PAYMENT事務
PAYMENT事務有兩種版本。對於那些提供了客戶id 的客戶,使用第一種版本。對於不記得客戶ID,而只提供了姓氏的客戶,使用第二種版本。這裡只討論第二種版本,因為其中提出了第一種版本中所沒有的挑戰。
在支付事務(按姓氏)中,必須發生以下步驟:
檢索地區的名稱和地址。
根據姓氏發現客戶的客戶 id。如果在該地區有多個同姓的客戶,則正確的客戶應該是根據客戶的名字得來的“中間”客戶。
檢索客戶的個人信息。
增加該地區至今為止的收入。
增加倉庫至今為止的收入。
增加客戶的支付額,如果客戶信用不佳,則還應包括額外的數據。
將這次的支付記錄到歷史中。
與前面的事務一樣,這裡的大部分邏輯被封裝到一個名為 PAY_C_LAST() 的表函數中。
清單 13. 表函數 PAY_C_LAST
1
CREATE FUNCTION PAY_C_LAST( W_ID INTEGER
2 , D_ID SMALLINT
3 , C_W_ID INTEGER
4 , C_D_ID SMALLINT
5 , C_LAST VARCHAR(16)
6 , H_DATE BIGINT
7 , H_AMOUNT BIGINT
8 , BAD_CREDIT_PREFIX VARCHAR(34)
9 )
10
RETURNS TABLE( W_STREET_1 CHAR(20)
11 , W_STREET_2 CHAR(20)
12 , W_CITY CHAR(20)
13 , W_STATE CHAR(2)
14 , W_ZIP CHAR(9)
15 , D_STREET_1 CHAR(20)
16 , D_STREET_2 CHAR(20)
17 , D_CITY CHAR(20)
11 , D_STATE CHAR(2)
19 , D_ZIP CHAR(9)
20 , C_ID INTEGER
21 , C_FIRST VARCHAR(16)
22 , C_MIDDLE CHAR(2)
23 , C_STREET_1 VARCHAR(20)
24 , C_STREET_2 VARCHAR(20)
25 , C_CITY VARCHAR(20)
26 , C_STATE CHAR(2)
27 , C_ZIP CHAR(9)
28 , C_PHONE CHAR(16)
29 , C_SINCE BIGINT
30 , C_CREDIT CHAR(2)
31 , C_CREDIT_LIM BIGINT
32 , C_DISCOUNT INTEGER
33 , C_BALANCE BIGINT
34 , C_DATA CHAR(200)
35 )
36
SPECIFIC PAY_C_Id
INHERIT ISOLATION LEVEL WITH LOCK REQUEST
37
MODIFIES SQL DATA DETERMINISTIC NO EXTERNAL ACTION LANGUAGE SQL
38 VAR:
BEGIN ATOMIC
39
DECLARE W_NAME CHAR(10) ;
40
DECLARE D_NAME CHAR(10) ;
41
DECLARE W_STREET_1 CHAR(20) ;
42
DECLARE W_STREET_2 CHAR(20) ;
43
DECLARE W_CITY CHAR(20) ;
44
DECLARE W_STATE CHAR(2) ;
45
DECLARE W_ZIP CHAR(9) ;
46
DECLARE D_STREET_1 CHAR(20) ;
47
DECLARE D_STREET_2 CHAR(20) ;
48
DECLARE D_CITY CHAR(20) ;
49
DECLARE D_STATE CHAR(2) ;
50
DECLARE D_ZIP CHAR(9) ;
51
DECLARE C_ID INTEGER ;
52
DECLARE C_FIRST VARCHAR(16) ;
53
DECLARE C_MIDDLE CHAR(2) ;
54
DECLARE C_STREET_1 VARCHAR(20) ;
55
DECLARE C_STREET_2 VARCHAR(20) ;
56
DECLARE C_CITY VARCHAR(20) ;
57
DECLARE C_STATE CHAR(2) ;
58
DECLARE C_ZIP CHAR(9) ;
59
DECLARE C_PHONE CHAR(16) ;
60
DECLARE C_SINCE BIGINT ;
61
DECLARE C_CREDIT CHAR(2) ;
62
DECLARE C_CREDIT_LIM BIGINT ;
63
DECLARE C_DISCOUNT INTEGER ;
64
DECLARE C_BALANCE BIGINT ;
65
DECLARE C_DATA CHAR(200) ;
66
67 /* Update District and retrIEve its data */
68
SET ( D_NAME, D_STREET_1, D_STREET_2, D_CITY, D_STATE, D_ZIP )
69 = (
SELECT D_NAME, D_STREET_1, D_STREET_2, D_CITY, D_STATE, D_ZIP
70
FROM OLD TABLE (
UPDATE DISTRICT
71
SET D_YTD = D_YTD + PAY_C_ID.H_AMOUNT
72
WHERE D_W_ID = PAY_C_ID.W_Id
73
AND D_ID = PAY_C_ID.D_Id
74 )
AS U
75 )
76 ;
77 /* Determine the C_ID */
78
SET ( C_ID )
79 = (
SELECT C_Id
80
FROM (
SELECT C_Id
81 , COUNT(*) OVER()
AS COUNT
82 , ROWNUMBER() OVER (
ORDER BY C_FIRST)
AS NUM
83
FROM CUSTOMER
84
WHERE C_LAST = PAY_C_LAST.C_LAST
85
AND C_W_ID = PAY_C_LAST.C_W_Id
86
AND C_D_ID = PAY_C_LAST.C_D_Id
87 )
AS T
88
WHERE NUM = (COUNT + 1) / 2
89 )
90 ;
91 /* Update the customer */
92
SET ( C_FIRST, C_MIDDLE, C_STREET_1, C_STREET_2
93 , C_CITY, C_STATE, C_ZIP, C_PHONE, C_SINCE, C_CREDIT, C_CREDIT_LIM
94 , C_DISCOUNT, C_BALANCE, C_DATA )
95 = (
SELECT C_FIRST, C_MIDDLE, C_STREET_1, C_STREET_2
96 , C_CITY, C_STATE, C_ZIP, C_PHONE, C_SINCE, C_CREDIT
97 , C_CREDIT_LIM , C_DISCOUNT, C_BALANCE
98 ,
CASE WHEN C_CREDIT = 'BC'
99
THEN SUBSTR(C_DATA, 1, 200)
END AS C_DATA
100
FROM NEW TABLE (
UPDATE CUSTOMER
101
SET C_BALANCE = C_BALANCE - PAY_C_ID.H_AMOUNT
102 , C_YTD_PAYMENT = C_YTD_PAYMENT + PAY_C_ID.H_AMOUNT
103 , C_PAYMENT_CNT = C_PAYMENT_CNT + 1
104 , C_DATA =
CASE WHEN C_CREDIT = 'BC'
105
THEN BAD_CREDIT_PREFIX
106 || SUBSTR( C_DATA, 1, 466 )
107
ELSE C_DATA
108
ENd
109
WHERE C_W_ID = PAY_C_ID.C_W_Id
110
AND C_D_ID = PAY_C_ID.C_D_Id
111
AND C_ID = PAY_C_ID.C_Id
112 )
AS U
113 )
114 ;
115 /* Update the warehouse */
116
SET ( W_NAME, W_STREET_1, W_STREET_2, W_CITY, W_STATE, W_ZIP )
117 = (
SELECT W_NAME, W_STREET_1, W_STREET_2, W_CITY, W_STATE, W_ZIP
118
FROM OLD TABLE (
UPDATE WAREHOUSE
119
SET W_YTD = W_YTD + PAY_C_ID.H_AMOUNT
120
WHERE W_ID = PAY_C_ID.W_Id
121 )
AS U
122 )
123 ;
124 /* Finally insert into the history */
125
INSERT
126
INTO HISTORY ( H_C_ID, H_C_D_ID, H_C_W_ID, H_D_Id
127 , H_W_ID, H_DATA, H_DATE, H_AMOUNT )
128
VALUES ( PAY_C_ID.C_Id
129 , PAY_C_ID.C_D_Id
130 , PAY_C_ID.C_W_Id
131 , PAY_C_ID.D_Id
132 , PAY_C_ID.W_Id
133 , VAR.W_NAME || CHAR( ' ', 4 ) || VAR.D_NAME
134 , PAY_C_ID.H_DATE
135 , PAY_C_ID.H_AMOUNT
136 )
137 ;
138 /* Done - return the collected data */
139
RETURN VALUES ( W_STREET_1, W_STREET_2, W_CITY, W_STATE, W_ZIP
140 , D_STREET_1, D_STREET_2, D_CITY, D_STATE, D_ZIP
141 , C_ID , C_FIRST, C_MIDDLE, C_STREET_1, C_STREET_2
142 , C_CITY, C_STATE, C_ZIP, C_PHONE, C_SINCE, C_CREDIT
143 , C_CREDIT_LIM , C_DISCOUNT, C_BALANCE, C_DATA
144 )
145 ;
146
END
清單 14. 用於支付事務的 SQL 語句
1
SELECT W_STREET_1, W_STREET_2, W_CITY, W_STATE, W_ZIP
2 , D_STREET_1, D_STREET_2, D_CITY, D_STATE, D_ZIP
3 , C_ID, C_FIRST, C_MIDDLE, C_STREET_1, C_STREET_2
4 , C_CITY, C_STATE, C_ZIP, C_PHONE, C_SINCE, C_CREDIT, C_CREDIT_LIM
5 , C_DISCOUNT, C_BALANCE, C_DATA
6
INTO :w_street_1 , :w_street_2 , :w_city , :w_state , :w_zip
7 , :d_street_1 , :d_street_2 , :d_city , :d_state , :d_zip
8 , :c_id , :c_first , :c_middle , :c_street_1 , :c_street_2 , :c_city , :c_state
9 , :c_zip , :c_phone , :c_since , :c_credit , :c_credit_liM
10 , :c_discount , :c_balance, :c_data :c_data_indicator
11
FROM TABLE ( PAY_C_LAST( :w_id
12 , :d_id
13 , :c_w_id
14 , :c_d_id
15 , :c_last_inpuT
16 , :h_date
17 , :h_amounT
18 , :c_data_prefix_c_lasT
19 )
20 )
AS PAY_C_LAST
21
WITH RR USE AND KEEP UPDATE LOCKS
在通常的優化的基礎上,還應注意兩種新的技術:
為了確定正確的客戶,需要讀 CUSTOMER 表。只有在此基礎上,才可以執行對 CUSTOMER 表的更新。默認情況下,這意味著所有姓氏有問題的客戶行將獲得一個 共享鎖(share lock)。為執行更新,需要將共享鎖轉換為一個 更新鎖(update lock)。這裡有一個小小的風險,同一個客戶可能想要在同一時間為另一個訂單進行支付。如果是在取數據(fetch)和更新(update)之間發生這樣的情況,那麼就會出現 死鎖(dead lock),因為如果另一個事務持有共享鎖的話,這兩個事務就都不能獲得更新鎖。為了避免這樣情況發生,DB2 V8.2 支持所謂的 lock-request-clause。在這個例子中, WITH RR USE AND KEEP UPDATE LOCKS 將導致 DB2 在整個語句中收集最少的更新鎖,而不是共享鎖。為了語義上的純淨和未來的可擴展性,這個 SQL 函數使用一個匹配子句 INHERIT ISOLATION LEVEL WITH LOCK REQUEST。
為了發現中間的客戶,這裡選擇了使用 ROW_NUMBER()。這個 OLAP 函數將所有同姓的客戶按照他們的名字來編號。而且,這裡決定不使用一個單獨的查詢來獲得總的 COUNT。相反,這裡再次使用 OLAP。這需要在用於緩沖所有匹配客戶的內存消耗 —— 因為總 COUNT 必須跟在每個客戶的後面,但是這個總 COUNT 只有到最後才知道 —— 和從客戶表進行兩次索引掃描之間作出取捨。對於行數較少並且每行的寬度不大的情況,實際上使用 COUNT(*) OVER() 的 (C_ID, COUNT, NUM) 要好一些。
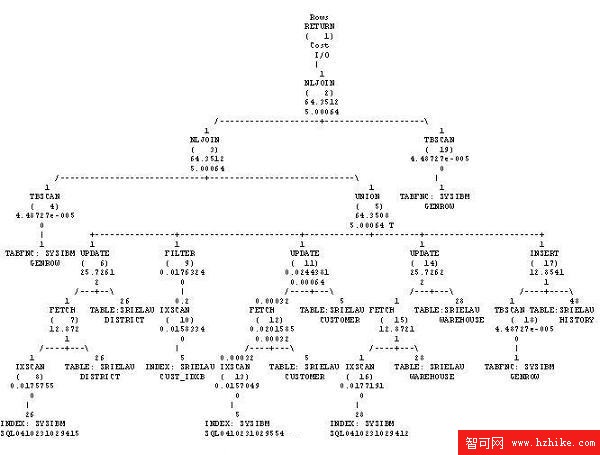
清單 15 展示了支付事務的計劃。
清單 15. 支付事務的訪問計劃
清單 14. 用於支付事務的 SQL 語句
1
SELECT W_STREET_1, W_STREET_2, W_CITY, W_STATE, W_ZIP
2 , D_STREET_1, D_STREET_2, D_CITY, D_STATE, D_ZIP
3 , C_ID, C_FIRST, C_MIDDLE, C_STREET_1, C_STREET_2
4 , C_CITY, C_STATE, C_ZIP, C_PHONE, C_SINCE, C_CREDIT, C_CREDIT_LIM
5 , C_DISCOUNT, C_BALANCE, C_DATA
6
INTO :w_street_1 , :w_street_2 , :w_city , :w_state , :w_zip
7 , :d_street_1 , :d_street_2 , :d_city , :d_state , :d_zip
8 , :c_id , :c_first , :c_middle , :c_street_1 , :c_street_2 , :c_city , :c_state
9 , :c_zip , :c_phone , :c_since , :c_credit , :c_credit_liM
10 , :c_discount , :c_balance, :c_data :c_data_indicator
11
FROM TABLE ( PAY_C_LAST( :w_id
12 , :d_id
13 , :c_w_id
14 , :c_d_id
15 , :c_last_inpuT
16 , :h_date
17 , :h_amounT
18 , :c_data_prefix_c_lasT
19 )
20 )
AS PAY_C_LAST
21
WITH RR USE AND KEEP UPDATE LOCKS
在通常的優化的基礎上,還應注意兩種新的技術:
為了確定正確的客戶,需要讀 CUSTOMER 表。只有在此基礎上,才可以執行對 CUSTOMER 表的更新。默認情況下,這意味著所有姓氏有問題的客戶行將獲得一個 共享鎖(share lock)。為執行更新,需要將共享鎖轉換為一個 更新鎖(update lock)。這裡有一個小小的風險,同一個客戶可能想要在同一時間為另一個訂單進行支付。如果是在取數據(fetch)和更新(update)之間發生這樣的情況,那麼就會出現 死鎖(dead lock),因為如果另一個事務持有共享鎖的話,這兩個事務就都不能獲得更新鎖。為了避免這樣情況發生,DB2 V8.2 支持所謂的 lock-request-clause。在這個例子中, WITH RR USE AND KEEP UPDATE LOCKS 將導致 DB2 在整個語句中收集最少的更新鎖,而不是共享鎖。為了語義上的純淨和未來的可擴展性,這個 SQL 函數使用一個匹配子句 INHERIT ISOLATION LEVEL WITH LOCK REQUEST。
為了發現中間的客戶,這裡選擇了使用 ROW_NUMBER()。這個 OLAP 函數將所有同姓的客戶按照他們的名字來編號。而且,這裡決定不使用一個單獨的查詢來獲得總的 COUNT。相反,這裡再次使用 OLAP。這需要在用於緩沖所有匹配客戶的內存消耗 —— 因為總 COUNT 必須跟在每個客戶的後面,但是這個總 COUNT 只有到最後才知道 —— 和從客戶表進行兩次索引掃描之間作出取捨。對於行數較少並且每行的寬度不大的情況,實際上使用 COUNT(*) OVER() 的 (C_ID, COUNT, NUM) 要好一些。
清單 15 展示了支付事務的計劃。
清單 15. 支付事務的訪問計劃
清單 17. 調用函數
1
SELECT O_ID, O_CARRIER_ID, O_ENTRY_D, C_BALANCE, C_FIRST, C_MIDDLE, C_Id
2
INTO :o_id, :o_carrIEr_id , :o_entry_d , :c_balance, :c_first, :c_middle, :c_id
3
FROM TABLE ( ORD_C_LAST( :w_id
4 , :d_id
5 , :c_last_inpuT
6 )
7 )
AS ORD_C_LAST
清單 18. 用於訂單狀態查詢的 SQL 語句
1
SELECT OL_I_ID, OL_SUPPLY_W_ID, OL_QUANTITY, OL_AMOUNT, OL_DELIVERY_d
2
FROM ORDER_LINE
3
WHERE OL_W_ID = :w_id
4
AND OL_D_ID = :d_id
5
AND OL_O_ID = :o_id
6
FOR FETCH ONLY ;
這裡同樣應用了很多常用的提高性能的技巧。例如,所有未涉及訂購項的步驟都被封裝到一個 SQL 表函數中。而且,這裡使用 OLAP 來檢索“中間客戶”。然而,最後從這個查詢中還可以收集到一些有趣的事情:
天真的人可能會首先確定客戶的最大訂單 id,然後使用這個 ID 來檢索送貨人和訂單日期。如果訂單 id 按照降序排序,則一個客戶的最大訂單 id 也就是基於客戶 id 和訂單 id 的索引中的第一個訂單 ID。然而,利用這一事實將那兩個查詢組合到一起則顯得更為緊湊。給定一個匹配的索引,通過一個單獨的取索引操作就可以得到要檢索的行。在發貨事務中也使用了相同的技巧,但此處則沒有 DELETE 和 MAXIMUM。
注意,訂購項是通過一個單獨的游標來檢索的。執行兩條語句與返回這兩個查詢的笛卡兒積相比效率要高一些,後者將重復發送每個訂購項的客戶信息和訂單信息。
清單 19 列出的計劃展示了使用前面討論的 ORDER BY 的 (FETCH(8)) 和 FETCH FIRST 1 ROW ONLY 的效率。
清單 19. 訂單狀態查詢計劃
Rows
RETURN
( 1)
CosT
I/O
|
1
NLJOIN
( 2)
12.928
2.008
/----------+---------
1 1
NLJOIN TBSCAN
( 3) ( 10)
12.9279 4.48727e-005
2.008 0
/---------+-------- |
1 1 1
TBSCAN UNION TABFNC: SYSIBM
( 4) ( 5) GENROW
4.48727e-005 0.108135
0 0.013056
| /-------+------
1 1 1
TABFNC: SYSIBM FILTER FETCH
GENROW ( 6) ( 8)
0.0176324 0.0905021
0 0.005056
| /----+---
0.2 0.005056 79
IXSCAN IXSCAN TABLE: SRIELAU
( 7) ( 9) ORDERS
0.0158334 0.0251716
0 0
| |
5 79
INDEX: SRIELAU INDEX: SRIELAU
CUST_IDXB ORDR_IDXB
STOCK LEVEL查詢
最後一點,也是重要的一點, STOCK LEVEL 查詢演習了一個三方(three-way)連接,以確定對於一個給定的、庫存水平低於一個指定阈值的地區,在過去 20 份訂單中產品的數量。關於這個查詢沒有很多要講的,只有一點:該查詢是惟一可以以 cursor stability 隔離級別運行的查詢。DB2 能夠逐個地為查詢指定隔離級別,這裡就使用了這一功能。
清單 20. 庫存水平查詢
1
SELECT COUNT( S_I_ID )
INTO :low_stock
2
FROM (
SELECT DISTINCT S_I_Id
3
FROM ORDER_LINE , STOCK , DISTRICT
4
WHERE D_W_ID = :w_id
5
AND D_ID = :d_id
6
AND OL_O_ID < d_next_o_id
7
AND OL_O_ID >= ( d_next_o_id - 20 )
8
AND OL_W_ID = D_W_Id
9
AND OL_D_ID = D_Id
10
AND S_I_ID = OL_I_Id
11
AND S_W_ID = OL_W_Id
12
AND S_QUANTITY < :threshold
13 )
AS OLS
14
WITH CS
清單 21. 庫存水平查詢訪問計劃
Rows
RETURN
( 1)
CosT
I/O
|
1
GRPBY
( 2)
13.204
1.02222
|
3.75467e-005
TBSCAN
( 3)
13.2039
1.02222
|
3.75467e-005
SORT
( 4)
13.2033
1.02222
|
3.75467e-005
NLJOIN
( 5)
13.2023
1.02222
/--------------------+--------------------
0.00782222 0.0048
NLJOIN FETCH
( 6) ( 11)
13.0011 0.201169
1.00782 0.0144
/-----------+----------- /----+---
1 0.00782222 0.0144 9
FETCH FETCH IXSCAN TABLE: SRIELAU
( 7) ( 9) ( 12) STOCK
12.872 0.129119 0.0157274
1 0.00782222 0
/----+--- /----+--- |
1 26 0.00782222 44 9
IXSCAN TABLE: SRIELAU IXSCAN TABLE: SRIELAU INDEX: SYSIBM
( 8) DISTRICT ( 10) ORDER_LINE SQL0410231029421
0.0175755 0.0282312
0 0
| |
26 44
INDEX: SYSIBM INDEX: SYSIBM
SQL0410231029415 SQL0410231030088
結束語
在本文中,Rielau 簡要地介紹了 TPC-C 基准的模式及其事務。為了在 DB2 已達到的極限級別上執行這個基准,需要更多的東西,但對 SQL 的簡潔的使用處於首要地位。高效的 SQL 產生高效的查詢計劃,高效的查詢計劃又意味著只需要執行必不可少的代碼路徑。只讀取必不可少的行。RIElau 認為 DB2 在 TPC-C 基准中使用的 SQL 已經非常接近最優。要進一步精化的東西非常少。
總而言之,以下是 TPC-C 這個實現暴露出的有趣的 SQL 特性:
SQL 表函數的使用使您可以將過程性邏輯放入到查詢的 FROM 子句中。通過 關聯(correlation),SQL 表函數允許以一種更高效的方式實現迭代,而不是使用游標。
SQL 表函數中的 MODIFIES SQL DATA 使您甚至可以將 INSERT、UPDATE、DELETE 和 MERGE ( 數據更改操作)放入到關聯連接的內表中。
在 FROM 子句中對 數據更新操作 的使用允許對生成的列(例如 ID)的檢索,以及對要被刪除或更新的數據的檢索。
通過使用 作為 數據更改操作 的目標的查詢 ,可以刪除或更新由復雜的 SQL(包括 ORDER BY)確定的行。對這一特性的一個常見應用就是 POP 隊列語義 的實現。
ORDER BY 結合 FETCH FIRST 可以有效地用於選擇最大或最小行,包括對不是聚合函數本身一部分的列的檢索。
當按條件選擇行,而不是簡單地選擇最大或最小行時,可以考慮 OLAP 函數。
公共表表達式(WITH 子句)允許 數據更新操作 的高效 管道。
雖然 TPC-C 基准非常簡單,但是它在 OLTP 處理的很多方面仍然非常有效。
注意,雖然 DB2 不是第一種引入從 INSERT、UPDATE 和 DELETE 返回數據的手段的產品,但它是第一種將此概念集成到 SQL 本身當中的產品,它為結果的即時關系處理提供了支持,而無需使用臨時表和過程語言結構。