簡介
性能是關系到隨需應變型應用程序成功與否的關鍵。當那些應用程序使用 IBM® DB2 Universal Database™ 作為數據存儲時,至關重要的是,從一開始就應該知道有關如何在 DB2 UDB 上取得盡可能好的性能的基礎知識。在本文中,我將給出關於調優 DB2 UDB V8 系統的一些比較深入的建議。
我們將談論這一過程中自始至終存在的性能問題。您可以遵循從創建一個新數據庫到運行應用程序這之間的流程。通過本文可以看到如何使用 DB2 自動配置實用程序來初始配置數據庫管理器和數據庫環境。接著,我將討論創建緩沖池、表空間、表和索引的最佳實踐。另外,您可能還想改變一些重要配置參數的初始值,以便更好地支持應用程序,因此我們還將簡介這些配置參數。
我們將論述基於監視器(monitor)細節輸出的調優,從而展示如何使用快照監視(snapshot monitoring)幫助調優 SQL、緩沖池和各種不同的數據庫管理器以及數據庫配置參數。接著,我們將進一步研究應用程序發送給 DB2 的 SQL。通過使用 Explain,可以生成 SQL 采用的訪問計劃(Access plan),並尋找可以進一步優化的機會。我們將考察 Design Advisor 這樣一個工具,它可以根據所提供的 SQL 負載推薦出新的索引,或者評估現有的索引。最後,我們還將討論一些 DB2 SQL 選項。
此外,持續(on-going)維護對於維持最佳性能非常重要。所以我們將討論一些可以幫助我們進行持續維護的實用程序。對於那些正使用 DB2 ESE Database Partitioning Feature (DPF) 的讀者,我會用一節的篇幅談論為使數據庫高效運行而應該考慮的一些問題。有時候可能會存在某種外在的瓶頸(來自 DB2)而使您無法達到性能目標,本文列出了一些常見的瓶頸,以及用於監視這些瓶頸的實用程序。最後,本文列出了一些有價值的 IBM 資源,以幫助您發現有價值的 DB2 信息。
本文是為那些在 DB2 數據庫管理方面有中級技能的人而寫的。
讀前須知
在開始性能調優過程之前,應確保您已經應用了最新的 DB2 修訂包(fix pack)。修訂包常常會帶來性能的提高。我們要使用 DB2 FixPak 4 作為本文的基礎。如果您使用的是 FP4 之前的版本,那麼這種環境可能不能提供這裡討論的所有選項。
在進行調優時,最好是有一個關於數據庫使用(即應用程序運行在 DB2 上的工作負載)的可再現場景,這樣就可以利用這種可再現場景來量身定制調優效果。例如,如果工作負載在不同的運行期間所經歷的時間上有 10% 的變化量,那麼就很難知道調優的真正效果如何。此外,如果在兩次運行中各自的工作負載不一樣,也就難於衡量數據庫管理器和數據庫配置參數所發生的變化。
堅持跟蹤所有的變化。這樣有助於開發調優腳本或者建議,以作為供其他 DBA 參考的歷史,同時也有助於防止遵循不良的變化。
“十大”性能增強推動器
做了下面十件事情,您就幾乎可以使數據庫獲得最佳性能。通常您會發現,通過大約 10% 的配置變化,就可以達到最佳性能的 90%。我將在下面適當的小節(在圓括號中標出)中詳細討論其中的每一條:
確保有足夠的磁盤(每個 CPU 有 6-10 個磁盤才是一個好的開端)。每個表空間的容器應該跨越所有可用的磁盤。有些表空間,例如 SYSCATSPACE 以及那些表數量不多的表空間,不需要展開到所有磁盤上,而那些具有大型用戶或臨時表的表空間則應該跨越所有磁盤。( 表空間)。
緩沖池應該占用可用內存的大約 75% (OLTP) 或 50% (OLAP)( 緩沖池)。
應該對所有表執行 runstats,包括系統編目表( Runstats)。
使用 Design Advisor 為 SQL 工作負載推薦索引和檢查索引( Design Advisor)。
使用 Configuration Advisor 為應用程序環境配置數據庫管理器和數據庫( Configuration Advisor)。
日志記錄應該在一個獨立的高速驅動器上進行,該驅動器由 NEWLOGPATH 數據庫配置參數指定( Experimenting)。
通過頻繁的提交可以增加並發性( SQL 語句調優)。
應該增加 SORTHEAP,以避免排序溢出( DBM 和 DB 配置)。
對於系統編目表空間和臨時表空間,表空間類型應該為 SMS,而對於其他表空間,表空間類型應為 DMS( raw device 或者是文件)。運行 db2empfa,以便支持用於 SMS 表空間的多頁(multi-page )文件的空間分配。這將允許 SMS 表空間一次增長一個區段(Extend),而不是一頁,從而可以加快那些大型的插入操作和溢出磁盤的排序操作( 表空間)。
對於重復的語句,使用參數標記 ( SQL 語句調優)。
創建數據庫
創建一個數據庫時,系統會缺省地創建 3 個系統管理存儲(System Managed Storage,SMS) 表空間(SYSCATSPACE、TEMPSPACE1 和 USERSPACE),以及一個 4 MB 的緩沖池(IBMDEFAULTBP),這些表空間和緩沖池的頁面大小都是 4 KB 。根據下面的建議,先刪除 TEMPSPACE1 和 USERSPACE 然後再重新創建它們,通常這是一種可取的做法。幾乎在所有情況下, SYSCATSPACE 都不需要再作進一步的優化,但是如果將其容器展開到幾個磁盤上,性能上可能會有少量提升。( 稍後討論)。
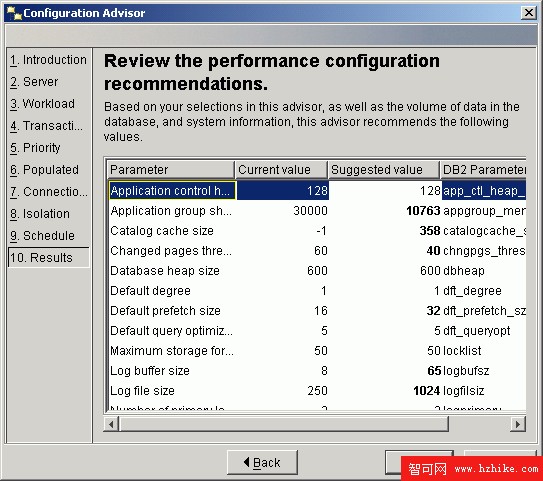
在創建數據庫時,您可以利用自動配置選項來根據環境對數據庫進行最初的配置。當應用程序以編程方式創建 DB2 數據庫時,這樣做很方便,因為可以將這些選項從應用程序提供給 DB2。在自動配置數據庫時不得不用到的另一個選項是更強大的 Configuration Advisor GUI,它不但可以配置數據庫,而且還可以配置實例。不過,要使用 Configuration Advisor,數據庫必須首先存在。我們將在 隨後的小節中討論 Configuration Advisor。
在 清單 1中,我們使用 CREATE DATABASE 命令的自動配置選項在 Windows 中創建了一個數據庫,該數據庫有一個跨越兩個可用磁盤的 SYSCATSPACE。
清單 1. 使用自動配置選項創建數據庫
create database prod1 catalog tablespace
managed by system using ('c:proddbcattbs1','d:proddbcattbs2')
extentsize 16 prefetchsize 32
autocon圖 using mem_percent 50 workload_type simple num_stmts 10
tpm 20 admin_priority performance num_local_apps 2 num_remote_aPPS
200 isolation CS bp_resizeable yes apply db and dbm
表 1顯示了有效的自動配置輸入關鍵字以及值:
表 1. 自動配置選項
關鍵字 有效值 缺省值 描述 mem_percent 1-100 25 分配給數據庫的物理存儲空間的百分比。如果本服務器(不包括操作系統)上運行有其他應用程序,那麼將其設為小於 100 的某個值 workload_type simple, mixed, complex mixed simple 型工作負載傾向於 I/O 密集型,並且大多數是事務處理(OLTP),而 complex 型工作負載則傾向於 CPU 密集型,並且大多數是查詢(OLAP/DSS) num_stmts 1-1000000 25 每個工作單元包含的語句條數 tpm 1-200000 60 每分鐘的事務數。 admin_priority performance, recovery, both both 優化以獲得更好性能(每分鐘更多的事務數)或更好的回復時間 num_local_aPPS 0-5000 0 連接的本地應用程序的數目 num_remote_aPPS 0-5000 100 連接的遠程應用程序的數目 isolation RR, RS, CS, UR RR 連接到該數據庫的應用程序的隔離級別(Repeatable Read、Read Stability、Cursor Stability 和 Uncommitted Read)。 bp_resizeable yes, no yes 是否可以在線更改緩沖池大小
Configuration Advisor
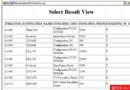
如果您在創建數據庫的時候已經使用了自動配置,那麼這一步就不是很重要了。Configuration Advisor 是一個 GUI 工具,它允許根據您針對一系列問題給出的回答自動配置數據庫和實例。通過使用這種工具,常常可以取得相當可觀的性能提升。這個工具可以從 Control Center 中通過右鍵單擊數據庫並選擇 "Configuration Advisor" 來打開。當您回答完所有問題後,就可以生成結果,還可以選擇應用結果。 圖 1展示了結果頁面的屏幕快照:
圖 1. Configuration Advisor Results 屏幕
創建緩沖池
恰當地定義緩沖池是擁有一個運行良好的系統的關鍵之一。對於 32 位操作系統,知道共享存儲器的界限十分重要,因為這種界限將限制數據庫的緩沖池(即數據庫的全局存儲器),使其不能超出以下界限(64 位系統沒有這樣的界限):
AIX - 1.75 GB
Linux - 1.75 GB
Sun - 3.35 GB
HP-UX - approximately 800 MB
Windows - 2-3 GB (在 NT/2000 上的 boot.ini 中使用的是 ' 3GB' switch)
用下面的公式計算近似的數據庫全局存儲器的使用:
清單 2. 計算全局存儲器的使用(共享存儲器)
buffer pools + dbheap + util_heap_sz + pkgcachesz + aslheapsz + locklist + approx 10% overhead
如果啟用了 INTRA_PARALLEL,那麼將 sheapthres_shr 的值加到總和中。
確定有多少緩沖池
對於數據庫中一個表空間所使用的每一種頁面大小,都需要至少一個緩沖池。通常,缺省的 IBMDEFAULTBP 緩沖池是留給系統編目的。為處理表空間的不同頁面大小和行為,須創建新的緩沖池。
對於初學者,一開始為每種頁面大小使用一個緩沖池,對於 OLAP/DSS 類型的工作負載更是如此。DB2 在其緩沖池的自我調優方面十分擅長,並且會將經常被訪問的行放入內存,因此一個緩沖池就足夠了。(這一選擇也避免了管理多個緩沖池的復雜性。)
如果時間允許,並且需要進行改進,那麼您可能希望使用多個緩沖池。其思想是將訪問最頻繁的行放入一個緩沖池中。在那些隨機訪問或者很少訪問的表之間共享一個緩沖池可能會給緩沖池帶來“污染”,因為有時候要為一個本來可能不會再去訪問的行消耗空間,甚至可能將經常訪問的行擠出到磁盤上。如果將索引保留在它們自己的緩沖池中,那麼在索引使用頻繁的時候(例如,索引掃描)還可以顯著地提高性能。
這與我們對表空間的討論是緊密聯系的,因為要根據表空間中表的行為來分配緩沖池。如果采用多緩沖池的方法,對於初學者來說使用 4 個緩沖池比較合適:
一個中等大小的緩沖池,用於臨時表空間。
一個大型的緩沖池,用於索引表空間。
一個大型的緩沖池,用於那些包含經常要訪問的表的表空間。
一個小型的緩沖池,用於那些包含訪問不多的表、隨機訪問的表或順序訪問的表的表空間。
對於 DMS 只包含 LOB 數據的表空間,可以為其分配任何緩沖池,因為 LOB 不占用緩沖池空間。
確定為緩沖池分配的內存
千萬不要為緩沖池分配多於所能提供的內存,否則就會招致代價不菲的 OS 內存分頁(memory paging)。通常來講,如果沒有進行監控,要想知道一開始為每個緩沖池分配多少內存是十分困難的。
對於 OLTP 類型的工作負載,一開始將 75% 的可用內存分配給緩沖池比較合適。
對於 OLAP/DSS,經驗法則告訴我們,應該將 50% 的可用內存分配給一個緩沖池(假設只有一種頁面大小),而將剩下的 50% 分配給 SORTHEAP。
使用基於塊(block-based)的緩沖池
倚重於預取技術的 OLAP 查詢可以得益於基於塊的緩沖池。缺省情況下,所有緩沖池都是基於頁的,這意味著預取操作將把磁盤上相鄰的頁放入到不相鄰的內存中。而如果采用基於塊的緩沖池,則 DB2 將使用塊 I/O 一次將多個頁讀入緩沖池中,這樣可以顯著提高順序預取的性能。
一個基於塊的緩沖池由標准頁區和一個塊區同時組成。CREATE 和 altER BUFFERPOOL SQL 語句的 NUMBLOCKPAGES 參數用於定義塊內存的大小,而 BLOCKSIZE 參數則指定每個塊的大小,即在一次塊 I/O 中從一個磁盤讀取的頁的數量。
共享相同區段大小的表空間應該成為一個特定的基於塊的緩沖池的專門用戶。將 BLOCKSIZE 設置為等於正在使用該緩沖池的表空間的 EXTENT SIZE。
確定分配多少內存給緩沖區內的塊區要更為復雜一些。如果要碰到大量的順序預取操作,那麼您很可能會想要更多基於塊的緩沖池。NUMBLOCKPAGES 應該是 BLOCKSIZE 的倍數,並且不能大於緩沖池頁面數量的 98%。先將它設小一點(不大於緩沖池總共大小的 15% 或剛好 15%)。在後面還可以根據快照監視(snapshot monitoring)對其進行調整。
DB2 v8 Documentation:
Concepts ==> Administration ==> Database objects ==> Buffer Pool Management
Reference ==> SQL ==> SQL Statements ==> CREATE BUFFERPOOL
Reference ==> SQL ==> SQL Statements ==> altER BUFFERPOOL
Concepts ==> Administration ==> Performance tuning ==> Operational performance ==> Memory-use organization
創建表空間
既然要為表空間分配緩沖池, 關於緩沖池的上一節就跟涉及表空間的性能問題十分相關。使用 DB2 Control Center 是創建和配置表空間的最容易的方法,也是我們推薦的方法(右鍵單擊數據庫的 Table Spaces文件夾並選擇 Create...)。
確定要創建的表空間的類型(DMS 或 SMS)
對於系統臨時表空間和系統編目表空間,應該使用 System Managed Storage(SMS),因為它允許表空間動態地增長和收縮。如果有大量臨時表要刷新到磁盤上(或者是沒有足夠的排序空間,或者是顯式地創建臨時表),則 DMS 會更有效一些。當使用 SMS 時,應該運行實用程序 'db2empfa',這個實用程序將支持多頁文件分配,從而一次一個區段地增長表空間,而不是一次一頁地增長表空間。
對於所有其他的表空間,應該使用 Database Managed Storage(DMS)。DMS 允許一個表跨越多個表空間(索引、用戶數據和 LOB),這樣就減少了在預取和更新操作時索引、用戶和 LOB 數據之間的爭用,從而縮短了數據訪問的時間。通過使用 DMS raw 甚至還可以擠出額外的 5-10% 的性能提升。
確定頁面大小
為了創建一個表,必須有一個表空間,其頁面大小應足以容納一行。您可以選擇使用 4、8、16 或 32 KB 這幾種頁面大小。有時候必須使用較大的頁面大小,以回避某些數據庫管理器的限制。例如,表空間的最大尺寸與表空間的頁面大小成比例。如果使用 4K 的頁面大小,那麼表空間的大小(每個分區)最大是 64 GB,如果使用 32K 的頁面大小,那麼最大是 512 GB。
對於執行隨機更新操作的 OLTP 應用程序,采用較小的頁面大小更為可取,因為這樣消耗的緩沖池中的空間更少。
對於要一次訪問大量連續行的 OLAP 應用程序,通常使用較大頁面大小效果會更好些,因為這樣可以減少在讀取特定數量的行時發出的 I/O 請求的數量。較大的頁面大小還允許您減少索引中的層數,因為在一頁中可以保留更多的行指針。然而,也有例外情況。如果行長度小於頁面大小的 255 分之 1,則每一頁中都將存在浪費的空間,因為每頁最多只能有 255 行(對於索引數據頁不適用)。在這種情況下,采用較小的頁面大小或許更合適一些。
例如,如果要使用 32K 的頁面大小來存儲平均大小為 100 字節的行,則一個 32 KB 的頁只能存儲 100 * 255 = 25500 byte (24.9 KB)。這意味著每 32 KB 中就有大約 7 KB 要浪費掉。
確定表空間的數量
與緩沖池一樣,一開始應該為每種頁面大小使用一個緩沖池。對於所使用的每種頁面大小,必須存在一個具有匹配頁面大小的系統臨時表空間(以支持排序和重組)。然後將所有享用匹配頁面大小的表空間指派給具有相同頁面大小的緩沖池。
如果您還關心性能問題,並且有時間投入,那麼可以使用 DMS 表空間,並且根據使用情況來組織表。另外,還要遵循前面給出的關於使用多個緩沖池的建議。
對於每種頁面大小,創建一個:
系統臨時表空間。
用於索引的常規表空間。
用於頻繁訪問的表的常規表空間。
用於訪問不多的表、隨機訪問的表以及順序訪問的表的常規表空間。
用於 LOB 數據的大型表空間。
容器布局
一開始最好是對於每個 CPU 分配 6-10 個磁盤給表空間。每個表空間應該跨越多個磁盤,也就是說,在每個可用磁盤上有一個(且不多於一個)容器。
有多少個表空間,就應該在每個磁盤上創建相同數量的邏輯卷(UNIX)。這樣一來,每個表空間在每個磁盤上都有自己的邏輯卷(logical volume),用以放置容器。如果不是使用 raw device,那麼就需要在每個邏輯卷內創建一個文件系統。
磁盤陣列和存儲子系統
對於大型磁盤系統,應該使用單個容器。此外,還需要為表空間設置 DB2 Profile Registry 變量 DB2_PARALLEL_IO。這一點放在 概要注冊表一節中討論。
區段大小
Extent Size 指定在跳到下一個容器之前,可以寫入到一個容器中的 PAGESIZE 頁面的數量,這個參數是在創建表空間時定義的(之後不能輕易修改)。處理較小的表時,使用較小的區段效率會更高一些。
下面的經驗法則是建立在表空間中每個表的平均大小的基礎上的:
如果小於 25 MB,Extent Size 為 8
如果介於 25 到 250 MB 之間,則 Extent Size 為 16
如果介於 250 MB 到 2 GB 之間,則 Extent Size 為 32
如果大於 2 GB,則 Extent Size 為 64
對於 OLAP 數據庫和大部分都要掃描(僅限於查詢)的表,或者增長速度很快的表,應使用較大的值。
如果表空間駐留在一個磁盤陣列上,則應將區段大小設置成條紋大小(也就是說,寫入到陣列中一個磁盤上的數據)。
預取大小
通過使用 altER TABLESPACE 可以輕易地修改預取大小。最優設置差不多是這樣的:Prefetch Size = (# Containers of the table space on different physical disks) * Extent Size
如果表空間駐留在一個磁盤陣列上,則設置如下: PREFETCH SIZE = EXTENT SIZE * (# of non-parity disks in array)。
DB2 v8 Documentation:
Concepts ==> Administration ==> Database design ==> Physical ==> Table Space Design
Reference ==> SQL ==> SQL Statements ==> CREATE TABLESPACE
Reference ==> SQL ==> SQL Statements ==> altER TABLESPACE
創建表
多維群集(Multidimensional clustering ,MDC)
MDC 提供了數據在多個維上的靈活的、連續的和自動的多維群集。它提升了查詢的性能,並且減少了在插入、更新和刪除期間對 REORG 和索引維護的需要。
多維群集從物理上把表數據同時沿著多個維群集起來,這與使用表上的多個獨立的群集的索引類似。MDC 通常用於幫助提高對大型表的復雜查詢的性能。這裡不需要使用 REORG 來重新群集索引,因為 MDC 會自動地、動態地維護每個維上的群集。
對於一個 MDC,最合適的是那些具有范圍、相等和連接謂詞的訪問多行的查詢。千萬不要使用具有惟一性的列作為一個維,因為這樣會導致一個表不必要地變大。如果具有每種維值組合(即單元)的行不是很多,應避免使用太多的維。為獲得最佳的性能,那麼至少需要有足夠的行來填滿每個單元的塊,也就是該表所在表空間的區段大小。
DB2 v8 Documentation:
Concepts ==> Administration ==> Database design ==> Logical ==> Multidimensional clustering (MDC)
Concepts ==> Administration ==> Database objects ==> Tables ==> Multidimensional clustering (MDC) tables
物化查詢表(MQT)
MQT 可用於提升使用 GROUP BY、GROUPING、RANK 或 ROLLUP OLAP 函數的查詢的性能。MQT 的使用對用戶來說是透明的,DB2 選擇何時使用 MQT 來達到優化的目的。DB2 使用 MQT 在內部維護被查詢的分組的總結結果,這樣用戶就可以直接訪問 DB2 維護的分組,而不必去讀動辄數 GB 的數據來尋找答案。這些 MQT 還可以在分區間復制,以避免這種信息在分區間的散播,從而幫助提升合並連接(collocated jion)的性能。
CREATE TABLE 選項
對於 30 字節或更少字節的列,應避免使用 VARCHAR 數據類型,因為這種情況下,VARCHAR 類型通常會浪費空間,所以建議使用 CHAR 類型。如果數據量很大,那麼空間的浪費往往會對查詢時間造成影響。
當使用 IDENTITY或 SEQUENCE時,應至少使用缺省的大小為 20 的緩存(除非編號中的間隔很有干系)。這樣一來,就不必在每次需要的時候請求 DBM 生成一個數字,同時也避免了在生成數字時要做的日志記錄。
當一個表使用很多空值和系統缺省值時, VALUE COMPRESSION和 COMPRESS SYSTEM DEFAULT可以節省磁盤空間。系統缺省值是指在沒有指定特定的值時,為某個數據類型而使用的缺省值。如果量很大,這樣還可以幫助縮短查詢時間。如果插入或者更新一個值,壓縮的列只會招致很少的開銷。
ALTER TABLE 選項
對於有大量插入操作的表,使用 APPEND ON以避免在插入過程中搜索空閒空間,而只需將行附加在表的最後。如果要依賴於處於某種特殊順序中的表,並且無法承受執行 REORG 的開銷,那麼應避免使用 APPEND ON。
對於只讀的表或者獨占訪問的表,將 LOCKSIZE設置為 TABLE。這樣就避免了為行加鎖時所費的時間,並且減少了所需的 LOCKLIST 數量。
使用 PCTFREE來維護空閒空間,以助將來的 INSERT、LOAD 和 REORG 一臂之力。PCTFREE 的缺省值是 10;對於具有群集索引和插入量很大的表,可以嘗試使用 20-35。如果使用 APPEND ON,則將 PCTFREE 設置為 0。
使用 VOLATILE來鼓勵索引掃描。易變(volatile)表明表的基數可以在很大的范圍內顯著變化,從一個很大的數一直到空。這樣就促使優化器不管表的統計數字如何,都使用索引掃描,而不是使用表掃描。不過,只有在索引包含所有被引用的列,或者索引可以在索引掃描時應用謂詞的情況下,上述情況才會出現。
使用 NOT LOGGED INITIALLY將事務執行期間(也就是直到 COMMIT)的日志記錄關閉掉。
VALUE COMPRESSION和 COMPRESS SYSTEM DEFAULT還可以用在 altER TABLE 命令中。
DB2 v8 Documentation:
Reference ==> SQL ==> SQL Statements ==> CREATE TABLE
Reference ==> SQL ==> SQL Statements ==> altER TABLE
創建索引
由於有了 Design Advisor,設計索引的負擔已經消除。Design Advisor 用於為特定的 SQL 工作負載(即一組 SQL 語句)推薦和評估索引, 很快我們就將討論這個工具。
下面仍然是一些您應該知道的跟索引有關的問題:
當要在一個合理的時間內結束查詢時,應避免添加索引,因為索引會降慢更新操作的速度並消耗額外的空間。有時候還可能存在覆蓋好幾個查詢的大型索引。
基數較大的列很適合用來做索引。
考慮到管理上的開銷,應避免在索引中使用多於 5 個的列。
對於多列索引,將查詢中引用最多的列放在定義的前面。
避免添加與已有的索引相似的索引。因為這樣會給優化器帶來更多的工作,並且會降慢更新操作的速度。相反,我們應該修改已有的索引,使其包含附加的列。例如,假設在一個表的 (c1,c2) 上有一個索引 i1。您注意到查詢中使用了 "where c2=?",於是又創建一個 (c2) 上的索引 i2。但是這個相似的索引沒有添加任何東西,它只是 i1 的冗余,而現在反而成了額外的開銷。
如果表是只讀的,並且包含很多的行,那麼可以嘗試定義一個索引,通過 CREATE INDEX 中的 INCLUDE 子句使該索引包含查詢中引用的所有列(被 INCLUDE 子句包含的列並不是索引的一部分,而只是作為索引頁的一部分來存儲,以避免附加的數據 FETCHES)。
群集索引
我們可以創建群集索引來為表中的行排序,並且是按照所需結果集的物理順序來排序。群集索引可以用 CREATE INDEX 語句的 CLUSTER 選項來創建。為獲得最佳性能,應該在那些小型的數據類型(比如整型和 char(10))、具有惟一性的列以及在范圍搜索中經常要用到的列上創建索引。
群集索引允許對數據頁采用更線性的訪問模式,允許更有效的預取,並且有助於避免排序。這意味著插入操作要花更多的時間,但是查詢操作會更快。當使用群集索引時,應考慮將數據頁和索引頁上的空閒空間增加到大約 15-35(而不是 PCTFREE 的缺省值 10),以允許大容量的插入。對於會受到大量插入操作的表,考慮使用單維的 MDC 表(或許是使用像 idcolumn/1000 或 INT(date)/100 這樣的生成列)。這將導致對數據(在維上)的塊索引,而不是按行索引。這樣產生的索引會更小一些,並且在插入期間的日志內容也大大減少。
CREATE INDEX 選項
對於只讀表上的索引,使 PCTFREE為 0,對於其他索引使 PCTFREE 為 10,以提供可用的空間,從而加快插入操作的速度。此外 ,對於有群集索引的表,這個值應該更大一些,以確保群集索引不會被分成太多的碎片。如果存在大量的插入操作,那麼使用 15 ' 35 之間的值或許更合適一些。
使用 ALLOW REVERSE SCANS以便可以對一個索引進行雙向(bi-directionally)掃描,也就是說,可以對按升序排列的結果集和按降序排列的結果集進行更快速的檢索。這樣做還沒有負面的性能影響,因為在為這個特性提供支持的過程中,並沒有在內部改變索引的結構。
可以使用 INCLUDE將其他沒有被索引的列包括到索引頁中來,以促進純索引訪問,並避免了從數據頁取數據。
可以使用 UNIQUE 列來有效地實施一個列或一組列的惟一性。
TYPE-2 INDEXES可以大大減少 next-key 鎖,允許索引列大於缺省的 255 字節,允許在線 REORG 和 RUNSTATS,並且支持新的多維群集功能。在 v8 中,所有新的索引都是以 type-2 類型創建的,只有已經在表上定義了(遷移前) type-1 索引的時候才是例外。可以使用 REORG INDEXES 將 type-1 索引轉換為 type-2 索引。
DB2 v8 Documentation:
Concepts ==> Administration ==> Performance tuning ==> Operational performance ==> Table and index management ==> Index planning
Concepts ==> Administration ==> Performance tuning ==> Operational performance ==> Table and index management ==> Performance tips for indexes
Reference ==> SQL ==> SQL Statements ==> CREATE INDEX
概要注冊表配置
DB2 概要注冊表變量通常要影響優化器和 DB2 引擎本身的行為。雖然概要注冊表變量有很多,但是其中的大部分都有其非常特定的用途,因而在大部分的 DB2 環境中都不會用到。下面是一些常用的概要注冊表變量。
表 2列出了用於概要注冊表一些基本管理命令:
表 2. 概要注冊表管理
命令 描述 db2set -all 列出所有當前設置的 DB2 注冊表變量 db2set -g | -i variable= value 設置指定的 DB2 注冊表變量,使其或者處於全局(-g)級,或者處於實例(-i)級
注意:在變量和值之間不要有空格,否則變量又會重新被設置成缺省值。
DB2_PARALLEL_IO
這將幫助促使對駐留在磁盤陣列上的任何表空間采用並行訪問。如果所有表空間都在磁盤陣列上,則將該變量設置成等於 *。如果只有一些表空間在磁盤陣列上,則使用 "db2 list tablespaces" 檢索這些表空間的 ID,並將該變量設置成這些 ID(使用逗號將各 ID 分隔開)。為獲得最佳性能,應確保表空間的預取大小明顯大於它的區段大小。
DB2_EVALUNCOMMITTED
缺省值是 OFF,如果將其改為 ON,則會將鎖操作推遲到謂詞演算。啟用這個變量對於減少從 Oracle 移植過來的應用程序中存在的鎖爭用十分有用。
DB2_SKIPDELETED
缺省值是 OFF,如果將其改為 ON,則允許使用 CS 或 RS 的語句略過索引中被刪除的鍵以及表中被刪除的行。同樣,啟用這個變量對於減少從 Oracle 移植過來的應用程序中存在的鎖爭用十分有用。
DB2_HASH_JOIN
缺省值是 Enabled。如果禁用 DB2_HASH_JOIN(NO),則 OLTP 可能受益。
(AIX): DB2_FORCE_FCM_BP
缺省值是 NO。如果使用了 DB2 的 Database Partitioning Feature (DPF) 功能,並且有多個邏輯分區,那麼將該變量設置為 YES 可以改善分區間的通信,代價是可供緩沖池使用的共享內存段要少掉一個。如果沒有使用數據庫分區功能,則應使用 NO 值。
(AIX 4.3) DB2_MMAP_READ 和 DB2_MMAP_WRITE
缺省情況下兩者都處於啟用狀態的。如果使用 AIX 4.3,32 位的 DB2,並且內存會限制增加緩沖池的大小,那麼應將此變量設置成 OFF,以便多釋放一個內存段。這樣大約可以釋放 256 MB 的共享內存(這樣就可以將其中一部分用於緩沖池)。可以進行一些測試,以確信這一更改的確提升了性能,因為有時候對磁盤使用內存映射的讀和寫比起增加緩沖池大小來可以獲得更好的性能,雖然這種做法並不常見。
DB2 v8 Documentation:
Reference ==> Registry and environment variables
通過配置避免運行時錯誤
應用程序開始運行的時候,通常會暴露出與某些配置參數有關的問題。如果在應用程序運行期間沒有收到任何錯誤或警告信息,那麼就是安全的。如果收到了這樣的信息,那麼請參閱本文後面對 數據庫管理器和數據庫配置參數管理的討論。如果沒有足夠的內存來處理 SQL,下面的一些配置參數就會出問題:
MON_HEAP_SZ (DBM)
這是為數據庫系統監視器(system monitor)數據分配的內存數量。當執行諸如快照監視或激活一個事件監視器之類的數據庫監控活動時,就要從監視器堆中分配內存。如果沒有足夠的可用內存,並且 DB2 返回一個錯誤,則可以試著將這個值設為 256。如果還是遇到錯誤,一次一次地增加 256,直到錯誤消失。
QUERY_HEAP_SZ (DBM)
這是為了將每個查詢存儲到代理的私有內存時可以分配的最大內存量。查詢堆還可用於為塊游標(blocking cursor)提供內存分配。查詢堆的大小必須大於或等於 ASLHEAPSZ。如果收到 DB2 返回的一個錯誤,表明性能可能不是最優,而處於最低狀態,那麼可將此參數設為至少大於 ASLHEAPSZ 的五倍,這樣就允許查詢大於 ASLHEAPSZ,並且為 3 個或 4 個並發的塊游標足夠的內存。
MAXAPPLS (DB)
該參數指定可以連接(包括本地連接和遠程連接)到一個數據庫的並發的應用程序的最大數目。在絕對最小值情況下,將此參數設置為 >= (用戶連接的數量)。要了解詳細信息,請參閱本文後面對 MAXAGENTS的討論。
STMTHEAP (DB)
語句堆用於在 SQL 語句的編譯期間作為編譯器的工作區。對於每一條要處理的 SQL 語句,都要從該區域分配和釋放空間。如果收到警告信息或錯誤信息,那麼可以按 256 逐次增加,直到錯誤消失。
APPLHEAPSZ (DB)
應用程序堆是供數據庫管理器代表某個特定代理使用的私有內存。當代理或子代理要為應用程序而初始化時,就要從這個堆中分配內存,並且所分配的內存數量是處理請求時所需的最小內存量,如果需要更多的內存,則最多可以從堆中分配由該參數指定的一個最大值那麼多的內存。按 256 逐次增加,直到錯誤消失。
為提高性能進行快照監視
使用快照監視來識別數據庫在一段時間裡的行為,顯示一些諸如內存使用情況和鎖的獲得過程之類的信息。監控是用於微調配置和識別問題(例如語句執行時間較長)的一種方法。如果已經使用了 Configuration Advisor,那麼這裡可能無法在性能上獲得什麼好處。
要收集供分析的數據,最容易的方法是在應用程序運行的時候用一個腳本來執行抽樣的快照監視。像 清單 3中或者 清單 4中顯示的腳本將會收集您進入下一步之前所需的所有信息。首先在 60 秒的一段時間內運行該腳本,其中有幾次間歇;這樣應該可以對應用程序行為的一個較好的抽樣,並且不會有太多的信息要處理。
清單 3. getsnap.ksh (UNIX)
#!/usr/bin/ksh
# take a snapshot after specifIEd sleep period for a number of iterations
# parameters: (1) database name
# (2) directory for output
# (3) interval between iterations (seconds)
# (4) maximum number of iterations
#
# Note: You may receive an error about the monitor heap being too small. You may
# want to set mon_heap_sz to 2048 while monitoring.
if [ $# -ne 4 ]
then echo "4 parameters required: dbname output_dir sleep_interval iterations"; exit
fi
dbname=$1
runDir=$2
sleep_interval=$3
iterations=$4
stat_interval=3
stat_iterations=$(($sleep_interval/$stat_interval))
if [[ -d $runDir ]]; then
echo "dir: $runDir already exists, either remove it or 使用 another directory name"
exit
fi
mkdir $runDir
cd $runDir
db2 update monitor switches using bufferpool on lock on sort on statement on
table on uow on
# repeat the snapshot loop for the specifIEd iterations
let i=1
while [ i -le $iterations ]
do
if [ $i -le 9 ]
then
i2="0$i"
else
i2="$i"
fi
echo "Iteration $i2 (of $iterations) starting at `date`"
vmstat $stat_interval $stat_iterations > vmstat_$i2
iostat $stat_interval $stat_iterations > iOStat_$i2
db2 -v reset monitor all
sleep $sleep_interval
db2 -v get snapshot for dbm > snap_$i2
db2 -v get snapshot for all on $dbname >> snap_$i2
echo "Iteration $i2 (of $iterations) complete at `date`"
let i=$i+1
done
db2 update monitor switches using bufferpool off lock off sort off statement off
table off uow off
db2 terminate
清單 4. getsnap.bat (Windows)
@echo off
REM
REM take a snapshot after specifIEd sleep period for a number of iterations
REM parameters: (1) database name
REM (2) file name id
REM (3) interval between iterations (seconds)
REM (4) maximum number of iterations
REM
REM Note: You may receive an error about the monitor heap being too small. You may
REM want to set mon_heap_sz to 2048 while monitoring.
:CHECKINPUT
IF ""=="%4" GOTO INPUTERROR
GOTO STARTPRG
:INPUTERROR
echo %0 requires 4 parameters: dbname filename_id sleep_interval iterations
echo e.g. "getsnap.bat sample 0302 60 3"
GOTO END
:STARTPRG
SET dbname=%1
SET fileid=%2
SET sleep_interval=%3
SET iterations=%4
db2 update monitor switches using bufferpool on lock on sort on statement on table on uow on
REM repeat the snapshot loop for the specifIEd iterations
SET i=1
:SNAPLOOP
IF %i% LSS 10 SET i2=0%i%
IF %i% GTR 9 SET i2=%i%
echo Starting Iteration %i2% (of %iterations%)
db2 -v reset monitor all
sleep %sleep_interval%
db2 -v get snapshot for dbm > snap%i2%_%fileid%
db2 -v get snapshot for all on %dbname% >> snap%i2%_%fileid%
echo Completing Iteration %i2% (of %iterations%)
SET /a i+=1
IF %i% GTR %iterations% GOTO ENDLOOP
GOTO SNAPLOOP
:ENDLOOP
db2 update monitor switches using bufferpool off lock off sort off statement off table off uow off
db2 terminate
:END
注意,這兩個腳本在行為上稍有不同,但是都可以產生所需的快照輸出。
在後面的一些小節中,快照監視可用作尋找 DBM 和 DB 配置參數的最優設置的一種方式。
DB2 v8 Documentation:
Reference ==> System monitor ==> Snapshot monitor
動態 SQL 語句
清單 3和 清單 4中顯示的腳本將發出一個 "get snapshot for all on dbname" 命令,該命令包括 "get snapshot for dynamic SQL on dbname" 命令的所有輸出。如果您發現不會捕獲很多的 SQL 語句,那麼可以增加監控的歷時。一條語句的輸出的 "Dynamic SQL Snapshot Result" 部分看上去如 清單 5所示:
清單 5. 示例動態 SQL 快照
Dynamic SQL Snapshot Result
Database name = SAMPLE
Database path = C:DB2NODE0000SQL00003
Number of executions = 1
Number of compilations = 1
Worst preparation time (ms) = 1624
Best preparation time (ms) = 1624
Internal rows deleted = 0
Internal rows inserted = 0
Rows read = 41
Internal rows updated = 0
Rows written = 0
Statement sorts = 0
Total execution time (sec.ms) = 0.134186
Total user cpu time (sec.ms) = 0.000000
Total system cpu time (sec.ms) = 0.000000
Statement text = select * from sales
...
您可以看到,在輸出中可以搜索一些很有用的字符串。
"Number of executions"- 可以幫助您找到應該調優的那些重要語句。它對於幫助計算語句的平均執行時間也很有用。
對於執行時間很長的語句,單獨執行一次或許對系統要求不多,但是累加起來的結果就會大大降低性能。應盡量理解應用程序如何使用該 SQL,或許只需對應用程序邏輯稍微重新設計一下就可以提高性能。
看看是否可以使用參數標記(parameter marker),以便只需為語句創建一個包,這一點也很管用。參數標記 可用作動態准備的語句(生成訪問計劃時)中的占位符。在執行的時候,就可以將值提供給這些參數標記 marker,從而使語句得以運行。
例如,要搜索執行得最頻繁的語句:
UNIX:
grep -n " Number of executions"
snap.out | grep -v "= 0" | sort -k 5,5rn | more
Windows:
findstr /C:" Number of executions"
snap.out | findstr /V /C:"= 0"
"Rows read"- 可幫助識別讀取行數最多的 Dynamic SQL 語句。如果讀取的行數很多,通常意味著要進行表掃描。如果這個值很高,也可能表明要進行索引掃描,掃描時選擇性很小,或者沒有選擇性,這跟表掃描一樣糟糕。
您可用使用 Explain 來查看是否真的如此。如果有表掃描發生,那麼可以對表執行一次 RUNSTATS,或者將 SQL 語句提供給 DB2 Design Advisor,以便令其推薦一個更好的索引,以此來進行彌補。如果是選擇性很差的索引掃描,或許需要一個更好的索引。可以試試 Design Advisor。
grep -n " Rows read"
snap.out | grep -v "= 0" | sort -k 5,5rn
findstr /C:" Rows read"
snap.out | findstr /V /C:"= 0"
"Total execution time" - 這是將語句每次執行時間加起來得到的總執行時間。我們可以很方便地將這個數字除以執行的次數。如果發現語句的平均執行時間很長,那麼可能是因為表掃描和/或出現鎖等待(lock-wait)的情況。索引掃描和頁面獲取導致的大量 I/O 活動也是一個原因。通過使用索引,通常可以避免表掃描和鎖等待。鎖會在提交的時候解除,因此如果提交得更頻繁一些,或許可以彌補鎖等的問題。
grep -n " Total execution time"
snap.out | grep -v "= 0.0" | sort -k 5,5rn | more
findstr /C:" Total execution time"
snap.out | findstr /V /C:"= 0.0" |sort /R
"Statement text"顯示語句文本。如果注意到了重復的語句,這些語句除了 WHERE 子句中謂詞的值有所不同以外,其他地方都是一致的,那麼就可以使用參數標記,以避免重新編譯語句。這樣可以使用相同的包,從而幫助避免重復的語句准備,而這種准備的消耗是比較大的。還可以將語句文本輸入到 Design Advisor 中,以便生成最優的索引。
grep -n " Statement text"
snap.out | more
findstr /C:"Statement text"
snap.out
緩沖池大小的設置
通過使用 "get snapshot for all on dbname" 可以為數據庫上的每個緩沖池生成一個快照。 清單 6展示了那樣一個快照:
清單 6. 示例緩沖池快照
Bufferpool Snapshot
Bufferpool name = IBMDEFAULTBP
Database name = SAMPLE
Database path = C:DB2NODE0000SQL00002
Input database alias = SAMPLE
Snapshot timestamp = 02-20-2004 06:24:45.991065
Buffer pool data logical reads = 370
Buffer pool data physical reads = 54
Buffer pool temporary data logical reads = 0
Buffer pool temporary data physical reads = 0
Buffer pool data writes = 3
Buffer pool index logical reads = 221
Buffer pool index physical reads = 94
Buffer pool temporary index logical reads = 0
Buffer pool temporary index physical reads = 0
Total buffer pool read time (ms) = 287
Total buffer pool write time (ms) = 1
Asynchronous pool data page reads = 9
Asynchronous pool data page writes = 0
Buffer pool index writes = 0
Asynchronous pool index page reads = 0
Asynchronous pool index page writes = 0
Total elapsed asynchronous read time = 0
Total elapsed asynchronous write time = 0
Asynchronous data read requests = 3
Asynchronous index read requests = 0
No victim buffers available = 0
Direct reads = 86
Direct writes = 4
Direct read requests = 14
Direct write requests = 2
Direct reads elapsed time (ms) = 247
Direct write elapsed time (ms) = 56
Database files closed = 0
Data pages copIEd to extended storage = 0
Index pages copIEd to extended storage = 0
Data pages copIEd from extended storage = 0
Index pages copIEd from extended storage = 0
Unread prefetch pages = 0
Vectored iOS = 3
Pages from vectored iOS = 9
Block iOS = 0
Pages from block iOS = 0
Physical page maps = 0
Node number = 0
Tablespaces using bufferpool = 4
Alter bufferpool information:
Pages left to remove = 0
Current size = 250
Post-alter size = 250
為了判斷一個緩沖池的效率,需要計算它的緩沖池命中率(BPHR)。您所需的重要信息在上面已經用粗體標出來了。如果可能的話,一個理想的 BPHR 在某些地方應超過 90%。公式如下:
BPHR (%) = (1 - (("Buffer pool data physical reads" + "Buffer pool index physical reads") /
("Buffer pool data logical reads" + "Buffer pool index logical reads"))) * 100
在 IBMDEFAULTBP 緩沖池的 以上快照中,我們可以這樣來計算 BPHR:
= (1-((54 + 94) / (370 + 221))) * 100
= (1-(148 / 591)) * 100
= (1- 0.2504) * 100
= 74.96
在這種情況下,BPHR 大約等於 75%。當前,緩沖池只有 250 * 4KB 頁(1MB)。增加該緩沖池的大小,看看 BPHR 是否會隨之增加,這樣做是值得的。如果 BPHR 還是比較低,那麼可能就需要像 創建緩沖池和 創建表空間這兩節中討論的那樣重新設計邏輯布局。
基於塊的緩沖池的效率
如果是一個基於塊的緩沖池,並且看到 "Block IOs" 的值較低,那麼應考慮修改緩沖池,增加 NUMBLOCKPAGES 的大小。如果這時看到 "Block iOS" 的值更大了,則可以考慮將 NUMBLOCKPAGES 再增大一些。如果結果適得其反,則應減小 NUMBLOCKPAGES 的大小。
DBM 和 DB 配置
DB2 有幾十個配置參數。很多參數都是由 DB2 自動配置的,而其他一些參數都有它們的缺省值,這些缺省值都被證明在大多數環境中能夠發揮得很好。接下來,我們只描述那些常常需要另外進行配置的參數。
有些數據庫管理器(即實例)配置參數可以在線更改(立即生效),而另一些參數則要求對實例實行再循環(即 DB2STOP 之後接著又是 DB2START)。對於數據庫配置參數也是一樣。有些參數的更改可以立即生效,而另一些參數則要求先停止數據庫,再重新激活數據庫。關於每種配置參數的文檔都規定了參數是否可以在線配置。
數據庫管理器和數據庫配置文件的基本管理命令如 表 3所示:
表 3. 數據庫管理器和數據庫配置管理
命令 描述 GET DBM CFG [SHOW DETAIL] 列出數據庫管理器配置文件中的當前值 UPDATE DBM CFG USING config_param value 將指定的數據庫管理器配置參數設置成指定的值 GET DB CFG FOR db_name[SHOW DETAIL] 列出某個特定數據庫的配置文件中的當前值 UPDATE DB CFG FOR db_nameUSING config_param value 將指定的數據庫管理器配置參數設置成指定的值
當您對一個配置參數作了更改時,就可以用下面的 DB2 CLP 命令查看該設置是否立即生效(在線):
GET DBM CFG SHOW DETAIL
GET DB CFG FOR dbname SHOW DETAIL
例如,在接下來的情況中,MAX_QUERYDEGREE 和 MAXTOTFILOP 分別增加到了 3 和 19000。如果參數是在線配置的,則 Delayed Value 跟 Current Value 應該是一樣的。否則,就需要重新啟動實例,或者重新激活數據庫。
清單 7. Show Details 實例
Database Manager Configuration
Node type = Enterprise Server Edition with local and remote clIEnts
Description Parameter Current Value Delayed Value
-------------------------------------------------------------------------------------------
Maximum query degree of parallelism (MAX_QUERYDEGREE) = 3 3
Maximum total of files open (MAXTOTFILOP) = 16000 19000
下面的配置參數中,有些是從共享內存分配空間的,所以應該記住 OS 的限制(在 前面已討論)。您必須確保沒有過度分配內存。如果過度分配內存,就會導致操作系統發生換頁(page),這對於性能來說是災難性的。
DB2 v8 Documentation:
Reference ==> Configuration parameters ==> Database manager
Reference ==> Configuration parameters ==> Database
清單 8和 清單 9顯示了一個數據庫管理器和數據庫快照的示例。順著右邊(順帶提一下),可以看到能根據輸出進行調優的配置參數。
清單 8. 數據庫管理器快照
Database Manager Snapshot
Node name =
Node type = Enterprise Server Edition with
local and remote clIEnts
Instance name = DB2
Number of database partitions in DB2 instance = 1
Database manager status = Active
Product name = DB2 v8.1.4.341
Service level = s031027 (WR21326)
Private Sort heap allocated = 0 (SHEAPTHRES
Private Sort heap high water mark = 1024
Post threshold sorts = 0 and
Piped sorts requested = 0
Piped sorts accepted = 0 SORTHEAP)
Start Database Manager timestamp = 02-17-2004 14:24:37.107003
Last reset timestamp =
Snapshot timestamp = 02-20-2004 06:19:53.272049
Remote connections to db manager = 0 (MAXAGENTS,MAXAPPLS,MAX_COORDAGENTS)
Remote connections executing in db manager = 0
Local connections = 1 (MAXAGENTS,MAXAPPLS,MAX_COORDAGENTS)
Local connections executing in db manager = 0
Active local databases = 1 (NUMDB)
High water mark for agents registered = 8 (MAXAGENTS)
High water mark for agents waiting for a token = 0
Agents registered = 8 (MAXAGENTS)
Agents waiting for a token = 0
Idle agents = 6 (NUM_POOLAGENTS and NUM_INITAGENTS)
Committed private Memory (Bytes) = 46645248
Switch list for db partition number 0
Buffer Pool Activity Information (BUFFERPOOL) = ON 02-20-2004 06:18:57.403336
Lock Information (LOCK) = ON 02-20-2004 06:18:57.403338
Sorting Information (SORT) = ON 02-20-2004 06:18:57.403339
SQL Statement Information (STATEMENT) = ON 02-20-2004 06:18:57.403333
Table Activity Information (TABLE) = ON 02-20-2004 06:18:57.403335
Take Timestamp Information (TIMESTAMP) = ON 02-17-2004 14:24:37.107003
Unit of Work Information (UOW) = ON 02-20-2004 06:18:57.403328
Agents assigned from pool = 26 (NUM_POOLAGENTS and NUM_INITAGENTS)
Agents created from empty pool = 10 (NUM_POOLAGENTS and NUM_INITAGENTS)
Agents stolen from another application = 0 (MAXAGENTS)
High water mark for coordinating agents = 8
Max agents overflow = 0 (MAXAGENTS)
Hash joins after heap threshold exceeded = 0
Total number of gateway connections = 0
Current number of gateway connections = 0
Gateway connections waiting for host reply = 0
Gateway connections waiting for clIEnt request = 0
Gateway connection pool agents stolen = 0
Node FCM information corresponds to = 2
Free FCM buffers = 4093
Free FCM buffers low water mark = 4087 (FCM_NUM_BUFFERS)
Free FCM message anchors = 1279
Free FCM message anchors low water mark = 1276
Free FCM connection entrIEs = 1280
Free FCM connection entrIEs low water mark = 1276
Free FCM request blocks = 2031
Free FCM request blocks low water mark = 2026
Number of FCM nodes = 4
Node Total Buffers Total Buffers Connection (FCM_NUM_BUFFERS)
Number Sent Received Status
----------- ------------------ ------------------ -----------------
0 282 275 Active
1 51 48 Active
2 0 0 Active
3 1 1 Active
Memory usage for database manager:
Memory Pool Type = Backup/Restore/Util Heap (UTIL_HEAP_SZ*)
Current size (bytes) = 16384
High water mark (bytes) = 16384
Maximum size allowed (bytes) = 20660224
Memory Pool Type = Package Cache Heap (PCKCACHESZ*)
Current size (bytes) = 327680
High water mark (bytes) = 327680
Maximum size allowed (bytes) = 1071644672
Memory Pool Type = Catalog Cache Heap (CATALOGCACHE_SZ*)
Current size (bytes) = 81920
High water mark (bytes) = 81920
Maximum size allowed (bytes) = 1071644672
Memory Pool Type = Buffer Pool Heap
Current size (bytes) = 1179648
High water mark (bytes) = 1179648
Maximum size allowed (bytes) = 1071644672
Memory Pool Type = Lock Manager Heap (LOCKLIST*)
Current size (bytes) = 278528
High water mark (bytes) = 278528
Maximum size allowed (bytes) = 425984
Memory Pool Type = Database Heap (DBHEAP*)
Current size (bytes) = 3342336
High water mark (bytes) = 3342336
Maximum size allowed (bytes) = 6275072
Memory Pool Type = Database Monitor Heap (MON_HEAP_SZ)
Current size (bytes) = 180224
High water mark (bytes) = 425984
Maximum size allowed (bytes) = 442368
Memory Pool Type = Other Memory
Current size (bytes) = 8060928
High water mark (bytes) = 8159232
Maximum size allowed (bytes) = 1071644672
快照總是顯示 Current size (bytes) = High water mark (bytes),因為內存是在數據庫激活的時候分配的。
清單 9. 數據庫快照
Database Snapshot
Database name = SAMPLE
Database path = C:DB2NODE0000SQL00002
Input database alias = SAMPLE
Database status = Active
Catalog database partition number = 0
Catalog network node name =
Operating system running at database server= NT
Location of the database = Local
First database connect timestamp = 02-20-2004 06:19:00.847979
Last reset timestamp =
Last backup timestamp =
Snapshot timestamp = 02-20-2004 06:23:17.252491
High water mark for connections = 1 (MAXAPPLS)
Application connects = 1
Secondary connects total = 0
Applications connected currently = 1 (AVG_APPLS)
Appls. executing in db manager currently = 0
Agents associated with applications = 1
Maximum agents associated with applications= 1
Maximum coordinating agents = 1
Locks held currently = 0
Lock waits = 0
Time database waited on locks (ms) = 0
Lock list memory in 使用 (Bytes) = 1000 (LOCKLIST and MAXLOCKS)
Deadlocks detected = 0
Lock escalations = 0 (LOCKLIST and MAXLOCKS)
Exclusive lock escalations = 0 (LOCKLIST and MAXLOCKS)
Agents currently waiting on locks = 0
Lock Timeouts = 0 (LOCKTIMEOUT)
Number of indoubt transactions = 0
Total Private Sort heap allocated = 0 (SHEAPTHRES and SORTHEAP)
Total Shared Sort heap allocated = 0 (SHEAPTHRES_SHR and SORTHEAP)
Shared Sort heap high water mark = 0 (SHEAPTHRES_SHR and SORTHEAP)
Total sorts = 0
Total sort time (ms) = 0
Sort overflows = 0 (SORTHEAP)
Active sorts = 0
Buffer pool data logical reads = 370
Buffer pool data physical reads = 54
Buffer pool temporary data logical reads = 0
Buffer pool temporary data physical reads = 0
Asynchronous pool data page reads = 9 (NUM_iOSERVERS)
Buffer pool data writes = 3 (CHNGPGS_THRESH and NUM_IOCLEANERS)
Asynchronous pool data page writes = 0 (CHNGPGS_THRESH and NUM_IOCLEANERS)
Buffer pool index logical reads = 221
Buffer pool index physical reads = 94
Buffer pool temporary index logical reads = 0
Buffer pool temporary index physical reads = 0
Asynchronous pool index page reads = 0 (NUM_iOSERVERS)
Buffer pool index writes = 0 (CHNGPGS_THRESH and NUM_IOCLEANERS)
Asynchronous pool index page writes = 0 (CHNGPGS_THRESH and NUM_IOCLEANERS)
Total buffer pool read time (ms) = 287
Total buffer pool write time (ms) = 1
Total elapsed asynchronous read time = 0
Total elapsed asynchronous write time = 0
Asynchronous data read requests = 3
Asynchronous index read requests = 0
No victim buffers available = 0
LSN Gap cleaner triggers = 0
Dirty page steal cleaner triggers = 0 (CHNGPGS_THRESH)
Dirty page threshold cleaner triggers = 0 (CHNGPGS_THRESH)
Time waited for prefetch (ms) = 0 (NUM_iOSERVERS)
Unread prefetch pages = 0
Direct reads = 86
Direct writes = 4
Direct read requests = 14
Direct write requests = 2
Direct reads elapsed time (ms) = 247
Direct write elapsed time (ms) = 56
Database files closed = 0 (MAXFILOP)
Data pages copIEd to extended storage = 0
Index pages copIEd to extended storage = 0
Data pages copIEd from extended storage = 0
Index pages copIEd from extended storage = 0
Host execution elapsed time = 0.000039
Commit statements attempted = 6
Rollback statements attempted = 1
Dynamic statements attempted = 281
Static statements attempted = 7
Failed statement Operations = 1
Select SQL statements executed = 4
Update/Insert/Delete statements executed = 0
DDL statements executed = 2
Internal automatic rebinds = 0
Internal rows deleted = 0
Internal rows inserted = 0
Internal rows updated = 0
Internal commits = 1
Internal rollbacks = 0
Internal rollbacks due to deadlock = 0
Rows deleted = 0
Rows inserted = 0
Rows updated = 0
Rows selected = 336
Rows read = 375
Binds/precompiles attempted = 0
Log space available to the database (Bytes)= 5095757 (LOGPRIMARY and LOGSECOND)
Log space used by the database (Bytes) = 4243
Maximum secondary log space used (Bytes) = 0
Maximum total log space used (Bytes) = 6498 (LOGPRIMARY and LOGSECOND)
Secondary logs allocated currently = 0 (LOGPRIMARY and LOGSECOND)
Log pages read = 0 (LOGBUFSZ)
Log pages written = 5 (LOGBUFSZ)
Appl id holding the oldest transaction = 38
Package cache lookups = 10 (PKGCACHESZ)
Package cache inserts = 8 (PKGCACHESZ)
Package cache overflows = 0 (PKGCACHESZ)
Package cache high water mark (Bytes) = 191140 (PKGCACHESZ)
Application section lookups = 281
Application section inserts = 6
Catalog cache lookups = 18 (CATALOGCACHE_SZ)
Catalog cache inserts = 9 (CATALOGCACHE_SZ)
Catalog cache overflows = 0 (CATALOGCACHE_SZ)
Catalog cache high water mark = 0 (CATALOGCACHE_SZ)
Workspace Information
Shared high water mark = 0
Corresponding shared overflows = 0
Total shared section inserts = 0
Total shared section lookups = 0
Private high water mark = 21102
Corresponding private overflows = 0
Total private section inserts = 6
Total private section lookups = 6
Number of hash joins = 0
Number of hash loops = 0
Number of hash join overflows = 0 (SORTHEAP)
Number of small hash join overflows = 0 (SORTHEAP)
有時候,為了某些問題使用 "grep" (UNIX) 和 "findstr" (Windows) 對快照輸出執行初步的搜索非常方便。如果發現了什麼東西,就可以通過打開快照輸出並找到問題所在,以便作進一步調查。
例如,為了識別是否存在死鎖:
UNIX:
grep -n "Deadlocks detected" snap.out | grep -v "= 0" | more
Windows:
findstr /C:"Deadlocks detected" snap.out | findstr /V /C:"= 0"
SHEAPTHRES (DBM)
這是實例中所有數據庫的並發私有排序 所消耗的內存總量。另外傳入的排序只能得到更少量的可用內存。對於 OLTP,一開始最好是使用大約 20000,而對於 OLAP 40000-60000 會工作得更好一些。
當 "Piped sorts accepted"的值與 "Piped sorts requested" 比起來較低時,通過增加 SHEAPTHRES 的大小,常常可以提高性能。如果 "Post threshold sorts" (在 SHEAPTHRES 已經被超出之後,請求堆的排序) 的值較高(也就是有兩位數),應嘗試增加 SHEAPTHRES 的大小。 "Total Private Sort heap allocated"應該小於 SHEAPTHRES。如果不是這樣,則應增加 SHEAPTHRES。
MAXAGENTS (DBM)
這是可用於接受對實例中所有數據庫的應用程序請求的數據庫管理器代理的最多數量。在受限內存(memory constrained)的環境中,這個參數對於限制數據庫管理器的總內存使用量很有用,因為每個附加的代理都需要附加的內存。
如果機器是受限內存的,那麼可以增加 MAXAGENTS,直到 "Agents stolen from another application"為 0。此外, "Local connections"+ "Remote connections to db manager"將指出連接到實例上的並發連接的數量。 "High water mark for agents registered"將報告在某一次連接到數據庫管理器的代理曾出現的最大數量。 "Max agents overflow"報告當已經達到 MAXAGENTS 時,所收到的創建一個新代理的請求的次數。最後, "Agents Registered"顯示在被監控的數據庫管理器實例中當前注冊的代理的數量。
NUMDB (DBM)
指定可以同時激活的本地數據庫的數量。在生產系統中,建議每個實例有一個數據庫,因此應該將這個值設為 1。否則,將其設為同時激活的數據庫的最大數量。如果不確定的話,使用 "Active local databases"。
NUM_INITAGENTS 和 NUM_POOLAGENTS (DBM)
NUM_INITAGENTS 指定在 db2start 上的池中創建的空閒代理的數量,它可以幫助加快在開始使用數據庫時的連接。NUM_POOLAGENTS 也是相關的,但是如果數據庫已經運行了一段時間,那麼它對性能會有更大的影響。當 Connections Concentrator 為 OFF(缺省值;MAX_CONNECTIONS = MAX_COORDAGENTS)時,NUM_POOLAGENTS 指定代理池的最大大小。當 Concentrator 為 ON (MAXCONNECTIONS > MAX_COORDAGENTS)時,可以參考這個值來決定在系統工作負載較低時代理池應該有多大。
NUM_INITAGENTS 和 NUM_POOLAGENTS 應該設為預期的並發實例級連接的平均數量,對於 OLAP 這個值通常比較低,而對於 OLTP 就要高一些。對於存在大量 ramp up 連接情況下的性能基准,將 NUM_INITAGENTS 設置成預期的連接數量(這將減少資源爭用,從而顯著地減少 ramp up 連接所需的時間)。在使用了連接池的 3 層環境中,NUM_INITAGENTS 和 NUM_POOLAGENTS 對性能的影響很小,因為即使在應用程序空閒的時候,應用服務器也會連續不斷地維護連接。
"Idle agents"顯示了在代理池中空閒代理的數量,而 "Agents assigned from pool"則顯示從代理池中將一個代理分配出去的次數。 "Agents created from empty pool"顯示在空池情況下必須創建的代理的數量,這可能會讓人誤解為剛好在 db2start 之後。而在 db2start 之後,它只是顯示被創建的代理的數量。如果 "Agents created from empty pool"/ "Agents assigned from pool"的比例比較高(5:1 或更大),則可能表明應該增加 NUM_POOLAGENTS。這也可能表明系統的總體工作負載太高。這時可以通過降低 MAXCAGENTS 來調整工作負載。如果這個比例較低,則暗示著 NUM_POOLAGENTS 可能被設得太高,有些代理就會浪費系統資源。
FCM_NUM_BUFFERS (DBM)
只在有多個邏輯分區的 DPF 環境中使用。它指定用於內部通信的大小為 4 KB 的緩沖區的數量。如果沒有使用 DPF,那麼這個值甚至不會出現在快照輸出中。此外,該信息將來自其上運行了快照的分區。例如,在 DBM 快照之前的那個快照中, "Node FCM information corresponds to"顯示了一個值 2,因此它是從 2 號分區那裡得來的。"Get snapshot for dbm global" 可用於獲得所有分區值的群集。
DBM 快照的 FCM Node 部分可用於查看主要的分區間通信發生的地點,以用於調查的目的。如果通信量很大,則表明需要更多的 FCM 緩沖區內存,需要不同的分區鍵,或者需要不同的表來分派表空間。如果 "Free FCM buffers low water mark"小於 FCM_NUM_BUFFERS 的百分之 15,那麼可以增加 FCM_NUM_BUFFERS,直到 "Free FCM buffers low water mark"大於或等於 FCM_NUM_BUFFERS 的百分之 15,以確保總有足夠的 FCM 資源可供使用。
AVG_APPLS (DB)
只有在應用程序發出復雜的 SQL(例如連接、函數、遞歸等等)時才更改它,否則讓它一直為 1。這可以幫助估計在運行時可以為一個訪問計劃提供多少的緩沖池。它應該設為一個較低的值,即 "Applications connected currently"的平均數量乘以復雜 SQL 的百分比。
LOCKLIST 和 MAXLOCKS (DB)
對於每個數據庫都有一個鎖列表,該列表包含所有同時連接到數據庫的應用程序所持有的鎖。在 32 位的平台上,一個對象上的第一個鎖要求占 72 字節,而其他的鎖要求占 36 字節。在 64 位平台上,第一個鎖要求占 112 字節,而其他鎖要求占 56 字節。
當一個應用程序使用的 LOCKLIST 的百分比達到 MAXLOCKS 時,數據庫管理器將執行一次鎖升級(lock escalation),在這個操作中將使得行鎖換成單獨的一個表鎖。而且,如果 LOCKLIST 快要耗盡,數據庫管理器將找出持有一個表上的最多行鎖的連接,並將這些行鎖換成表鎖,以釋放 LOCKLIST 內存。鎖整個表可以大大減少並發性,死鎖的幾率也增加了。
如果 "Lock list memory in 使用 (Bytes)"超出了定義的 LOCKLIST 大小的 50%,那麼應增加 LOCKLIST 4 KB 大小的頁面的數量。如果發生了 "Lock escalations"或 鈥淓xclusive lock escalations鈥_,則應該或者增加 LOCKLIST,或者增加 MAXLOCKS,抑或同時增加兩者。
關於鎖的數據庫快照部分包含大量有價值的信息。看看 "Locks held currently"、 "Lock waits"、 "Time database waited on locks (ms)"、 "Agents currently waiting on locks"和 "Deadlocks detected"中是否存在高值,如果有的話,就可能是差於最優訪問計劃、事務時間較長或者應用程序並發問題的症狀。如果要發現死鎖,那麼需要創建一個針對死鎖的事件監視器,事件監視器帶有詳細信息,以便查看當前正在發生的事情。
要了解關於鎖問題的詳細信息,請參閱 Bill Wilkins 撰寫的文章 Diagnosing and Resolving Lock Problems with DB2 Universal Database。
您可以做下列事情來減少鎖:
確保應用程序正在使用最低的隔離級別。
經常執行 COMMIT。
當執行很多更新時,在更新前顯式地鎖整個表(使用 LOCK TABLE 語句)。
盡量使用 Cursor Stability 隔離級別(缺省情況),以便減少被持有的共享鎖的數量。(如果應用程序能夠承受髒讀,那麼 Uncommitted Read 可以進一步減少鎖。)
LOCKTIMEOUT (DB)
指定應用程序在獲得一個鎖之前所等待的秒數。這可以幫助避免全局死鎖的情況。如果該值為 -1,如果出現鎖等待,則應用程序將會出現。Bill Wilkins 關於鎖的文章 也以較大的篇幅包含了這一點。
對於生產系統中的 OLAP,一開始為 60 (秒)比較好,對於 OLTP 大約為 10 秒比較好。對於開發環境,應該使用 -1,以識別和解決鎖等待的情況。如果有大量的並發用戶,可能需要增加 OLTP 時間,以避免回滾。
如果 "Lock Timeouts"是一個較高的數,那麼可能由以下原因造成:(1) LOCKTIMEOUT 的值太低,(2) 某個事務持有鎖的時間有所延長,或者(3) 鎖升級。
SHEAPTHRES_SHR (DBM)
這是對一個實例中並發共享的排序可以消耗的內存總量的硬性限制。這個值只有在以下情況下才適用:(1) INTRA_PARALLEL=YES,或者 (2) Concentrator 在 (MAX_CONNECTIONS > MAX_COORDAGENTS) 范圍內。對於在 WITH HOLD 選項下使用游標的 排序,將從共享內存中為其分配內存。
"Shared Sort heap high water mark"顯示一次最多可以分配的共享排序 內存。如果這個值總是遠遠低於 SHEAPTHRES_SHR,那麼應該減少 SHEAPTHRES_SHR,以便為其他數據庫函數節省內存。如果這個值剛好接近於 SHEAPTHRES_SHR,那麼可能需要增加 SHEAPTHRES_SHR。 "Total Shared Sort heap all
-