簡介
隨著 DB2 應用的逐漸增多,越來越多的數據庫開發人員在項目開發過程中都會遇到查詢過於復雜,導致性能難以接受的問題。本文將主要從一個數據庫開發者的角度介紹幾種常用的方法來提高 DB2 查詢的性能,而並不討論如何通過配置 DB2 的各項參數以及調整服務器環境等方式來提高整個數據庫性能的方法。系統配置等工作屬於 DBA 的工作范疇,在一般的項目開發中,這對於開發人員都是透明的。本文先對 DB2 提供的幾種用於提高查詢性能的相關工具和命令進行介紹,然後根據筆者的工作經驗介紹一些常用的技巧和方法來提高查詢性能。主要集中於如何創建和維護索引、改寫查詢以及改變查詢的實現方式,相關內容都將通過實例加以說明。
DB2 提供的幾種相關工具和命令
我們將著重介紹如何使用 Visual Explain 和 db2expln 查看動態查詢的存取計劃。讀者可以查閱 DB2 Info Center 獲得有關查看靜態查詢存取計劃的內容。
DB2 Visual Explain
DB2 提供了非常直觀有效的方法來查看查詢的存取計劃。DB2 Visual Explain 能夠獲得可視化的查詢計劃,而 db2expln 命令則可以獲得文本形式的查詢計劃。有了查詢計劃,我們就可以有針對的對查詢進行優化。根據查詢計劃找出代價最高的掃描 ( 表掃描,索引掃描等 ) 和操作 (Join,Filter,Fetch 等 ),繼而通過改寫查詢或者創建索引消除代價較高的掃描或操作來優化查詢。
DB2 提供了多種方法來得到可視化查詢計劃。
通過 DB2 Control Center 獲得可視化查詢計劃。如圖 1:
圖 1. 可視化查詢計劃
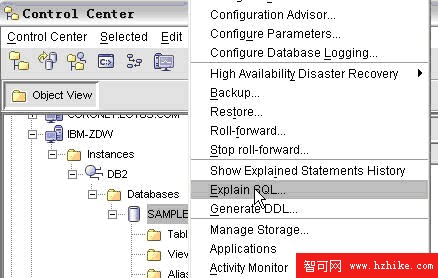
點擊”Explain SQL”後輸入要進行分析的查詢語句以及查詢標號和標簽,點擊 Ok 按鈕便可得到可視化的查詢計劃。此時,查詢計劃會被存儲在系統的 Explain 表中。用戶可以通過圖 1 中的”Show Explained Statements History”命令獲得存儲在 Explain 表中的所有查詢計劃。
通過 Command Editor( 在 DB2 8.2 版本之前叫做 Command Center) 獲得可視化的查詢計劃。如圖 2:
圖 2. 獲得可視化的查詢計劃
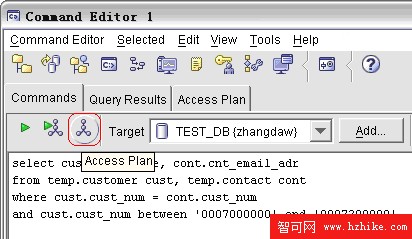
在主窗口輸入查詢並連接數據庫後,點擊圖中所示的按鈕即可得到可視化的查詢計劃,如圖 3:
圖 3. 查詢計劃結果
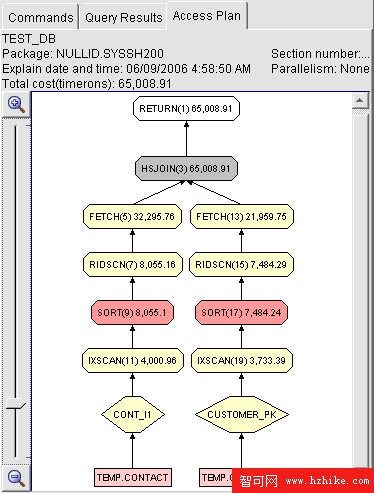
在圖 3 所示的查詢計劃中,還可以點擊圖示中的每個節點來察看詳細的統計信息。譬如雙擊節點”FETCH(13) 21,959.75” 後將會彈出如圖 4 所示的對話框:
圖 4. 詳細的統計信息
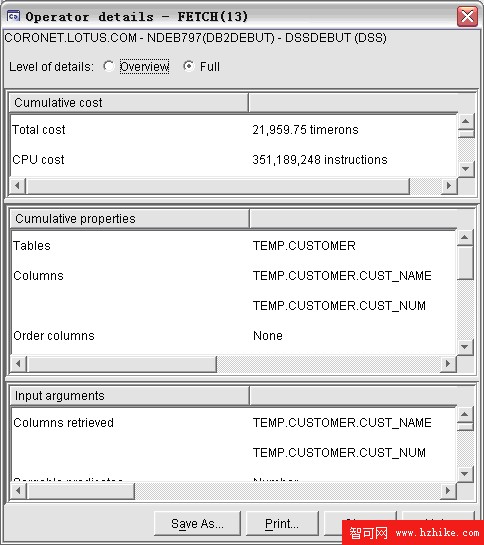
圖 4 中的統計信息主要包括此 FETCH 操作的總代價,CPU,I/O 以及獲得結果集中的第一行的代價。在這裡,timerons 是結合了 CPU 和 I/O 代價的成本單位。此外,圖 4 中還收集了其他相關信息。譬如此操作讀取了哪個表的哪些列,每個謂詞的選擇度 (selectivity),使用了多少 buffer 等等。
db2exfmt
db2exfmt 命令能夠將 Explain 表中存儲的存取計劃信息以文本的形式進行格式化輸出。db2exfmt 命令將各項信息更為直觀的顯示,使用起來更加方便。命令如清單 1 所示:
清單 1. db2exfmt 命令
db2exfmt -d <db_name> -e <schema> -g T -o <output> -u <user> <passWord> -w <timestamp>
Example: db2exfmt -d test_db -e user -g T -o D:tempsql_1_result_db2exfmt.txt
-u user passWord -w l
Query:
sql_1.txt(附件中)
Results:
sql_1_result_db2exfmt.txt(附件中)
db2expln
db2expln 是命令行下的解釋工具,和前面介紹的 Visual Explain 功能相似。通過該命令可以獲得文本形式的查詢計劃。命令如清單 2 所示 :
清單 2. db2expln 命令
db2expln -d <db_name> -user <user> <passWord> -stmtfile <sql.file>
-z @ -output <output> -g
Example: db2expln -d test_db -user user passWord -stmtfile D:tempsql_1.txt
-z @ -output D:tempsql_1_result_db2expln.txt –g
Query:
sql_1.txt(附件中)
Results:
sql_1_result_db2expln.txt(附件中)
db2expln 將存取計劃以文本形式輸出,它只提供存取計劃中主要的信息,並不包含每一個操作占用多少 CPU、I/O、占用 Buffer 的大小以及使用的數據庫對象等信息,方便閱讀。但是 db2expln 也會將各項有關存取計劃的信息存入 Explain 表中,用戶可以使用 db2exfmt 察看詳細的格式化文本信息。
db2advis
db2advis 是 DB2 提供的另外一種非常有用的命令。通過該命令 DB2 可以根據優化器的配置以及機器性能給出提高查詢性能的建議。這種建議主要集中於如何創建索引,這些索引可以降低多少查詢代價,需要創建哪些表或者 Materialized Query Table(MQT) 等。命令如清單 3 所示:
清單 3. db2advis 命令
db2advis -d <db_name> -a <user>/<passWord> -i <sql.file> -o <output>
Example: db2advis -d test_db -a user/passWord
-i D:tempsql_2.txt > D:tempsql_2_result_db2advis.txt
Query:
sql_2.txt(附件中)
Results:
sql_2_result_db2advis.txt(附件中)
通過 -i 指定的 SQL 文件可以包含多個查詢,但是查詢必須以分號分隔。這與 db2expln 命令不同,db2expln 可以通過 -z 參數指定多個查詢之間的分隔符。用戶可以把某一個 workload 中所使用的所有查詢寫入 SQL 文件中,並在每個查詢之前使用”--#SET FREQUENCY <num>”為其指定在這個 workload 中的執行頻率。db2advis 會根據每個查詢在這個 workload 的頻率指數進行權衡來給出索引的創建建議,從而達到整個 workload 的性能最優。
db2batch
前面介紹的工具和命令只提供了查詢的估算代價,但有些時候估算代價和實際的執行時間並不是完全呈線形關系,有必要實際執行這些查詢。db2batch 就是這樣一個 Benchmark 工具,它能夠提供從准備到查詢完成中各個階段所花費地具體時間,CPU 時間,以及返回的記錄。命令如清單 4 所示:
清單 4. db2batch 命令
db2batch -d <db_name> -a <user>/<passWord>
-i <time_condition> -f <sql.file> -r <output>
Example: db2batch -d test_db -a user/passWord
-i complete -f D:tempsql_3.txt -r d:tempsql_3_result_db2batch.txt
Query:
sql_3.txt(附件中)
Results:
sql_3_result_db2batch.txt(附件中)
對於執行 db2batch 時一些詳細的設置可以通過 -o 參數指定,也可以在 SQL 文件中指定,譬如本例中在 SQL 文件中使用了下面的配置參數 :
--#SET ROWS_FETCH -1 ROWS_OUT 5 PERF_DETAIL 1 DELIMITER @ TIMESTAMP
其中 ROWS_FETCH 和 ROWS_OUT 定義了從查詢的結果集中讀取記錄數和打印到輸出文件中的記錄數,PERF_DETAIL 設置了收集性能信息的級別,DELIMITER 則指定了多個查詢間的間隔符。
提高查詢性能的常用方法
下面我們將從三個方面介紹一些提高查詢性能的方法。
創建索引
根據查詢所使用的列建立多列索引
建立索引是用來提高查詢性能最常用的方法。對於一個特定的查詢,可以為某一個表所有出現在查詢中的列建立一個聯合索引,包括出現在 select 子句和條件語句中的列。但簡單的建立一個覆蓋所有列的索引並不一定能有效提高查詢,因為在多列索引中列的順序是非常重要的。這個特性是由於索引的 B+ 樹結構決定的。一般情況下,要根據謂詞的選擇度來排列索引中各列的位置,選擇度大的謂詞所使用的列放在索引的前面,把那些只存在與 select 子句中的列放在索引的最後。譬如清單 5 中的查詢:
清單 5. 索引中的謂詞位置
select add_date
from temp.customer
where city = 'WASHINGTON'
and cntry_code = 'USA';
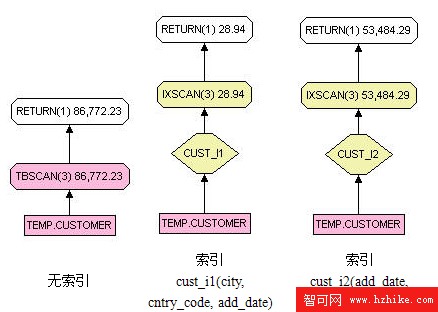
對於這樣的查詢可以在 temp.customer 上建立 (city,cntry_code,add_date) 索引。由於該索引包含了 temp.customer 所有用到的列,此查詢將不會訪問 temp.customer 的數據頁面,而直接使用了索引頁面。對於包含多列的聯合索引,索引樹中的根節點和中間節點存儲了多列的值的聯合。這就決定了存在兩種索引掃描。回到清單 5 中的查詢,由於此查詢在新建索引的第一列上存在謂詞條件,DB2 能夠根據這個謂詞條件從索引樹的根節點開始遍歷,經過中間節點最後定位到某一個葉子節點,然後從此葉子節點開始往後進行在葉子節點上的索引掃描,直到找到所有滿足條件的記錄。這種索引掃描稱之為 Matching Index Scan。但是如果將 add_date 放在索引的第一個位置,而查詢並不存在 add_date 上的謂詞條件,那麼這個索引掃描將會從第一個索引葉子節點開始,它無法從根節點開始並經過中間節點直接定位到某一個葉子節點,這種掃描的范圍擴大到了整個索引,我們稱之為 Non-matching Index Scan。圖 5 顯示了 DB2 根據不同索引生成的存取計劃。
圖 5. 根據不同索引生成的存取計劃
根據條件語句中的謂詞的選擇度創建索引
因為建立索引需要占用數據庫的存儲空間,所以需要在空間和時間性能之間進行權衡。很多時候,只考慮那些在條件子句中有條件判斷的列上建立索引會也會同樣有效,同時節約了空間。譬如清單 5 中的查詢,可以只建立 (city,cntry_code) 索引。我們還可以進一步地檢查條件語句中的這兩個謂詞的選擇度,執行清單 6 中的語句檢查謂詞選擇度:
清單 6. 檢查謂詞選擇度
QuerIEs:
1. select count(*) from temp.customer
where city = 'WASHINGTON'
and cntry_code = 'USA';
2. select count(*) from temp.customer
where city = 'WASHINGTON';
3. select count(*) from temp.customer
where cntry_code = 'USA';
Results:
1. 1404
2. 1407
3. 128700
選擇度越大,過濾掉的記錄越多,返回的結果集也就越小。從清單 6 的結果可以看到,第二個查詢的選擇度幾乎有和整個條件語句相同。因此可以直接建立單列索引 (city),其性能與索引 (city,cntry_code,add_date) 具有相差不多的性能。表 1 中對兩個索引的性能和大小進行了對比。
表 1. 兩個索引的性能和大小對比
索引 查詢計劃總代價 索引大小 cust_i1(city,cntry_code,add_date) 28.94 timerons 19.52M cust_i3(city) 63.29 timerons 5.48M
從表 1 中可以看到單列索引 (city) 具有更加有效的性能空間比,也就是說占有盡可能小的空間得到盡可能高的查詢速度。
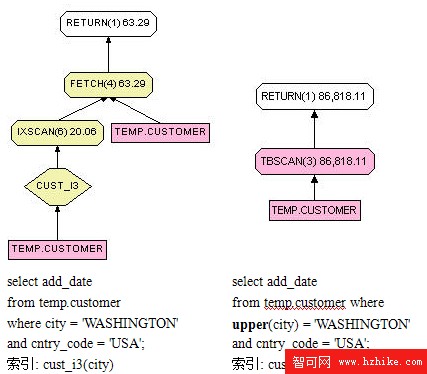
避免在建有索引的列上使用函數
這是一個很簡單的原則,如果在建有索引的列上使用函數,由於函數的單調性不確定,函數的返回值和輸入值可能不會一一對應,就可能存在索引中位置差異很大的多個列值可以滿足帶有函數的謂詞條件,因此 DB2 優化器將無法進行 Matching Index Scan,更壞的情況下可能會導致直接進行表掃描。圖 6 中對比了使用 function 前後的存取計劃的變化。
圖 6. 使用 function 前後的存取計劃的變化
在那些需要被排序的列上創建索引
這裡的排序不僅僅指 order by 子句,還包括 distinct 和 group by 子句,他們都會產生排序的操作。由於索引本身是有序的,在其創建過程中已經進行了排序處理,因此在應用這些語句的列上創建索引會降低排序操作的代價。這種情況一般針對於沒有條件語句的查詢。如果存在條件語句,DB2 優化器會首先選擇出滿足條件的紀錄,然後才對中間結果集進行排序。對於沒有條件語句的查詢,排序操作在總的查詢代價中會占有較大比重,因此能夠較大限度的利用索引的排序結構進行查詢優化。此時可以創建單列索引,如果需要創建聯合索引則需要把被排序的列放在聯合索引的第一列。圖 7 對比了清單 7 中的查詢在創建索引前後的存取計劃。
清單 7. 查詢在創建索引前後的存取計劃
select distinct add_date from temp.customer;
圖 7. 在創建索引前後的存取計劃
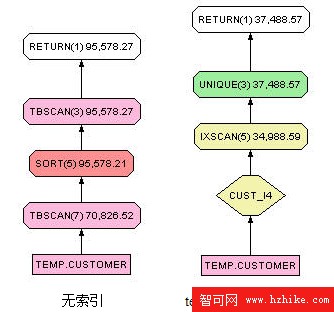
從圖 7 中我們可以看到在沒有索引的情況下 SORT 操作是 24751.69 timerons,但是有索引的情況下,不再需要對結果集進行排序,可以直接進行 UNIQUE 操作,表中顯示了這一操作只花費了 2499.98 timerons.
圖 8 對比了清單 8 中的查詢在創建聯合索引前後的存取計劃,從中可以更好的理解索引對排序操作的優化。
清單 8. 查詢示例
select cust_name from temp.customer order by add_date;
圖 8. 創建聯合索引前後的存取計劃
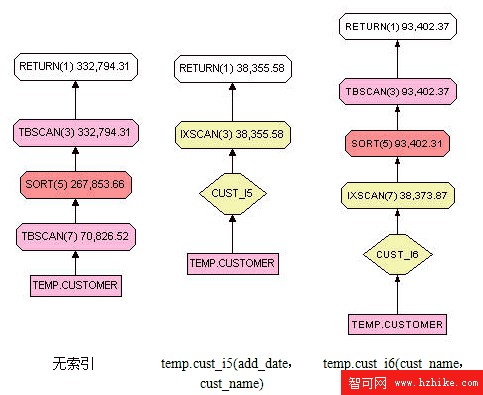
索引的 B+ 樹結構決定了索引 temp.cust_i5 的所有葉子節點本身就是按照 add_date 排序的,所以對於清單 8 中的查詢,只需要順序掃描索引 temp.cust_i5 的所有葉子節點。但是對於 temp.cust_i6 索引,其所有葉子節點是按照 cust_name 排序,因此在經過對索引的葉子節點掃描獲得所有數據之後,還需要對 add_date 進行排序操作。
合理使用 include 關鍵詞創建索引
對於類似下面的查詢 :
清單 9. 查詢示例
select cust_name from temp.customer
where cust_num between '0007000000' and '0007200000'
在第一點中我們提到可以在 cust_num 和 cust_name 上建立聯合索引來提高查詢性能。但是由於 cust_num 是主鍵,可以使用 include 關鍵字創建唯一性索引:
create unique index temp.cust_i7 on temp.customer(cust_num) include (cust_name)
使用 include 後,cust_name 列的數據將只存在於索引樹的葉子節點,並不存在於索引的關鍵字中。這種情況下,使用帶有 include 列的唯一索引會帶來優於聯合索引的性能,因為唯一索引能夠避免一些不必要的操作,如排序。對於清單 9 中的查詢創建索引 temp.cust_i7 後存取計劃的代價為 12338.7 timerons,創建聯合索引 temp.cust_i8(cust_num,cust_name) 後的代價為 12363.17 timerons。一般情況下,當查詢的 where 子句中存在主鍵的謂詞我們就可以創建帶有 include 列的唯一索引,形成純索引訪問來提高查詢性能。注意 include 只能用在創建唯一性索引中。
指定索引的排序屬性
對於下面用來顯示最近一個員工入職的時間的查詢:
select max(add_date) from temp.employee
很顯然這個查詢會進行全表掃描。查詢計劃如圖 9.a:
圖 9. 查詢計劃
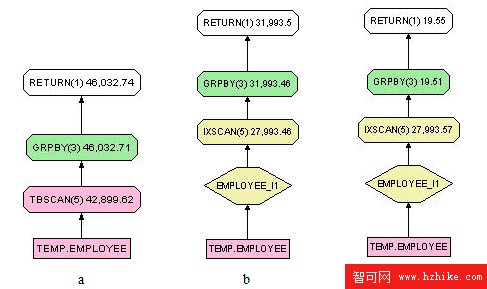
顯然我們可以在 add_date 上創建索引。根據下面的命令創建索引後的查詢計劃如圖 9.b。
create index temp.employee_i1 on temp.employee(add_date)
這裡存在一個誤區,大家可能認為既然查詢裡要取得的是 add_date 的最大值,而我們又在 add_date 上建立了一個索引,優化器應該知道從索引樹中直接去尋找最大值。但是實際情況並非如此,因為創建索引的時候並沒有指定排序屬性,默認為 ASC 升序排列,DB2 將會掃描整個索引樹的葉子節點取得所有值後,然後取其最大。我們可以通過設置索引的排序屬性來提高查詢性能,根據下面的命令創建索引後的查詢計劃如圖 9.c。
create index temp.employee_i1 on temp.employee(add_date desc)
對於降序排列的索引,DB2 不需要掃描整個索引數的葉子節點,因為第一個節點便是最大的。我們同樣可以使用 ALLOW REVERSE SCANS 來指定索引為雙向掃描,具有和 DESC 近似的查詢性能。ALLOW REVERSE SCANS 可以被認為是 ASC 和 DESC 的組合,只是在以後數據更新的時候維護成本會相對高一些。
如果無法改變索引的排序屬性,但是我們具有額外的信息,該公司每個月都會有新員工入職,那麼這個查詢就可以改寫成:
select max(add_date) from temp.employee where add_date > current timestamp - 1 month
這樣通過限定一個查詢范圍也會有效地提高查詢性能。
索引和表的維護
重新組織索引
隨著數據的不斷刪除,插入和更新,索引頁會變得越來越零散,索引頁的物理存儲順序不再匹配其邏輯順序,索引結構的層次會變得過大,這些都會導致索引頁的預讀取變得效率低下。因此,根據數據更新的頻繁程度需要適當的重新組織索引。可以使用 REORG INDEXES 命令來重新組織索引結構,也可以刪除並重新創建索引達到相同的目的。同樣的,對表進行重新組織也會帶來性能的改善。
重新組織某一個表的所有索引的命令如下:REORG INDEXES ALL FOR TABLE table_name。
重新組織一個表的數據的命令如下,在下面的命令還可以為其指定一個特定的索引,REORG 命令將會根據這個索引的排序方式重新組織該表的數據。
REORG TABLE table_name INDEX index_name。
重新收集表和索引的統計信息
和在 2.1 中提到的原因類似,當一個表經過大量的索引修改、數據量變化或者重新組織後,可能需要重新收集表以及相關索引的統計信息。這些統計信息主要是關於表和索引存儲的物理特性,包括記錄數目,數據頁的數目以及記錄的平均長度等。優化器將根據這些信息決定使用什麼樣的存取計劃來訪問數據。因此,不能真實反映實際情況的統計信息可能會導致優化器選擇錯誤的存取計劃。收集表及其所有索引的統計信息的命令如下:RUNSTATS ON TABLE table_name FOR INDEXES ALL。
上述兩個命令具有復雜的參數選擇,用戶可以參閱 DB2 Info Center 來根據實際情況使用這兩個命令。
修改查詢
合理使用 NOT IN 和 NOT EXISTS
一般情況下 NOT EXISTS 具有快於 NOT IN 的性能,但是這並不絕對。根據具體的數據情況、存在的索引以及查詢的結構等因素,兩者會有較大的性能差異,開發人員需要根據實際情況選擇適當的方式。
譬如下面的查詢:
清單 10. 查詢示例
表結構:temp.customer(cust_num) 主鍵:cust_num
表結構:temp.contact(cnt_id,cust_num) 主鍵:cnt_id
表結構:temp.contact_detail(cnt_id,address,phone) 主鍵:cnt_id
查詢 :
select cust_num
from temp.customer cust
where not exists (select 1 from temp.contact cont
here cust.cust_num = cont.cust_num)
此查詢用來列出所有不存在聯系人的客戶。對於這樣的需求,開發人員會最自然的寫出清單 10 中的查詢,的確,對於大部分情況它具有最優的性能。該查詢的查詢代價為 178,430 timerons。讓我們再來看看使用 NOT IN 後查詢的總代價,請看清單 11。
清單 11. 查詢示例
查詢:
select cust_num
from temp.customer cust
where cust.cust_num not in (select cont.cust_num from temp.contact cont)
代價:12,648,897,536 timerons
可以看到 NOT EXISTS 的性能要比 NOT IN 高出許多。NOT IN 是自內向外的操作,即先得到子查詢的結果,然後執行最外層的查詢,而 NOT EXISTS 恰好相反,是自外向內的操作。在上述例子中,temp.contact 表中有 65 萬條記錄,使得 10.2 查詢中的 NOT IN 列表非常大,導致了使用 NOT IN 的查詢具有非常高的查詢代價。下面我們對 10.1 和 10.2 的查詢進行修改,將 temp.contact 表中的記錄限制到 100 條,請看下面的查詢:
清單 12. 查詢示例
查詢:
select cust_num
from temp.customer cust
where not exists (select 1 from temp.contact cont
here cust.cust_num = cont.cust_num
and cont.cnt_id < 100)
代價:42,015 timerons
清單 13. 查詢示例
查詢:
select cust_num
from temp.customer cust
where cust.cust_num not in (select cont.cust_num from temp.contact cont
where cont.cnt_id < 100)
代價:917,804 timerons
從 12 和 13 中可以看出 NOT EXISTS 的查詢代價隨子查詢返回的結果集的變化沒有大幅度的下降,隨著子查詢的結果集從 65 萬下降到 100 條,NOT EXISTS 的查詢代價從 178,430 下降到 42,015,只下降 4 倍。但是 NOT IN 的查詢代價卻有著極大的變化,其查詢代價從 12,648,897,536 下降到 917,804,下降了 13782 倍。可見子查詢的結果集對 NOT IN 的性能影響很大,但是這個簡單的查詢不能說明 NOT EXISTS 永遠好於 NOT IN,因為同樣存在一些因素對 NOT EXISTS 的性能有很大的影響。我們再看下面的例子:
清單 14. 查詢示例
查詢:
select cust_num
from temp.customer cust
where not exists (select 1 from temp.contact cont
where cust.cust_num = cont.cust_num
and cont.cnt_id in (select cnt_id from temp.contact_detail
where cnt_id<100))
代價:5,263,096 timerons
清單 15. 查詢示例
查詢:
select cust_num
from temp.customer cust
where cust_num not in (select cust_num from temp.contact cont
where cont.cnt_id in (select cnt_id from temp.contact_detail
where cnt_id<100))
代價:4,289,095 timerons
在上面的例子中,我們只是對查詢增加了一個小改動,使用一個嵌套查詢限制了在 temp.contact 中掃描的范圍。但是在這兩個新的查詢中,NOT IN 的性能卻又好於 NOT EXISTS。NOT EXISTS 的代價增加了 125 倍,而 NOT IN 的代價卻只增加了 4 倍。這是由於 NOT EXISTS 是自外向內,嵌套查詢的復雜度對其存在較大的影響。因此在實際應用中,要考慮子查詢的結果集以及子查詢的復雜度來決定使用 NOT EXISTS 或者 NOT IN。對於 IN,EXISTS 和 JOIN 等操作,大多數情況下 DB2 優化器都能形成比較一致的最終查詢計劃。
合理使用子查詢減少數據掃描和利用索引
某些情況下可以將查詢中的某一部分邏輯提取出來作為子查詢出現,能夠減少掃描的數據量,以及利用索引進行數據檢索。請看清單 16 中的查詢:
清單 16.
索引:temp.cust_i1 on temp.customer(add_date)
temp.order_i1 on temp.order(sold_to_cust_num)
temp.order_i2 on temp.order(add_date)
查詢:
select cust.cust_num
from temp.customer cust
left join temp.order ord
on cust.cust_num = ord.sold_to_cust_num
where cust.add_date > current timestamp - 2 months
or ord.add_date > current timestamp - 2 months
上面的查詢用來選擇所有兩個月內新增加的用戶以及在兩個月內定購了產品的用戶。從圖 10.a 的查詢計劃中可看出沒有任何索引被使用。
圖 10. 查詢計劃
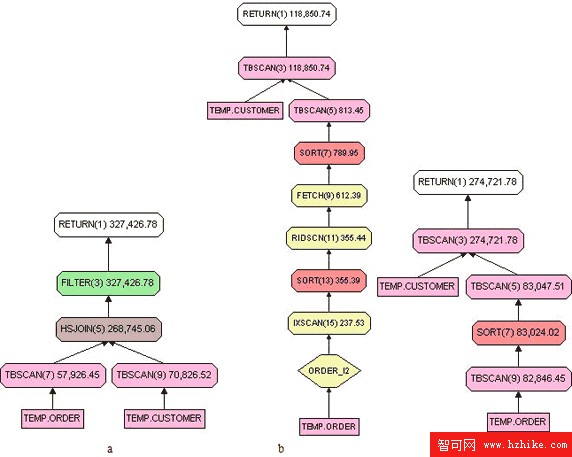
使用子查詢對該查詢重新改寫後,請看清單 17:
清單 17.
查詢:
with tmp as(
select sold_to_cust_num from temp.order
where add_date > current timestamp - 2 months)
select cust.cust_num from temp.customer cust
where cust.add_date > current timestamp - 2 months
or cust.cust_num in (select sold_to_cust_num from tmp )
在清單 17 的查詢中,我們使用子查詢預先限定了要掃描 temp.order 表中的記錄數目,而不是像清單 16 中的查詢那樣對 temp.order 表進行全表掃描。同時,在預先限定數據范圍的時候,能夠利用 temp.order_i2 索引。請看其查詢計劃,如圖 10.b。可以看到查詢代價有大幅度下降。其實,即使沒有 temp.order_i2 索引,修改後的查詢也仍然由於前者,因為它預先限定了數據的掃描范圍,也減少了後續連接處理的數據量,請看圖 10.c。
重新排列各個表的連接順序,盡量減小中間結果集的數據量
一般情況下,DB2 會根據各表的 JOIN 順序自頂向下順序處理,因此合理排列各表的連接順序會提高查詢性能。譬如清單 18 中的查詢:
清單 18.
查詢:
select cust.cust_name, ord.order_num, cnt.cnt_first_name
from temp.customer cust
left join temp.order ord
on cust.cust_num = ord.sold_to_cust_num
join temp.contact cnt
on cust.cust_num = cnt.cust_num
where cnt.mod_date > current timestamp - 1 months
清單 18 中的查詢用來選擇出所有最近一個月內修改過聯系人信息的客戶的訂單信息。此查詢會按照鏈接的順序先將 temp.customer 表和 temp.order 表進行 LEFT JOIN,然後使用結果集去 JOIN temp.contact 表。由於該查詢使用了 LEFT JOIN,因此在生成中間結果集的時候不會有任何記錄會被過濾掉,中間結果集的記錄數目大於等於 temp.customer 表。了解到了 DB2 是如何解釋和執行這樣的查詢後,很自然的我們就會想到將 JOIN 提前。請看清單 19。
清單 19.
查詢:
select cust.cust_name, ord.order_num, cnt.cnt_first_name
from temp.customer cust
join temp.contact cnt
on cust.cust_num = cnt.cust_num
left join temp.order ord
on cust.cust_num = ord.sold_to_cust_num
where cnt.mod_date > current timestamp - 1 months
圖 11.a 和圖 11.b 分別為清單 18 和 19 的查詢的存取計劃。在 19 的查詢中,在形成中間結果集的時候也應用到了 WHERE 語句中的條件,而不是在所有 JOIN 都結束以後才被應用去除記錄的。
圖 11. 查詢計劃
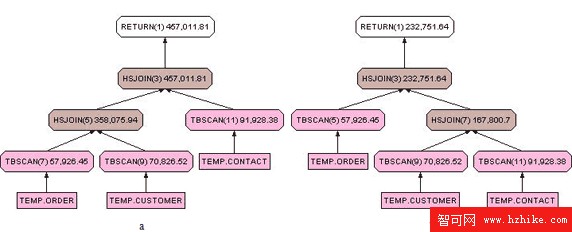
另外,在修改查詢盡量減少中間結果集的記錄條數的時候還要考慮中間結果集的數據總量,譬如中間結果集需要保存的每條記錄的長度。如果我們把 JOIN temp.contact 提前以後,由於中間結果集需要保存過多的 contact 表的列反而使得結果集的數據總量變大,可能不會帶來性能上的改善。
使用 UDF 代替查詢中復雜的部分
由於 UDF 是預先編譯的,性能普遍優於一般的查詢,UDF 使用的存取計劃一經編譯就會相對穩定。筆者在工作中曾多次發現,使用 UDF 代替查詢或者視圖中的復雜部分會提高幾倍甚至幾十倍的性能,主要原因是迫使 DB2 使用指定的存取計劃來充分利用 index 或者調整其訪問過程(如 Join 順序, Filter 位置等)。使用 UDF 進行優化的基本思路是,將復雜查詢分解為多個部分執行,針對每個部分優化處理,將各部分組合時能夠避免存取計劃的一些不必要變化,優化整體性能。譬如清單 20 中的查詢:
清單 20.
查詢:select * from temp.customer where cust_num in (
select distinct sold_to_cust_num from temp.order
where add_date > current timestamp - 2 months
union
select distinct cust_num from temp.contact
where add_date > current timestamp - 2 months
)
這個查詢會導致優化器生成比較復雜的查詢計劃,尤其是 temp.customer 是一個比較復雜的視圖的時候。這種情況下我們可以通過創建 UDF,將其分步執行:先執行子查詢獲得 cust_num 值的列表,然後執行最外層的查詢。下面的例子是通過 UDF 對清單 20 的查詢的改寫:
清單 21.
CREATE FUNCTION temp.getCustNum(p_date timestamp)
RETURNS
TABLE (cust_num CHARACTER(10))
RETURN
select distinct sold_to_cust_num from temp.order
where add_date > p_date
union
select distinct cust_num from temp.contact
where add_date > p_date;
select * from customer where cust_num in (
select cust_num from table(temp.getCustNum(current timestamp - 2 months)) tbl
)
改寫前後的查詢代價分別是 445,159.31 和 254,436.98。當面對比較復雜的查詢時考慮使用 UDF 將其拆分為多步執行常常會帶來意想不到的效果。在實際的項目中,如果數據處理和查詢調用是包含在其他應用程序中如 Unix 腳本,Java 程序等,同樣可以考慮采用分步數據處理的方式來調用數據庫,以優化應用性能。
總結
本文主要介紹了如何使用 DB2 提供的各種查看存取計劃的工具,並根據作者在 DB2 方面的開發經驗總結了一些提高查詢性能的方法和技巧。如果能夠有效地利用 DB2 提供的各種工具,理解 DB2 中索引的結構,以及查詢將如何被解釋,數據庫開發人員可以更好的提高查詢性能來滿足需求。