IBM Data Studio 是一款免費的基於 Eclipse 的用於數據庫開發的工具。 IBM Data Studio 包含了開發數據庫存儲過程的所有功能,同時提供了對 DB2 v9 的 XML 功能的支持。
本文將通過一個開發實例介紹 IBM Data Studio 是如何幫助我們進行存儲過程開發的。
項目實例介紹
在開始使用 IBM Data Studio 之前,讓我們先來了解一下本文的項目實例。該項目實例是一個簡化版的軟件開發管理系統。系統主要管理 User Story 和 Work Item 的信息。 User Story 就是以用戶的角度編寫的業務需求,是軟件需要實現的功能。我們需要記錄 User Story 的具體內容和其狀態。這裡的狀態是指該 User Story 是在草擬狀態還是完成狀態。 Work Item 用於記錄軟件開發的過程。 Work Item 可以是根據某個 User Story 編寫的詳細設計,也可以是一個編碼任務,或者是一個 bug 報告。我們需要記錄其狀態(未分配,處理中和完成等),結對編程人員的 Email 等信息。
本系統應該實現如下功能 ( 未列出所有功能 ):
創建 User Story 。
修改 User Story 。
查詢所有草擬狀態的 User Story 。
創建 Work Item 。
修改 Work Item 。
查詢屬於某個 User Story 的所有 Work Item 。
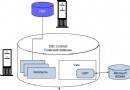
為此我們設計了相應的數據庫表:USER_STORY 和 WORK_ITEM 。它們的詳細定義如下表所示:
圖 1. User story 和 Work item 的關系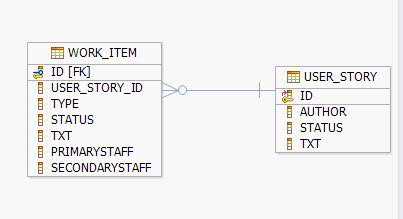
表 1. User Story 的定義
USER_STORY 列名稱 類型 說明 id INTEGER 表主鍵。 author VARCHAR 編寫人的 Email 地址。 status CHAR 表示 User Story 的狀態,可以是草擬,完成等值。 txt VARCHAR User Story 的具體內容
表 2. Work Item 的定義
WORK_ITEM 列名稱 類型 說明 id INTEGER 表主鍵。 user_story_id INTEGER 記錄該 Work Item 對應的 User Story 。 type CHAR 類型,分為:詳細設計,編碼任務,bug 報告。 status CHAR 狀態,分為: 未分配,處理中,完成等。 txt VARCHAR Work Item 的具體說明。 primaryStaff VARCHAR 首席工作人員 Email 地址 secondaryStaff VARCHAR 結對的開發人員 Email 地址
為了實現系統的功能,我們還需要下列存儲過程 :
I_USER_STORY: 創建 User Story 。
U_USER_STORY: 修改 User Story 。
S_INIT_STORY: 查詢所有草擬狀態的 User Story 。
I_WORK_ITEM: 創建 Work Item 。
U_WORK_ITEM: 修改 Work Item 。
S_ITEM_OF_STORY: 查詢屬於某個 User Story 的所有 Work Item 。
DB2 存儲過程開發
“工欲善其事,必先利其器”。現在我們明確了需求,為了開發出優秀的軟件,我們還需要一個開發工具。 IBM Data Studio 就是一款非常好的存儲過程開發工具,我們可以從 IBM 官方網站上下載其安裝包。安裝完畢後啟動 IBM Data Studio,可以看到 IBM Data Studio 的界面主要由四個區域組成:
Data Project Explorer中會列出所有的Data project。
Data Explorer中會列出所有的數據庫連接。
工作區用於編輯 SQL 文件和存儲過程源文件。
Data Output是結果輸出區,在我們執行 SQL 語句後,數據庫返回的結果會顯示在該區域。
圖 2. IBM Data Studio 的主要界面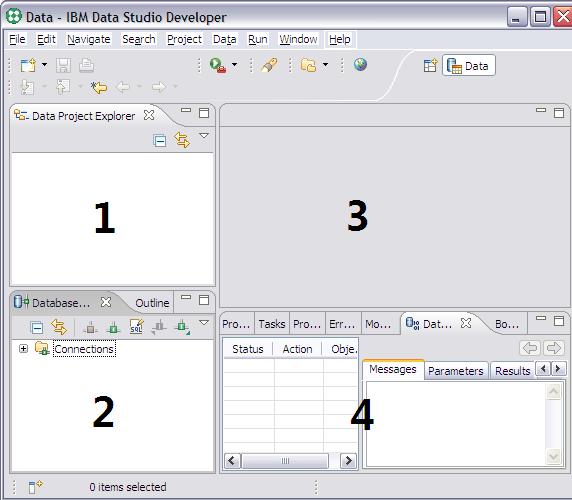
查看原圖(大圖)
創建數據庫項目
首先創建一個數據庫連接:
右鍵單擊Data Explorer中的Connections, 選擇New Connections...,
在新建數據庫連接向導中,填入數據庫的信息 : 數據庫地址,端口,用戶名和密碼等,
單擊Test Connection按鈕來測試數據庫連接是否正常,
單擊Finish按鈕後,一個新的數據庫連接就創建完畢。我們可以在Data Explorer中看到新建的數據庫連接 DRAG 。
圖 3. 新建數據庫連接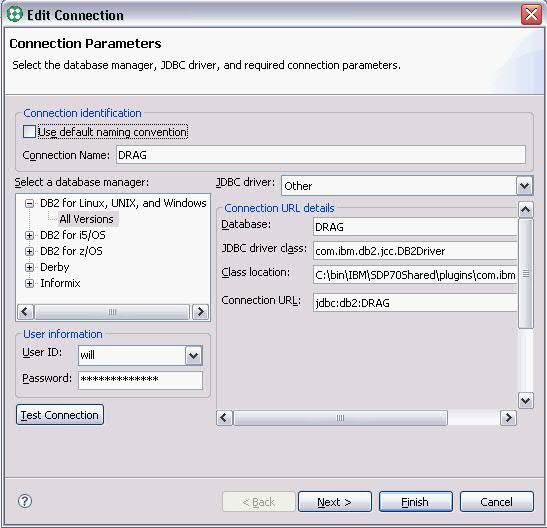
默認情況下 IBM Data Studio 不會記錄連接數據庫的用戶密碼,為了避免每次連接數據庫時都輸入密碼,我們可以修改相應設置,把數據庫的用戶和密碼存儲在電腦中:
從菜單上選擇Window > Preferences...,
在彈出窗口的左邊選定Data節點,
把PassWord information設置為Persistence Scope。
圖 4. 修改密碼保存選項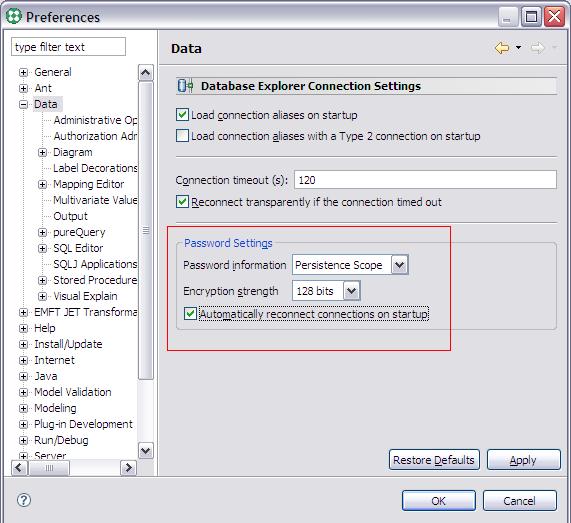
查看原圖(大圖)
接著,我們創建一個數據庫項目。
右鍵單擊Data Project Explorer,在彈出菜單上選擇New > Data Development Project。
輸入項目名稱和 schema 名稱。這裡我們輸入 Sample 作為項目的名稱,使用登錄用戶 ID 作為項目的 schema 。
選擇數據庫連接。您可以創建一個新連接,也可以使用已有的數據庫連接。這裡我們選擇數據庫 DRAG 。
點擊Finish,一個 Data Development Project 就創建完畢了。
展開 Sample 項目,我們可以看到在項目的根目錄下有五個文件夾,分別用來存放 SQL 文件,存儲過程源文件,UDF 源文件,Web Service 文件和 XML 文件。
圖 5. 項目的結構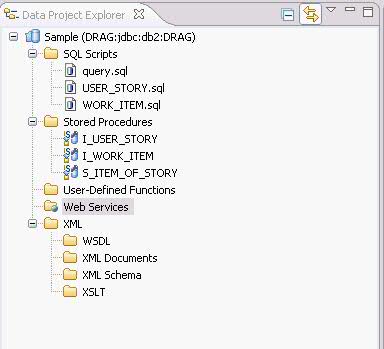
開發數據庫對象
創建完項目,我們就可以開始開發數據庫對象了,也就是要編寫建表語句和存儲過程。為了規范我們編寫的代碼和提高我們編碼的效率,我們首先要設置一下模板。
在 IBM Data Studio 中可以很方便地定義 SQL 模板:
選擇菜單Window > Preferences。
在彈出的參數配置頁面的左側,選擇Data > SQL Editor > Templates。
從下圖我們可以看到,IBM Data Studio 給我們提供了一些通用的模板。
圖 6. 通用模板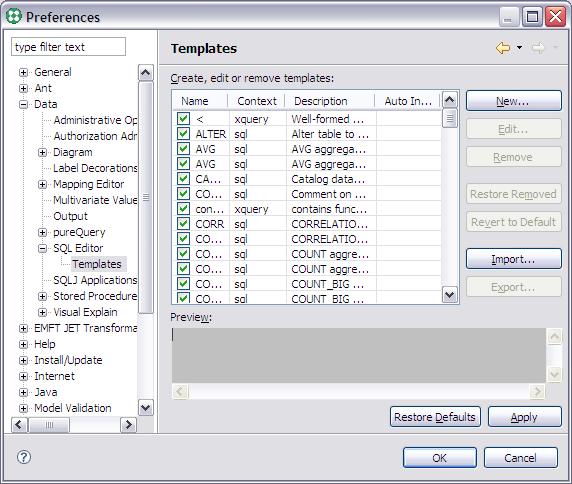
查看原圖(大圖)
這裡我們再定義一些我們項目中使用的模板。
點擊New...按鈕,IBM Data Studio 會彈出一個模板定義窗口。
輸入模板的名稱和內容 (Pattern) 等。在定義模板內容的時候,需要替換的部分我們稱為變量,變量可以使用 ${} 進行定義,例如 ${expression} 。
下面是我們定義的模板的具體內容:
清單 1. 創建表的模板
DROP TABLE ${table_name}
@
----------------------------------------------------------------------------------
--
-- Table_Name: ${table_name}
-- File Name: ${table_name}.SQL
-- Author: ${user}
-- Date: ${date}
--
-- Abstract:
--
--
-- MAINTENANCE LOG
-- who date comment
-- --- -------- ---------------------------------------------------------------
-----------------------------------------------------------------------------------
CREATE TABLE ${table_name}
(
)
@
--Primary Key
ALTER TABLE ${table_name}
ADD CONSTRAINT ${table_name}_PK
PRIMARY KEY (${pk} )
@
清單 2. 創建存儲過程的模板
DROP SPECIFIC PROCEDURE ${spName}
@
CREATE PROCEDURE ${spName} (
OUT poGenStatus INTEGER
, IN ${piArgu} VARCHAR(8)
)
SPECIFIC ${spName}
RESULT SETS 0
LANGUAGE SQL
------------------------------------------------------------------------------
--
-- Procedure Name : ${spName}
-- Specific Name: ${spName}
-- File Name: ${spName}.SQL
-- Author: ${user}
-- Date: ${date}
--
-- Abstract: ${description}
--
--
-- Sample Calls:
-- call ${spName} (?,'${piArgu}')
--
-- MAINTENANCE LOG
-- who date comment
-- --- -------- ------------------------------------------------------------
-- ${user} ${date} Initial version
--
-------------------------------------------------------------------------------
BEGIN NOT ATOMIC
-------------------------------------------------------------
-- Variables declarations
-------------------------------------------------------------
-- Generic Variables
DECLARE SQLCODE INTEGER DEFAULT 0;
DECLARE SQLSTATE CHAR(5) DEFAULT '00000';
-- Generic handler variables
DECLARE hSqlcode INTEGER DEFAULT 0;
DECLARE hSqlstate CHAR(5) DEFAULT '00000';
-- error variables
DECLARE ERR_MISSING_INPUT INTEGER DEFAULT 34100;
DECLARE ERR_GENERAL_SQL INTEGER DEFAULT 1;
DECLARE ERR_RECORD_EXISTS INTEGER DEFAULT 4;
DECLARE ERR_ROW_NOT_FOUND INTEGER DEFAULT 5000;
-- Local Variables
DECLARE vCurrentTimestamp TIMESTAMP;
-------------------------------------------------------------
-- CONDITION declaration
-------------------------------------------------------------
-- (80100~80199) SQLCODE & SQLSTATE
DECLARE sqlReset CONDITION FOR SQLSTATE '80100';
-------------------------------------------------------------
-- CURSOR declaration
-------------------------------------------------------------
-------------------------------------------------------------
-- EXCEPTION HANDLER declaration
-------------------------------------------------------------
-- Handy Handler
DECLARE CONTINUE HANDLER FOR sqlReset
BEGIN NOT ATOMIC
SET hSqlcode = 0;
SET hSqlstate = '00000';
SET poGenStatus = 0;
END;
-- Generic Handler
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION, SQLWARNING, NOT FOUND
BEGIN NOT ATOMIC
-- Capture SQLCODE & SQLSTATE
SELECT SQLCODE, SQLSTATE
INTO hSqlcode, hSqlstate
FROM SYSIBM.SYSDUMMY1;
-- Use the poGenStatus variable to tell the procedure what type
-- of error occurred. In some cases, it can be assigned to the
-- poGenStatus variable to be returned to the clIEnt.
CASE hSqlstate
WHEN '02000' THEN --row not found
SET poGenStatus=5000;
WHEN '42724' THEN --missing llsp
SET poGenStatus=3;
ELSE
IF (hSqlCode < 0) THEN --trap only errors, not warnings
SET poGenStatus=2;
END IF;
END CASE;
END;
-------------------------------------------------------------
-- Initialization
-------------------------------------------------------------
-- reset all output parameters to NULL
SET poGenStatus = 0;
SET ${piArgu} = RTRIM(COALESCE(${piArgu}, ''));
--------------------
-- data validation
--------------------
IF (${piArgu} = '') THEN
SET poGenStatus = ERR_MISSING_INPUT;
RETURN poGenStatus;
END IF;
SET vCurrentTimestamp = CURRENT TIMESTAMP;
RETURN poGenStatus;
END
@
現在我們開始編寫代碼。右鍵單擊SQL Scripts文件夾,在彈出菜單中選擇New > SQL or Xquery Script。輸入名稱 USER_STORY,然後單擊Finish。在打開的 USER_STORY.SQL 中,單擊右鍵選擇Content Assist,然後選擇 create table 模板。模板的內容被插入到文件中,需要修改的內容被高亮顯示。我們依次修改表名和列的信息。在我們修改 SQL 文件的時候,IBM Data Studio 還在有語法錯誤的語句下面顯示一條紅線,真是太棒了!
修改後的代碼如下:
清單 3. 建表語句
-- <ScriptOptions statementTerminator="@" />
DROP TABLE USER_STORY
@
----------------------------------------------------------------------------------
--
-- Table_Name: USER_STORY
-- File Name: USER_STORY.SQL
-- Author: will
-- Date: Sep 9, 2008
--
-- Abstract:
--
--
-- MAINTENANCE LOG
-- who date comment
-- --- -------- ---------------------------------------------------------------
-----------------------------------------------------------------------------------
CREATE TABLE USER_STORY
(
id INTEGER NOT NULL, -- 表主鍵。
author VARCHAR(80), -- 編寫人的 Email 地址。
status CHAR(10), -- 表示 User Story 的狀態,可以是草擬,完成等值。
txt VARCHAR(500) --User Story 的具體內容
)
@
--Primary Key
ALTER TABLE USER_STORY
ADD CONSTRAINT USER_STORY_PK
PRIMARY KEY (ID )
@
編寫完建表文件後,我們需要把它裝載到數據庫中。
由於我們在 USER_STORY.SQL 文件中使用 @ 符號作為分隔符。所以,我們需要在 IBM Data Studio 中把 @ 指定成分隔符。在工作區,單擊右鍵,在彈出菜單中選擇Set Statement Terminator,然後輸入 @ 。
下面,我們開始執行我們編寫的 USER_STORY.SQL 文件。右鍵單擊工作區,選擇Run SQL。我們可以在Data Output視圖中看到 Run successful 的消息。
我們來查詢一下 USER_STORY 表裡數據。新建一個 query.sql 文件。在 query.sql 文件裡鍵入 SELECT * FROM, 這時我突然忘記了表的名字(有時候,因為表名太長,我們很容易不記得其名字),IBM Data Studio 可以幫助我們找到我們想要的表。首先鍵入 U (我記得表是以 U 開頭的),然後單擊右鍵選擇Content Assist或者使用快捷鍵 Alt+/ 。哦,IBM Data Studio 把所有以 U 開頭的表都列在了彈出框裡。我們選擇 USER_STORY 這個表。然後,我們象執行 USER_STORY.SQL 一樣執行該語句,可以在 Data Output 視圖中看到,目前表裡沒有任何數據。
圖 7. Data Output 視圖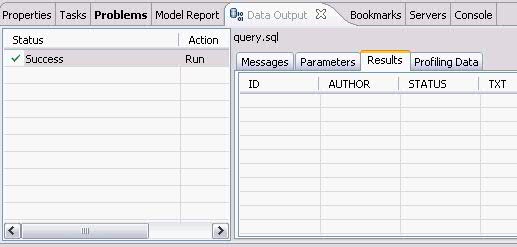
在Content Assist和模板的幫助下,我們很方便的完成了項目所需要的表和存儲過程。雖然 IBM Data Studio 也提供了創建存儲過程的向導,不過我更傾向於模板加手動修改源文件的方式編寫存儲過程。您可以選擇您自己喜歡的方式去編寫存儲過程。
有時候,我們需要看一下數據庫中某個存儲過程的源代碼。我們可以在Database Explorer中,依次打開[database name]> Schemas > Stored Procedures。右鍵單擊存儲過程,在彈出菜單中選擇Open > With SQL Editor。然後存儲過程的源代碼就在 IBM Data Studio 中打開了。
圖 8. 打開源代碼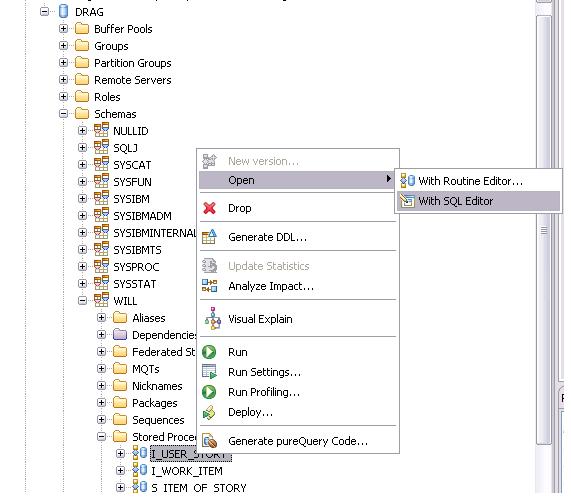
查看原圖(大圖)
調試存儲過程
我們已經編寫完所有的存儲過程了,測試人員正在對這些存儲過程進行測試,初步結論是這些存儲過程運行正常。我們非常高興,認為開發工作應該是完成了。可是正當我們暗自高興的時候,測試人員來找我們了。他們說,新增 User Story 這塊功能突然出問題了,這塊功能在前幾天的測試都是正常的。這就奇怪了,我們最近沒有更新過代碼,為什麼原來可以使用的功能突然就不能用了呢? 大家一邊看著代碼,一邊皺眉---代碼應該沒有問題啊。
幸好,IBM Data Studio 為我們提供了非常優秀的調試功能,我們可以像調試 Java 程序那樣調試存儲過程。 在 IBM Data Studio 中針對存儲過程設置斷點,單步執行,查看存儲過程運行時的某些變量值都變得非常簡單。
現在我們就開始調試出問題的存儲過程 I_USER_STORY 。
在Data Project Explorer窗口中,右鍵單擊存儲過程 I_USER_STORY,選擇Deploy...,
在彈出的部署向導頁上選中Enable Debuging選項,點擊Finish,把 I_USER_SOTRY 部署到數據庫中,
使用 SQL 編輯器打開項目中的存儲過程,雙擊左側欄設置斷點。
在Data Project Explorer窗口中右鍵單擊存儲過程,選擇彈出菜單中的Debug...。
IBM Data Studio 詢問我們是否使用調試視圖,選擇Yes。
在調試視圖中,我們可以點擊 Debug 窗口中的step into,step over進行單步調試,可以在Variables窗口看到當前所有變量的值。
圖 9. 設置 debug 選項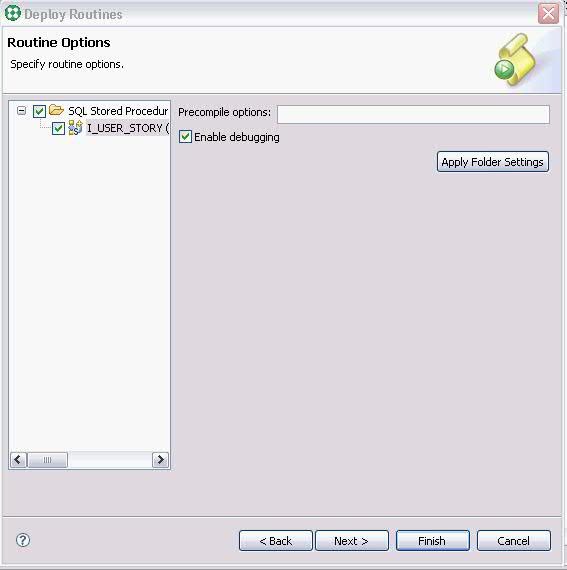
查看原圖(大圖)
圖 10. Debug 視圖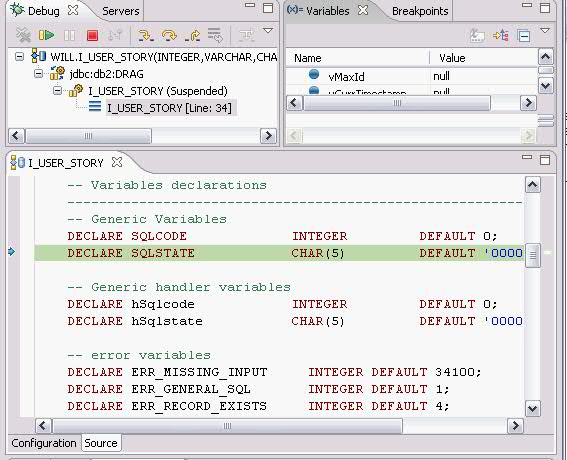
查看原圖(大圖)
通過單步執行,我們很快的就找到了出錯的代碼:
清單 4. 出錯的代碼
DECLARE vMaxId SMALLINT;
...
SELECT MAX(ID)+1 INTO vMaxId FROM USER_STORY;
原來,我們把 vMaxId 聲明成 SMALLINT, 然而隨著表 USER_STORY 中數據的增加,MAX(ID) 很快就超過了 SMALLINT 的最大值,這時我們再把 MAX(ID) 賦值給 vMaxId,就會出現溢出的錯誤。看來 I_USER_SOTRY 中有一個 bug 。我們應當把 vMaxId 聲明成 INTEGER 而不是 SMALLINT 。我們把修改後的代碼重新部署到數據庫中後,測試人員高興的告訴我們,新增 User Story 又重新可用了。
多虧 IBM Data Studio 的調試功能,使得我們很快的找到並修改了 bug 。
分析存儲過程性能
我們的系統順利的通過了功能測試,接下來我們要面臨性能測試的考驗了。
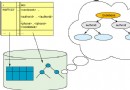
在性能測試時,測試人員抱怨說,在查詢 Work Item 的時候,系統的性能特別差。為了解決性能問題,IBM Data Studio 為我們提供了 Visual explain 。 Visual explain 可以幫助我們編寫出高效率的 SQL 語句。這對於存儲過程的性能調優非常重要。 IBM Data Studio 可以為我們提供圖形化的執行計劃:在 SQL 編輯器中選中你需要分析的 SQL 語句,單擊右鍵,選擇Visual Explain,然後我們就得到了如下圖所示的 SQL 執行計劃。
圖 11. SQL 執行計劃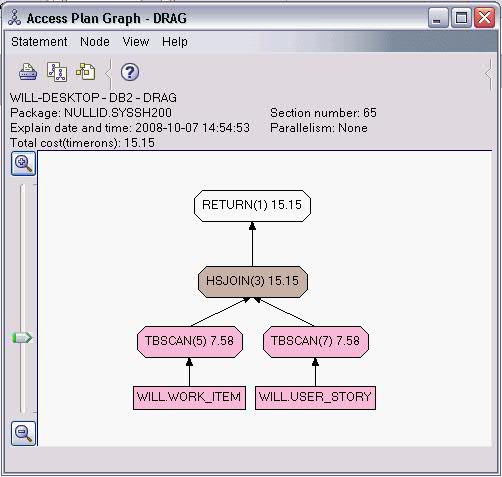
通過查看 Visual Explain,我們得出結論:由於 WORK_ITEM 表中的數據太多,對全表掃描花費太多的時間,我們應該建立合適的索引來提高性能。建立完索引後,我們再次執行 Visual Explain 。現在,其性能就提高了很多。
當然,本文中的例子只有兩個表,略顯簡單。在實際項目中,我們往往需要查詢多個表,查詢條件也會非常復雜。通過 Visual Explain 我們可以獲得 SQL 語句是否使用了索引,是否對某個表進行了多次掃描等信息。這些信息對優化我們的 SQL 語句非常有用。
Data Web Service
我們的系統經過嚴格的測試後,終於上線了。用戶對我們的系統非常滿意。但是他們提出了一個要求,希望我們的系統可以跟他們另外的一個業務系統進行集成。那個業務系統需要獲得 Work Item 的信息,但是它不能直接調用我們的存儲過程。經過討論,我們決定把我們的存儲過程發布成 Web Service,以方便其業務系統的訪問。
使用 IBM Data Studio,我們可以很方便的把存儲過程發布成 Web Service 。
右鍵單擊項目中的文件夾,選擇New Web Service...。
在彈出的頁面中輸入 Web Service 名稱 getWorkItem,點擊Finish。
把 Stored Procedures 文件夾下的 S_ITEM_OF_STORY 拖到 Web Service 文件夾下的 getWorkItem 上,這樣一個 Web Service 就構建完成了。
圖 12. 創建 web service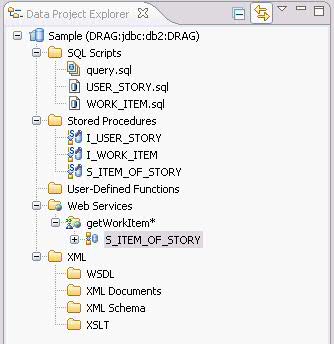
下面我們把這個 Web Service 到出為 war 包。
右鍵點擊 Web Service 文件夾下的 GetTasks,選擇Build and Deploy...,
在彈出的向導頁面中,指定 web server 的類型和 web service 的類型,點擊Finish, 完成 war 包的導出。
圖 13. 導出 war 包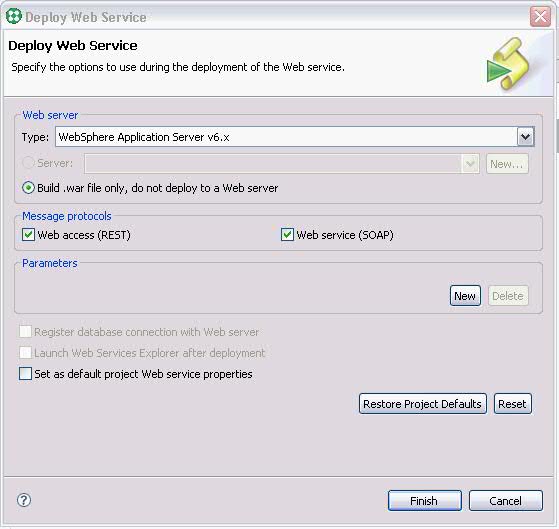
查看原圖(大圖)
結束語
文中的例子雖然簡單,但是包含了開發存儲的各個方面。可以看出 IBM Data Studio 對存儲過程的開發的支持是非常全面的。
IBM Data Studio 還提供了很多有用的功能,例如:通過圖形方式生成 SELECT 語句,可以生成存儲過程的 Unit Test 程序等等。相信讀者在使用 IBM Data Studio 的過程中會不斷發現一些非常有用的功能。希望本文能促使您開始使用 IBM Data Studio,並且享受 IBM Data Studio 給我們帶來的開發存儲過程的便利。
本文示例源代碼或素材下載
-