由於關聯規則挖掘是一項高度交互的任務,更好的一種解決方案是允許用戶直接從 Cognos 報告調用挖掘,甚至指定額外的參數。這種方式可被認為是一種動態挖掘。在本文中,您將了解這一點是如何實現的。
簡介
在處理大量數據時,很重要的一點是要理解不同實體間相互關聯的規律。通常,發現這些規律是個極為復雜的過程。關聯規則是一種十分簡單卻功能強大的、描述數據集的規則,這是因為關聯規則表達了哪些實體能同時發生。
關聯規則的傳統應用多見於零售業。比方說,有這樣的一個管理規則,即 “IF 雞蛋 AND 牛奶 THEN 糖”,它的意思是很多在購物時購買雞蛋和牛奶的顧客也會購買糖。這類規則甚至能夠從大型數據集中被有效發掘出來。借助 InfoSphere Warehouse,能夠方便地找到這些規則,本文會對此進行詳述。
在本系列的前一篇 文章 中,介紹了如何先在 InfoSphere Warehouse 構建一個挖掘模型,然後再使用 Cognos 公布結果。在某些情況下,這種做法效果還不錯。但是,通常,分析師希望能夠交互地影響分析,比如,對所找到的規則進行約束。每次當參數改變的時候,都要進入到 InfoSphere Warehouse DesignStudio,再返回至 Cognos,這非常不方便。相反,您可能更希望創建交互報告以便用戶能夠設置 Cognos 報告內的參數、在後台自動調用挖掘,然後將結果返回至 Cognos。本文將展示實現此目的的具體步驟。
首先,我們先來了解關聯規則挖掘的任務以及如何在 InfoSphere Warehouse 內實現此任務。然後,再來看看如何從 Cognos 動態調用數據挖掘。最後,研究此機制實際應用的一個例子。
市場購物籃分析及關聯規則挖掘
關聯規則及其應用
關聯規則描述了哪些項目經常同時發生。在這種上下文環境中,交易的概念就顯得極其重要。到商店的一次訪問就應被視作是一次交易,而在這次訪問期間所購買的所有商品都是同時發生的,被稱作是一個市場購物籃。當然,也可以將某顧客在一年內所有的購物視作是一次交易。這取決於所采用的規則。
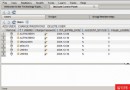
讓我們看一個簡單的例子。下表展示了商品的交易。每次交易都包含顧客在一次到店期間所購買的所有商品。
圖 1. 示例交易
可以看出,pc 的購買次數很頻繁。而 pc 和顯示器的組合則占到了所有交易的 20%。另外,在購買了 pc 和顯示器的情況中,有 50% 還會購買鼠標。如果我們采用如下規則,即 [PC, Monitor]->Mouse,其中 [Pc,Monitor] 是主體,而 Mouse 則是頭或目標,那麼同時涉及主體和頭的交易數量除以所有交易的數量得到的就是 support (20%)。 這種測量方法能告訴我們該規則在數據內發生的頻率。但它並不能告所我們該規則的准確度。confidence 描述了規則的主體和頭在交易內同時發生次數的百分比。這能給出有關規則准確度的信息。關聯規則挖掘要求用戶要能說明最少 support 和 confidence。算法還能准確表述出滿足這些標准的項目和規則的組合。
關聯規則挖掘的應用場景很多。其中最為突出的就是我們已經提到過的零售業。關聯規則可用來進行超級市場內的商品擺放,以便經常同時購買的產品的位置能夠彼此靠近。更為重要的是,關聯規則還可用在電子商務中,通過向用戶建議他們可能感興趣的其他商品來進行潛在的交叉銷售。另一個應用的領域是健康醫療,利用關聯規則找出經常同時發生的健康問題,以便診斷出患一種疾病的患者還能進行額外的檢查,從而判斷該患者是否存在其他與此疾病經常連帶發生的身體問題。其他的應用領域還包括侵入檢測、Web 日志分析、數據庫訪問模式等等。
序列規則是關聯規則的一種,與關聯規則稍有不同。序列規則不只能表明哪些實體同時發生,而且還能表明就其出現的時間而言這些事件是如何關聯的。比如,序列規則可能會表明先購買筆記本再購買筆記本包的顧客,很有可能在 6 個月內還會購買一個便攜鼠標。本文所展示的大部分內容也都適用於序列規則。
InfoSphere Warehouse 內的關聯規則挖掘
對關聯規則挖掘的調用是通過調用一個存儲過程完成的,與 InfoSphere Warehouse 內的所有其他挖掘操作無異。受支持的交易格式各異,在本文的後續章節,我們將使用如下所示的這種交易格式。
圖 2. 交易表
要執行挖掘,必須先告知算法,在哪些列能找到實際的商品,在哪一列包含如何將商品組合成交易的相關信息。在本例中,此列的名字是 TRANSID,用途是根據每個顧客購物的情況對商品進行組合。我們也可以使用顧客 id 作為組的 id 來根據顧客購物的完整歷史尋找關聯。使用 SQL 命令 IDMMX.BuildRuleModel 或 DesignStudio 內的 Associations 操作符,就能調用挖掘。但必須提供模式名、交易表名、組列、最小 support 和 confidence 以及最大的規則長度。請注意,商品是由 id 描述的。商品的名稱可以通過一個名稱映射表添加,該表包含商品 id 及相應的描述。此外,還有很多其他的可選項,比如分類法、商品重量等。更多細節,請參考 InfoSphere Warehouse 教程。
與分類或集群模型類似,規則模型也可以在 DesignStudio 被可視化。我們還可以將此模型內包含的信息提取到表內,這與 集群的情況是一樣的。通過命令 IDMMX.DM_getRules 或 DesignStudio 內的 Rule Extractor 操作符可實現此目的。在結果集內,每個記錄包含一個規則,並具有如下信息:
head
body
confidence
support
lift
length
而包含被提取後的規則的表則非常類似於:
圖 3. 規則表
查看原圖(大圖)
下一個章節將展示如何將這些信息傳遞給 Cognos 以便以一種簡便的方式對之進行可視化。
從 Cognos 調用挖掘過程
在上篇文章中,您了解了通過將 DB2 存儲過程作為 Query Subject 包括到 Cognos Metadata 是能夠從 Cognos Reporting 調用 DB2 存儲過程的。這樣做會使存儲過程在報告運行時就能執行,而後,您就能使用它來從已有的 PMML 挖掘模型提取信息。
在本文中,我們還會更進一步,利用 InfoSphere Warehouse Mining SQL API 在參數化了的存儲過程內動態創建一個挖掘模型。該存儲過程之後會從此模型提取信息並將其返回給 Cognos Report。
實際上,生成這些規則並將它們傳遞給 Cognos 的過程所涉及到的調用只有兩個。一個調用在數據庫內構建規則模型,另一個調用提取這些規則並將其作為結果集返回。不過,創建模型的調用是一個不具有任何返回值的存儲過程。要從 Cognos 調用挖掘,最好是在對數據庫的單一調用內執行這二者。
以此為目的,基本的想法是創建一個用戶定義組合函數,此函數首先調用模型創建過程,之後再提取規則並將這些規則作為結果集返回。這個過程如下圖所示。
圖 4. 用於動態挖掘的用戶定義組合函數
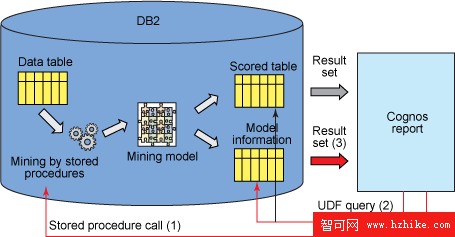
此外,也可以手工創建這個組合存儲過程。通過 InfoSphere Warehouse 還可以可視地創建它。稍後,將通過一個例子給出實現這一目的的全過程。
使用 InfoSphere Warehouse 創建復雜的挖掘存儲過程
首先,必須創建復合挖掘邏輯。InfoSphere Warehouse 包含了 Mining Editor,可用來圖形式地設計挖掘流(挖掘命令的序列)。它們可以在 DesignStudio 內執行,也可以被部署到 InfoSphere Warehouse Administration Console 以便定時運行。但是由於所有挖掘操作都基於的是 SQL,所以,也可以從挖掘流生成一個 SQL 腳本(不包括某些操作符,比如 Mining Visualizers 和 Text analytics,它們沒有包含在此數據內)。像 Association Operator 和 Rules Extractor(用在如下的例子中)這樣的挖掘操作符均被轉變為 SQL。Mining Editor 的 “Generate SQL Code” 命令生成代表挖掘流的 SQL DDL 並被包括在存儲過程內,挖掘流的結果表作為此存儲過程的結果返回。以下的示例向您展示了這一點是如何做到的。
創建復合挖掘邏輯之後,下一個任務是創建、部署並測試想要創建的這個 SQL 存儲過程。InfoSphere Warehouse DesignStudio 包含了 Data Development 項目的 Data 透視圖,提供了對 Java 和 SQL 存儲過程以及用戶定義函數創建的支持。由向導負責創建一個模板存儲過程,而您則可直接從 DesignStudio 對之進行部署和測試。
下面的示例顯示了如何創建挖掘流程,同時創建關聯模型並從中提取規則。之後,了解如何從此流程創建 SQL 代碼。在下一步中,這種方法被用來從這些 SQL 代碼創建一個存儲過程。我們會將輸入參數添加到這個存儲過程以便之後在 Cognos Report 內設置,我們還要參數化所創建的這個挖掘模型。這些從關聯模型中提取出來的規則由此存儲過程返回並導入到 Cognos 作為查詢主題。最後,我們還要學習如何創建一個簡單的 Cognos 報告來顯示產品的收入列表和允許穿透鑽取這些產品的相關關聯規則。
使用 Cognos Report 內的動態數據挖掘結果:一個來自零售業的示例
這個示例中,我們將對零售交易數據進行市場購物籃分析。數據代表的是來自某個零售店的市場購物籃(交易)。第一個表中包含用來標識單個市場購物籃的交易 ID 以及產品 ID。要獲得有意義的結果,需要為產品 ID 應用一個名稱映射表。
在 InfoSphere Warehouse 自帶的示例中可以找到此表。要將此表導入數據庫:
打開 DB2 命令窗口
進入 InfoSphere Warehouse 的安裝目錄
導航到 SQLLIB\samples\dwe\ModelingDB2 子目錄
連接到工作數據庫(在本示例中,為示例數據庫 DWESAMP: db2 CONNECT TO DWESAMP)
執行 db2 -tvf retailImport.db2 命令將此示例表導入到用戶模式(在我們的示例中,這被叫做 IMINER)
再創建一個新模式,即 ASSOC,通過 db2 CREATE SCHEMA ASSOC 命令可將其用在後面的示例中
此次分析的目的是提取表單的關聯規則:
Toy car + Flash light => Battery (support: 3%, confidence: 83%)
上述的規則表明了在玩具汽車和手電筒的購買案例中,有 83% 的顧客還同時購入了電池。購買了所有這幾樣產品的情況占所有購物籃的 3%(也即 support)。
規則並不是預先計算的,計算由 Cognos 報告觸發。在本示例中,有一個針對每個產品的收入列表,借助它就能夠穿透鑽取特定產品的關聯規則。此外,還可以定義這些規則的最小 support 及長度。之後,根據需要,對這些規則繼續計算並通過另一個報告返回給用戶。比如,這些規則可被用來進行商店內的產品的合理擺放以提高營業收入。
在 InfoSphere Warehouse DesignStudio 中創建關聯規則
首先,必須創建一個關聯規則模型,該模型被存儲為 PMML,從中可以提取這些規則並將其放入一個數據庫表以供日後的 Cognos 訪問。要獲取更多關於 PMML 的信息,請參考 PMML 標准 Web 站點。
創建一個 Data Warehouse 項目:
在 Project Explorer 中,單擊右鍵並選中 New > Data Warehouse 項目,如圖 5 所示。
圖 5. 創建一個 Data Warehouse 項目
在下面的向導中,鍵入項目名稱,比如 “AdvancedAnalytics” ,然後按下 Finish。
創建一個空的挖掘流程:
展開我們剛剛創建的這個項目。
右鍵單擊 Mining Flow 文件夾。選中 New -> Mining Flow。
在後面的向導中,鍵入 AssocFlow 作為挖掘流程的名稱。
在本例中,我們將開始處理這個數據庫,因此,保持默認並按 Next。
選中 DWESAMP 數據庫(或您所選中的那個數據庫)並單擊 Finish。
創建挖掘流程:
Mining Flow 編輯器打開。在 Mining Flow 編輯器的右側,可以看到一個帶操作符的調色板。有了這些操作符,就能通過將其拖放到編輯器的 canvas 來構建一個 Mining Flow。
圖 6. Design Studio 中的挖掘流
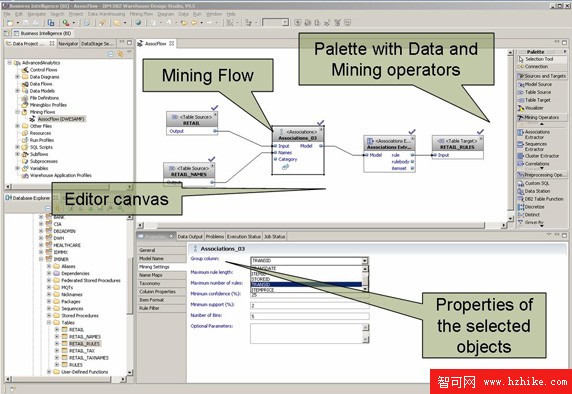
查看原圖(大圖)
要創建關聯規則挖掘模型並將這些規則提取到數據庫表,可以執行如下操作:
在調色板中,可以找到 Sources 和 Targets 區域。選中一個 Table Source 操作符並將其拖到編輯器上。
在表選擇對話框中,展開 IMINER 模式(或是默認模式)並選擇 RETAIL,然後按下 Finish。
用一個名為 RETAIL_NAMES 的表創建另一個 Table Source 操作符。
在這個調色板中,找到 Mining Operators 區域。選中一個 Associations 操作符並將其拖到編輯器上。
把 RETAIL 表的 Output Port 連接到 Associations Input Port,同時將 RETAIL_NAME 表的 Output Port 連接到 Associations Names Port。
選中 Associations 操作符。
在挖掘編輯器下面的屬性選項卡內,選中左側的 Mining Settings 選項卡。
在 Group 列選擇列表中,選中 TRANSID。具有相同 TRANSID 的所有產品 (ITEMID) 均被放入一個市場購物籃內。
現在,選中 Name Maps 屬性頁並將 “Item Id Column” 設為 “ITEMID”,將 “Item Name Column” 設為 “DESCRIPTION”。這兩列都來自於 RETAIL_NAMES 表,該表是一個名稱查閱表。
進入 Column Properties 頁面。將除 ITEMID 列外的所有輸入列的 “FIEld Usage Type” 都設為 Inactive ,ITEMID 列則被設為 Active。
在 “FIEld Usage Type” 的右側,可以為列指定 Name Mapping。對於 ITEMID 列,指定名稱映射為 Names。Names 是輸入端口的名稱,該輸入端口被連接到名稱映射表 RETAIL_NAMES。
從 Mining Operators 下的調色板,可以找到一個 Associations Extractor 操作符。將其拖到編輯器上並將 Associations 操作符的 Model 輸出端口連接到提取器的 Model 輸入端口。這個提取器操作符能從 PMML 模型(由 Associations 操作符創建)提取關聯規則並通過關系表結構提供這些規則。
最後,我們還必須將這些提取出的關聯規則存儲到一個物理表中。要做到這一點,右鍵單擊提取器的 “rule” 輸出端口並選中 Create Suitable Table。
將表名稱設置為 RETAIL_RULES,對於模式,選擇這個 RETAIL 表所在的默認模式。按下 Finish。
針對 “RETAIL_RULES” 的一個表目標操作符現在應被顯示在挖掘流中。要想只獲得針對每次運行的當前規則,選中表目標操作符屬性中的 Delete previous content 復選框。
保存這個挖掘流。
至此,挖掘流就已經准備好,可以執行了。
執行這個挖掘流:
這個流生成了一個包含了關聯規則的模型並將此模型作為 PMML 模型存儲在數據庫中。之後,這些規則被提取到一個數據庫表以便於日後從 Cognos 內訪問。在編輯器下方的視圖中,Execution Status 選項卡被選中並且在這個視圖的右側,還可以看見最後一個操作符(即 Target Table 操作符)的表輸出。此表顯示了所提取的這些規則,每個規則都有一個 ID、Head、Body 信息以及有關的統計數據。可以通過右鍵單擊 Associations 操作符並選中 Open Model 來直觀地查閱這些關聯規則。
將關聯規則挖掘流部署為 DB2 存儲過程
稍後,在 Cognos 中,您可能會想用用戶定義的輸入來動態調用前面設計的這個挖掘流。如前面提到過的,此輸入是這些規則的最小 support 及規則的長度。為了實現動態調用,需要創建一個存儲過程,它接受這兩個參數並通過此用戶輸入調用挖掘流。
在 Data Development 項目中創建一個新的存儲過程:
要創建 Data Development 項目,按如下操作:
在 “Data Project Explorer” 內右鍵單擊,並選中 New ->Data Development Project。若找不到這個 Data Development 項目,則選擇 Project . . . 並在整個 ect 列表中查找。
指定名稱為 Assoc Stored Procedure 並按下Next。
選擇 Use an existing connection 並選中零售表被導入其中的這個數據庫。單擊 Finish。
如果系統詢問您是否想切換這個透視圖,請選擇 No。
要創建這個存儲過程,請如下操作:
展開這個新項目並右鍵單擊 Stored Procedure 文件夾。選中 New" -> Stored Procedure。
將過程的名稱設為 “ASSOC_PROC” 並選中 SQL 作為此過程的語言。單擊 Next。