集群(cluster)就是一組互相連接的服務器,它們作為一個整體向用戶提供服務,每個服務器都是集群系統的一個節點。在用戶看來,集群提供的服務與單個服務器提供的服務沒有區別。
HA 集群(High Availability, 高可用性集群)是為了提高系統的可用性,以便在單個節點出現故障的時候,持續滿足用戶的需求的集群系統。
本章主要介紹 HA 集群的原理及配置實例。

本章內容:
HA 集群概述
在 Linux 環境下搭建雙機熱備環境
難點與重點:
在 Linux 環境下搭建雙機熱備環境
2.1 HA 集群概述
集群(Cluster),就是一組相互連接的計算機作為一個整體向用戶提供服務。集群中的每個計算機都是一個節點,集群中的節點可以自由增刪而不會影響提供給用戶的服務。多台計算機整合起來形成的集群,或者提供數倍於單台計算機的性能,或者提供更高的可用性。
HA 集群(High Availability, 高可用性集群)是集群中較常見的一種,當硬件或軟件系統發生故障時,運行在該集群系統上的數據不易丟失,而且能在盡可能短的時間內恢復正常運行。
雙機熱備是 HA 集群中較常見的一種解決方案,它特指兩台服務器組成的 HA 集群。雙機熱備按工作中的切換方式可以分為:主 - 備方式(Active-Standby 方式)和雙主機方式(Active-Active 方式)。主 - 備方式即指的是一台服務器處於某種業務的激活狀態,另一台服務器處於該業務的備用狀態。而雙主機方式即指兩種不同業務分別在兩台服務器上互為主備狀態。
在雙機熱備的兩台服務器中,一台作為主服務器,另外一台作為備用服務器。通常情況下由主服務器提供服務,當主服務器出現故障時,備用服務器接管主服務器的工作。通過這種方式,雙機熱備提供給用戶更高的可用性。雙機熱備的實現方式主要有兩種:同步可用方式和異步可用方式。同步可用方式通過在雙機間共享存儲(磁盤陣列)來保證雙機數據的一致性;異步可用方式通過數據復制來保證雙機間數據的同步性。下面分別介紹同步可用方式和異步可用方式的基本原理。
2.1.1 同步可用
同步可用的雙機熱備方案(見圖 2.1)由主 / 備用服務器、共享的物理存儲器(含有數據庫文件)以及集群管理軟件組成。通常情況下,共享的物理存儲器中的數據庫文件掛靠在主服務器上,通過主服務器為用戶提供數據;當主服務器出現故障的時候,集群管理軟件將物理存儲器的所有權從主服務器轉移到備用服務器上,並在備用服務器上啟動數據庫服務。這樣,提供給用戶的服務只是產生很短一段時間的延遲,便能恢復正常。
圖 2.1 同步可用的雙機熱備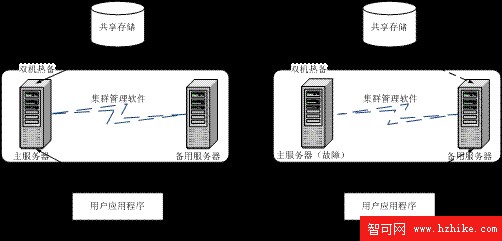
下面對該解決方案的幾個概念進行說明:
主服務器和備用服務器。
主服務器和備用服務器是建立雙機熱備的基本條件。兩個系統上的數據庫服務器共享同一個數據庫文件。通常情況下,數據庫文件掛靠在主數據庫服務器上,用戶連接到主服務器上進行數據庫操作。當主服務器出現故障時,備用服務器會自動連接數據庫文件,並接替主系統的工作。用戶在未告知的情況下,通過備用數據庫連接到數據庫文件進行操作。等主服務器的故障修復之後,又可以重新加入集群。
故障檢測。
故障檢測是實現雙機熱備的關鍵技術之一。故障檢測軟件同時運行在主服務器和備用服務器上,並通過集群的節點間傳送的數據包來監視主服務器和備用服務器的狀態。當備用服務器上的故障檢測軟件檢測不到主系統發送來的信號時,便認為主服務器出現了故障。此時,故障檢測軟件會協助備用服務器進行數據源移動(從主服務器移動到備用服務器)。當主服務器的故障被排除重新加入集群時,故障檢測軟件檢測到這一變化,可以重新執行數據源移動(從備用服務器移動到主服務器)。
數據源移動。
當主服務器出現故障時,在用戶覺察不出的情況下,集群管理軟件將數據源從主服務器上卸載下來並掛靠到備用服務器上,同時啟動備用服務器上的服務,繼續向用戶提供服務。而當主服務器重新開始運行後,集群管理軟件可以執行同樣的操作,將數據源移動到主服務器上,並啟動主服務器的服務,停止備用服務器上的服務。
2.1.2 異步可用
獨立存儲雙機方式是通過支持映像的軟件,將數據能實時復制到另一台服務器上。這樣,同樣的數據就在兩台服務器上各存在一份,如果一台服務器出現故障,數據能及時轉換到另一台服務器。
獨立存儲雙機方式的解決方案主要有 3 種:數據復制選項、日志傳送選項和高級存儲選項。。
1. 數據復制選項
數據復制選項(見圖 2.2)捕獲主服務器上源數據庫的變更,並將之應用到備用數據庫中。DB2 數據復制選項的實現包括兩部分:捕獲變更和應用變更。其實現過程為:
(1)在源數據發生變化時,數據會被記錄到日志文件中。
(2)當主服務器上定義的源表發生數據變化時,被主服務器寫入日志文件;
(3)捕獲進程監控到主服務器上事務日志的變化,從中獲取源表的所有更改,並將這些變更寫入到預訂變更表中;
(4)應用變更進程定期讀取預訂變更表,並將其中的變更應用到備用數據庫上的目標表中。
圖 2.2 數據復制選項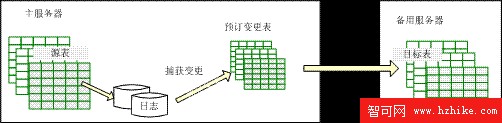
2. 日志傳送選項
日志傳送選項(見圖 2.3)是將整個日志文件復制到備用服務器上,備用服務器通過日志的不斷前滾會隨著主服務器的變化而變化。在主服務器發生故障時,備用服務器前滾完最新的日志數據後,將數據庫置於聯機方式。
所謂前滾(roll forward),是指應用數據庫或日志備份中的全部已完成的事務,以將數據庫恢復到某個時間點,相當於重新執行一遍“事務日志文件中的記錄”和“所做修改尚未寫入磁盤的事務”的每一步操作。由於主服務器傳送過來的事務日志在備用服務器上還沒有被應用過,所以執行前滾以將備用數據庫的狀態與主數據庫同步。
什麼是回滾?
與前滾相對應,回滾(roll back)是指刪除由一個或多個部分完成的事務執行的更新。主要用於在應用程序、數據庫或系統錯誤後還原數據庫的完整性。
圖 2.3 日志傳送選項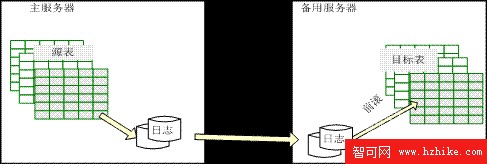
3. 暫掛 I/O 選項
暫掛 I/O 選項(如圖 2.4)是 DB2 提供的一個高級存儲選項,它創建主數據庫的分割鏡像並將其安裝在備用服務器上,以實現主 / 備用服務器的同步。
在創建分割鏡像期間,為了防止在主服務器上出現數據的部分更新,DB2 UDB 暫時掛起主服務器上的數據庫 I/O,然後快速地創建數據庫副本,再對主數據庫取消 I/O 暫掛。最後,分割鏡像被應用到備用數據庫上,實現了備用服務器與主服務器數據的一致性。
什麼是分割鏡像?
分割鏡像(split mirror)是具有同一性、獨立性、瞬時性的磁盤卷拷貝,分割鏡像可被應用到其他 DB2 服務器上。
圖 2.4 暫掛 I/O 選項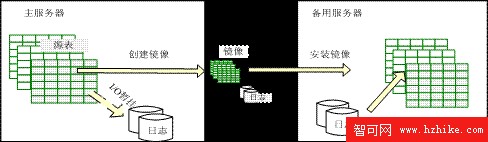
2.2 HA 雙機配置實踐
本節介紹一個利用 heartbeat 軟件實現的雙機同步熱備(雙機異步熱備的案例將在第 3 章中介紹)。heartbeat 是開源項目 High Availability Linux 提供的集群軟件包之一,它提供了所有集群系統所需要的基本功能,比如啟動和停止資源、監測集群中系統的可用性、在集群中的節點間共享 IP 地址等。
2.2.1 構成
本節介紹的雙機熱備包括兩個數據庫服務器以及存放在共享存儲器中的數據庫文件。在本案例中,主 / 備用服務器共享同一份數據庫文件。通常情況下,數據庫文件掛在主服務器上,供主服務器進行訪問。當主服務器發生故障時,數據庫文件轉而掛在備用服務器上,通過備用服務器提供數據,以保證服務的可用性。
圖 2.5 雙機熱備案例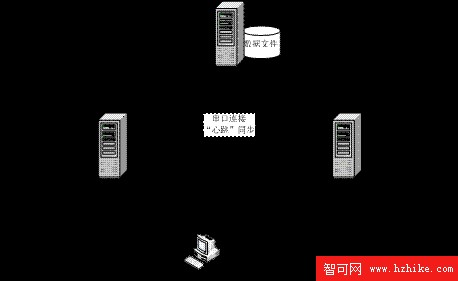
該集群的詳細構成(如圖 2.5 所示)為:
Primary 節點,主 DB2 數據庫服務器,IP 地址為 192.168.168.131,並通過端口 /dev/ttyS0 與 Standby 節點相連;
Standby 節點,備用 DB2 數據庫服務器,IP 地址為 192.168.168.135,並通過端口 /dev/ttyS0 與 Primary 節點相連;
Nfsserver 文件服務器,提供 NFS 文件共享服務的文件服務器,IP 地址為 192.168.168.129;
串口心跳線,為了保證主 / 備用數據庫“心跳”一致,heartbeat 軟件用串口連線來監測多個節點的運行狀態;
什麼是心跳線?
心跳線是用於連接主機和備用機的連線。集群管理軟件通過心跳線來監測集群中節點的運行狀態。
集群 IP,集群的虛擬 IP,DB2 客戶端通過連接虛擬 IP 來得到服務,IP 地址為 192.168.168.100;
DB2 客戶端,連接集群系統的 DB2 數據庫客戶端;
以太網絡,節點間用來連接的 TCP/IP 網絡。
為了安裝方便,本案例節點的 IP 地址整理如表 2.1 所示(Linux 下查看 IP 的命令為 ifconfig)。
表 2.1 IP 地址
節點名 說明 IP 地址 Primary 主服務器 192.168.168.131 Standby 備用服務器 192.168.168.135 Nfsserver NFS 文件服務器 192.168.168.129 集群 IP 集群虛擬地址 192.168.168.100
2.2.2 配置
1 .設置 IP 表(/etc/hosts)
hosts 文件用於將主機名稱映射到 IP 地址。為了方便後面的連接,將三個物理節點的主機名與其 IP 間建立映射。打開 /etc/hosts 文件,將各個節點的 IP 地址與節點名追加進去(在三台機器上都要做同樣的配置)。編輯完成的 hosts 文件如圖 2.6 所示。
Hosts 是什麼文件?
Hosts,域名解析文件。對於要經常訪問的 IP 地址,我們可以通過在 Hosts 中配置主機名和 IP 的映射關系,這樣以後訪問的時候只要輸入這個服務器的名字就行了。
圖 2.6 /etc/hosts 設置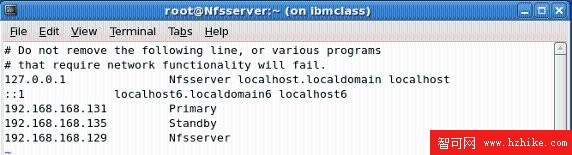
查看原圖(大圖)
保存設置後,打開一個 Terminal 然後執行下面的命令以確認節點名與 IP 地址的映射結果。
# ping Primary
# ping Standby
# ping Nfsserver
2 .建立串口連接
高可用性集群系統中,當主節點發生故障時,備用節點要及時監測到這個故障並接替主節點的工作。因此,主備用節點的互相監聽成為集群系統中必不可少的功能。Heartbeat 軟件可以通過多種方式監聽主 / 備用服務器,串口連接是其中比較簡單的一種。
用一根串行線將 Primary 和 Standby 兩個節點連接起來,並確認連接狀況。
在 Standby 節點上執行命令:
# cat < /dev/ttyS0
在 Primary 節點上執行命令:
# echo "Connection test" > /dev/ttyS0
上面的命令是從 Primary 節點上通過串行端口,發送消息給 Standby 節點。如果在 Standby 上能得到該消息,則證明串口連接成功。如圖 2.7 所示。
圖 2.7 串口連接
查看原圖(大圖)
3 .配置 NFS 文件服務器
在本解決方案中,NFS 文件服務器用於存放 DB2 數據庫文件。通常情況下只有主數據庫節點連接 NFS 文件服務器,進行數據庫的讀寫操作。當主數據庫服務器出現故障時,heartbeat 軟件會斷開 NFS 文件服務器與主節點間的連接,而連接到備用服務器上。同時備用節點的數據庫服務器也啟動起來,繼續為客戶提供服務。
什麼是 NFS ?
NFS(Network File System)網絡文件系統,用於設置 Linux/Unix 系統之間的文件共享。NFS 既是一種文件系統,也是一個網絡協議。
Nfsserver 節點的配置過程如下:
(1)在 Nfsserver 上創建用於共享的目錄 /database:
# mkdir /database
(2)修改 /etc/exports 文件,以說明要共享的目錄和共享的方式。/etc/exports 是一個訪問控制列表,定義了可以被 NFS 客戶端訪問的路徑。/etc/exports 文件的格式為:
[ shared_path ] [ nfs_clIEnt (parm,parm)]
其中:
shared_path:NFS 服務器上被共享的目錄。
nfs_client:可以訪問共享目錄的 NFS 客戶端,當 nfs_clIEnt 省略時,代表可被任意客戶端訪問。
parm:可選的訪問參數,常用的訪問參數有:
ro:只讀訪問;
rw:讀寫訪問;
root_squash:root 用戶的所有請求映射成如 anonymous 用戶一樣的權限(默認);
no_root_squas:root 用戶具有根目錄的完全管理訪問權限。
本例中,如下設置 /etc/exports 文件(如圖 2.8),對 Primary 和 Standby 節點賦予對 /database 的讀寫權限。
圖 2.8 配置共享的目錄
查看原圖(大圖)
(3)啟動 NFS 服務。
# /etc/rc.d/init.d/nfs restart
如果 NFS 服務已經在運行,也可以不用重新啟動 NFS 服務,直接采用 exports 命令即可重新導出共享目錄。該命令格式如下:
exportfs [-aruv]
其中:
-a :全部 mount 或者 unmount /etc/exports 中的內容。
什麼是 mount ?
如果想在 Linux 服務器中訪問文件系統的資源,就要用 mount 命令來實現。mount 的基本語法為:mount [- 參數 ] [ 設備名稱 ] [ 掛載點 ]。
-r :重新 mount /etc/exports 中分享出來的目錄。
-u :umount 目錄。
-v :在 export 的時候,將詳細的信息輸出到屏幕上。
例如,可以執行下面的命令發布共享目錄。
# /usr/sbin/exportfs – a
(4)客戶機配置。分別在 Primary 和 Standby 上掛載該共享文件。
# mkdir /database
# mount Nfsserver:/database /database
如果執行 mount 時收到如圖 2.9 所示的消息,說明 NFS 服務未啟動,可以執行 /etc/rc.d/init.d/nfs restart 來重啟 NFS 服務。
圖 2.9 NFS 服務重啟動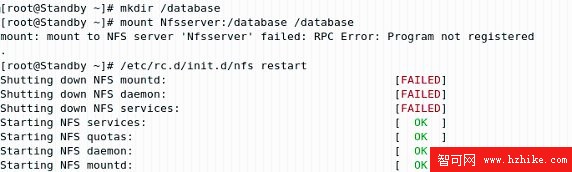
查看原圖(大圖)
執行 df 命令確認 Nfsserver/database 被正確掛載。df 命令用來檢查文件系統的磁盤空間占用情況。可以利用該命令來獲取硬盤被占用了多少空間,目前還剩下多少空間等信息。效果如圖 2.10 所示。
圖 2.10 NFS 文件共享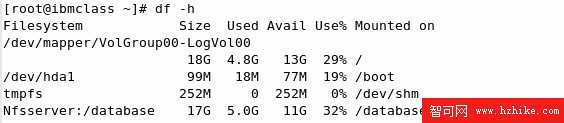
查看原圖(大圖)
4 .創建數據庫
(1)創建用戶(兩個節點上都要創建)。DB2 用戶的創建,既可以使用第 1 章介紹的圖形管理工具,也可以使用命令行。在 Linux 命令行創建 DB2 用戶的命令為 useradd。useradd 命令的基本語法為:
useradd [-d home_dir]
[-g initial_group]
[-m ]
[-u uid]
[username]
其中:
-d home_dir:新賬號每次登入時所使用的主目錄。
-g initial_group:使用者所屬的群組名,該群組名必須是既存的。
-m:使用者目錄如不存在則自動建立。
-u uid:使用者的 ID 值,必須唯一的 ID 值。
Username:用戶賬號。
本例中,要創建 db2ha1 用戶,其所屬群組為 db2iadm1,主目錄為 /home/db2ha1。 該命令如下所示:
# useradd – u 504 – g db2iadm1 – m – d /home/db2ha1 db2ha1
(2)DB2 用戶創建完成後,接下來在兩個節點上創建 DB2 實例 db2ha1。
# db2icrt – u db2fenc1 db2ha1
(3)在 Primary 上以 db2ha1 登錄,啟動 db2ha1 實例,然後創建數據庫 HADB,路徑為 /database。其中,/database 路徑是 Nfsserver 節點上 /database 目錄的本地映射。
# su – db2ha1
$ db2start
$ db2 create database HADB on /database
創建成功後,斷開到 HADB 的連接,並停止 db2ha1 實例。
# db2 connect reset
# db2stop
(4)在 Standby 節點上,以 db2ha1 登錄,並編目 /database 目錄下的 HADB 數據庫。
# su – db2ha1
$ db2start
$ db2 catalog database HADB on /database
編目 HADB 後,用 db2 connect 命令連接到 HADB 上以確認創建是否成功。如果收到下面的信息,表示編目成功(如圖 2.11)。
圖 2.11 在 Standby 上連接 HADB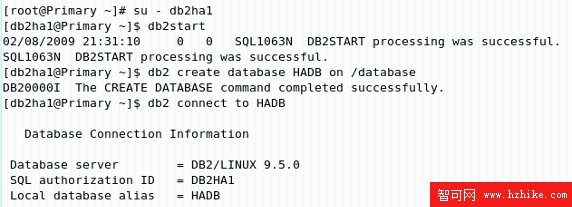
查看原圖(大圖)
斷開連接,停止 DB2 管理服務器。
$ db2 connect reset
$ db2stop
5 .配置集群軟件
(1)下載 Heartbeat(見圖 2.12)。登錄 http://clusterlabs.org,針對相應的 Linux 版本選擇 Heartbeat 的不同版本(本文中的 Linux 系統是 Cent OS 5.0.2)。
圖 2.12 下載 Heartbeat
查看原圖(大圖)
(2)安裝依賴包。在 Heartbeat 安裝之前,要先安裝兩個軟件包:perl-TimeDate 和 perl-MailTools。
perl-TimeDate 是用來提供時間日期函數的 perl 模塊;perl-MailTools 是一組 mail 相關的 perl 模塊。由於 Heartbeat 的腳本是用 perl 腳本書寫的,所以需要安裝這兩個軟件包。
#yum install perl-TimeDate
#yum install perl-MailTools
yum 是什麼?
yum(Yellowdog Updater, ModifIEd)是一個軟件管理系統,它能自動解決安裝包的依賴性問題,使得添加 / 刪除 / 更新軟件包更加方便。關於軟件包的依賴性問題,可以參考下面使用 rpm 來安裝 Heartbeat 的過程。
(3)安裝 Heartbeat。因為安裝包之間的依賴關系,按照圖 2.13 所示順次安裝 Heartbeat。
圖 2.13 Heartbeat 安裝
查看原圖(大圖)
(4)拷貝 /usr/share/doc/packages/heartbeat 路徑下的示例文件 ha.cf,authkeys 和 haresources 文件至 /etc/ha.d。
01 # cd /usr/share/doc/packages/heartbeat
02 # cp authkeys /etc/ha.d
03 # cp haresources /etc/ha.d
04 # cp ha.cf /etc/ha.d
不同版本或安裝方式下,Heartbeat 示例文件的路徑可能有所不同,可用“rpm – q”命令來確定該文件的位置(如圖 2.14)。
圖 2.14 查詢安裝位置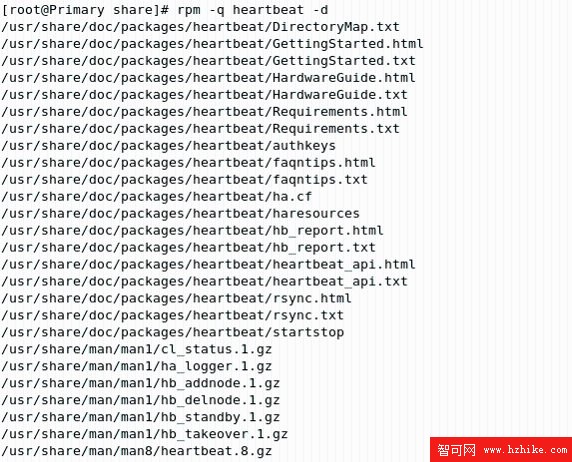
查看原圖(大圖)
(5)配置 authkeys 文件。/etc/ha.d/authkeys 文件定義了集群的認證密鑰,集群中的所有節點必須有相同的認證密鑰。編輯 /etc/ha.d/authkeys 文件,取消下面兩行內容前的注釋符號:
## /etc/ha.d/authkeys
auth 1
1 crc
其中:
auth 1:指示系統用關鍵字 1 對應的加密方式(本例中關鍵字為 1 的加密方式為 crc)來加密送出的數據。
1 crc:定義關鍵字 1 的加密方式為 crc。
Heartbeat 的加密方式
Heartbeat 目前支持 3 種加密方式:crc,sha1 和 md5。其中 crc 的方式最簡單,安全性也最低。
確保 authkeys 文件只能由 root 讀取,將該文件的屬性設為 600。
# chmod 600 authkeys
(6)配置 ha.cf 文件。/etc/ha.d/ha.cf 文件定義了 Heartbeat 集群中的節點,以及 Heartbeat 用來監測系統運行狀況的端口等配置。ha.cf 文件中可配置的內容如下:
use_logd on/off:是否由 Heartbeat 記錄日志文件。
serial /dev/ttyS0:使用串口連線監聽集群節點的運行狀態。如果不使用串口 Heartbeat,則必須使用其他的設備文件代替 /dev/ttyS0(如 bcast 等)。
bcast eth1:表示在 eth1 接口上使用廣播監聽集群節點的運行狀態。
node linuxha1.Linux-ha.org:必選項,集群中機器的主機名。根據集群中節點的數據,可以有多行。節點的主機名可以通過在 Terminal 中執行“uname – n”獲得。
uname 是什麼?
uname 是顯示系統信息的命令。uname – n 顯示在網絡上的主機名稱。
keepalive 2:設定 Heartbeat 之間的時間間隔為 2 秒。
auto_failback on:在主機發生故障(failover)之後,從節點接管主節點的所有資源。當 auto_failback 設置為 on 時,一旦主節點重新恢復聯機,將從節點取回所有資源。若該選項設置為 off,主節點便不能重新獲得資源。
crm yes/no:是否使用 crm(集群資源管理器)來管理集群資源。
本例中,/etc/ha.d/ha.cf 文件的相關設置如下:
01 ## /etc/ha.d/ha.cf
02 serial /dev/ttyS0
03 auto_failback on
04 node Primary
05 node Standby
06 use_logd yes
07 crm yes
其中,node 中指定的 Primary/Standby 已經在 /etc/hosts 中定義過了。
(7)配置 Haresources 文件。Heartbeat 使用 Haresources 配置文件決定它首次啟動時做些什麼。Haresources 文件的內容為:
node-name network-config <resource-group>
其中:
node-name 是主服務器的節點名,取值必須匹配 ha.cf 文件中 node 選項設置的主機名中的一個,node 選項設置的另一個主機名成為從節點。
network-config 用於網絡設置,包括指定集群 IP、子網掩碼、廣播地址等。
resource-group 用於設置 Heartbeat 啟動的服務,該服務最終由雙機系統通過集群 IP 對外提供。Resource-group 中包含了存在於 /etc/init.d 目錄或 /etc/ha.d/resource.d 目錄下的腳本文件(這個腳本的副本必須同時存在於主服務器和備用服務器上)。這個腳本文件定義了 Heartbeat 啟動、接管以及停止時系統應該做的操作。
本例中,如下指定 Haresources 文件:
## /etc/ha.d/haresources
Primary 192.168.168.100 Filesystem::Nfsserver:/database::/database::nfs::rw,
hard db2::db2ha1
這一行指出,在啟動 Heartbeat 時,要實現以下操作:
將 Primary 設定為集群的虛擬 IP 192.168.168.100;
以可讀寫的方式掛載 Nfsserver 節點上的共享文件系統 /database;
以用戶 db2ha1 啟動 DB2 實例。
在 Heartbeat 關閉時,Heartbeat 將執行以下操作:
停止數據庫服務器;
卸載 NFS 共享文件系統 /database;
釋放集群的虛擬 IP。
在 Heartbeat 2.x 版本以後,Heartbeat 的資源配置文件采用了 XML 格式。為了方便不熟悉 XML 的用戶使用,Heartbeat 自帶了一個從 Haresources 生成 cib.XML 配置文件的工具。因此要將上面做成的 Haresource 文件進行如下轉換:
# /usr/lib/heartbeat/haresources2cib.py – stout
– c /etc/ha.d/ha.cf /etc/ha.d/haresources
該命令把原來的資源文件 /etc/ha.d/haresources 轉換成新的 XML 格式的配置文件 /var/lib/heartbeat/crm/cib.XML。
(8)將 Primary 節點上的配置文件復制到 Standby 節點上。向遠程節點復制文件可以使用命令 SCP。SCP(Secure Copy)是 Linux 文件傳送命令,用於在兩台服務器間傳送文件,格式為:
SCP 文件名 1 遠程用戶名 @ 遠程節點名 : 文件名 2
命令的執行過程中會要求輸入遠程用戶名的登錄密碼。本例中,執行下面的命令:
# cd /etc/ha.d
# scp ha.cf authkeys haresources root@Standby:/etc/ha.d
#scp /var/lib/heartbeat/crm/cib.XML root@Standby:/var/lib/heartbeat/crm
6 .啟動集群
(1)在 Primary 上啟動 Heartbeat。Heartbeat 啟動前,Primary 節點上的目錄掛載和 IP 地址的分配情況如圖 2.15 所示。NFS 共享文件系統 (/database 目錄 ) 和集群的虛擬 IP(192.168.168.100)都沒有掛載在節點上。
圖 2.15 Heartbeat 啟動前的 Primary 節點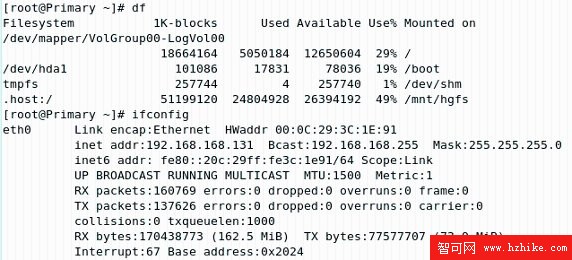
查看原圖(大圖)
利用 heartbeat start 命令來啟動 Primary 節點上的 Heartbeat(如圖 2.16 所示)。系統返回的消息顯示 Primary 上 Heartbeat 已經成功啟動。
圖 2.16 啟動 Primary Heartbeat
查看原圖(大圖)
(2)查看 Primary 節點集群狀態。查看集群的狀態可以使用 crm_mon 命令,其基本語法為:
crm_mon [ -i interval ] | [ -r] [ -h filename ]
其中:
-i interval:集群狀態刷新的時間間隔,單位為秒。如果該值不指定,默認 15 秒刷新一次集群的狀態。
-r:顯示無效的資源。
-h filename:將集群狀態處理到文件 filename 中。
本例中,將刷新的間隔設定為 5 秒:
# crm_mon – i5
圖 2.17 中顯示了集群的狀態,對其中的幾個項目進行說明:
Refresh in xs …:集群將在 x 秒後刷新狀態。
Last updated:集群的上次刷新時間。
Current DC:當前協調節點(主節點),所有其他的節點從主節點上讀取資源文件和配置信息。當備用節點接管主節點時,Current DC 會切換到備用節點。Current DC 後面跟著節點名和唯一的節點 ID。
x Nodes configed:當前集群中配置的節點數。
x Resources configured:集群中配置的資源數。
Node:列出集群中節點的詳細情況,如節點名、節點 id 以及節點的狀態(online/offline)。
Resource Group:在 Haresource 文件中定義的服務資源組,每一行就是一個資源組。
IPaddr_xxx_xxx_xxx_xxx:虛擬 IP 地址服務。ocf::heartbeat:IPaddr 表明提供該服務的腳本的類型(ocf)和腳本名(IPaddr);Started primary 表明該服務由 Primary 節點提供。
Filesystem_2:文件系統服務。ocf::heartbeat:Filesystem 表明提供該服務的腳本的類型(ocf)和腳本名(Filesystem);Started primary 表明該服務由 Primary 節點提供。
db2_3:DB2 數據庫服務。ocf::heartbeat:db2 表明提供該服務的腳本的類型(ocf)和腳本名(db2);Started primary 表明該服務由 Primary 節點提供。
本例中,集群有 1 個組成節點(Primary)和 1 個資源組(group_1),提供了集群 IP、文件系統和 DB2 數據庫服務。
圖 2.17 查看集群狀態(Primary)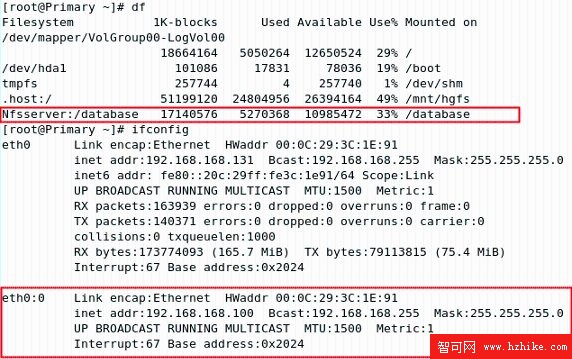
查看原圖(大圖)
此時,再次查看 Primary 節點上的目錄掛載和 IP 地址的分配情況(如圖 2.18)。從中可以看出,NFS 共享目錄(Nfsserver:/database)已經掛載在 Primary 節點上,集群虛擬 IP(192.168.168.100)也已經綁定在 Primary 節點上。
圖 2.18 Heartbeat 啟動後的 Primary 節點
查看原圖(大圖)
(3)在 Standby 上啟動 Heartbeat。同 Primary 節點一樣,在 Standby 節點上打開一個 Terminal,執行下面的命令:
# /etc/init.d/heartbeat start
(4)查看 Standby 節點集群狀態。在 Standby 節點上執行下列命令以查看集群狀態:
# crm_mon – i5
在集群資源監視窗口,可以看到集群的狀況發生了下面的變化:
x Nodes configed:集群中配置的節點數由 1 變為 2。
Node Standby:集群中節點增加了 Standby,狀態為 online。
盡管 Standby 節點加入到了集群中,提供虛擬 IP、Nfs 共享資源即 DB2 數據庫服務的節點仍然是 Primary(如圖 2.19)。
圖 2.19 查看集群狀態(Primary 和 Standby)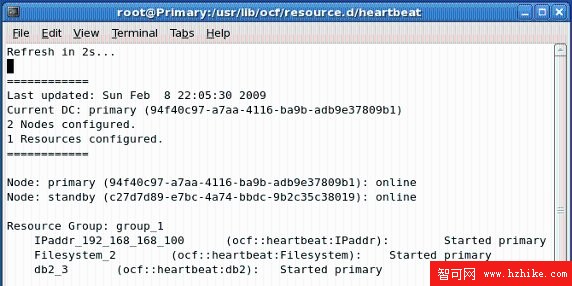
查看原圖(大圖)
查看 Standby 節點上 NFS 共享目錄的掛載和集群的虛擬 IP 地址的分配情況,可以證實上面的結果(見圖 2.20)。
圖 2.20 Heartbeat 啟動後的 Standby 節點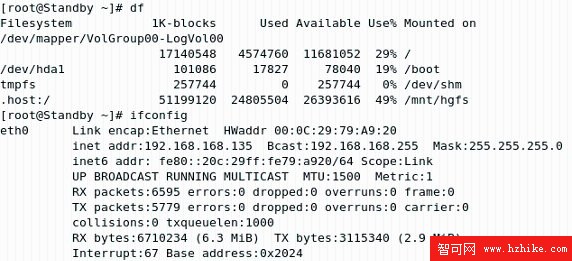
查看原圖(大圖)
7 .服務接管
(1)停止 Primary 節點上的 Heartbeat。使用下面的命令來停止 Primary 節點上的 Heartbeat。
# /etc/init.d/heartbeat stop
(2)查看集群狀態。執行下面的命令以查看集群的狀況(如圖 2.21):
# crm_mon – i5
圖 2.21 停止 Primary 節點後的集群狀態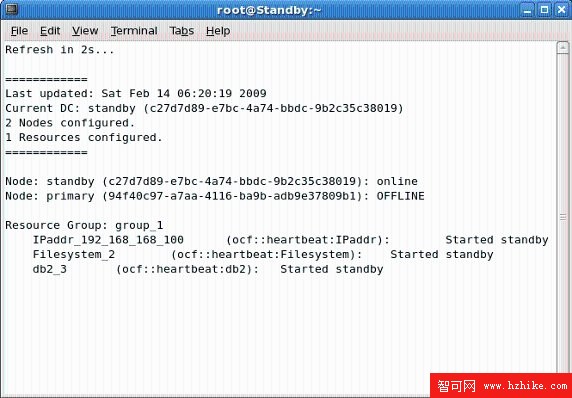
查看原圖(大圖)
可以看到,集群的狀況發生了下列變化:
Current DC:協調節點由之前的 Primary 變成了 Standby。
Node Primary:節點的狀態由 Online 變成了 Offline。
IPaddr_xxx_xxx_xxx_xxx:虛擬 IP 地址服務。Started Standby 表明該服務改由 Standby 節點提供。
Filesystem_2:文件系統服務。Started Standby 表明該服務改由 Standby 節點提供。
db2_3:DB2 數據庫服務。Started Standby 表明該服務改由 Standby 節點提供。
此時虛擬 IP、NFS 路徑掛載、DB2 服務都轉移到了 Standby 節點上。到 Standby 節點上查看節點的掛載目錄(如圖 2.22)和 IP 地址(如圖 2.23),也證實了上面的結果。
圖 2.22 Standby 節點的掛載目錄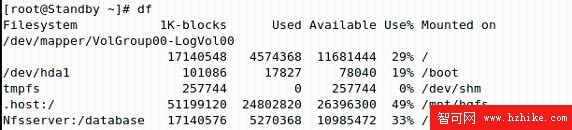
查看原圖(大圖)
圖 2.23 Standby 節點的 IP 地址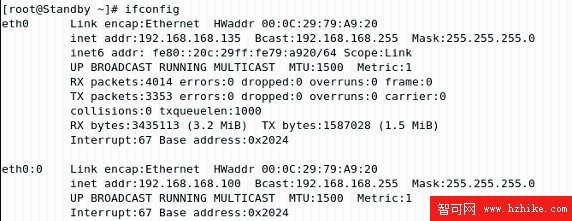
查看原圖(大圖)
(3)此時重新啟動 Primary 節點的 Heartbeat,並查看集群的狀態(如圖 2.24)。
# /etc/init.d/heartbeat start
# crm_mon – i5
因為之前將 auto_failback 參數設置為 on,因此服務再次被 Primary 節點接管。集群的狀況發生了下列變化:
Current DC:協調節點由之前的 Standby 變成了 Primary。
Node Primary:節點的狀態由 Offline 變成了 Online。
IPaddr_xxx_xxx_xxx_xxx:虛擬 IP 地址服務。Started Primary 表明該服務改由 Primary 節點提供。
Filesystem_2:文件系統服務。Started Primary 表明該服務改由 Primary 節點提供。
db2_3:DB2 數據庫服務。Started Primary 表明該服務改由 Primary 節點提供。
圖 2.24 查看集群狀態(Primary 和 Standby)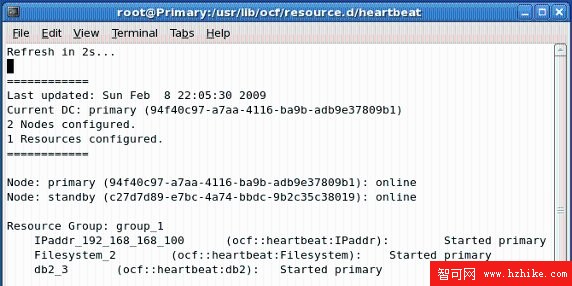
查看原圖(大圖)
2.2.3 測試
首先在 Primary 節點上插入數據,然後由 Standby 節點接管服務,在 Standby 上查詢插入的數據來檢驗集群的創建。
(1)啟動 Primary 節點上的 Heartbeat。
# /etc/init.d/heartbeat start
(2)用 db2ha1 登錄 Primary 節點,啟動實例 db2ha1,然後連接 HADB 並創建測試表 Test,並插入一條記錄。
01 # su – db2ha1
02 # db2start
03 # db2 connect to HADB
04 # db2
05 db2 => create table test(msg char(5),message char(20))
06 db2 => insert into test values( ‘ msg01 ’ , ’ Hello Cluster ’ )
(3) 啟動 Standby 節點的 Heartbeat,並停止 Primary 節點上的 Heartbeat。在 Standby 節點上執行下面的命令:
# /etc/init.d/heartbeat start
在 Primary 節點上執行下面的命令:
# /etc/init.d/heartbeat stop
查看集群狀態,使用下面的命令:
# crm_mon – i5
在集群資源管理器中確認提供服務的節點從 Primary 轉移到了 Standby。
(4)用 db2ha1 登錄 Standby 節點,啟動實例 db2ha1,然後連接 HADB 並查詢 Test 表的內容。
01 # su – db2ha1
02 # db2start
03 # db2 connect to HADB
04 # db2
05 db2 => select * from test
抽出來的 Test 表中的數據(見圖 2.25)與在 Primary 節點上插入的一致,證明集群創建成功。
圖 2.25 在 Standby 節點上抽出數據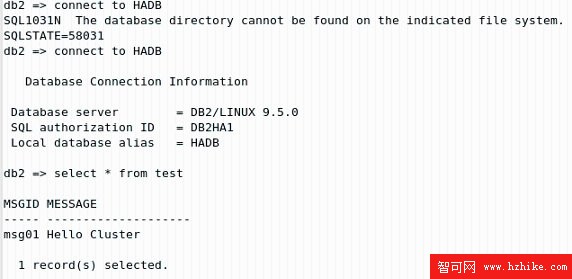
查看原圖(大圖)
2.3 實踐技巧
1 .在 ha.cf 文件中配置了兩個節點,為何用 crm_mon 對集群進行監視的時候,兩個節點互相“視而不見”?
首先,請確認一下 /etc/hosts 文件的配置是否正確。/etc/hosts 文件中定義的節點名應該和“uname -n”命令輸出的一致,如果出現不一致,節點間便可能無法正確連接。可以用下面的命令確認 /etc/hosts 文件的配置:
# ping hostname
其中的 hostname 為遠程的主機名。
如果 /etc/hosts 文件沒有問題,節點間可以用 ping 命令連接,卻在集群資源管理器中無法發現對方,最可能的原因就是防火牆的設置。用戶可以先試著停掉防火牆,再觀察能否監視到對方。停掉防火牆的命令為:
# service iptables stop
防火牆的設置導致不能互相連接是一個常見的問題,在後面的章節中也會碰到。
2 .如果兩台機器間不用串口連接的方式傳遞“心跳”信號,還可以用什麼方式?
除了串口連接之外,還有多種方式傳遞“心跳”信號。如用戶也可以為每台機器配置兩個網卡。其中一個網卡為外界提供服務,另一個網卡用於集群節點間的連接。重新配置一下 ha.cf 文件,心跳線的連接方式由串口連接(serial /dev/ttyS0)改為廣播的方式(bcast eth1)即可。
3 .為什麼定義的資源不能啟動,而且沒有任何錯誤提示?
Heartbeat 通過 perl 腳本來啟動相應的資源,如果資源無法啟動,很有可能是該資源對應的腳本文件不正確。用戶可以查看 /etc/init.d 目錄或 /etc/ha.d/resource.d 目錄下相應的腳本文件。詳見 http://wiki.Linux-ha.org/HeartbeatResourceAgent。
2.4 本章小結
本章首先介紹了集群。集群是一組計算機合起來提供一項服務的架構。通過集群,可以提高應用系統的計算速度或可用性。
其次,介紹了集群的可用性,主要包括共享存儲和獨立存儲。共享存儲模式是雙機熱備的最常見方案,實施簡單、管理方便。此外,還介紹了一個利用 Heartbeat 軟件實現的高可用性集群的配置實例。
獨立存儲的解決方案主要有 3 種:數據復制選項、日志傳送選項和高級存儲選項。獨立存儲方式投資較大,但數據的可靠性大大提升,詳細的配置實例參見本書第 3 章“DB2 高可用性災難恢復”的相關內容。