的例子中,MQT SALES_BY_CAT 的定義包含列 CAT_ID,統計每類產品的銷售總量,然而查詢卻希望獲得 CAT_DESC 和銷售總量,而 CAT_DESC 不在 MQT 中。如果沒有函數依賴,這個 MQT 是不能匹配的。而正是 Product 上的函數依賴 CAT_ID -> CAT_DESC 讓這個 MQT 的匹配變成可能。
拓展診斷信息 (Extended Diagnostic Information) 段揭示了編譯器的整個處理過程:診斷信息 1 中 EXP0073W 說明由於查詢中包含 MQT 沒有的列,這個 MQT 不能匹配;診斷 3 中 EXP0149W 表示當編譯器收集到函數依賴後,用 MQT 匹配了這個查詢。優化後的語句和執行計劃一致的顯示 MQT 的匹配以及 re-join 操作的生成。
由於 CAT_ID 不是具有唯一性的鍵,優化後的語句中利用 DISTINCT 來去除重復,對應了查詢計劃的 SORT 操作。一般情況下,這個 DISTINCT 是作用在維表上,開銷很小。
清單 6. 含有額外 RI-Join 時的 MQT 匹配
--MQT missing columns, with FD
CREATE TABLE MQTSCH.SALES_BY_CAT AS
(SELECT CAT_ID, SUM(AMOUNT) AS TOTAL, COUNT(*) AS CNT
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S
WHERE P.PROD_ID = S.PROD_ID
GROUP BY CAT_ID )
DATA INITIALLY DEFERRED REFRESH IMMEDIATE;
refresh table MQTSCH.SALES_BY_CAT;
runstats on table MQTSCH.SALES_BY_CAT;
update syscat.tables set card=10 where tabname='SALES_BY_CAT';
--collect the explain information
DELETE FROM EXPLAIN_INSTANCE;
explain plan for SELECT CAT_DESC, SUM(AMOUNT)
FROM MQTSCH.PRODUCT P, MQTSCH.SALES S
WHERE P.PROD_ID = S.PROD_ID
GROUP BY CAT_ID, CAT_DESC;
!db2exfmt -1 -d mqtdb -o fd.plan;
下面是 fd.plan 打印出的執行計劃和診斷信息:
Optimized Statement:
-------------------
SELECT Q3.CAT_DESC AS "CAT_DESC", Q1.TOTAL
FROM MQTSCH.SALES_BY_CATAS Q1,
(SELECT DISTINCTQ2.CAT_DESC, Q2.CAT_ID
FROM MQTSCH.PRODUCT AS Q2) AS Q3
WHERE (Q1.CAT_ID = Q3.CAT_ID)
Access Plan:
-----------
Total Cost: 98.6553
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
0.4
HSJOIN
( 2)
98.6553
10
/---+----\
10 1
TBSCAN TBSCAN
( 3) ( 4)
74.9814 23.5881
9 1
| |
10 1
TABLE: MQTSCH SORT
SALES_BY_CAT ( 5)
Q1 23.5366
1
|
200
TBSCAN
( 6)
23.4286
1
|
200
TABLE: MQTSCH
PRODUCT
Q2
Extended Diagnostic Information:
--------------------------------
Diagnostic IdentifIEr: 1
Diagnostic Details: EXP0073W The following MQT or statistical vIEw was
not eligible because one or more data filtering
predicates from the query could not be matched with
the MQT: "MQTSCH "."SALES_BY_CAT".
Diagnostic IdentifIEr: 2
Diagnostic Details: EXP0148W The following MQT or statistical vIEw was
considered in query matching: "MQTSCH ".
"SALES_BY_CAT".
Diagnostic IdentifIEr: 3
Diagnostic Details: EXP0149W The following MQT was used (from those
considered) in query matching: "MQTSCH ".
"SALES_BY_CAT".