背景知識
在 2007 年,IBM Master Data Management 小組正在計劃 WebSphere® Customer Center 產品的一個重要的新發行版,新發行版將更名為 IBM InfoSphere Master Data Management Server。這個小組在架構方面必須做出的一個關鍵決策是,如何對待現有的持久性機制,該機制基於 Enterprise JavaBeans(EJB)2 容器管理持久性(container-managed persistence,CMP)實體 bean 和本地 JDBC 調用,並且正逐漸過時。這個包含兩部分的系列描述如何以及為何作出使用 pureQuery 技術的決定;我們實現和遷移至 pureQuery 的計劃;最後,介紹為了驗證這一決定而進行的性能和功能測試的結果。
InfoSphere Master Data Management Server 概述
IBM InfoSphere Master Data Management(MDM)Server 管理在組織內驅動最重要的業務流程的主數據實體(即客戶、帳戶和產品)。IBM 提供了一個全面的 MDM 解決方案,該解決方案擁有可為所有主數據管理方法服務的高度即開即用的功能。使用 MDM Server,組織可以將最關鍵的數據集中到單個受信任的源 —— 使他們可以識別最有價值的客戶,增加收益並降低成本。這種功能使他們可以從已有的系統中獲取更大的價值,提高客戶滿意度,並快速發現新的市場。
主數據通常有很多用途(運營系統、數據倉庫、業務流程、數據治理等),不同用途有不同的需求。但是,對於 MDM 系統,這些用途卻有一些共同的關鍵需求。這種系統有如下需求:
提供一個統一的多域(參與方、帳戶、產品)主數據庫 —— 知識層。
提供 SOA 業務服務,用於操縱和查詢這種數據
管理數據的質量和正確性
提供智能的、前攝性的業務邏輯,使 MDM 積極參與到數據生命周期中
提供數據治理功能,實現並審計事務和數據訪問安全
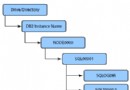
下面的 MDM 產品概覽說明了這些需求是如何被滿足的:
圖 1. MDM 產品概覽
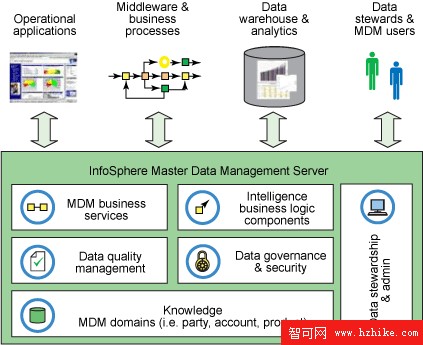
實際上,IBM InfoSphere MDM Server 是一個 SOA 應用程序,具有一套豐富的預定義業務服務,用於維護它的數據庫中的主數據(或主數據引用)。例如,MDM 服務器接受一個 XML 格式的對更新的請求,並將它解析成對象形式;接下來檢查它的安全性;驗證、標准化和復制它的內容;然後通過一個持久層應用更改。持久層是本文的關注點。
IBM InfoSphere Master Data Management Server 是 IBM WebSphere Customer Center 的後繼者。它對 WebSphere Customer Center 的功能進行了增強,具有附加的主數據域 Account 和 Product。因此,當本文提到 WebSphere Customer Center 時,是指之前的架構,而當提到 MDM Server 時,是指新的架構。
Data Studio Developer 和 pureQuery 概述
IBM Data Studio 產品組合提供了一個集成的、模塊化的數據管理環境,該環境可以跨整個數據管理生命周期設計、開發、部署和管理數據、數據庫和數據驅動的應用程序。本文的焦點是 Data Studio Developer 和 Data Studio pureQuery Runtime 中提供的 pureQuery 技術。pureQuery 是一項高性能的 Java™ 數據訪問技術,構建在 JDBC 之上,它使開發和部署數據庫應用程序和服務變得更容易。pureQuery 在 Java 和數據庫之間搭起一座橋梁,而要連結這兩個領域,需要解決大量性能和生產率問題。
編寫直接的 JDBC 可能非常冗長乏味。此外,成為一名 JDBC 和 SQL 專家的確有助於確保 JDBC 數據訪問的高效性。為獲得最佳性能,開發人員必須掌握 JDBC API,並利用諸如批處理和結果優化之類的特性。實際上,必須使用大量代碼才能編寫一個使用 JDBC 的簡單查詢。
冗長乏味的 JDBC 開發導致對象關系映射(ORM)框架的誕生,該框架提供一個數據訪問抽象層。ORM 通常需要更少的初始工作就能創建數據訪問層。然而,在診斷運行時性能問題時,這些框架會增加開銷和額外的復雜性。調優和診斷變得更加困難,因為開發人員再也不能控制發送到數據庫的 SQL;因此,很難更改 SQL 或者確定是哪個應用程序發出它。IBM 創建了 pureQuery,可以為 Java 數據訪問開發解決這些問題和其他問題。pureQuery 引入了一個新的 API,它是用於 Java 開發人員的一個簡單而直觀的 API,通過它可以預覽針對 JDBC 標准化而考慮實現的功能。而且,pureQuery 使您可以在 Java 集合和數據庫緩存中利用 SQL 的威力。
pureQuery 工具簡化了大多數常見的任務,包括存儲和檢索 bean 以及與數據庫之間的來回映射等即開即用支持。SQL 是完全可定制的,所以沒什麼值得驚奇的。而它又是可擴展的,這意味著可以插入定制結果(custom-result)處理模式。擴展的 Java 編輯器包括一個集成的 SQL 編輯器,它為開發人員提供了與 Java 相同級別的用於 SQL 的代碼完成、驗證和執行輔助。它為使用 Java 和 SQL 最佳實踐提供了便利。
DB2 中 pureQuery 編程的一個關鍵標志是使用單個 API 進行編程以及使用 SQL 的靜態或動態執行進行部署的能力。在 DB2 數據庫中使用靜態 SQL 早已被公認為可以提高性能、穩定性和安全性,但是在過去需要專門化的編程才能利用它。雖然我們還沒有用過這個功能,但是我們清楚它的優點,在將來的增強中我們會加以考慮。
在一個即將到來的發行版中,pureQuery 還將使管理員或開發人員能夠跟蹤 SQL 回到初始的應用程序,從而縮短問題判別時間和幫助進行影響分析。
參考資料 小節包括很多文章,在這些文章中可以學到更多關於 pureQuery 和 Data Studio Developer 的知識。
IBM pureQuery 不是一個成熟的持久層。它沒有提供受管對象支持。如果需要一個成熟的持久層和/或受管對象支持,那麼很可能需要使用像 openJPA 之類的東西。在一個即將到來的發行版中,pureQuery 有望向所有 Java 應用程序(而不僅僅是用 pureQuery API 編寫的應用程序)實現它的眾多優點。
WebSphere Customer Center 之前使用的持久性機制
WebSphere Customer Center 中使用了兩種持久性機制。由於使用 EJB2 查詢存在性能問題,我們很早就決定對於查詢操作使用直接 JDBC 調用,而對於創建、檢索、更新和刪除(CRUD)操作則使用 EJB2 CMP。
EJB2 CMP 實體 bean 中的 ORM 層向對象操作隱藏了 JDBC 操作的細節。這個層還幫助生成用於檢索、更改和持久表記錄的適當的 SQL 語句。對於我們來說,這個 ORM 層是簡單的、輕量級的,因為我們不需要它的所有特性:
它只映射 CMP 實體 bean 與一個表之間的一對一的關系。
它不將表關系映射到 CMP 實體 bean 關系。
它不將表繼承映射到 CMP 實體 bean 繼承。
在將一條記錄插入到一個表中和對它進行更新之前,我們使用 EJB2 CMP 實體 bean 生命周期事件。
在插入記錄之前,使用 ejbCreate 方法設置主鍵。
在更新記錄之前,我們通過實體對象方法 set 使用了樂觀並發控制。
在插入或更新記錄之前,設置常見實體字段的邏輯出現在 ejbCreate 和 set 實體對象方法中。
如前所述,對於復雜的查詢操作,我們使用了直接 JDBC 調用,從而避免 EJB2 查詢中的性能開銷。不幸的是,我們因此不能重用在 EJB2 CMP ORM 中使用的代碼,所以我們需要手動地編寫用於 JDBC 查詢的對象關系映射。
WebSphere Customer Center 中 CMP 實體 bean 的架構視圖
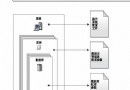
圖 2 顯示了 WebSphere Customer Center 中用於 CRUD 操作的使用 CMP 實體 bean 的持久性機制的架構視圖。
圖 2. Add/Update/Delete 服務中的 CMP 實體 bean
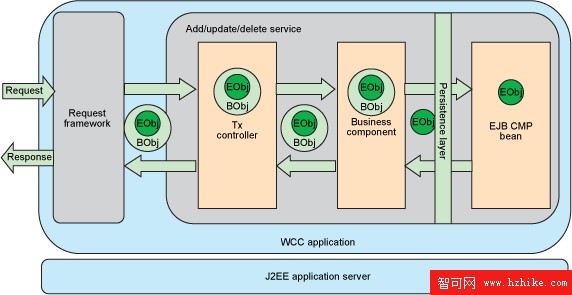
WebSphere Customer Center 是一個 J2EE 應用程序,在一個應用服務器中運行。它有以下 4 個層(圖中從左到右排列):
請求框架(Request framework)操縱和轉換請求和響應消息。
Tx 控制器(Tx controller)處理事務級邏輯,可能調用一個或多個用於組件級邏輯的業務組件。
業務組件(Business component)處理組件級邏輯,並且可用於創建不同的事務。
持久層(CMP 實體 bean)由業務組件為執行 CRUD 操作而調用。
首先在業務組件層從業務對象(BObj)中獲取實體對象(EObj),然後將它發送到持久層(CMP 實體 bean),執行 CRUD 操作。從持久層返回後,再次使用業務對象包裝實體對象(EObj)。實體對象與表之間有一對一的映射,是用於在持久層和業務組件層之間傳遞數據的傳送對象。
WebSphere Customer Center 中的直接 JDBC 調用的架構視圖
圖 3 是用於查詢操作的持久性機制的架構視圖,該機制使用 WebSphere Customer Center 中的 JDBC 調用。代碼層與 圖 2 顯示的一樣,只是持久層受到我們自己的框架代碼的支持,可以執行直接 JDBC 調用。
圖 3. 查詢服務中的直接 JDBC 調用
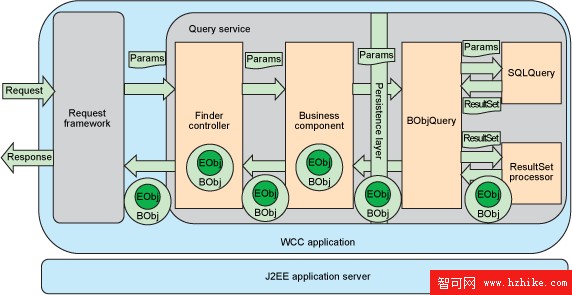
請求框架 操縱和轉換請求和響應消息。
finder 控制器(finder controller)處理事務級邏輯,可能調用一個或多個用於組件級邏輯的業務組件。
業務組件 處理組件級邏輯,並且可用於創建不同的事務。
持久層(Direct JDBC) 由業務組件為執行 CRUD 操作而調用。
查詢參數通過不同的代碼層傳遞到 BObjQuery。 對於不同的業務組件,BObjQuery 類有不同的實現。 BObjQuery 調用一個公共的 SQLQuery 類來獲得一個 SQL ResultSet。該 ResultSet 被傳遞到 ResultSetProcessor,用來創建業務對象。每個業務組件都有一個特定的 ResultSetProcessor 實現。
WebSphere Customer Center 持久性機制的問題
我們的產品使用前面描述的持久性機制已有數年,它們工作得很好。我們可以擴展 WebSphere Customer Center 應用程序,從而滿足大規模的用戶、事務和數據量,並為我們的客戶機提供很多擴展機制。然而,隨著時間的推移,我們也遇到一些缺點,希望您對此有所了解。
EJB2 CMP 實體 bean 的問題
下面是我們發現的 CMP 實體 bean 的問題:
CMP 只能解決我們的部分 ORM 需要。實體 bean 不僅僅是傳統 Java 對象(POJO),不能到處傳遞,所以我們創建了自己的實體對象。這迫使我們手動地在 CMP 實體 bean 與我們自己的實體對象之間來回移動屬性值。
如前所述,CMP 中用過的 ORM 不能在 JDBC 查詢中重用。CMP 中的 ORM 生成 CMP 實體 bean 與表之間的映射代碼。由於不能將 CMP 實體 bean 當作 POJO 來對待,因此在 JDBC 查詢中這種映射沒有用處。
即使借助 IDE,CMP 開發仍然相當復雜。僅僅對於一個 CMP 實體 bean,就需要創建 6 個類:Local Home、Remote Home、Remote Interface、Local Interface、Key Class 和 Bean Class。此外,還需要有 EJB 實體 bean 部署描述符和一個映射文件及數據庫模式。即使是簡單地調用 CMP 實體 bean 也涉及到很多步驟。例如,對於一個更新操作,需要獲得 JNDI 上下文,查找 EJB home,發現 EJB 實體 bean 並更新這個 bean。
CMP 實體 bean 依賴於 J2EE 服務器。不同的服務器需要一套不同的部署代碼和部署描述符。這些都需要在代碼維護和產品分發中投入額外的工作。
直接 JDBC 調用的問題
當編寫 JDBC 查詢時,ORM 依賴於手動編程。這樣做很麻煩,容易出錯,而且會降低開發的生產率。
將 JDBC 與 EJB2 CMP 相結合的問題
如果同時使用 JDBC 和 EJB2 CMP 訪問數據庫,那麼當在一個事務中同時執行更新和查詢時會發生數據同步問題。在一個事務中,通過 EJB2 CMP 實體 bean 的更新直到事務結束才會被發送到數據庫中,這意味著更新的數據對於同一個事務中隨後的 JDBC 查詢是不可見的。
性能問題
下面是我們在現有的持久性機制中遇到的性能問題列表:
CMP EJB 查詢在查詢場景中不能執行,這正是我們為查詢使用直接 JDBC 調用的原因。
CMP 實體 bean 更新效率不高,因為它需要在數據庫中進行讀取和更新。這是因為 CMP 實體 bean 是由容器管理的。
對實體 bean 使用容器管理會生成很多代碼。這對於將關系層與對象層分離是必需的,但這種便利是以犧牲性能為代價獲得的。在我們的編程模型中,將為復雜的本地 SQL 處理關系層,而不必對程序員隱藏 SQL。這使得實體管理對於我們基本上沒有用處。
技術路線圖問題
現在是時候對我們使用的技術路線圖作一個評估了。我們發現一些缺陷,這使我們不得不重新思考我們的持久性機制。
我們正在計劃使用 XML 數據類型,它不是一種標准的 JDBC SQL 類型。 我們的產品可以在 DB2 和 Oracle 上運行,它們以不同的方式解釋 XML 數據類型。這意味著對於每種數據庫,我們將修改基本的 CRUD SQL 語句。然而,CMP 實體 bean 生成的基本 CRUD SQL 語句是不能修改的,這使得我們不可能采用 XML 數據類型。
EJB2/CMP 在 JEE5 中已被棄用,並且被 EJB3/Java Persistence API(JPA)替代。EJB3/JPA 被設計用來簡化開發,並為復雜的查詢場景提供更大的靈活性。EJB3/JPA 仍然基於實體管理的概念。
對新的持久性機制的期待
基於我們遇到的問題和未來計劃,我們將需要一種新的持久性機制。下面列出了我們對於持久性機制的要求:
只需簡單的對象到關系的映射功能,特別是:
Java bean 屬性名到表列名的映射,而不是實體關系或繼承的映射
超類映射支持;超類中定義的屬性到列的映射應該可用於它的子類。但是,超類本身不映射到表。這是為了避免用於很多常見的屬性和列的映射。
用於基本實體 CRUD 操作的 SQL 生成
用於在插入、更新和刪除前後處理一些邏輯的實體生命周期事件回調
所有生成的代碼應該可以移植到不同的應用服務器上。
實現持久性機制的開發過程可以很容易地降低與升級相關的開發成本。這包括對於可以處理 “自下而上” 和 “中間會合” 方法的開發工具的支持。
“自下而上” 方法假設已經有數據庫表模式,而需要根據表模式開發一個對象層和對象關系映射。
“中間會合” 方法則假設已經有數據庫表模式和一個對象層,而需要開發兩者之間的一個 ORM。
可擴展性和靈活性,包括使用 SQL 所有功能和更改生成的 SQL CRUD 語句的能力。
與現有的持久性機制相比,我們選擇的持久性機制必須執行良好。
可以順利地遷移已有代碼。
客戶機可以用更多的實體和屬性擴展我們的產品,並且該機制與客戶機已有代碼是向後兼容的。
該技術必須匹配下一版本產品的交付進度,並且采用它的風險必須降到最小。
該技術需要具有強大的技術路線圖,並且與我們的方向保持一致,可以為我們提供優勢。此外,該技術必須至少 5 年內可用。
受管持久性與 pureQuery 的比較
清楚了新持久性機制的所有期望之後,我們調查了 3 種持久性機制,並對它們作了比較:1)現有的持久性機制 —— EJB2 CMP,2)EJB3/JPA,3)pureQuery。EJB2/CMP 和 EJB3/JPA 是受管的持久性解決方案,而 pureQuery 不是。表 1 根據我們的需求對這些技術作了評價。
表 1. 持久性機制比較
EJB 2/CMP(沒有改變) EJB3/JPA pureQuery 簡單的 O/R 映射 半支持 完全支持 POJO 風格 完全支持 POJO 風格 易於開發/在不同的應用服務器上運行 復雜
在不同的應用服務器上,對於不同的 CMP 實現有不同的生成代碼
簡單在不同的應用服務器上,對於不同的 JPA 實現有不同的生成代碼
簡單Java 編輯器中集成的 SQL 輔助功能。對於不同的應用服務器使用單一的代碼生成
靈活性和可擴展性 生成的 CRUD SQL 不能更改 生成的 INSERT SQL 不能更改 生成的 CRUD SQL 可以更改 性能 基准使用 CMP 的查詢不能很好地執行
對於實體更新場景需要執行讀和更新操作
需要額外的成本管理實體
較好可以使用 JPA 查詢 API 執行查詢
對於實體更新場景需要執行讀和更新操作
需要額外的成本管理實體
最好查詢 API 或方法風格的查詢執行得較好
對於實體更新場景只需執行更新
沒有實體管理,可以減少成本
遷移和向後兼容性 沒有遷移,這是我們的起點 需要遷移。應該基於 JEE 規范向後兼容 需要遷移。應該基於設計向後兼容 技術可用性 可用 可用 可用(但我們使用的是預發布代碼) 技術路線 不推薦使用 由 JCP 掌控路線圖和方向新特性的采用速度可能較慢
具有與 IBM 持久性戰略一致的清晰的路線圖可快速添加或采用新特性
風險 如果應用服務器停止支持,則在未來會產生很高的成本。實體管理會導致潛在的性能問題 實體管理會導致潛在的性能問題 風險最小做出決定並開發一個執行計劃
顯然,對於我們的編程模型,受管持久性解決方案不是必需的,我們希望釋放出 SQL 的威力,而不是對開發人員隱藏它。對於我們來說,實體管理增加了一層不必要的開銷,並且對性能有負面的影響。
鑒於 Data Studio Developer 工具提供的對 SQL 開發的幫助,以及對以數據為中心的開發的關注,pureQuery 成為我們最自然的選擇。為了支持我們的持久性機制決策,我們制定了一個計劃,以便在以下方面證明該技術:
確定 pureQuery 開發和交付環境
調查編程模型
調查用於產品交付的軟件平台
調查用於產品開發的軟件平台
調查用於對象到關系映射的開發工具
調查樂觀控制實現
估計將 CMP 和直接 JDBC 調用遷移至 pureQuery 的工作量
調查如何遷移已有的 WebSphere Customer Center EJB CMP bean
調查如何遷移已有的直接 JDBC 調用
執行功能測試,消除對向後兼容性的擔心
調查 pureQuery 與 EJB2/CMP 和直接 JDBC 調用的共存性
調查 Global Transaction(XA)的支持
執行基准測試,消除對性能的擔憂,並確保新機制的性能好於現有的機制
致謝
我們要感謝 pureQuery 開發小組,他們對我們的初始調查和本文的審校工作提供了幫助。
結束語
本文對 InfoSphere Master Data Management Server 和 Data Studio Developer/pureQuery 作了概述,然後深入研究了 WebSphere Customer Center 在之前使用的持久性機制。本文還列出了與持久性機制有關的一些問題,以便實現改進。根據我們對持久性機制的期望,我們對 EJB2/CMP、EJB3/JPA 和 pureQuery 作了一個比較。最後,pureQuery 脫穎而出成了我們的選擇,我們還開發了一個執行計劃,以便進一步驗證我們的決定。
在本文的第 2 部分,我們將詳細討論技術驗證的結果,包括將實體 bean 遷移至 pureQuery 時開發人員的生產率、查詢和 CRUD 操作的性能結果以及事務一致性。我們還將提供一些經驗教訓,如果您決定著手一個類似的項目,這些經驗教訓可能會提供幫助。