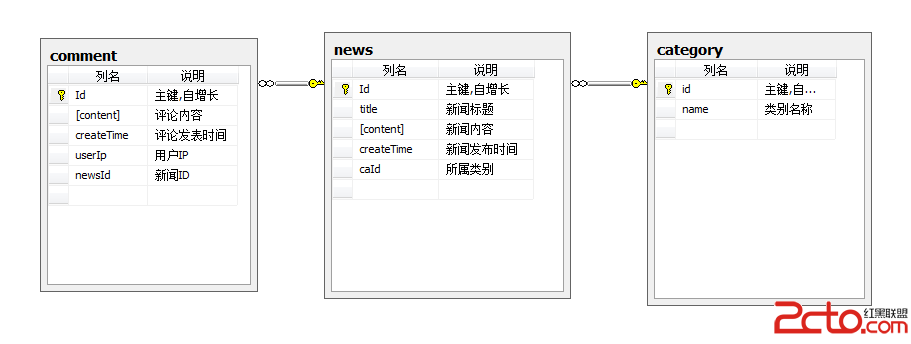
數據集群和 MDC 最佳實踐
MDC 是一個同時有不止一個維度數據集群的技術。然而,你也可以對一個維度使用 MDC 集群,就像你可以使用一個集群索引一樣。 MDC 的一個好處是它能保證數據一直處於集群狀態,永遠不需要執行一個重組操作來重新建立較高的集群命中率。
而且,不同於用 CREATE INDEX 語法創建的傳統索引,MDC 是對表中的每一行建立索引,MDC 通過塊把表中的數據編入索引。每個塊和表所在的表空間中的擴展數據塊有相同的大小。當 CREATE INDEX 命令創建索引時,每一行數據頁會同時被編入索引,每個 MDC 表索引 BLOCKS 可以包含上千條數據。 MDC 索引,也叫 BLOCK INDEX,通常只有 1/1000 大小基於索引的行,而且不光為索引提供了大量的保留存儲空間,同時也為所有 BLOCK INDEX 操作(索引掃描、索引 ANDing、索引 ORing,等等)提供了非常好的性能。
要理解 MDC,你必須首先理解一些基礎術語:單元是表容納數據的部分,它有一套唯一的維度值 ,是每個維度切片相交形成的。塊是存儲單元等於一個擴展數據塊(一個或多個頁面),塊被用來存儲一個單元。
MDC 表的塊索引
如上面所述,除了它們指向的是塊而不是記錄,塊索引在結構上和普通索引是一樣的。塊索引比普通索引要更小,因為塊大小是一個頁面中的平均記錄數的數倍。如圖 4 中所示,同每一行每一個單獨的輸入相比,在一個塊索引中每塊都有一個單獨的索引。結果就是,一個塊索引顯著降低了磁盤使用率並明顯加快了數據訪問的速度。
圖 4. 行索引和塊索引有什麼不同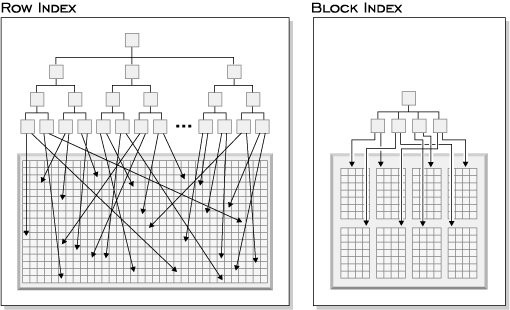
圖 5 中顯示的 MDC 表示一個物理組織,比如所有記錄有相同的“ Region ”以及“ Year ”值都同每個塊或擴展數據塊中連在一起。
圖 5. 一個多維集群表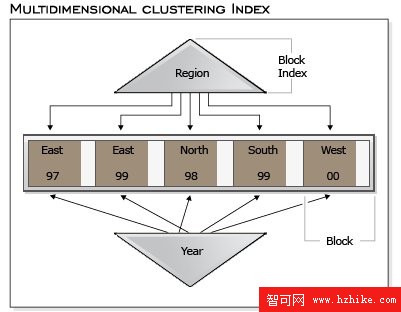
甚至一個只定義一個維度的 MDC 表也可以從這些 MDC 屬性中獲益,而且可以替換一個有集群索引的普通表。這個決定應該基於很多因素,包括組成工作負載的查詢以及表中數據的性質和分布。
在插入操作過程中自動維護集群
在 MDC 表中自動維護數據集群確保了使用復合塊索引。這些索引被用來根據在 INSERTS 操作過程中的表的維度來動態管理和維護數據庫的物理集群。當一個插入發生了,合成塊索引將會在與被插入記錄的維度值相應的邏輯單元中被探測到。
如圖 6 所示,在索引中的邏輯單元的鍵值,它的塊 ID(BIDs)的列表完整的給出了表中有這個本地單元維度值的塊列表。這限制了給插入記錄搜索可用空間的表的擴展數據塊的數目。
圖 6. 在‘ YearAndMonth ’,‘ Region ’上的復合塊索引
圖片看不清楚?請點擊這裡查看原圖(大圖)。
因為集群是自動維護的,所以對 MDC 表來說不需要重組操作來重新集群數據。然而,重組仍然被用來釋放空間。例如,如果單元有很多分散的塊,數據很少能夠匹配到,或者,如果表有很多指針溢出,這個表的重組操作將壓縮屬於邏輯單元的記錄到最少的塊中,用時也刪除指針溢出對。
使用 MDC 的益處
MDC 的意義非常深遠。在某些情況下它能將復雜查詢的性能提高 10 倍以上,同時你還可以用它轉入和轉出數據。還有下面顯示的其他好處:
MDCs 是多維的。例如,數據可以根據 DATE 和 LOCATION 維度完美集群;單元和范圍在新數據插入的時候會被自動創建。
MDCs 能和普通基於 RID 的索引、范圍分區和 MQTs 聯合使用。
MDCs 和內部查詢並行性、DPF(不共享)並行性、LOAD、BACKUP 和 REORG 操作同時使用。
MDC 維度,和范圍分區表不同,它是動態的;它會在表中自動創建新的單元,因為新單元是表示通過 SQL 操作(包括 JDBC、CLI,等等)或通過使用工具操作(比如 LOAD 和 IMPORT)插入的新的唯一數據。
MDCs 維護集群,而且正因為這樣就不需要 REORGs 來維護集群命中率了。
下面的例子顯示了如何定義一個 MDC 表:
CREATE TABLE T1 (c1 DATE, c2 INT, c3 INT, c4 DOUBLE,
c5 INT generated always as (INT(C1)/100) )
ORGANIZE BY DIMENSIONS (c5, c3)
ORGANIZE By 子句定義了集群的維度。這個表同時在 C5 和 C3 上被集群。 C1 是 coarsifIEd C5,它包含很少的不同值(天減少為月)。
注意:由 coarsifIEd 產生的 columns(s) 被使用在 MDC 塊索引中,以提高單元級別的數據清除。
MDC 設計的一個關鍵是謹慎選擇集群的維度。如果你選擇的集群維度產生太多的單元,存儲的成本會顯著的增加。知道其中的原因非常重要。在一個 MDC 表中,每個單元都會根據需要的存儲塊來分配。存儲塊是設計為和表所在表空間的擴展數據塊的大小相等。如果一個單元沒有數據,那麼存儲塊的數據是 0 。然而,在一個單元中存儲了若干記錄的典型表中會造成給單元分配一個或多個存儲塊。對每個有數據的單元都會有一批通常只包含了被部分填充數據塊。因此,在每個單元(不是數據塊)中造成浪費和存儲塊的大小成比例。新數據庫只有個在前面的數據塊被填滿(或快滿)後被創建。如果行被刪除,數據庫管理器會嘗試盡可能多的重用空間。
存儲塊被設計為同這個表所在表空間的擴展數據塊大小相等。如果這個表的單元數目非常大,存儲的浪費也會很大。如果 MDC 很差而且產生了大量的單元,表的存儲需求會非常顯著的增加,而且 MDC 的性能也會受損。然而,設計的 MDC 表只會比非 MDC 表大一點,而且在集群和數據轉入轉出上提供了較大的好處(將在後面討論)
圖 7 顯示存儲塊和單元分配。如圖所示,每個單元都包含了一批存儲塊。絕大多數塊被數據填充,不過對於每個單元的最後一個塊,卻是或多或少被部分填充的。
圖 7. MDC 單元存儲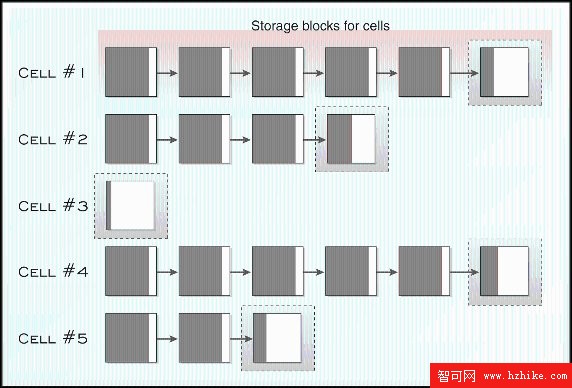
圖片看不清楚?請點擊這裡查看原圖(大圖)。
如果你有樣本數據或具體數據,你就可以使用 SQL 來為所有可能的 MDC 設計度量 MDC 需要的單元數目,如下所示:
SELECT COUNT(*) FROM (SELECT DISTINCT COL1, COL2, COL3 FROM MY_FAV_TABLE) AS NUM_DISTINCT;
對一個 3 維的 MDC 表來說,COL1、COL2 和 COL3 是 MDC 的維度。結果數乘以表的擴展數據塊大小將得出一個在表被轉換為 MDC 過程中擴展數據塊增長(不是大小)的上限。
MDC 的其他核心價值是 DB2 數據庫管理器在表的 MDC 維度上自動為 MDC 表創建索引。這些特殊的索引對塊而非行建立索引,這是可行的。因為在 MDC 表中數據會一直保持集群,因此在相同塊中的所有的行同樣確保有相同的鍵值。這是由於在 MDC 中數據是對塊進行索引而非記錄,所以塊索引通常是傳統基於行的索引的 1/1000 大小。結果就是在相關查詢運行時的性能好處,並把 INSERT、UPDATE 和 DELETE 操作的開銷減到了最少。
MDC 提供的功能方便了數據的轉入和轉出。索引條目指向一個塊而不是一行,塊索引又比典型的(rowID)RID 索引要小很多。因此,當 MDC 在轉入處理時只有很少的塊索引 I/O,這是因為塊索引只在塊被寫滿的時候被更新一次(而不是每一行插入)。由於 MDC 重用已經存在的空塊不需要分頁,所以插入也很快。插入時加的鎖也少了,因為他們發生在一個塊級別而不是行級別。表在轉入和轉出後不需要 REORG 數據。
MDC 存儲場景
想要為一個傳統事實表基於 Date、Product Name 和 Region 創建一個 MDC 。這裡有一些在創建 MDC 時需要考慮的變量:
一年有 365 天。
XYZ 公司有 100,000 個產品。
XYZ 公司有 10 個區域。
開始創建 MDC
如果 MDC 直接創建在 Date, Product 和 Region 列上,每天將會產生 1,000,000 個新的單元(1 x 100,000 x 10),而每年則會產生 365,000,000 個單元。
如果區域中事務非常少,這將會有很多分散甚至是空的頁面。這會導致大量沒有必要的空間分配數量巨大的單元(頁面)用來容納塊數據。這非常不好。
開始 MDC 的創建
使用函數來 coarsify 和限制 MDC 的基數,例如:
如果你在 Date 上使用月份函數,那麼每年你會有 12 條記錄。
如果你截取 Production Name 來挑出產品名稱的第一個字母,你就會有 26 條可能的結果。
保留 Region 的 10 個結果。
使用這個場景中的建議,MDC 將會每年產生 12*26*10 = 3210 個單元或每天 8-9 個單元。這會消除很多頁面沒有數據的情況,並對 MDC 提供合理的基數來獲得性能的好處。
MDC 運行時的開銷 / 收益
MDC 是設計來為查詢和許多刪除場景提供極大性能好處。雖然如此,在對使用了集群索引的集群表提供顯著的性能好處的同時,MDC 表這麼做所帶來的開銷還是超過了非集群表。 MDC 和非集群表相比第一個開銷是:
在一個非集群表上的 INSERT 操作,不需要通過索引訪問來判斷記錄被存放在磁盤的什麼位置。相比之下在 MDC 表上,在選擇哪個塊中有空間存放插入的記錄之前,需要通過訪問 MDC 復合塊索引來判斷記錄屬於哪個單元。
如果 MDC 表包括一個產生的列來 coarsify 其中的一個維度,每個 INSERT 將引起很少的處理開銷來為這一列計算生成值 , 就像 DB2 中的所有生成列一樣被物化,也就是被計算出來然後填充在記錄中。
然而,當和使用集群索引而集群起來的表相比較的話,MDC 有著顯著的性能優勢:
與一個集群索引相比,索引維護可以顯著的減少 INSERTs,因為 DB2 數據庫管理器僅只有在第一個鍵值添加到塊中時的時候才更新塊索引——不像一個 RID 索引,每一行插入表中都需要對索引進行更新。也就是說,如果每塊有 1000 條記錄,索引更新率就是 RID 索引更新率的 1/1000 。
索引更新也非常廉價,因為索引更小而且因此所以在樹中有更少的層。在 B+ 樹中有更少的層次,則意味著需要更少的處理來為索引插入判斷目標的葉子節點。
無論使用集群索引還是用 MDC 來進行索引,在這兩種情況下 DB2 數據庫管理器都將在 INSERT 到目標記錄的位置時訪問索引(塊索引的集群索引),並在 INSERT 過程中判斷記錄的目標位置。再強調一下這個索引非常小,而且樹的高度通常很短,因此搜索速度非常快。
判斷什麼時候使用 MDC,什麼時候使用集群索引
MDC 的價值要比集群索引高很多,因為它可以自動保證集群。根據 coarsification 的需求,MDC 的集群率通常可以達到 93%-100% 之間的某個值。相比之下,集群索引雖然可以在一開始就接近 100%,但是隨著時間的推移卻會變得不集群,因而需要花費時間來對數據重新集群。一般情況下,使用 MDC 在你的數據庫上創建和維護數據集群,除非:
MDC 需要 coarsification,而且你不能將一個生成列添加到你的表中。
你不能也不需要在表增長過程中將表的結果生成 MDC 版本。良好設計的 MDC 表一般比非 MDC 表大 2-15% 。
你會發現,由於 coarsification 的原因,MDC 集群將提供稍小的集群率(例如,93%)。而使用集群索引的話,為了提高集群率你需要周期性的執行 REORG 來達到這個比率。
使用下面的 MDC 設計的最佳實踐:
從找出等於、不等、范圍和排序謂詞使用的列開始,請選擇出你的 MDC 候選列。維度必須匹配你的轉入范圍才能提高數據轉入效率。
記住,要爭取密度!為每個已經存在的單元分配一個擴展數據塊 – ——不管單元中有多少條記錄。這樣可以通過最優的空間利用率來增強 MDC,盡量高密度的填充數據塊。
控制表的膨脹。保持盡可能低的單元數目並限制存儲擴展。 5% 到 10% 的增長對任何單個表都是合理的范圍(本文在下面章節討論 MDC 單元),但是也有例外,甚至也有兩倍於平常的增長,不過很少。
注意:BLOCK 索引與相應的表相比非常的小,在大多數情況下,你可以忽略它們的存儲需求。
Coarsify 一些維度來提高數據的密度。使用生成列來 coarsifications 表中基數非常少的列。例如,基於日期列的一部分 month-of-year 上創建一列,或使用(INT(列名))/100 來把 DATE 列從 Y-M-D 格式轉換成 Y-M 。CREATE TABLE Sales
(SALES_DATE DATE,
REGION CHAR(12),
PRODUCT CHAR(30), …
MONTH GENERATED ALWAYS AS
((INTEGER(DATE)/100) …
ORGANIZE BY (MONTH, REGION, PRODUCT)
查詢:
select * from sales
where sales_date> ” 2006/03/03 ” and date< “ 2007/01/01 ” ..
編譯器會生成附加的謂詞:
month>=200603 and month<=200701
為了減少空間浪費,可以指定一個更小的表空間擴展數據塊,這會減少你的 MDC 塊大小。
不要選擇太多的維度。很少有設計能在 MDC 有 3 個以上的維度卻不產生過多的存儲需求。
你擁有的維度越多,單元基數就會以指數級相應的增長。這使得控制表膨脹率 10% 的設計目標變得幾乎不可能實現。如果表過度膨脹(例如超過兩倍大小)不僅需要更多的存儲,同時也會因為部分填充塊的 I/O 增加而使集群失去優勢。
一個簡單的例子:考慮一個有三個維度適合集群的表,每個有 10,000 唯一值。如果這些列彼此之間沒有相互關聯,那麼對所有三個維度的集群就沒有 coarsification,這會產生 10,000 x 10,000 x 10,000 個單元,每個單元有一個部分填充塊。如果每塊是 1MB,那麼這個設計上的疏忽產生的代價就將是 500,000TB !
考慮只有一個維度的 MDC 。和傳統單維度集群索引相比,單個維度的 MDC 仍然有相當多的優點。有如下理由:
集群是有保證的。
MDC 表中的索引是用block創建的,而非row。這種索引大小只有傳統基於行的索引的 1/1000 。
用 MDC 轉出數據,提高了 DELETE 性能。 DB2 9.5 中在 MDC 上的 RID 索引更新是異步的。
MDC 可以很方便的轉入數據。
使用單維 MDC(如果需要可以 coarsification)強制進行集群來替代集群索引。集群索引需要付出很大的努力(不能保證集群質量)來集群數據,而且隨著時間的推移,數據將變得不再集群。與之相比,MDC 保證了數據集群性,避免了重組數據的需求(見上面“ MDC Scenario ”章節中的 coarsification)。
准備修補(在一個測試數據庫上)。在尋找一個好的 MDC 設計過程中,可能需要嘗試也可能會失敗。可以使用帶有– m C 選項(C 是集群搜索)的 DB2 設計顧問程序。也可以使用 db2mdcsizer 實用工具,這在某個 DB2 產品版本的 AlphaWorks 中提供。 MDC 的修改不會影響你的應用程序編程。
對一個有代表性的工作負載使用 DB2 設計顧問程序的 MDC 選擇能力來為現有表找出恰當的 MDC 維度。
數據庫分區(不共享 hash 分區)的最佳實踐
數據庫分區是一個在數據庫中跨多個彼此合作的實例以建立單個大型數據庫服務器的水平分布記錄的技術。這些實例可以位於一個服務器中、跨多個物理機器、或它們的組合。在 DB2 產品中,這個叫數據庫分區功能(DPF)。
數據庫分區允許 DB2 數據庫管理器擴充到上百個實例參與的大型數據庫系統。這個設計的可伸縮性能使很多復雜查詢的工作負載達到線性增長。這樣,因為數據庫分區接近線性的擴展特征以及數據規模能達到數百 T 以及上百個 CPUs,數據庫分區在數據倉庫和 BI 工作負載下變得非常流行。由於每個事物都會產生實例內部的通訊,而這即使很少卻也能嚴重影響在 OLTP 工作負載中常見的短期執行事務類型,因此這個架構在 OLTP 處理上用的較少。
不共享 hash 分區是把記錄 hash 分布到邏輯數據分區上。 Hash 分布的主要的設計目的是確保數據均勻分布到所有邏輯節點(因為范圍分區容易發生數據傾斜)。這些分區可能存在於一個服務器中或者分布到一批物理機器上,如圖 9 所示:
圖 9. 表上的 hash 分區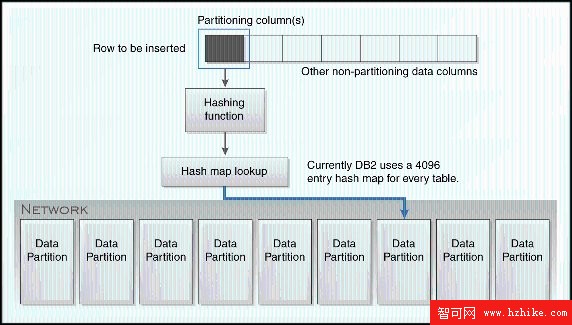
圖片看不清楚?請點擊這裡查看原圖(大圖)。
不共享數據庫的擴展性已經在大多數查詢工作負載接近於線性的擴展上得到了證明。同樣,模塊化的設計讓使它的存儲壓力、工作壓力或它們兩個也都線性增長。結果就是在過去十年中不共享結構在數據倉上的統治地位。數據庫分區可以在不影響現有應用代碼的情況下使用,而且對它們是完全透明的。使用 redistribution 實用工具,可以在線更改分區策略而應用代碼不會受到影響。
最主要的選擇就是決定哪些列用來 hash 分割每個表,並且這些列包含數據庫分區鍵值。這有兩個目標:
在各個分區間均勻的分布數據。這要求選擇那些高基數值的列為分區鍵,以確保所有行能均勻的分布到各個邏輯分區上。
把在 join 處理中數據庫分區之間的數據傳輸減少到最小。如果在 WHERE 子句中包含分區鍵,那麼將對被連接的行的表並置(避免移動數據)。
使用下面的數據庫分區的最佳實踐:
選擇用大量值(高基數)作為分區鍵,以確保表中的行能均勻的分布到各個分區。唯一鍵是一個很好的候選。
為了提高表並置,可以對一個經常進行連接的表使用分區鍵作為連接列(假如這些列有很高的基數來滿足均勻分布行的需求)。
選擇能獲得高基數並能在分區鍵中均勻分布行的最小的列數。減少分區鍵中的列數提高了列出現在連接謂詞中的可能性(提高表並置的幾率)。
確保唯一索引是分區鍵的超集。
對小表(表大小只有或不到數據庫大小的 3% 或不到最大的表的 5% ,是一個合理的法則)或經常被更新的表,使用復制 MQTs ,目的是: