簡介
數據集成是數據倉庫中的關鍵概念。ETL(數據的提取、轉換和加載)過程的設計和實現是數據倉庫解決方案中極其重要的一部分。ETL 過程用於從多個源提取業務數據,清理數據,然後集成這些數據,並將它們裝入數據倉庫數據庫中,為數據分析做好准備。
ETL 過程設計
盡管實際的 ETL 設計和實現在很大程度上取決於為數據倉庫項目選擇的 ETL 工具,但是高級的系統化 ETL 設計將有助於構建高效靈活的 ETL 過程。
在深入研究數據倉庫 ETL 過程的設計之前,請記住 ETL 的經驗法則:“ETL 過程不應修改數據,而應該優化數據。”如果您發現需要對業務數據進行修改,但不確定這些修改是否會更改數據本身的含義,那麼請在開始 ETL 過程之前咨詢您的客戶。
調制的 ETL 過程設計
由於其過程化特性以及進行數百或數千個操作的可能性,所以以精確方式設計 ETL 過程,從而使它們變得高效、可伸縮並且可維護就極為重要。ETL 數據轉換操作大致可以分為 6 個組或模塊:數據的提取、驗證、清理、集成、聚集和裝入。要安排好這些組,按照使這一過程獲得最大簡化、具有最佳性能和易於修改的邏輯次序來執行操作。下圖中展示了執行的次序。
圖 1. ETL 數據轉換過程的功能模塊設計
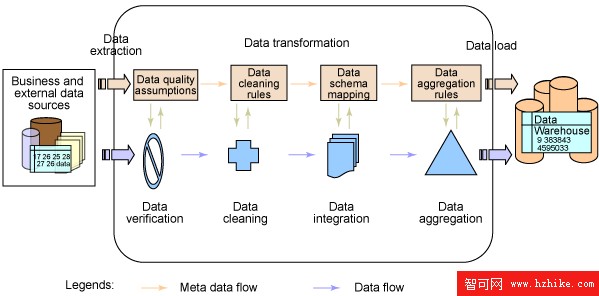
在項目的業務需求和數據分析階段,我們創建了數據映射信息。有許多中記錄數據映射的方式;ETL 數據映射表是指導 ETL 過程設計的最佳方式。您還可以將該表用作與業務客戶就數據映射和 ETL 過程問題進行交流的方式。ETL 數據映射表有不同的級別,如實體級別和屬性級別。每個級別中都具有不同級別的詳細數據映射信息。下表是一個實體級別的 ETL 數據映射表的簡化例子。該表中的每個“X”表示到操作細節或較低級數據映射文檔的鏈接。
表 1. ETL 實體映射表
源 驗證 清理 轉換 集成 聚集 目標 賬戶客戶 X X ? X X 客戶 信貸客戶 X X X 借貸客戶 X ? X 支票賬戶 X X ? X X 賬戶 儲蓄賬戶 X ? X 信貸賬戶 X ? X 借貸賬戶 X X ?
在 DB2 數據倉庫中實現 ETL 過程
DB2® Universal Database™ Data Warehouse Editions 為數據倉庫功能提供了改進的性能和可用性。DB2 Data Warehouse Center(DWC)是一個可視化的 ETL 設計和實現工具,它是 DB2 UDB 中的組成部分。這一節將查看如何使用 DB2 UDB(Version 8.2.1)Data Warehouse Center 設計和實現倉庫 ETL 過程。
創建倉庫控制數據庫
倉庫控制數據庫包含存儲數據倉庫中心(Data Warehouse Center)元數據所必需的控制表。在 Data Warehouse Center 的 Version 8.2 或更新的版本中,倉庫控制數據庫必須是 UTF-8(Unicode Transformation Format 或 Unicode)的數據庫。這一需求為 Data Warehouse Center 提供了擴展的語言支持。如果嘗試使用非 Unicode 格式的數據庫登錄 Data Warehouse Center,那麼您會收到無法登錄的錯誤消息。您可以使用 Warehouse Control Database Management 工具,將元數據從指定的數據庫遷移到新的 Unicode 數據庫中。
下面是創建和啟動新的倉庫控制數據庫的步驟:
確保啟動了 DB2 倉庫(Warehouse)服務器和相關的服務。在倉庫控制數據庫的管理窗口中,填入控制數據庫名、模式名(IWH)、用戶 ID 和密碼,並創建該倉庫控制數據庫。如果在以前版本的 DB2 DWE 上已經有一個倉庫,那麼還可以使用此過程將倉庫控制數據庫遷移到當前版本中。
通過新創建的或遷移的控制數據庫登錄到 DB2 Data Warehouse Center,如 圖 2 所示。確保使用與步驟 1 相同的用戶 ID 和密碼。如果倉庫控制數據庫是一個遠程數據庫,則必須對該節點和控制數據庫進行編目。
圖 2. 登錄 DB2 DWE 倉庫中心
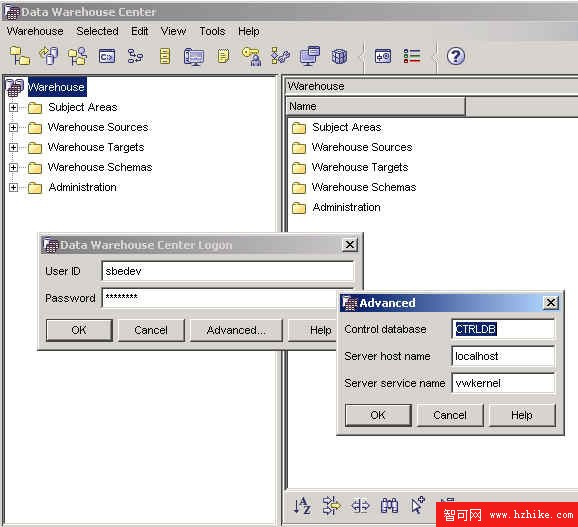
注意:DB2 Data Warehouse Center 的登錄窗口將允許您在多個倉庫控制數據庫中進行切換。當有許多項目或開發人員在同一 DB2 數據倉庫(Data Warehouse)服務器上工作時,此功能極其有用。
定義代理站點
倉庫代理(agent)管理數據源和目標倉庫之間的數據流。倉庫代理可用於 AIX®、Linux、iSerIEs™、z/OS™、Windows® NT、Windows 2000 和 Windows XP 操作系統,以及 Solaris™ 操作環境(Operating Environment)。
這些代理使用 Open Database Connectivity(ODBC)驅動程序或 DB2 CLI 與不同的數據庫進行通信。只需要幾個代理就可以處理源倉庫和目標倉庫之間的數據遷移。您所使用的代理數目取決於現有的連接配置,以及計劃遷移到倉庫中的數據量。如果需要同一代理的多個進程同時運行,則可以生成附加的代理實例。
代理站點是安裝了代理軟件的工作站的邏輯名稱。代理站點的名稱與 TCP/IP 主機名不同。一個工作站可以只有一個 TCP/IP 主機名。不過,您可以在一個工作站上定義多個代理站點。邏輯名稱將標識每個代理站點。
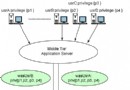
在設置數據倉庫時,必須定義倉庫將用來訪問源數據庫和目標數據庫的代理站點。Data Warehouse Center 使用本地代理作為所有 Data Warehouse Center 活動的默認代理。但是,您可能需要使用來自包含倉庫服務器的工作站的另一站點上的倉庫代理。您必須在 Data Warehouse Center 中定義該代理站點,從而標識安裝了該代理的工作站。Data Warehouse Center 使用這一定義來標識啟動代理的工作站。
圖 3. DB2 倉庫代理
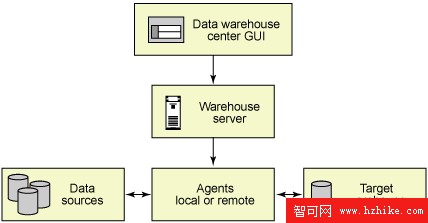
上圖說明了倉庫代理、數據源、目標和倉庫服務器之間的關系。
定義倉庫源
倉庫源指定將為倉庫提供數據的表和文件。Data Warehouse Center 使用倉庫源中的說明來訪問數據。DB2 Data Warehouse Center 支持所有主要平台上的大量關系數據源和非關系數據源,如下圖所示。
圖 4. 倉庫數據源
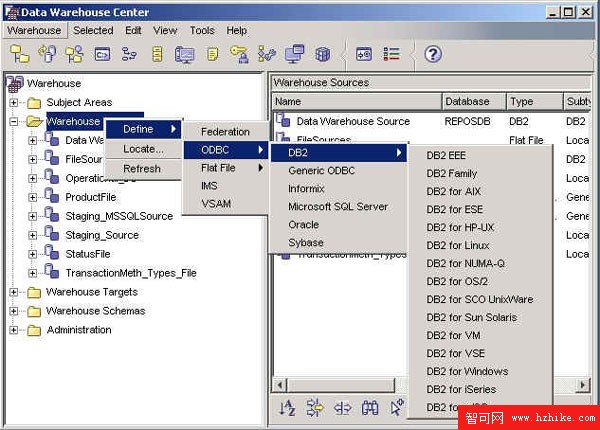
這使得配置從 DB2 Data Warehouse Center 到所支持數據源的連接變得極其容易。
在建立到數據源的連接並確定需要使用哪些源表之後,就可以在 Data Warehouse Center 中定義 DB2 倉庫數據源了。如果使用相對倉庫代理的遠程源數據庫,就必須在包含倉庫代理的工作站上注冊這些數據庫。
定義倉庫數據源的過程會根據數據源類型的不同而有所不同。下面是一個在 DB2 Data Warehouse Center 中定義關系倉庫數據源的例子。
為了在 Data Warehouse Center 中定義關系數據源,要執行以下操作:
在 Data Warehouse Center 中打開 Define Warehouse Source 記事本。
添加有關倉庫源的信息。
指定訪問倉庫源的代理站點。
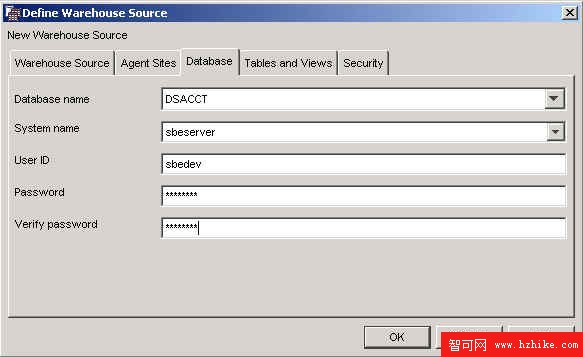
指定有關源數據庫的信息,如下圖 5 所示。
將源表和視圖導入倉庫源中。
授權倉庫組,以訪問倉庫源。
圖 5. 定義倉庫關系數據源
定義倉庫目標
倉庫目標是指包含已轉換數據的數據庫表或文件。您可以使用倉庫目標給其他倉庫目標提供數據。例如,一個中心倉庫可以向部門級服務器上的數據集市提供數據。有兩種創建倉庫目標的方法。一種是從現有的表或文件進行導入,另一種則是通過使用倉庫系統生成目標。
圖 6. 定義倉庫目標表
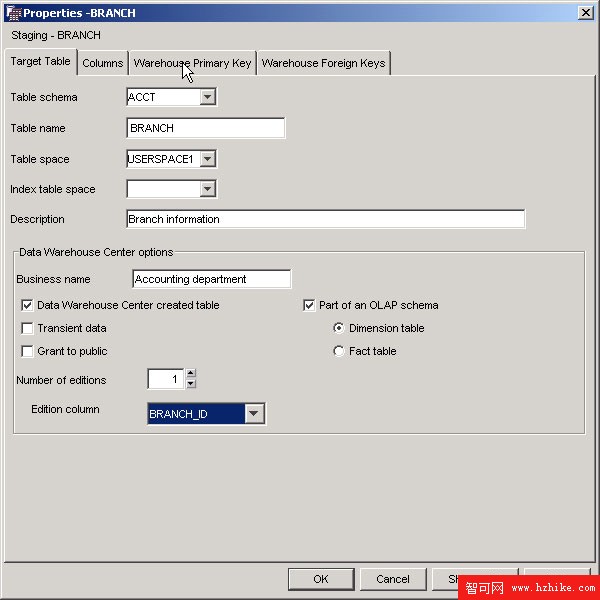
正如從 圖 6 中可以看到的,在定義 DB2 倉庫目標表時,可以指定是否由 DB2 Data Warehouse Center 創建該表,以及該表是否是 OLAP 模式中的一部分,這意味著它可能最終被用作多諸如星型模型之類的維數據模型中的一個維度或事實表。
定義倉庫主題領域、過程和步驟
倉庫步驟是對倉庫中單獨某一操作的定義。倉庫步驟定義如何移動和轉換數據。可以在 DB2 Data Warehouse Center 中使用的倉庫步驟類型有很多:
SQL(插入、更新和替換)
文件(FTP,文件數據的導入和導出)
DB2 程序(數據導出、裝入、表重組和統計數據更新)
倉庫轉換器(數據清理、鍵表和時間表的生成,以及翻轉和透視數據)
統計信息轉換器
在運行一個步驟時,可能發生倉庫源和倉庫目標之間的數據遷移或轉換。其中一個步驟就是 Data Warehouse Center 中的一個邏輯實體,該實體定義了以下內容:
到源數據的鏈接。
對輸出表或文件的定義和鏈接。
用來填充輸出表或文件機制(SQL 語句或程序)和定義。
填充輸出表或文件的處理選項或時間表。
倉庫過程包含為特定倉庫執行數據轉換和移動的一系列步驟。一個過程可以產生一個表或一組總結表(summary table)。過程還可以執行一些特定類型的數據轉換。
圖 7. 定義倉庫過程
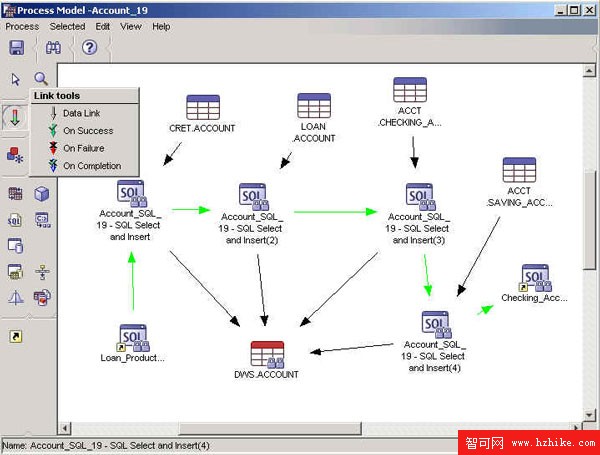
主題區域指定並劃分與邏輯業務領域相關的過程。例如,如果構建一個營銷和銷售數據的倉庫,那麼要定義一個銷售(Sales)主題領域和一個營銷(Marketing)主題領域。
倉庫過程和步驟模式
Data Warehouse Center 通過使用三種模式(開發、測試或生產)中的一種來劃分步驟,從而允許您管理步驟的開發。該模式將確定您是否可以修改步驟,以及 Data Warehouse Center 是否將根據其時間表運行步驟。升級步驟表示將該步驟移至更高的模式(開發 -> 測試 -> 生產)。
開發模式:在創建一個步驟之後,您就已經處在開發模式中。您可以在該模式中修改任何步驟屬性。在此模式下,倉庫為這一步驟所生成的目標表並不在目標倉庫中。如果需要運行這一步驟來執行測試,則必須將該步驟升級到測試模式。
測試模式:在步驟屬性中,可以指定使用 Data Warehouse Center 為該步驟創建目標表。當您將這一步驟升級到測試模式時,Data Warehouse Center 就會創建目標表。因此,當您將一個步驟升級到測試模式之後,就只能進行那些不會損壞目標表的修改。例如,當一個目標表的相關步驟處於測試模式時,就可以向該目標表添加列,但無法從目標表中刪除列。在測試模式下,可以單獨運行每個步驟。Data Warehouse Center 不會根據其自動時間表來運行步驟。
生產模式:為了激活時間表和任務流鏈接,必須將步驟升級到生產模式。生產模式表明步驟已經處於最終格式。在生產模式下,只能修改不影響該步驟所生成的數據的設置。您可以修改時間表、處理選項(除了填充類型)或關於該步驟的描述性數據。但您不能修改該步驟的參數。
可以在 Data Warehouse Center 中,或者通過外部觸發器程序在 DB2 Warehouse Center 外部對倉庫步驟進行升級和降級,並手工運行它。
DB2 倉庫外部觸發器程序
外部觸發器程序是調用 Data Warehouse Center 的倉庫程序。外部觸發器服務器腳本可以用於升級或降級 DB2 倉庫步驟,以及啟動或運行過程和步驟。在 ETL 開發和測試中,外部觸發器程序對於批量升級和降級倉庫過程和步驟特別有用。您還可以使用該腳本來管理 ETL 過程和步驟的執行次序。
外部觸發器程序包含兩個組件:外部觸發器服務器(XTServer)和外部觸發器客戶機(XTClIEnt)。XTServer 與倉庫服務器安裝在一起。XTClient 與倉庫代理安裝在一起,用於所有的代理類型。在從外部觸發器程序觸發一個步驟之前,必須在該步驟的 PropertIEs 記事本的 Processing Options 頁面上指定 Run on demand 選項。
下面是 Windows 平台上用於升級 ETL 步驟的外部觸發器腳本實例:
請確保 db2XTrigger.jar 和 common.jar 位於類路徑中:
CLASSPATH=%CLASSPATH%;%DB2PATH%toolsdb2XTrigger.jar;%DB2PATH%Javacommon.jar
從命令窗口啟動外部觸發器服務器:"%DB2PATH%javajdkbinJava" db2_vw_xt.XTServer <port_number>
其中,<port_number> 是倉庫服務器上外部觸發器的服務端口號。默認端口號是 11004。
創建並運行客戶端的腳本命令文件,該文件可能包含多行代碼。例如(在執行該文件時,在一行中包含了所有的參數):"%DB2PATH%javajdkbinJava" db2_vw_xt.XTClIEnt <server>
<port> <DWC_user> <passWord> <ETL_step> <command>
<wait_for_result>
其中:
<server> 是倉庫服務器。
<port> 是倉庫服務器上的外部觸發器服務端口號。默認端口號是 11004。
<ETL_step> 是您試圖升級的 ETL 步驟或過程的名稱。
<DWC_user> 是 Data Warehouse Center 的用戶 ID。
<command> 可以具有下列值之一:
populate/run a step
promote a step to test mode
promote a step to production mode
demote a step to test mode
demote a step to development mode
populate/run a process
verify that the Data Warehouse Center server is running
<wait_for_result> 是可選的。該參數表明外部觸發器程序是否要返回步驟或過程的處理結果。請選擇下列值之一:
1:等待步驟或過程完成。如果該步驟或過程成功完成了,則返回 0,或者如果該步驟或過程失敗,則返回一個錯誤。
0 或空白:不等待步驟或過程完成。
數據提取
數據提取是捕獲源數據的過程。有兩種捕獲數據的主要方法:
完全刷新
增量更新
完全刷新,顧名思義,只是對移入中間(staging)數據庫的數據進行完全復制。該復制可能替換數據倉庫中的內容,及時在新的時間點上添加完整的新副本,或者與目標數據進行比較,以便在目標中生成一條修改記錄。增量更新的關注重點是只捕獲源數據中修改的數據。
如何捕獲數據修改與數據源本身是密切相關的;它實際上是逐個(case-by-case)實現的問題。DB2 Data Warehouse Center 支持許多數據捕獲方法,其中包括直接用 SQL 選擇來捕獲所有數據或數據子集,用 FTP 來捕獲源數據源中的數據,數據文件的直接導入或裝入,以及數據復制。
提取大量數據
從倉庫數據源提取大量數據是所有數據倉庫項目中的一個重要問題。在 DB2 Warehouse Center 中,您可以采用許多方法:Select and Insert SQL 步驟或倉庫負載實用程序。
Select and Insert SQL
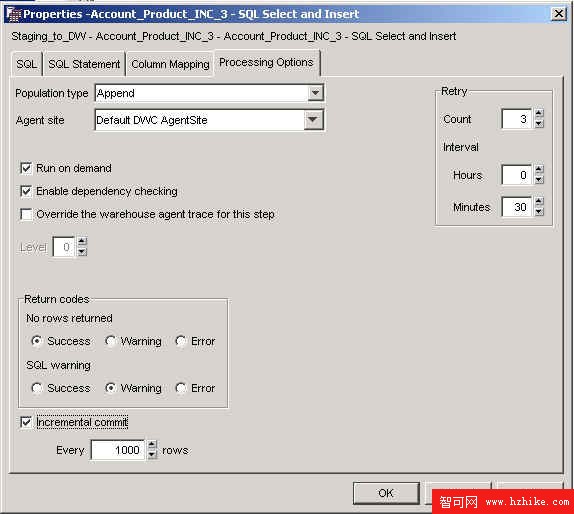
增量提交是一個允許您控制 Data Warehouse Center 所管理數據的提交范圍的選項。增量提交可用於 Select and Insert SQL 步驟中。在代理要移動的數據量十分大,以致於在整個步驟的工作完成之前 DB2 日志文件就可能已經填滿時,或者在需要保存部分數據時,可以使用增量提交。如果所移動的數據量超出了已經分配的 DB2 最大日志文件,SQL 步驟將以失敗結束。數據庫的性能可能會受到損害,因為在使用增量提交時,可能出現相當多的提交。在執行提交之前,要使用增量提交選項來指定將要處理的行數(大致為最接近的因數 16)。代理將選擇並插入數據,然後進行增量提交,直到成功完成數據移動為止。
圖 8. DB2 Warehouse SQL 的 Select and Insert 步驟的選項
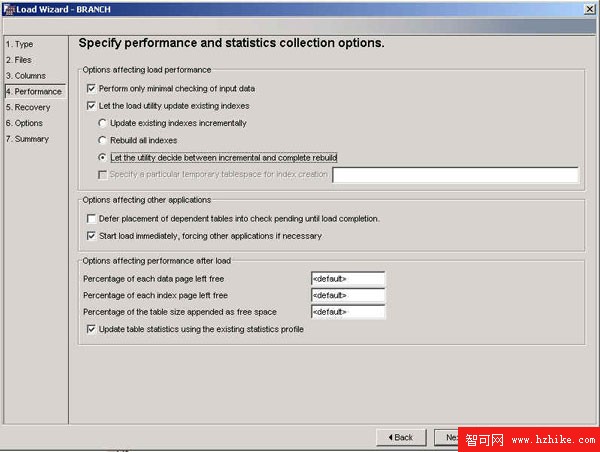
倉庫負載實用程序
DB2 Load 轉換器可以將大量數據從定界的(delimited)文件裝入 DB2 表,替換或追加數據庫現有的數據。默認情況下,DB2 Load 僅在日志中記錄進度消息,而不是真正地輸入數據,因此,在這裡不需要考慮日志文件的長度。在數據裝入結束之後,表空間會處於暫掛(pending)狀態;您需要備份該表空間,以使目標表可用。然而,DB2 Load 轉換器為您提供了一個保存輸入數據的副本的選項,如果使用該選項,則該表在數據裝入之後就立即可用。
您還可以指定要處理的最大行數,圖 9 中展示了其他許多性能相關選項。
圖 9. DB2 Warehouse 負載實用程序的性能選項
倉庫數據復制
DB2 Data Warehouse Center 的數據復制服務功能非常強大,並廣泛用於為數據倉庫中的完全刷新和增量更新捕獲數據。
對於增量更新,數據修改是從日志文件和時間取樣(time-sampled)源中捕獲的。提取日志數據的典型方法就是數據復制。DB2 數據復制服務是與 DB2 Data Warehouse 緊密集成在一起的,因此數據復制可以從 DB2 Data Warehouse Center 中進行配置和調度。
您可以使用 DB2 Data Warehouse Center 來定義復制步驟,它將復制所有 DB2 Data Warehouse 支持的數據源之間的修改。您所需要的復制環境取決於需要進行更新的時間以及處理事務的方式。數據倉庫(Data Warehouse)支持 5 種類型的復制:
用戶副本(User Copy):復制源表的完整壓縮副本。壓縮意味著目標表中包含一個主鍵,並且可用它來進行更新。
時間點(Point-in-time):在某一個時刻上的復制源表的完整的壓縮副本。目標表有一個主鍵和一個時間戳列。
基本聚集(Base aggregation):歷史表,為每個訂閱周期追加新行,在復制源表(基表)上使用 SQL 列函數的計算結果。
更改聚集(Change aggregate):歷史表,為每個訂閱周期追加新行,對包含了最近更改數據的復制源更改數據表使用 SQL 列函數的計算結果。
中間表(Staging table):生成包含所提交事務中數據的目標表的表。也稱作一致的更改數據表。
為了在 DB2 Data Warehouse Center 中設置復制,要執行以下步驟:
為復制准備源數據庫。
創建復制控制表。
在 DB2 Replication Center 中注冊源表。
將定義的復制源表導入 DB2 Data Warehouse Center 中。
在 DB2 Data Warehouse Center 中定義復制步驟。
創建倉庫步驟所需要的密碼文件。
在源數據庫的同一系統上啟動 Capture 程序。
在 DB2 Data Warehouse Center 中將復制步驟升級到測試模式或生產模式。
運行該步驟。在運行該步驟時,倉庫代理啟動 Apply 程序來處理復制訂閱。
為復制准備 DB2 源數據庫
為了使 DB2 源數據庫用於復制,必須將數據庫配置參數 LOG_RETAIN 設置為 RECOVERY,以保留數據庫日志文件。
將源數據庫配置參數 LOG_RETAIN 的值設置為 RECOVERY。該操作使數據庫處於 BACKUP PENDING 狀態。
備份源數據庫,以解除數據庫的 BACKUP PENDING 狀態。
檢查源數據庫的配置參數 LOGPRIMARY、LOGFILSIZ 和 LOGSECOND。確保這些值足夠大,能夠處理數據修改。
創建 capture 和 apply 控制表
可以在 DB2 Data Warehouse Center 中設置復制之前,必須在倉庫控制數據庫和目標數據庫中創建復制控制表。復制控制服務器上的用於捕獲復制數據的控制表。目標數據庫中的控制表用於應用復制數據。
下面是從 DB2 Replication Control Center 創建控制表的步驟:
對於創建 capture 控制表:在 DB2 Replication Control Center 中,右擊 Capture Control Servers 並選擇 Create Capture Control tables。在 Select a Server 窗口中選擇倉庫控制數據庫。
對於創建 apply 控制表:在 DB2 Replication Control Center 中,右擊 Apply Control Servers 並選擇 Create Apply Control tables。在 Select a Server 窗口中選擇倉庫目標數據庫。
對於創建 capture 控制表:選擇選項 Host sources for replication and capture changes to those sources。
對於創建 apply 控制表:選擇選項 Apply captured changes to target tables。
輸入合適的大小值。下表中的值是一個實例: 問題 回答 您將擁有多少源表? 少於 100 對於一個源表,您通常擁有多少目標表? 1 隔多久將數據應用到目標表? 每天 您期望一天捕獲多少事務? 1
保留 ASN 的默認控制表模式,以及 TCASNCA 和 TCASNUOW 的默認表空間。選擇 Run Now 來創建復制控制表。
為進行復制而注冊源表
注冊源表將告訴 DB2 需要捕獲哪些表修改。在 DB2 Data Warehouse Center 中使用表或視圖作為復制源之前,必須使用 DB2 Replication Center 將之定義為復制源。
在 DB2 Replication Center 中,選擇 SQL Replication > Capture Control Servers。選擇源數據庫,然後定位至 Capture Schemas。選擇模式名(ASN)並定位至 Registered Tables。
選擇合適的源表,並保留這些表的默認設置。選擇 Run now 注冊用於復制的源表。
將源表導入 Data Warehouse Center
在 DB2 Data Warehouse Center 中,檢查 Warehouse Sources 下面所列的數據庫或表。如果沒有列出復制源數據庫或表,則將其作為倉庫數據源進行導入或添加。
將目標表導入 Data Warehouse Center
在 DB2 Data Warehouse Center 中,檢查 Warehouse Targets 下面所列的數據庫或表。如果沒有列出復制源數據庫或表,則將其作為倉庫目標導入。盡管這些表可能已經列出,但仍需要重新導入它們,讓 DB2 DWC 知道已經為進行復制注冊了這些表。
在 Data Warehouse Center 中定義復制步驟
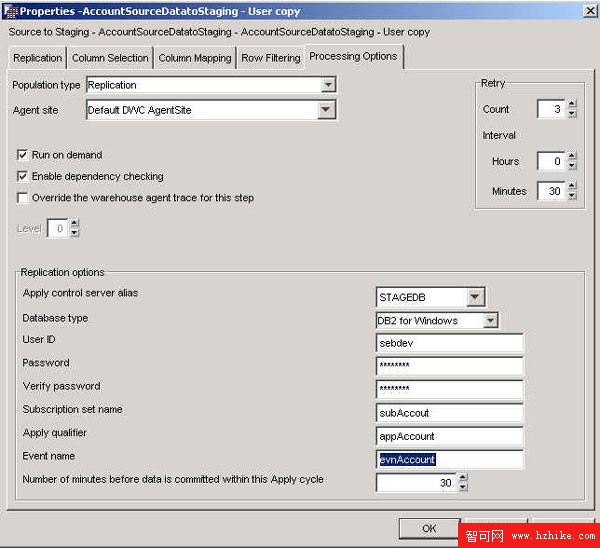
定義復制步驟與定義其他倉庫步驟十分相似。您可以在復制倉庫步驟中定義 5 種類型的復制步驟:用戶副本、時間點、基本聚集、更改聚集和中間表。(這些與 上面 所解釋的步驟相同。)
默認情況下,設置復制步驟是為了生成目標表。如果需要將復制步驟鏈接到現有的目標表中,那麼可以雙擊該目標表來打開 PropertIEs 窗口。在第一個選項卡上,啟用選項 Data Warehouse Center created this table。然後使用數據鏈接工具來將復制步驟連接到目標步驟上。在進行連接之後,返回到目標表的屬性,然後取消選項 Data Warehouse Center created this table。
在使用現有的用戶創建的目標表時,請特別小心,它與 DWC 生成的目標表相反。正如前面提到的,在將復制步驟降級到開發模式時,DWC 將刪除 Apply 以及與這些步驟相關的訂閱集。在升級步驟時,將重新創建它們,而且因為 ApplIEs 在此時是新的,所以 Capture 程序將認為它需要向目標表提供完全刷新。如果已經在每個目標表上啟用了 Data Warehouse Center created this table 選項,那麼將在降級時刪除這些表,並在升級時重新創建它們,(以及 Apply 程序、訂閱集和表),這些表將為空,准備各自接收數據的完全刷新。但是,如果從不刪除這些表,那麼數據都會保留著,並且如果執行完全刷新,那麼通過外鍵連接目標表時很可能會發生錯誤。在作為已填充的另一表的外鍵的目標表上,完全刷新的 Apply 部分將失敗,因為不可以從父表刪除它。
圖 10 說明倉庫 User Copy 復制步驟的屬性,其中包括數據源和目標表之間的數據映射、復制訂閱集名稱、事件名、應用限定符(有關的細節,請參閱下一小節)和用戶 ID/密碼。
圖 10. 定義倉庫用戶副本復制步驟
使用 asnpwd 實用程序創建密碼文件
對於 Version 8 或更新版本的 Data Warehouse Center 中的復制,必須通過使用復制程序 asnpwd 來設置並維護復制密碼文件。
復制密碼文件是加密的。Data Warehouse Center 復制步驟假定用於復制步驟的密碼文件是:
位於由環境變量 VWS_LOGGING 指定的目錄中。
名為 <applyqual>.pwd,其中 <applyqual> 是 Data Warehouse Center 復制步驟的應用(Apply)限定符。
在啟動 Apply 程序之前,Data Warehouse Center 代理從該文件向 Apply 程序命令添加用戶 ID 和密碼。
為了創建 pwd 文件,在第一次使用 asnpwd 時,需要打開 DB2 命令窗口。然後切換至 LOGGING 目錄(例如,C:Program FilesIBMSQLLIBLOGGING),運行以下命令:
asnpwd init encrypt passWord using applyqual.pwd
然後添加用戶 ID 和密碼:
asnpwd add alias db id <userID> password <passWord> using applyqual.pwd
除了對所有的應用限定符重復該命令之外,您可以只創建一次 pwd 文件,然後為每個應用限定符制作該文件副本,將其重新命名為 applyqual.pwd —— 假定復制步驟都使用相同的數據庫、用戶 ID 和密碼。
啟動 capture 程序
您可以從 DB2 Replication Center 啟動復制 capture 控制服務器。啟動 Capture 程序將啟動對復制啟用的源表進行的數據庫日志記錄修改,其中包括刪除、插入和更新。請確保您所指定的日志記錄目錄有足夠大的空間,可以處理修改數據量。
您還可以通過將 capture 程序保存到文件中並從命令行運行它,或者通過將 capture 程序保存為任務來啟動它。
將復制步驟升級到測試或生產模式
在 DB2 Data Warehouse Center 中,將復制步驟升級到測試或生產級別。在升級步驟時,DB2 將創建訂閱集和 Apply 程序,並在降級步驟時刪除它們。
在 DB2 Replication Center 中,可以在數據庫名下面發現新生成的 Subscription Sets 和 Apply QualifIErs。您可能需要刷新該視圖。在訂閱集的屬性中,可以看到 DB2 Data Warehouse Center 已經為您將源映射到目標表列。
可以修改測試模式中復制步驟的屬性,只要不將復制降級到開發模式,修改就會有效。下次將復制步驟降級到開發模式時,這些修改將會丟失。
DB2 復制錯誤記錄
如果您有麻煩,則可以在日志記錄目錄(通常為 C:Program FilesIBMSQLLIBLOGGING)中找到日志文件的默認位置。對於 capture 程序的錯誤,可以檢查文件 DB2.<source db name>.<replication schema name>.CAP.log。(例如:DB2.DSACCT.ASN.CAP.log)
名為 <ApplyName>.trc 的文件通常為 Apply 相關的錯誤提供良好的錯誤處理信息。
文件 DB2.<target db name>.<Apply name>.APP.log 還包含一些與 Apply 相關的信息。(例如:DB2.STAGEDB.APPLYPROD.APP.log)
數據驗證
在項目的業務數據分析階段,您產生了一組數據質量假設。這些假設將指定客戶和解決方案提供者雙方在數據質量問題上的職責。解決方案提供者通常關心數據清理和增強問題。客戶至少要關注僅僅可以在數據源本身中解決的問題,以及與解釋數據含義相關的數據質量問題。例如:
丟失的數據恢復。
模糊的數據轉換。
業務操作應用程序相關的數據問題 —— 只能從應用程序本身解決的數據質量問題。
您應該在項目合同文檔中包含數據質量假設,因為如果沒有用正確的方法及時解決業務數據的質量問題,它可能嚴重影響項目時間表。數據質量假設可能是與客戶進行時間表協商的一個好基礎。
即使假設客戶將承擔其責任,解決他們業務數據源中的數據質量問題,將來仍然可能在業務數據源中產生質量較差的數據。在那些數據對後面的 ETL 過程產生負面影響之前,實現數據驗證 ETL 篩選器模塊來拒絕它們就顯得十分重要。數據驗證包含許多檢查,其中包括:
屬性的有效值(域檢查)。
屬性在剩余行的環境中是有效的。
屬性在該表或其他表中相關行的環境中是有效的。
關系在該表和其他表中的行間是有效的(外鍵檢查)。
這並非是一個詳盡的列表。它僅僅強調了數據驗證的一些基本概念。
錯誤處理是一個確定如何處理不盡人意的(less-than-perfect)數據的過程。可以暫時拒絕這些數據,將數據存儲起來以便在固定領域中對它們進行修正,或者將其缺點傳遞給數據倉庫。所拒絕的數據將存儲在客戶可以訪問的位置;請確保每次發生數據的拒絕時,都會通知您的客戶。應該允許稍後將已修理的遭拒絕的業務數據移至數據倉庫中。
DB2 Data Warehouse Center 中的 Clean Data 轉換器可以用於基本的數據驗證目的。您還可以構建自己的數據驗證 SQL 步驟或特殊的數據驗證步驟來進行復雜的數據驗證。
數據清理
數據清理是清理有效數據,使之更精確更有意義的過程。數據清理包括下列等任務:
從數據源的數據合並。
域轉換和同步。
數據類型和格式的轉換。
用於不同目標表的數據分離(Data splitting)。
數據合並的一個常見例子就是姓名和地址信息。客戶的姓名和地址信息通常存儲在多個位置上。經過一段時間,這些信息可能就不同步了。為客戶合並數據通常比較困難,因為用於匹配不同客戶映像的數據不再匹配。數據增強將重新同步這些數據。
您可以使用 DB2 Warehouse Center 中的 Clean Data 轉換器來執行源數據上的基本清理、替換和映射操作。Clean Data 轉換器操作源表中步驟所訪問的特定數據列。然後,轉換器在您的步驟所寫入的目標表中插入新的行。根據您所選擇的處理選項,將無法清理的數據寫入目標錯誤表中。在將數據作為過程中一部分進行裝入或導入之後,您還可以使用 Clean Data 轉換器來清理和標准化數據值。
Clean Data 轉換器提供了下列可供指定的清理類型:
Find and replace:在規則表的 Find 列中定位所選擇的源列值,然後在目標表中用規則表中相應的替換值替換該值。規則表是這種清理類型所必需的。規則表指定 Clean Data 轉換在查找和替換過程中將使用的值。
Numeric™ clip:縮短超出了指定范圍的數字輸入值。范圍內的輸入值將不加修改的寫入輸出。范圍之外的輸入值將由下界替換值或上界替換值進行替換。規則表是這種清理類型所必需的。
Discretize into ranges:基於規則表中的范圍執行輸入值的離散化(discretization)。規則表是這種清理類型所必需的。如果允許該清理類型為空(null),則必須在規則表的 Bound 列中放入 null 值。
Carry over with null handling:指定輸入表中要復制到輸出表中的列。您可以從輸入表中選擇多個列移至輸出表中。規則表不是這種清理類型所必需的。這種清理類型允許您用指定的值替換空(null)值。您還可以拒絕 null,並將所拒絕的行寫入錯誤表中。
Convert case:將源列中的字符從大寫轉換成小寫,或從小寫轉換成大寫,並將其插入目標列中。默認情況下,將源列中的字符轉換成大寫。規則表不是這種清理類型所必需的。
Encode invalid values:用指定的值替換沒有包含在您所使用的規則表的有效值列中的所有值。您要在 Clean Data 轉換器的 PropertIEs 記事本中指定替換值,並且必須指定與源列數據類型相同的替換值。例如,如果源列是數字類型的,則必須指定一個數字型的替換值。有效值在寫入目標表時不會發生改變。規則表是這種清理類型所必需的。
大多數清理類型都有一個 Matching Options 窗口,用於指定希望用來處理匹配的方式。
數據集成
數據集成是將多個數據源聯合成一個統一數據接口來進行數據分析的過程。數據集成是倉庫數據轉換過程中最重要的步驟,也是數據倉庫設計中的關鍵概念。
數據集成可能極其復雜。在該模塊中,可以應用數據集成業務規則以及數據轉換邏輯和算法。集成過程的源數據可以來自兩個或更多數據源;它通常包含不同的連接操作。源數據還可能來自單個數據源;該類型的數據集成通常包含域值的合並和轉換。集成結果通常生成新的數據實體或屬性,易於終端用戶進行訪問和理解。
數據聚集
數據聚集是收集並以總結形式表達信息的過程。數據聚集通常是數據倉庫需求的一部分,它通常是以業務報表的形式出現的。
在多維模型中,數據聚集路徑是維度表設計中的重要部分。在數據存儲庫或數據倉庫中,數據聚集的級別是逐個(case-by-case)確定的。因為數據倉庫幾乎仍然都是關系數據模型類型的,所以最好是建議您的客戶從數據集市構建業務報表。但是,某些客戶喜歡直接從數據倉庫構建報表。本例中,將考慮在倉庫數據模型中進行數據聚集。請確保數據聚集表與其余的倉庫數據模式相對分隔,因此,報表的業務需求修改將不影響基本的數據倉庫數據結構。
將數據裝入倉庫目標表
將數據移至中心數據倉庫中的目標表通常是 ETL 過程的最後步驟。裝入數據的最佳方法取決於所執行操作的類型以及需要裝入多少數據。您可以通過兩種基本方法在數據庫表中插入和修改數據:
SQL insert/update/delete(IUD)
成批 load 實用程序
大多數應用程序使用 SQL IUD 操作,因為它們進行了日志記錄並且是可恢復的。但是,成批加載操作易於使用,並且在裝入大量數據時速度極快。使用哪種數據裝入方法取決於業務環境;應在 ETL 設計文檔中指定裝入方法。
ETL 數據拒絕的處理
如何處理拒絕的業務數據是 ETL 設計中的重要問題。當業務數據違背下列條件時將遭到拒絕:
業務數據質量假設。
數據參照完整性。
ETL 過程中所實現的業務數據集成規則。
您應在數據倉庫開發人員/管理員和終端用戶都同意的地方存儲遭拒絕的業務數據。被拒絕的業務數據中的問題的解決是數據倉庫維護中的一部分;它通常是屬於客戶的職責。因為處理這類問題需要域知識和數據庫技能,所以數據庫管理員和終端用戶都應該參與該工作。修復的業務數據最終將重新進入 ETL 周期,從而流入數據倉庫。
ETL 過程和步驟的執行次序
執行次序是另一個重要的 ETL 設計問題。盡管從數據倉庫服務器執行了越來越多的並行處理,但是並非所有的 ETL 過程都可以並發執行。有許多影響執行次序的因素:
實體依賴性:參照完整性的實施決定了表和對象的依賴性。例如,父實體表需要在子數據或關系表之前進行裝入。
屬性依賴性:屬性依賴性通常意味著屬性值是基於一個或多個屬性的一個或多個值進行計算的。
ETL 邏輯模塊:ETL 模塊設計次序通常決定了 ETL 過程中 ETL 步驟的執行次序。在數據集成步驟之前,需要驗證並清理數據是很易於理解的。
數據集成依賴性:數據集成業務規則通常包含對象和數據依賴性。
在倉庫過程中,執行次序是在設計階段使用 圖 7 所示的倉庫鏈接工具進行定義的。您可以定義倉庫過程中步驟之間的捷徑,以控制過程的執行次序。
運行倉庫 ETL 步驟
您可以隨需應變地運行步驟,或者按照下列方法來安排將運行的步驟:
在指定的時間
只有一次
重復地,例如每個星期五
依次,在一個步驟結束時,下一個步驟才開始運行
在完成時,不管是成功還是失敗,都將開始另一個步驟
如果您安排一個過程,該過程中的第一個步驟就會在安排的時運行。
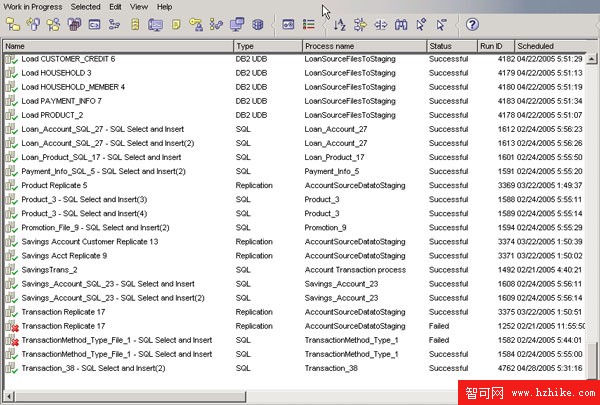
圖 11. DB2 Warehouse Work in Progress 窗口
您可以組合這些方法來運行一個過程中的步驟。您可以安排第一個步驟在指定的日期和時間運行。當該步驟處於生產模式時,這些時間表和級聯(cascade)就是活動的。在安排好第一個步驟之後,您可以指定另一步驟在第一個步驟運行之後開始,並指定第三個步驟在第二個步驟運行之後開始,等等。
您可以安排過程和步驟,並指定一個過程在另一個過程運行之後開始。您必須小心地將步驟組合成有意義的過程,以便可以正確地調度和指定過程的任務流。通過 Scheduler 記事本的 Process Task Flow 頁面,您可以基於一個過程的完成來啟動另一個過程。
Work in Progress 窗口允許您監控 Data Warehouse Center 中所有運行或計劃運行的步驟和過程的進度。Work in Progress 窗口為正在運行的步驟或過程顯示了一個條目,其中包含 Populating 狀態。如果處理失敗,可以使用 Show Log 動作找到問題所在。
管理 ETL 元數據
元數據管理對於 ETL 的有效開發和操作至關重要。ETL 元數據包括 ETL 過程設計、ETL 過程執行歷史、被拒絕的數據過程記錄、調度信息、數據增長和存儲管理記錄,以及用戶數據訪問記錄中所涉及的所有東西。
您可以導出 Data Warehouse Center 中所存儲的元數據,並且還可以從另一元數據源導入元數據。
導出元數據
您可以使用 Data Warehouse Center 導出功能來導出主題、過程、源、目標和用戶定義的程序定義。在導出對象時,所有的隸屬對象在默認情況下都將導出到標記語言文件或 XML 文件中。您可以導出下列類型的元數據:
標記語言(XML 格式)
公共倉庫元模型(Common Warehouse Meta-model)元數據
DB2 OLAP Integration Server 元數據(僅在 Windows 上)
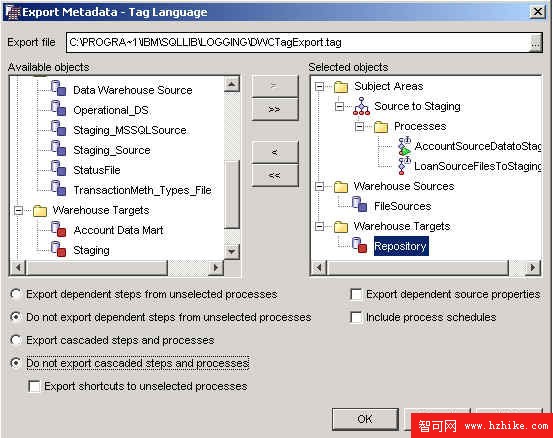
默認情況下,導出包括所選擇的對象和所有選擇對象引用的對象。例如,如果您選擇導出一個過程,那麼就包括了步驟所使用的源和目標、隸屬的步驟和隸屬的過程。
在將元數據導出到標記語言時,您可以通過取消 Export dependent source propertIEs 選項,在導出中排除源定義。如果這樣做,則必須在導入該標記文件之前在目標系統中定義源,以避免錯誤。
您可以限制導出對象的數目,減小標記文件的大小。默認情況下,導出操作包含具有數據依賴性的步驟。例如,考慮下列場景:過程 P1 包含用於填充 T1 的步驟 S1,而過程 P2 包含步驟 S2,而 S2 包含作為源的 T1,因此可以建立下列依賴性:S1 –> T1 –> S2 –> T3。如果您僅導出過程 P2,那麼 P1 也將導出到標記文件中,因為 S2 依賴於 S1 的數據。數據依賴性反向也成立。因此,即使您僅導出 P2,P1 也會包含在標記文件中。分開導出 P1 和 P2 不會有什麼幫助,因此最佳方法就是將其一起導出。當將元數據導出到標記文件時,您可以啟用選項 Do not export dependent steps from unselected process 來排除相依賴的步驟。
除了數據依賴性,您還必須考慮級聯(cascading)。可以考慮過程 P5 中的一個步驟,它包含到過程 P6 中某一個步驟的捷徑。如果導出 P5,那麼 P6 也會被導出。本例中,導出通過捷徑級聯向下轉到下一步驟。默認情況下,導出操作包括級聯操作和過程,無論在導出到標記文件時是否提供一個機會,使之不包括級聯步驟和過程。
圖 12. 倉庫元數據導出
導入元數據
您還可以導入對象定義,以便在 Data Warehouse Center 系統中使用。
在導入元數據時,所有對象都分配給標記語言文件中指定的安全分組。如果沒有指定安全分組,那麼所有對象都將分配給默認的安全分組。
您可以導入下列類型的元數據:
標記語言文件
公共倉庫元模型(Common Warehouse Metamodel)元數據
ERwin
IBM MQSerIEs
Trillium
提示:
如果您將標記語言文件從一個系統移至另一系統,則必須移動與之相關的所有文件(例如:源文件),它們必須位於在同一目錄中。
如果導出具有未鏈接的捷徑的過程,然後導入另一控制數據庫作為 .tag 文件,那麼未鏈接的捷徑數據將導致錯誤 DWC3142:“<dirID> was not found in the Data Warehouse Center control database。”該錯誤顯示在未鏈接的捷徑 dirIDs 沒有進行轉換時,它們會回到初始的控制數據庫。
導出和導入元數據的提示:
因為倉庫的導入和導出格式取決於版本,所以無法使用來自前面版本的導出文件從一個版本的 Data Warehouse Center 遷移到另一個版本的 Data Warehouse Center。
導出和導入過程都使用大量系統資源。當您導出對象定義時,可能需要限制其他程序的使用。當您進行大型導出操作時,可能需要將倉庫數據庫的 DB2 應用程序堆數大小增加到 8192。
與倉庫數據源、目標和代理相關的服務器名和用戶名都要導出到標簽文件中,而且在導入到新系統之後,需要對這些信息進行更新。不過,不用導出密碼,因此您需要提供密碼信息,以訪問倉庫數據源、目標和代理。
設置原型
一旦實現了數據倉庫項目業務域領域的第一個分組,您就應設置倉庫實現原型,以驗證:
所使用的技術
設計和實現
項目業務需求
倉庫性能
技術質量保證
當開始與用戶一起驗證設計時,實地體驗(hands-on)測試是最好的方法。讓用戶嘗試通過對測試目標的操作來回答問題。記錄測試目標無法提供所需數據的所有領域。必須與終端用戶一起執行建議解決方案的功能性驗證。這通常導致終端用戶暫時使用所構造的解決方案,讓他們有機會使用本地解決方案中(可能是數據集市中)已經可用的信息。此外,本地解決方案然後可能集成到更大業務范圍的數據倉庫架構中,包括所生成的數據模型。
除了測試之外,要與用戶一起檢查在設計階段產生的模型添加和修改,以確保它們是可以理解的。與模型的驗證步驟一樣,要將起作用的東西傳遞到實現階段。將不起作用的返回給需求階段,以便澄清和重新進入建模。
數據倉庫的性能調優
數據倉庫是系統、網絡配置、應用程序、數據庫、報表和人員的集合。數據倉庫的性能受所有這些因素的影響。這一節將關注如何從終端用戶的角度尋找數據倉庫的性能問題,該意味著從查詢工作負載和響應時間的角度查看問題。
數據倉庫上的工作負載很少保持不變。新的用戶帶來了他們自己的需求類型,現有的用戶修改他們的焦點,並且常常改變其研究深度,業務周期呈現其自己的峰值和谷值類型,在大多數情況下,數據倉庫隨著它存儲數據跨越更長時期而進行擴展。
索引的使用在只讀的數據倉庫中將更加自由,因為索引是為了高效的數據檢索而定義的。索引應根據數據倉庫決策支持環境中的訪問模式和查詢需求來進行優化。
隨著數據倉庫上的需求發生改變,一些索引成為無用的,而需要創建其他索引,一些聚集不再被引用,而其他的則需要進行評估,必須對並行處理上的限制進行評估和調整,以滿足當前需求。這些任務和其他調優任務都將定期執行,以確保查詢性能滿足業務需求。
查詢性能的評估和調優最接近於包含了一系列連續改進的進行過程。每次改進都是從對於分組查詢的較差響應時間的抱怨或觀察開始的。
在執行查詢調優任務之前,您需要知道有問題的查詢的期望響應時間。為了刻畫工作負載,您必須整理查詢,將其組成家族,然後確定它們在處理時間、I/O 請求、內存需求、網絡數據信息量(如果可適用)等方面的資源需求。期望的查詢響應時間是基於對查詢工作負載特性的評估而估算的。
一旦知道了期望的響應時間,並且測量了查詢的當前響應時間,就可以按照下列方法定期調優數據倉庫:
分析監控的響應時間,以確定它們是否滿足期望的響應時間。
當查詢無法滿足響應時間目標時,考慮進行調優:
設置系統和數據庫的性能監控,收集數據和分析監控的響應時間信息以尋找瓶頸。
記錄產生最大乃至最小影響的性能決定因素的列表,以進行相應的調整。
確定哪些查詢仍然無法滿足響應時間目標。數量應該很少。使用 DB2 Query Performance Monitor 為這些查詢開發詳細的概要文件和動作計劃。該動作計劃很可能將包含性能權衡(trade-off),這些權衡可能導致其他的資源瓶頸。
繼續調整系統和數據庫,直到所有查詢都½滿足其性能目標。
數據倉庫的安全性
數據倉庫包含秘密的和敏感的業務數據。在進入稍後的數據倉庫設計階段之前,數據倉庫的安全性常常被忽略。隨著其中涉及了更多數據源或業務主題領域,數據倉庫安全的復雜性也在增加。不同的數據源通常具有不同的安全性需求或用戶,因此為集成的倉庫數據定義數據訪問可能十分困難。幸好 DB2 數據庫系統和 DB2 Data Warehouse Center 提供了極其廣泛的數據訪問安全性服務,這使得維護數據倉庫的安全性變得更容易。
您需要在數據倉庫安全性設計中考慮許多因素:
數據訪問:數據倉庫是為了決策支持的傳遞而創建的;終端用戶只是從中挖掘信息。對於數據倉庫中數據的訪問是只讀性的。
終端用戶:知道誰將使用數據倉庫將指導倉庫的設計。如果授權終端用戶訪問倉庫中的所有數據,則只需要設置一個系統或數據庫組來訪問數據倉庫即可。然而,在實際的業務世界中,不是每位終端用戶都被允許訪問所有的業務數據,不同的終端用戶被授權訪問倉庫中不同的數據子集。
數據分析方法:有幾種從數據集市中生成報表的方法,其中包括標准化的業務報表、即席 OLAP 報表和數據挖掘。對於標准化的報表,在允許終端用戶訪問一組預先定義的報表時,安全性易於實現。對於即席 OLAP 和數據挖掘報表,安全性很可能通過將數據庫級別的數據集市或數據集市子集分配給用戶組來實現。
性能:限制性的安全性計劃是按不同的方式以犧牲性能為代價得到的。找到安全性和性能需求之間的平衡十分重要。
數據倉庫設計:數據安全性本身就是數據倉庫設計中的重要問題。該解決方案中兩層的數據倉庫設計假設終端用戶將僅僅訪問數據集市中更加用戶友好的數據,而非數據倉庫中復雜的數據結構。這極大地簡化了數據倉庫終端用戶的安全性,因為數據集市通常是為特定的部門或與用戶組定義的。
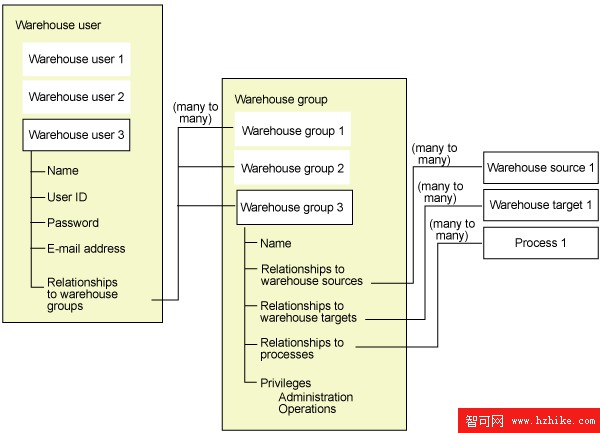
數據倉庫工具:DB2 Data Warehouse Center 安全性結構是與數據庫和操作系統的安全性相分離的。該結構包含倉庫組和倉庫用戶。通過屬於某一倉庫組,用戶可以獲得對 Data Warehouse Center 對象的權限和訪問。倉庫組是倉庫用戶和權限的命名分組,它授權用戶執行功能。倉庫用戶和倉庫組不需要與為倉庫控制數據庫所定義的數據庫用戶和數據庫組相匹配。
下圖展示了 DB2 倉庫用戶、倉庫組以及倉庫數據庫的用戶 ID 和密碼之間的關系。
圖 13. DB2 Data Warehouse 用戶管理結構
數據倉庫解決方案的可交付性
下面是重要的數據倉庫可交付性列表:
業務需求
數據質量假設
架構文檔
邏輯和物理數據模型
業務數據集成規范
ETL 設計文檔
測試計劃和結果
部署計劃和結果
客戶教育文檔
技術支持文檔
結束語
該文章系列向您介紹了商業智能,並提供了交付靈活的低成本數據倉庫解決方案的基本方法。該方法使用 IBM DB2 Data Warehouse Edition Version 8.2.1,它以用戶可承擔的價格提供了端對端的商業智能軟件,特別是對於中型市場的客戶。
商業智能特定領域中所提供的信息讓您洞悉在為客戶開發數據倉庫解決方案時將碰到的任務、決策和問題。從與客戶的第一次見面到將商業智能解決方案部署到生產中,本文包含了許多有用的想法和提示,其中包括 ETL 過程、數據倉庫的設計與實現,以及數據倉庫的安全性和性能。
IBM 是世界一流的商業智能解決方案提供商,而商業智能也是 IBM 的關鍵計劃。商業智能解決方案的范圍很廣,可以從部門級的數據集市,即用於諸如銷售或金融分析的特定功能,到增加到億萬字節(terabyte)的大規模企業數據倉庫。本文剖析了咨詢師或解決方案提供者為交付 IBM 商業智能策略中的部分解決方案要付出什麼代價。