XML 索引的使用指南
在下面章節中描述了在 XML 數據上創建索引的指南,以及如何有效的使用索引。
定義索引
對於最大化你的 XQuery 和 SQL/XML 語句的性能非常關鍵。 DB2 允許你在 XML 列上定義path-specificXML 索引。這意味著你可以把選中的在謂詞和連接中經常用到的元素和屬性編入索引中。例如,對於有 principal amounts 的交易下面的索引可以幫助你加速搜索:
清單 44. 在 principal amounts 上的 XML 索引
create index tdpa on trades(tradedoc) generate keys
using XMLpattern
'/FpML/trade/termDeposit/principal/amount' as sql double;
這個語句會創建一個現在存 TRADES 表的 TRADEDOC 列中的 XML 文檔的索引。將為每個匹配指定的 XPath 標的式的節點創建一個索引鍵。索引鍵在文檔插入、更新或刪除時被添加和刪除。<TIP>記住 XML 索引只能被定義在一個單獨的 XML 列上,不能有組合鍵,不過可以為每個基礎表生成多個鍵值。例如,一個定義在‘ /FpML/trade/fxSingleLeg/*/paymentAmount/amount ’上的索引將為每個外匯交易衍生工具創建兩個鍵值,因為這樣的文檔都包含兩個 amount 元素。記住 XML 索引不包含文檔輸入的也不包含索引路徑。因此,對於描述了bulletPayment 或外匯交易事務的交易文檔在清單 44 中的索引將不包含任何鍵,因為它們不包括 /FpML/trade/termDeposit/principal/amount 路徑。
與關系型索引一樣 XML 索引會消耗表空間的空間,並在文件被插入、更新或刪除後必須進行維護(保持實時)。因此,你需要在它們對查詢的好處和存儲維護它們需要額外的資源需求之間找到平衡。一個 XML 索引的大小和維護開銷是和每個匹配索引 XMLPATTERN 的文檔中元素和屬性數目直接相關的。下一章節解釋了如何盡可能保持較小 XML 索引開銷。
你可以在定義 XML 索引【 3 】中找到更多的細節。我們認為 你記得基本的指定索引路徑使用元素和屬性節點名、“ / ”,“ // ”和“ * ”符號以及每個索引以及每個索引包含一種 SQL 類型的必要性。在下面的章節中,我們將側重於索引定義的最佳實踐。
只要有可能就使用完全指定的路徑來定義索引
假設你需要確保在外匯兌換交易 payment amount 要求的中良好的查詢性能。因為每個外匯兌換交易都有兩個路徑對應一個 payment amount 即
/FpML/trade/fxSingleLeg/ExchangedCurrency1/paymentAmount/amount and
/FpML/trade/fxSingleLeg/ExchangedCurrency2/paymentAmount/amount,
/FpML/trade/fxSingleLeg/ExchangedCurrency1/paymentAmount/amount 和
/FpML/trade/fxSingleLeg/ExchangedCurrency2/paymentAmount/amount,
你打算保持簡潔並如圖 45 所示定義了一個以“ paymentAmount/amount ”為結尾的的索引。
清單 45. 一個有通配符的索引
create index tpa on trades(tradedoc) generate keys using XMLpattern
'//paymentAmount/amount' as sql double;
出於下列原因,這個索引可以被清單 46 中的查詢使用:
索引路徑比在查詢中指定的更簡單。
在謂詞(數字)中的文本值的數據類型匹配索引類型。
清單 46. 一個涉及 /paymentAmount/amount 查詢
select tradeid from trades t where
XMLexists('$TRADEDOC/FpML/trade/fxSingleLeg/*/paymentAmount[amount >
1000000 and currency = "USD"]');
然而,索引定義中的 // 對查詢具有在前文中討論過的相同的缺點。首先,在一個確定的元素比起完全指定了路徑和指向的情況下,// 意味著 DB2 需要做更多的工作來為索引查找匹配的元素。其次,// 在索引模式中可能會選擇比你期望的數目更多的節點。這意味著比起索引會變得比實際需要的大小要更大。如果你更詳細的指定路徑就可以避免這種情況。
清單 47. 更詳細的索引
create index tfxpa on trades(tradedoc) generate keys using XMLpattern
'/FpML/trade/fxSingleLeg/*/paymentAmount/amount' as sql double;
正確的使用 XML 索引數據類型
DB2 支持 5 種不同數據類型的 XML 索引:DOUBLE、VARCHAR(n)、VARCHAR HASHED、DATE 和時間戳。索引數據類型的選擇很重要,因為它影響索引在謂詞賦值中的使用。例如清單 48 中的索引不能在清單 49 中的查詢中使用。
清單 48. 一個使用數字類型的索引
create index thtd on trades(tradedoc) generate keys using XMLpattern
'/FpML/trade/tradeHeader/tradeDate' as sql double;
清單 49. 使用字符串謂詞的查詢
select *
from trades
where XMLexists('$TRADEDOC/FpML/party[partyId="510026"]')
為什麼呢?數字是 510026 在查詢謂詞中是包含在雙引號中的,因此它被解釋為一個字符串。因為索引數據類型是 DOUBLE,索引不能被用來決定字符串謂詞。你需要定義一個使用 VARCHAR 數據類型的索引(如果你想比較字符串)或者保持 DOUBLE 索引類型並刪除數字(數字比較)的雙引號
同樣的清單 50 中的索引不能被圖 51 中的查詢使用。這是因為“ 2002-02-14Z ”是一個字符串文字,它匹配 VARCHAR 索引卻不匹配 DATE 索引。
清單 50. 一個使用 DATE 類型的索引
create index thtd on trades(tradedoc) generate keys using XMLpattern
'/FpML/trade/tradeHeader/tradeDate' as sql date;
xquery for $i in db2-fn:XMLcolumn("TRADES.TRADEDOC")/FpML
where $i/trade[tradeHeader/tradeDate >= "2002-02-14Z"]
return $i;
圖 51:一個使用 VARCHAR 謂詞的查詢。
簡單的解決方案是把查詢中的文字映射為 XML 類型 xs:date,如清單 52 所示。這就可以使用 DATE 索引了。
清單 52. 利用 xs:date 來使用一個 DATE 索引
xquery for $i in db2-fn:XMLcolumn("TRADES.TRADEDOC")/FpML
where $i/trade[tradeHeader/tradeDate >= xs:date("2002-02-14Z")]
return $i;
索引數據類型:VARCHAR(n) 和 VARCHAR HASHED
VARCHAR(n) 索引對在被索引的字符串有最大長度“ n ”的情況非常適合,並且索引的元素可以在范圍謂詞(<,>)中使用。如果你嘗試在有長度大於“ n ”的節點上創建一個 VARCHAR(n) 索引,創建將會失敗。同樣的對一個文檔一個插入或更新也會失敗,在定義了 VARCHAR(n) 索引的情況下。因此,一個 VARCHAR(n) 索引對索引節點執行了一個長度為“ n ”限制。
另一方面一個 VARCHAR HASHED 索引允許你的索引字符串為任意長度。它們只存儲字符串的哈希值而不存儲索引的鍵值。這列索引可以快速評估等價謂詞,不過卻不能被用作范圍謂詞或排序。表 53 總結了這個兩種索引對 XML 字符數據的屬性。
索引類型
用途
是否限制索引鍵長度?
VARCHAR(N)
所有謂詞類型,排序
N 字節:最大 N 值取決於索引頁大小
VARCHAR HASHED
- - 僅限與等價謂詞
-- 對長型數據建立索引
圖 53:VARCHAR(n) 和 VARCHAR HASHED 索引的特征
<TIP>簡而言之,對於只會被用於等價謂詞的查詢的元素或屬性,一個 VARCHAR HASHED 索引常常是很好的選擇。尤其對於長型數據,一個 VARCHAR HASHED 索引比一個 VARCHAR(n) 索引更小。如果索引是常常被用於評估范圍謂詞那麼就需要使用 VARCHAR(n) 索引。
索引定義中的 text()
在考慮它在索引中的影響之前,讓我們簡單回顧一下路徑表達式中 /text() 的含義。下面是一個定期存款交易文檔的一部
清單 54. 定期存款文檔的很小一部分
<principal>
<currency>EUR</currency>
<amount>25000000.00</amount>
</principal>
元素節點 <principal>、<currency> 和 <amount>(以及他們各自的關閉標簽)提供了文檔結構。具體值存放在文本節點 EUR 和 25000000.00 中,它們是樹型結構的葉子節點。此外,每個元素節點在子樹下面的元素節點都有一個定義為所有文本節點的串聯。例如,<principal> 的值是 EUR25000000.00 。更詳細的,<currency> 的值是“ EUR ”。
更普遍的情況是葉子元素的值和它們文本節點一樣。因為 XML 謂詞總是定義在葉子節點,在謂詞使用 /text() 通常不會影響查詢結果;例如,在清單 55 中的兩個查詢子句對數據執行了完全一樣的過濾器。然而,在返回子句中 /text() 會有所不同。第一個查詢返回“ <currency>EUR</currency> ”而第二個查詢只返回“ EUR ”。
清單 55. 一個有 /text() 的查詢和一個沒有 /text() 的查詢
xquery for $i in db2-fn:XMLcolumn("TRADES.TRADEDOC")/FpML/trade
where $i/termDeposit/principal/currency = "EUR"
return $i/termDeposit/principal/currency;
xquery for $i in db2-fn:XMLcolumn("TRADES.TRADEDOC")/FpML/trade
where $i/termDeposit/principal/currency/text()= "EUR"
return $i/termDeposit/principal/currency/text();
<TIP>一個有 /text() 的謂詞只有這個索引也用 /text() 定義時,才可以使用這個索引。這是為了確保在極少的情況或是非葉子元素定義的索引時的正確並一致的行為。例如,<principal> 的值是“ EUR25000000.00 ”,而 <principal>/text() 的值是空。
在清單 55 中的第一查詢可以使用圖 56 中的第一個索引卻不能使用第二個索引。在圖 55 中的第二個查詢可以使用第二個索引而不是清單 56 中的第一個索引。通常的建議是不要使用 /text(),無論是謂詞還是索引定義中。
清單 56. 定義了 /text() 的索引和沒有定義 /text() 的索引
create index tradeIdIdx1 on trades(tradedoc) generate keys using XMLpattern
'/FpML/trade/termDeposit/principal/currency' as sql varchar hashed;
create index tradeIdIdx2 on trades(tradedoc) generate keys using XMLpattern
'/FpML/trade/termDeposit/principal/currency/text()' as sql varchar hashed;
在非葉子節點上的 XML 索引
讓我們在看一下清單 54 的文檔小片段並記住 <principal> 的值是 EUR25000000.00 。你可以使用這個操作來編寫查詢連續的文本節點。
清單 57. 在一個非葉子節點上的謂詞
xquery for $doc in db2-fn:XMLcolumn("TRADES.TRADEDOC")/FpML/trade
where $doc/termDeposit/principal = "EUR25000000.00"
return $doc/termDeposit/maturityDate;
可以通過在索引路徑表述中指定非葉子節點對這些“連續”節點定義索引:
清單 58. 在非葉子節點上的索引
create index tdp on trades(tradedoc) generate keys using XMLpattern
'/FpML/trade/termDeposit/principal' as sql varchar(30);
這個索引不像一個關系意義上的復合索引,因為她的數據仍然來自於一個 XML 列。然而,如果你確認索引節點在 <currency> 之間 <amount> 不包含其它子節點的話還是有用的,因為這將在索引鍵值中包括不希望的數據。
<TIP>在一些意外情況下,很少對非葉子節點建立索引。你應該只在有明顯的好處的情況下才對非葉子節點建立索引,除非你對查詢謂詞和文檔結構非常了解。
當我們考慮非葉子節點的時候,我們應該注意另外一個在用通配符定義索引時可能出現的陷阱。假設在 /FpML/trade/termDeposit/* 上定義一個索引,這個索引對“ termDeposit ”元素的所有子元素都有一個條目。如果任何這些子元素是一個非葉子節點,那麼相應的鍵值就可能是多個節點的串聯。這也可能意外的超過 VARCHAR(n) 索引的限制。
在 XML 查詢中使用索引
在你定義 XML 索引時要謹慎,不過你可能會發現你的索引並是像你期望那樣被使用。或許某個查詢的性能是令人失望,然後你檢查它的查詢計劃,卻發現它執行了一個表掃描而不是一個索引掃描。我們將會列舉一些簡單例子來展示如何確認索引使用的正確性。
使用通配符查詢
匹配索引的兩個條件之一是定義索引的路徑表達式至少和在索引謂詞中的路徑表達式大體一樣。換句話說,如果索引確定並且查詢謂詞等於這個索引包含的節點的子集(或全部,不能超過),那麼一個索引就能被一個查詢使用。
圖 1. 索引使用的容量要求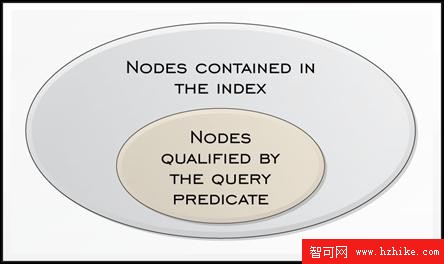
<TIP>對於查詢在它們的謂詞中使用通配符的情況下可能出現一個問題,它們可能等於超過候選索引所包括的節點。在這種情況下容量需求沒有得到滿足,索引將不會被使用。例如,在清單 60 中的查詢計算了所有涉及一個特定貨幣類型(EUR)交易的數目。
清單 60. 查詢謂詞中的通配符
select count(*) from trades t where XMLexists('$TRADEDOC[FpML//currency="EUR"]');
在路徑/FpML/trade/fxSingleLeg//currenc上的一個索引定義不能被用來評估清單 60 中的查詢。這個索引將提供一個僅對自己,而沒有滿足所有查詢條件中需要的元素,因此會被使用。
這種情況明顯是因為我們的樣本數據非常有限,在你沒有完全熟悉你的 XML 文檔結構的情況下,這很容易被不是用一個索引搞糊。你可能沒有注意到一個使用了一個(或多個!)通配符的謂詞匹配了的比你想象中要多的節點,而且個別情況下,超過了一個你期望使用的索引所包含的節點。
無論在什麼時候都最好是在查詢中避免通配符,並使用你想得到的元素和屬性的完整路徑。如果你使用了通配符(比如 //),那麼要確保你出於良好定義的原因,而不是想少打字。
在 XML 連接謂詞中的索引
在 7.1.2 章中,我們看到了在一個查詢謂詞定義中的文字值的類型如何定義比較類型,和它使用一個索引的資格。比如,由於沒有可以被識別的文字,一個判斷不可能用於一個連接謂詞。為了在 XML 連接謂詞中使用索引,你需要提供這個連接鍵的類型信息,這可以使用轉換函數來實現。
例如,讓我們用 partyId 元素來連接 TRADES 和 PARTIES 表並在每個表上創建一個正確的索引:
清單 61. 在可能的連接鍵上的索引
create index tptyid on trades(tradedoc) generate keys using
XMLpattern '/FpML/party/partyId' as sql double;
create index PPTyid on partIEs(partyinfo) generate keys using
XMLpattern '/Party/PtyID' as sql double;
然後我們執行一個連接來獲得一個有各方名字和交易時間的列表:
清單 62. 對交易和交易各方的連接
XQUERY
for $pdoc in db2-fn:XMLcolumn("PARTIES.PARTYINFO")/Party
for $tdoc in db2-fn:XMLcolumn("TRADES.TRADEDOC")/FpML
where $tdoc/party/partyId=$pdoc/PtyID
return <result>{$tdoc/trade/tradeHeader/tradeDate}{$pdoc/Name}</result>;
這個查詢不使用清單 61 中定義的任何索引。問題是連接查詢沒有包含關於 partyId 和 PtyID 可能數據類型的信息。我們可以知道 PartyId 的值是數字值,而 DB2 不是,所以它必須尋找所有類型的匹配值。這個索引定義限制鍵值如果是數字(SQL DOUBLE)並因此不包含其它類型的鍵值,比如字母字符串。結果就是 DB2 不能依賴這些索引來進行連接,因為它們可能只包含匹配值的一個子集。
如果你的興趣僅僅在匹配有數字值得 Party IDs,那麼可以使用索引。方法就是使用在連接鍵值上使用轉換函數。在這種情況下,你可以使用構造器 xs:double() 來指出它們是數字。協和在清單 63 中的 XQuery 和 SQL/XML 注釋中都有說明。
清單 63. 在連接鍵值上使用轉換函數進行連接
XQUERY
for $pdoc in db2-fn:XMLcolumn("PARTIES.PARTYINFO")/Party
for $tdoc in db2-fn:XMLcolumn("TRADES.TRADEDOC")/FpML
where $tdoc/party/partyId/xs:double(.) = $pdoc/PtyID/xs:double(.)
return <result>{$tdoc/trade/tradeHeader/tradeDate}{$pdoc/Name}</result>;
-- SQL/XML
select XMLquery('<result>{$TRADEDOC/FpML/trade/tradeHeader/tradeDate}
{$PARTYINFO/Party/Name}</result>')
from trades, partIEs
where XMLexists('$TRADEDOC/FpML/party[partyId/xs:double(.) =
$PARTYINFO/Party/PtyID/xs:double(.)]');
注意,這個查詢連接順序的 SQL/XML 版本,把 TRADES 表變成這個連接的內部表,這樣我們可以使用在 TRADES 表中的索引 tptyid 。這個查詢的 XQuery 版本有可能使用也有可能不是用索引,這取決於查詢優化器選擇什麼連接順序。
<TIP>總結,要在 XML 連接查詢中使用索引,應該隨時轉換連接謂詞為 XML 索引的類型。否則,查詢語義不會使用索引。如果 XML 索引被定義為 DOUBLE,就使用 xs:double 轉換連接謂詞。如果 XML 索引定義為 VARCHAR,就使用 fn:string 來轉換連接謂詞,等等,如下表所顯示的:
Index SQL type Cast join predicate using: Comment Double xs:double For any numeric comparison varchar(n), varchar hashed fn:string For any string comparison Date xs:date For date comparison Timestamp xs:dateTime For timestamp predicates
圖 64:在連接中使用的轉換函數類型
處理 XML 名稱空間
XML 名稱空間是一個 W3C XML 標准在 XML 文檔中提供了唯一的名稱元素和屬性。 XML 文檔可能包含來自於其它詞匯的元素和屬性,卻又有相同的名字。通過為每個詞匯給定一個名稱空間,解決了相同元素和屬性之間的容易混淆的問題。 DB2 版本 9.5 中所有 pureXML 功能都支持 XML 名稱空間,比如 SQL/XML、XQuery、XML 索引以及 XML 模式操作。我們回顧名稱空間聲明,然後展示如何在查詢和索引定義中使用名稱空間。
生命 XML 名稱空間
在 XML 文檔中,XML 名稱空間是由保留屬性XMLns聲明的,這些值必須包含一個通用資源標識符(URI)。 URIs 被作為標識符;它們通常看起來像一個 URL 不過他們沒有存在的網頁。一個名稱空間聲明也可以包含一個前綴,用來定位這個名稱空間的元素和屬性。
圖 65:一個使用名稱空間聲明來 INSERT 一個 FpML 文檔。第一個 XMLns 屬性沒有定義一個前綴因此並不是一個默認名稱空間。
<TIP>在這個沒有名稱空間前綴的域中的所有元素都不會自動繼承默認名稱空間和屬性。在文檔中聲明的第 2 個和第 3 個名稱空間為前綴“ fpml ”和“ xsi ”分別分配了它們的 URIs 。前綴“ fpml ”沒有在這個文檔中使用。前綴“ xsi ”被用來顯示屬於模式名稱表空間的屬性“ schemaLocation ”和“ type ”,因此有特殊的含義。例如,屬性 xsi:schemaLocation 定義了本文遵守的 XML 模式和在那裡可以找到這個模式。
清單 65. 把名稱空間聲明(部分清單)插入文檔insert into trades values (120,
'<FpML XMLns="http://www.fpml.org/2007/FpML-4-3"
XMLns:fpml="http://www.fpml.org/2007/FpML-4-3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
version="4-3"
xsi:schemaLocation="http://www.fpml.org/2007/FpML-4-3 ../fpml-main-4-3.xsd
http://www.w3.org/2000/09/xmldsig# ../XMLdsig-core-schema.xsd"
xsi:type="DataDocument">
<trade>
<tradeHeader>
<partyTradeIdentifIEr>
<partyReference href="party1"/>
<tradeId tradeIdScheme="http://www.MyGlobalIntl.com/trade-id">MyGlobal123</tradeId>
</partyTradeIdentifIEr>
<partyTradeIdentifIEr>
<partyReference href="party2"/>
<tradeId tradeIdScheme="http://www.NationalV.com/trade-id">123</tradeId>
</partyTradeIdentifIEr>
<tradeDate>2001-04-29Z</tradeDate>
</tradeHeader>
<bulletPayment>
… .
</FpML>');
查詢中的名稱空間
我們的查詢例子到目前為止都是假設元素和屬性名稱不是任何名稱空間的一部分。很重要的是要認識到如果不改變,這些查詢的例子將不會返回任何有名稱空間的 XML 文檔。
<TIP>這是因為一個沒有名稱空間的元素是不同於在名稱空間中有相同名字的元素。名稱空間是一個元素名稱的核心部分。讓我們來看下面測查詢:
清單 66. 如果沒有名稱空間的查詢select tradeid, t.*
from trades, XMLtable('$TRADEDOC/FpML'
columns
tradeDate date path 'trade/tradeHeader/tradeDate',
partyId1 integer path 'party[@id="party1"]/partyId' ,
partyId2 integer path 'party[@id="party2"]/partyId'
) as t;
這個查詢將把除了清單 65 中用 TRADEID 120 最新插入的文檔外的所有交易文檔返回,因為它的路徑表達式和謂詞不被元素和屬性所屬的名稱空間允許。確保返回所有和謂詞匹配的交易的一個簡單的辦法是,忽略名稱空間在名稱空間前綴使用通配符。通配符“ * ”匹配所有名稱空間也包括無名稱空間。這個查詢返回所有交易的行,無論文檔有沒有名稱空間:
清單 67. 查詢中使用名稱空間的通配符select tradeid, t.*
from trades, XMLtable('$TRADEDOC/*:FpML'
columns
tradeDate date path '*:trade/*:tradeHeader/*:tradeDate',
partyId1 integer path '*:party[@id="party1"]/*:partyId' ,
partyId2 integer path '*:party[@id="party2"]/*:partyId'
) as t;
<TIP>如果你知道所有你希望查詢的元素屬於一個特定的名稱空間,你就可以用 XMLNAMESPACES() 函數來指定名稱空間。對於 XMLTABLE,在 row-generating 和所有 column-generating 表達式中都應用了默認名稱空間。
清單 68. 聲明一個默認元素名稱空間select tradeid, t.*
from trades, xmltable(XMLNAMESPACES
(DEFAULT ‘ http://www.fpml.org/2007/FpML-4-3 ’ ), '$TRADEDOC/FpML'
columns
tradeDate date path 'trade/tradeHeader/tradeDate',
partyId1 integer path 'party[@id="party1"]/partyId' ,
partyId2 integer path 'party[@id="party2"]/partyId'
) as t;
注意,在圖 68 中的查詢只從一個和名稱空間定義匹配的交易文檔返回值,因為在我們樣本數據中的其它文檔沒有名稱空間。
<TIP>當你文檔中只出現一個名稱空間時,默認名稱空間是一個常用的解決方案,如果你想從多個特定的名稱空間中選擇元素和屬性你需要一個不同的方法。在這種情況下,在你的查詢中使用名稱空間前綴是最佳選擇。
注意,其它 SQL/XML 函數同樣需要處理名稱空間。在圖 69 中“ fpml ”前綴在 XMLQUERY 和 XMLEXISTS 函數中都有定義。沒有一個可以讓你對一個查詢甚至整個會話中的所有 SQL/XML 函數定義一個名稱空間的結構。
清單 69. 在 XMLQUERY 和 XMLEXISTS 函數中的名稱空間聲明select tradeid, XMLquery(
'declare namespace fpml="http://www.fpml.org/2007/FpML-4-3";
$TRADEDOC/fpml:FpML/fpml:trade/fpml:tradeHeader/fpml:partyTradeIdentifIEr')
from trades
where
XMLexists('declare namespace fpml="http://www.fpml.org/2007/FpML-4-3";
$TRADEDOC/fpml:FpML/fpml:trade/fpml:tradeHeader[
fpml:tradeDate=xs:date("2001-04-29Z")]')%
總結,在對用一個或多個名稱空間的文檔編寫查詢時要小心。所有 XPath 表達式都需要包括合適的默認名稱表空間或名稱空間前綴定義否則你的查詢將不會返回你期望的結果。
定義中的名稱空間
文檔中存在的名稱空間同樣影響他們所在的索引。
<TIP>有名稱空間的文檔的索引定義在它們的 XML 模式表達式中需要包含相同的名稱空間。在第 7.1 章中定義的索引沒有一個會包含在清單 65 中添加到 TRADES 表中文檔的,因為索引定義了沒有名稱空間的特定元素。
這裡有有兩個關於如何重寫清單 50 中索引定義的例子,因此會包含新的文檔。第一個例子定義了名稱空間前綴並在定義路徑的元素名稱中使用了它。第二個例子簡單定義了一個默認元素名稱空間,它應用與這個路徑中的所有元素。雖然符號不同,不過兩個定義是等價的並且你可以使用任何一個,但是不能兩個都用。
清單 70. 含有名稱空間聲明的索引定義create index thtdns1 on trades(tradedoc) generate keys using XMLpattern
'declare namespace fpml="http://www.fpml.org/2007/FpML-4-3";
/fpml:FpML/fpml:trade/fpml:tradeHeader/fpml:tradeDate' as sql date %
create index thtdns2 on trades(tradedoc) generate keys using XMLpattern
'declare default element namespace "http://www.fpml.org/2007/FpML-4-3";
/FpML/trade/tradeHeader/tradeDate' as sql date %
任何一個索引都可以在下面查詢中被使用。雖然查詢定義了一個明確的名稱空間前綴,第二索引(thtdns2)也可以被使用,因為它邏輯上和第一個等價。
清單 71. 一個有名稱空間並可以使用任何一個索引的的查詢select count(*)
from trades where
XMLexists('declare namespace fpml="http://www.fpml.org/2007/FpML-4-3";
$TRADEDOC/fpml:FpML/fpml:trade/fpml:tradeHeader[fpml:tradeDate
=xs:date("2001-04-29Z")]')%
然而,在清單 70 中的兩個索引定義都將包括有名稱空間定義的交易文檔,它們中任何一個都包括所有剩下沒有名稱空間的交易文檔。如果你想在索引中包括這兩種文檔的話,你可以在名稱前綴中使用通配符:
清單 72. 在名稱空間前綴中有通配符的索引定義create index thtdns3 on trades(tradedoc) generate keys using
XMLpattern '/*:FpML/*:trade/*:tradeHeader/*:tradeDate' as sql date %
這個索引也有資格在清單 71 中顯示的查詢中使用,因為它包含不管有沒有名稱空間的所有交易文檔。這把我們帶回了在 7.2.1 中討論過的索引“容量”需求。一個有名稱空間通配符的路徑表達式可能包含比有一個指定名稱空間的相同 XPath 表達式有更多的 XML 元素。因此,用名稱表空間匹配索引的規則是對我們已知規則的拓展。