SORTHEAP (DB)
這個參數指定為私有排序 使用的最大私有內存頁數,或者指定為共享排序使用的最大共享內存頁數。每個排序都有一個獨立的排序堆,這是由數據庫管理器在需要的時候分配的。
通常大家都理解得很好的是,當一個排序所需的內存量超過了 SORTHEAP 時,就會發生 排序溢出。然而理解得不夠好的一點是,如果統計信息已過時,或者數據有偏差,並且沒有收集到發布統計信息,這時一旦 DB2 請求一個太小的堆,而實際的排序操作超出了所請求的量,就會發生溢出。因此,使統計信息保持時新十分重要。此外,應確保排序 不是一個丟失的索引的結果。
對於 OLTP,一開始最好是設為 128,對於 OLAP,則設置在 4096 - 8192 之間。如果有很多的 "Sort overflows" (兩位數)那麼很可能需要增加 SORTHEAP。如果 "Number of hash join overflows" 不為 0,則按照 256 逐次增加 SORTHEAP,直到它為 0。如果 "Number of small hash join overflows" 不為 0,則按 10% 的速度增加 SORTHEAP,直到小散列連接溢出數為 0。
CHNGPGS_THRESH (DB)
使用這個參數來指定緩沖池中被更改頁面所占的百分比,此時將啟動異步的頁面清除器將更改寫入到磁盤,以便在緩沖池中為新的數據空出空間。在只讀環境下,不使用頁面清除器。在 OLTP 中,使用 20-40 這樣的一個值應該可以提高性能(在更新活動龐大的情況下使用 20),因為使這個值更低一些將使 I/O Cleaners 在從髒緩沖池頁面寫出數據時更具有侵略性,但是每次做的工作卻變少了。如果沒有很多的 INSERT 或 UPDATE,則對於 OLTP 和 OLAP 來說,缺省的 60 應該就比較好了。
如果 "Dirty page steal cleaner triggers"是一個兩位數,則試著降低之。如果 "Buffer pool data writes"較高,而 "Asynchronous pool data page writes"較低,則試著降低這個參數。
從 FixPak 4 起,有另一種頁面清除算法,這種算法可以提高特定緩沖池的性能。您需要令概要注冊表變量 DB2_USER_ALTERNATE_PAGE_CLEANING=YES,這樣忽略 CHNGPGS_THRESH。確保 NUM_iOSERVERS 至少為 3,否則它會拖新算法的後腿。
NUM_IOCLEANERS (DB)
這個參數指定一個數據庫的異步頁面清除器的數量,異步頁面清除器將更改後的頁面從緩沖池寫到磁盤。一開始將這個參數設為等於系統中 CPU 的數量。當觸發了 I/O Cleaners 時,它們會同時啟動,因此您不希望有那麼多的清除器,以致影響性能和阻塞其他處理過程。
如果 Asynchronous Write Percentage (AWP) 是 90% 或更高,則減少 NUM_IOCLEANERS,如果 Asynchronous Write Percentage (AWP) 小於 90%,則增加 NUM_IOCLEANERS。
AWP = (( "Asynchronous pool data page writes"+ "Asynchronous pool index page writes") * 100) / ( "Buffer pool data writes"+ "Buffer pool index writes")
NUM_iOSERVERS (DB)
I/O 服務器用於執行預取操作,而此參數則指定一個數據庫的 I/O 服務器的最多數量。非預取 I/O 是從數據庫代理調度的,因此不受此參數的約束。一開始將該參數設置為等於數據庫所跨的物理磁盤數(即使是一個磁盤陣列中的許多磁盤或者一個邏輯卷中的許多磁盤) + 1 或 2,但是不大於 CPU 的 # 的 4-6 倍。
如果您很快看到 "Time waited for prefetch (ms)",那麼您或許想添加一個 IO Server,以查看性能是否有提高。
MAXFILOP (DB)
這個參數指定每個數據庫代理所能打開的最大文件數。如果打開一個文件時被打開的文件數超出了這個值,則要關閉該代理正在使用的一些文件。過度的打開和關閉都會降低性能。SMS 表空間和 DMS 表空間文件容器都是視作文件來對待的。通常 SMS 使用的文件要更多一些。
增加該參數的值,直到 "Database files closed"為 0。
LOGPRIMARY、LOGSECOND 和 LOGFILSZ (DB)
LOGPRIMARY 指定要預先分配空間的主日志文件的數量,而 LOGSECOND 是按照需要來分配空間的。LOGFILSIZ 定義每個日志文件的大小。
如果 "Secondary logs allocated currently"的值很大,那麼就可能需要增加 LOGFILSIZ 或 LOGPRIMARY (但是要確保 LOGPRIMARY + LOGSECOND 不超過 256)。還可以使用 "Maximum total log space used (Bytes)"來幫助指出對日志文件空間(主日志 + 從日志)的依賴性。
日志文件的大小對災難恢復有一定的影響,因為在災難恢復中要使用日志發送(log shipping)。日志文件比較大時,性能會更好些,但是可能潛在地增加丟失事務的程度。當主系統崩潰時,最近的日志文件及其事務可能無法發送到從系統,因為在失敗之前沒有關閉該文件。日志文件越大,隨著日志文件的丟失,丟失事務的程度也越大。
LOGBUFSZ (DB)
這個參數允許指定用作在將日志記錄寫到磁盤之前的緩沖區的數據庫堆(DBHEAP)的數量。當提交一個事務或者日志緩沖區已滿的時候,就要將日志記錄寫入磁盤。對日志記錄進行緩沖將導致將日志記錄寫入磁盤的活動不那麼頻繁,但每次要寫的日志記錄會更多。對於 OLTP,一開始以至少 256 頁為佳,對於 OLAP,則以 128 頁為佳。如果常常看到多於一對的 "Log pages read",那麼可能需要增加這個值。如果發生了回滾,也可能要讀取日志頁。
如果在試圖增加 LOGBUFSZ 時收到一個錯誤,那麼可以按相同數量增加 DBHEAP,然後再次嘗試。
PKGCACHESZ (DB)
這個包緩存用作靜態和動態 SQL 語句的緩存部分。緩沖包允許數據庫管理器減少內部開銷,因為它消除了在重新裝載一個包時訪問系統編目的需要;或者,對於動態 SQL,消除了重新編譯的需要。
PKGCACHESZ 應該大於 "Package cache high water mark (Bytes)"。如果 "Package cache overflows"不為 0,那麼可以嘗試通過增加 PKGCACHESZ 來使這個計數器變為 0。
Package Cache Hit Ratio (PCHR) 應該盡可能接近 100%(而不從緩沖池中獲取所需的內存)。用下面的公式來計算:
PCHR = (1-( "Package cache inserts"/ "Package cache lookups"))*100
CATALOGCACHE_SZ (DB)
這個參數用於緩存系統編目信息,例如 SYSTABLE、授權和 SYSROUTINES 信息。緩存編目信息十分重要,尤其是在使用 DPF 的情況下更是如此,因為不必為獲得先前已經檢索過的信息而訪問系統編目(編目分區),從而減少了內部開銷。
不斷增加該值,直到對於 OLTP 的 Catalog Cache Hit Ratio (CCHR) 達到 95% 或更好的值:
CCHR = (1-( "Catalog cache inserts"/ "Catalog cache lookups"))*100
如果 "Catalog cache overflows"的值大於 0,也要增加該參數的值。還可以使用 "Catalog cache high water mark (Bytes)"來確定編目緩存曾消耗過的最多內存。如果 High water mark 等於允許的 Maximum 大小,那麼就需要增加編目緩存堆的大小。
實驗: DBM 和 DB 配置
下面的參數可能帶來額外的性能。然而,快照中的特定監視器並不是直接報告出它們的影響。相反,可能需要一次更改一個參數,然後測量應用程序的總體性能。最好的測量方法是從幾個快照中檢查更改前後 SQL 的執行次數。
INTRA_PARALLEL (DBM)
該參數指定數據庫管理器是否可以使用內部分區並行性(intra-partition parallelism)。缺省值 NO 對於並發連接較多的情況(主要是 OLTP)最好,而 YES 對於並發連接較少的情況以及復雜 SQL (OLAP/DSS)來說最好。混合的工作負載通常可以得益於 NO。
當啟用該參數時,就會導致從共享內存中分配排序內存。此外,如果並發程度顯著增加的話,還可能導致過多的系統開銷。如果系統是非 OLTP 的,則 CPU 數對分區數的比例是 4:1,而 CPU 負載運行的平均百分比是 50%,INTRA_PARALLEL 很可能會提高性能。
DFT_QUERYOPT (DB)
用於指定在編譯 SQL 查詢時所使用的缺省優化級別。對於混合的 OLTP/OLAP,使用 5 或 3 作為缺省值,對於 OLTP,使用一個更低的級別,而對於 OLAP,則使用一個更高的級別。對於簡單的 SELECTS 或短的運行時查詢(通常只需花不到 1 秒鐘就可以完成),使用 1 或 0 也許比較合適。如果有很多的表,有很多相同列上的連接謂詞,那麼嘗試級別 1 或 2。對於超過 30 秒鐘才能完成的長時間運行的查詢,或者如果要插入一個 UNION ALL VIEW(這是在 FixPak4 中加進來的),那麼可以嘗試使用級別 7。在大多數環境下都應該避免使用級別 9。
UTIL_HEAP_SZ (DB)
該參數指定 BACKUP、RESTORE 和 LOAD 實用程序可以同時使用的最大內存數。如果正在使用 LOAD,那麼對於每個 CPU 將 UTIL_HEAP_SZ 設置成至少 10000 頁。
NEWLOGPATH (DB)
該參數指定最長 242 個字節的一個字符串,用於更改日志文件寫和存儲的位置。這可以指向一個全限定路徑名,或者指向元設備。將日志路徑更改到一個獨立的本地高速磁盤(只用於日志記錄)可以顯著地提高性能。
進一步的 SQL 分析
Design Advisor
如果有一個針對特定問題的查詢或者一組查詢,那麼可以將該工作負載輸入到 DB2 Design Advisor (db2advis) 中,由它去推薦一組有效的索引。如果不知道 SQL,也可以
使用快照捕獲動態 SQL。
用一個語句事件監視器收集在一段時間內發出的所有 SQL。
從 SYSCAT.STATEMENTS 編目視圖中提取靜態 SQL。
語句事件監視器的使用將在本節稍後一點討論。
可以從 DB2 Control Center 使用 Design Advisor,或者從 CLP 命令行使用該工具。下面討論這兩種界面。
使用 DB2 Control Center
在 Control Center 中,展開對象樹,直到發現感興趣的數據庫。右鍵單擊數據庫名,並從彈出菜單中選擇 Design Advisor'。現在您就可以通過查看最近執行的 SQL,檢查包,或者手動地添加 SQL 語句來構造工作負載了。
使用 DB2 CLP
當使用 CLP 時,輸出被顯示到屏幕,這可以捕捉到一個腳本中並執行。下面是一些常見的例子。
要為一個特定的針對 'example' 數據庫的 SQL 語句推薦索引,並且要在 1 分鐘內標識出索引:
db2advis -d sample -s "select count(*) from sales where region = 'Quebec'" -t 1
要為多條語句推薦索引,我們可以構建一個文本文件,該文件看上去是這樣的:
db2advis -d sample -s "--#SET FREQUENCY 10
SELECT * FROM SALES;
--#SET FREQUENCY 2
SELECT FIRSTNME FROM EMPLOYEE WHERE EMPNO = ?;
其中 frequency 是該 SQL 語句與輸入文件中其他 SQL 語句相比其執行次數所占的比重。生成結果:
db2advis -d dbname -i sqlstmts_file > recindexes.out
由於輸出顯示到了屏幕上,我們使用一個重定向將索引定義捕捉到一個文件中,然後該文件就可以作為一個 DB2 腳本來運行了。
您還可以通過管道將動態 SQL 從一個快照發送到 Design Advisor 中:
get snapshot for dynamic SQL on dbname write to file
這樣將以一種內部文件格式保存快照。然後就可以用下列語句將結果插入到一個 Design Advisor 表中:
insert into advise_workload(select 'myworkload',0,stmt_text,cast(generate_unique() as char(254)), num_executions, 1,1,0,0,cast(null as char) from table (snapshot_dyn_sql(' dbname', -1)) as snapshot_dyn_sql)
在一個工作負載中,每條 SQL 語句的缺省 frequency 是 1,缺省的 importance 也是 1。generate_unique() 函數將一個惟一的標識符指定給語句。用於可以將這兩列更新為更有意義的值。要生成索引:
db2advis -d dbname -w myworkload
一旦執行了 Design Advisor,它就會填充 advise_index 表。您可以通過下面的查詢來查詢這個表,以列出 Design Advisor 的所有建議:
SELECT CAST(CREATION_TEXT as CHAR(200)) FROM ADVISE_INDEX
對 SQL 的事件監視
CREATE EVENT MONITOR 語句定義一個監視器,在使用數據庫的時候,該監視器將記錄所發生的某些事件。每個事件監視器的定義還會指定數據庫應該將事件記錄在哪裡。我們可以創建事件監視器來記錄跟下列類型的事件有關的信息:DATABASE、TABLES、DEADLOCKS [WITH DETAILS]、TABLESPACES、BUFFERPOOLS、CONNECTIONS STATEMENTS 和 TRANSACTIONS。
清單 10和 清單 11展示了可用於收集事件監視器輸出的腳本:
清單 10. getevmon.ksh (UNIX)
#!/usr/bin/ksh
# create an event monitor and capture its output
# parameters: (1) database name
# (2) monitor output file
# (3) interval between iterations (seconds)
# Note: You may receive an error about the monitor heap being too small. You may want to set
# mon_heap_sz to 2048 while monitoring.
if [ $# -ne 3 ]
then echo "Requires 3 Parameters: dbname monitor_output_file interval_in_#seconds"; exit
fi
MON=evmon
# "nonblocked" may cause loss of data but has less impact on system than default "blocked".
MONTYPE=nonblocked
SLEEP=$3
DB=$1
#EVENTS="deadlocks with details"
#EVENTS="tables, statements, deadlocks with details, connections"
EVENTS="statements"
OUTFILE=$2
OUTDIR="TMPEVMON"
mkdir $OUTDIR
chmod 777 $OUTDIR
cd $OUTDIR
db2 connect to $DB
db2 -v drop event monitor $MON
db2 -v create event monitor $MON for $EVENTS
write to file "'`pwd`'" buffersize 64 $MONTYPE
db2 -v set event monitor $MON state = 1
echo ""
echo "Event Monitor active at `date`; sleeping for $SLEEP seconds before turning it off."
sleep $SLEEP
db2 -v set event monitor $MON state = 0
cd ..
db2evmon -db $DB -evm $MON > $OUTFILE
db2 -v drop event monitor $MON
db2 terminate
rm -fr $OUTDIR
echo
echo db2evmon output is in $OUTFILE
清單 11. getevmon.bat (Windows)
@echo off
REM create an event monitor and capture its output
REM parameters: (1) database name
REM (2) monitor output file
REM (3) interval to monitor for (seconds)
REM Note: You may receive an error about the monitor heap being too small. You may want to set
REM mon_heap_sz to 2048 while monitoring.
:CHECKINPUT
IF ""=="%3" GOTO INPUTERROR
GOTO STARTPRG
:INPUTERROR
echo %0 requires 3 parameters: dbname filename sleep_interval
echo e.g. "%0 sample evmon0302.out 60"
GOTO END
:STARTPRG
SET dbname=%1
SET outfile=%2
SET sleep_interval=%3
SET MON=evmon
REM "nonblocked" may cause loss of data but has less impact on system than default "blocked".
SET MONTYPE=nonblocked
REM SET EVENTS="deadlocks with details"
REM SET EVENTS="tables, statements, deadlocks with details, connections"
SET EVENTS="statements"
SET OUTDIR="c: empevmon"
mkdir %OUTDIR%
db2 connect to %dbname%
db2 -v drop event monitor %MON%
db2 -v create event monitor %MON% for %EVENTS% write to file '%OUTDIR%' buffersize 64 %MONTYPE%
db2 -v set event monitor %MON% state = 1
echo Sleeping for %sleep_interval% seconds before turning off.
sleep %sleep_interval%
db2 -v set event monitor %MON% state = 0
db2evmon -db %dbname% -evm %MON% > %OUTFILE%
db2 -v drop event monitor %MON%
db2 terminate
rmdir /s /q %OUTDIR%
echo db2evmon output is in %OUTFILE%
:END
輸出將包含所有動態 SQL 語句的文本。不過,對於靜態 SQL 語句,輸出將列出包名和節號。具有包名和節號的 db2expln 可用來提取語句文本,或者也可以查詢 syscat.statements 視圖來提取文本。
清單 12展示了在語句事件監視器的輸出中捕獲到的一個事件:
清單 12. 示例語句事件監視器輸出
42) Statement Event ...
Appl Handle: 16
Appl Id: *LOCAL.DB2.010746204025
Appl Seq number: 0003
Record is the result of a flush: FALSE
-------------------------------------------
Type : Dynamic
Operation: Close
Section : 201
Creator : NULLID
Package : SQLC2E03
Consistency Token : AAAAAJHR
Package Version ID :
Cursor : SQLCUR201
Cursor was blocking: TRUE
Text : select * from staff
-------------------------------------------
Start Time: 10-06-2003 17:27:38.800490
Stop Time: 10-06-2003 17:27:38.806619
Exec Time: 0.006129 seconds
Number of Agents created: 1
user CPU: Not Available
System CPU: Not Available
Fetch Count: 35
Sorts: 0
Total sort time: 0
Sort overflows: 0
Rows read: 35
Rows written: 0
Internal rows deleted: 0
Internal rows updated: 0
Internal rows inserted: 0
SQLCA:
sqlcode: 0
sqlstate: 00000
由於可能存在數千個語句事件,找出問題的最容易的方法是使用 grep (UNIX) 或 findstr (Windows)。下面是在輸出中用於搜索的一些有用的字符串:
" sqlcode: -"
這對於發現錯誤很有用,例如發現 -911 RC 2,即死鎖,又例如 RC 68,即鎖超時。
grep -n " sqlcode: -" stmtevmon_output findstr /C:" sqlcode: -" stmtevmon_output
" Rows read: "
這標識了一條語句讀取的行數(沒有將索引項或直接表讀計算在內)。如果這個數字很大,則意味著需要一個索引,或者統計信息已過時。
grep -n " Rows read: " stmtevmon_output | grep -v ": 0" | sort -k 4,4rn | more findstr /C:" Rows read: " stmtevmon_output | findstr /V /C:" Rows read: 0" | sort
" Exec Time: "
這是語句的實際執行時間,包括鎖等待的時間。有時候,可以方便地從事件監視器數據的最後開始,向前搜索 "Exec Time",並查看一條開銷較大的 SQL 語句是否存在某種模式或存在重復。然後可以用 EXPLAIN 檢查 SQL 語句,看看是什麼問題。
grep -n " Exec Time: " stmtevmon_output | grep -v ": 0.0" | sort -k 4,4rn | more findstr /C:" Exec Time: " stmtevmon_output | findstr /V /C:" Exec Time: 0.0" |sort
" Sort overflows:"
顯示開銷很大的 排序溢出發生在哪裡。這可能表明需要使用索引、運行 RUNSTATS 或加大 SORTHEAP。
grep -n " Sort overflows:" stmtevmon_output | grep -v ": 0" | sort -k 4,4rn | more findstr /C:" Sort overflows: " stmtevmon_output |findstr /V /C:" Sortoverflows: 0"|sort
" Fetch Count:"
對於查看對結果集執行了多少 fetch 操作很有用。這裡並不是記錄每個 FETCH 操作。DB2 通過加大該字段,在語句級上跟蹤這些 FETCH 操作。可以用 FETCH FIRST 子句限制 FETCH 操作。
grep -n " Fetch Count:" stmtevmon_output | grep -v ": 0" | sort -k 4,4rn | more findstr /C:" Fetch Count: " stmtevmon_output | findstr /V /C:" Fetch Count: 0" | sort
標識了想要進一步觀察的一些元素之後,打開語句事件監視器的輸出,並按您感興趣的字符串進行搜索。一旦定位到語句,下面的一些字段將很有用:
" Operation: "
該字段可以提供一般語句流。它標識 Prepare、Open、Fetch、Close、Commit 等等。
" Text : "
這是用於動態 SQL 的語句文本。對於靜態 SQL,查找 "Section :"和 "Package :"。
" Start Time: " 或 " Stop Time: " 或 " Time: "
這可以幫助標識起始時間、終止時間或者同時標識這兩個時間。Stop time 和隨後的 Start time 還可以說明語句之間的間歇時間有多長,如果您懷疑 DB2 在其他某個地方花費了時間(可能是存儲過程開銷),那麼這一點就比較有用。
對訪問計劃的解釋
SQL 解釋工具是 SQL Compiler 的一部分,用於顯示一條語句的訪問計劃,以及編譯該語句時所在的環境。Explain 信息可以以很多方式來捕捉和顯示。
這種信息可以幫助您:
理解為一個查詢選擇的執行計劃。
輔助設計應用程序的程序。
確定應何時重新捆綁應用程序。
輔助數據庫設計。
在獲得一條 SQL 語句的解釋數據之前,必須使用跟調用 explain 工具的授權 ID 相同的模式定義一組 explain 表。請查看 DB2 安裝目錄下的 'qllib/misc/explain.ddl' 或 'qllibmiscexplain.ddl',以找到 Explain Tables 的 DDL。
要清除 explain 表,發出:
delete from schema.explain_instance
這樣所有其他的 explain 表也將被清除,這是由於參照完整性連鎖刪除功能造成的。
當分析 explain 輸出時,應識別是否出現下列情況:
對相同的一組列和基本表使用的 ORDER BY、GROUP BY 或 DISTINCT 操作符將從索引或物化查詢表(MQT)中受益,因為消除了排序。
代價較高的操作,例如大型排序、排序溢出以及對表的大量使用,都可以受益於更多的排序空間、更好的索引、更新的統計信息或不同的 SQL 。
表掃描也可以從索引中受益。
完全索引掃描或無選擇性的索引掃描,其中不使用 start 和 stop 關鍵字,或者使用這兩個關鍵字,但是有一個很寬的取值范圍。
Visual Explain
Visual Explain 使用起來非常簡單和直觀。它可以解釋包含參數標記(記為 "?")的語句,但是如果要與其他共享結果可能就比較困難,因為它是基於 GUI 的。在 Control Center 中,右鍵單擊想要為其解釋一條 SQL 語句的數據庫,並選擇 "Explain SQL'。您可以在 SQL 文本框中輸入 SQL 語句,然後單擊 "OK" 來生成圖。 圖 2展示了這種圖的一個例子看上去的樣子:
圖 2. Visual Explain Results 屏幕
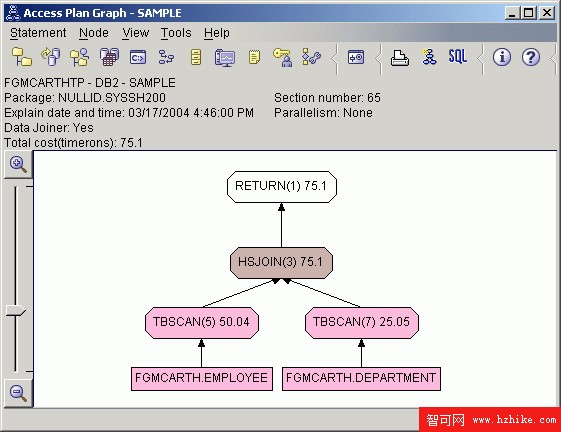
您可以通過雙擊任何節點來獲得更詳細的分析結果。
基於文本的 Explain
db2exfmt 和 db2expln 的 text-based 選項不易於讀(一開始),但是與他人共享起來就容易多了,因為您可以簡單地向他們發送輸出文件。
通用,在捕捉新數據之前清除 explain 表是一個好習慣。發出:
delete from schema.explain_instance
最後所有其他 explain 表都將被清除,這是由於參照完整性的連鎖刪除功能造成的。
所有 explain 輸出(包括 Visual Explain)都是從下往上讀的。
圖 3. Text Explain 屏幕
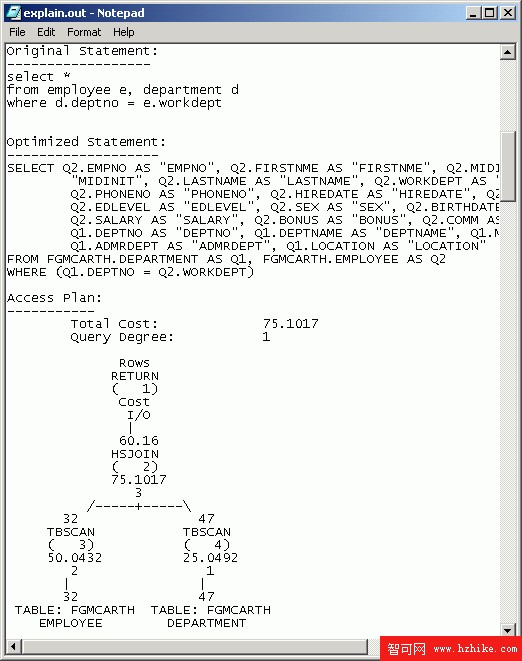
這裡不像 Visual Explain 那樣將所有細節顯示在不止一個屏幕上,而是將所有細節列在一個輸出文件中。在上圖中每個操作符都編了號,當您往下處理該文檔時,每個操作符都將被詳細解釋。例如,圖中的一個操作符可以作如下解釋:
清單 13. 讀 Text Explain 操作符
5.7904 - # of rows returned (based on statistics calculation)
HSJOIN - type of Operator
( 2) - Operator #
75.536 - cumulative timerons
3 - I/O costs
返回的行數、timeron (cost) 數和 I/O 都是優化器估計的,在某些情況下可能與實際數字不符。timeron 是 DB2 的度量單元,用於給出對數據庫服務器在執行同一查詢的兩種計劃時所需的資源或成本的粗略估計。估計時計算的資源包括處理器和 I/O 的加權成本。
您可以使用 db2exfmt 來解釋單獨一條語句。例如,
清單 14. 為一條語句生成 Text Explain 輸出
explain all for
SQL_statement
db2exfmt -d
dbname -g tic -e
explaintableschema -n % -s % -w -1 -# 0 -o
outfile
如果為用 ";" 隔開的幾條 "explain all' 語句構建一個文本文件,就可以一次解釋多條語句:
清單 15. 為多條語句生成 Text Explain 輸出
db2 -tf
file_with_statements
db2exfmt -d
dbname -g tic -e
explaintableschema -n % -s % -w % -# 0 -o
outfile
最後,如果想解釋一個包中包含的靜態 SQL,那麼您將需要使用 db2expln 工具:
db2expln -database dbname -schema schema_name -package package -output outfile.txt
DB2 v8 Documentation:
Concepts ==> Administration ==> Performance tuning ==> SQL explain facility
Tutorials ==> Tutorials (Visual Explain Tutorial)
SQL 語句調優
下面的這些技術可以用來從語句執行中擠出額外的性能:
使用 SELECT ... FOR UPDATE保護在隨後的 UPDATE 語句中可能被更新的那些行。這樣一來,選中的所有行上安置了一個更新(U)鎖。
使用 SELECT ' FOR READ ONLY(或 FETCH ONLY)表明結果表是只讀的。這意味著不能在隨後放置的 UPDATE 或 DELETE 語句中引用游標。這可以幫助提高 FETCH 操作的性能,因為它允許 DB2 執行塊操作(對於一個給定的 FETCH 請求返回多行給客戶)。
用 SELECT ' OPTIMIZE FOR n ROWS優化返回時間。這樣可以使優化器快速地返回 N 行,而不是像缺省行為那樣,最小化整個回答集的代價。此外,如果使用 READ ONLY 子句,這將影響在每個塊中返回的行數(一個塊中的行數不會大於 n)。這不會限制可以取的行數,但是如果要取多於 n 行的記錄,就可能降低性能。為了使該子句對數據緩沖區有一定的影響, n * row size 的值不能超出通信緩沖區的大小(由 DBM CFG RQRIOBLK 或 ASLHEAPSZ 定義)。
可以用 SELECT ' FETCH FIRST n ROWS來限制查詢結果集的大小。
大規模的 DELETE/Purging 可以通過 altER TABLE ' ACTIVATE NOT LOGGED INITIALLY WITH EMPTY TABLE來實現。由於該操作沒有日志記錄,如果哪個地方出了錯,就不得不將表刪除。一種更安全的方法是使用 Import 實用程序(帶上 Replace 選項)和一個空文件。
要減少鎖等待或死鎖出現的幾率,可以頻繁地使用 commit來釋放鎖。
確保讓重復的語句使用 參數標記。對於 OLTP,編譯時間是比較可觀的,因此用參數標記替換文字可以避免重復編譯。當使用參數標記時,優化器假設值是均勻分布的,因此如果數據比較偏,則意味著所選擇的訪問計劃不好。通常,正是 OLAP 這種類型的環境深受值的平均分布這一假設的毒害。
為了擁有更好的粒度,更好的性能和並發性,應在語句級指定 隔離級別。DB2 支持 Uncommitted Read、Cursor Stability、Read Stability 和 Repeatable Read (UR、CS、RS 和 RR)。例如,SELECT * FROM STAFF WITH UR 將使用 Uncommitted Read (最小鎖)執行 SELECT 語句。
DB2 v8 Documentation:
Reference ==> SQL ==> Queries and subquerIEs ==> select-statement
在有偏差數據的情況下使用參數標記時,指定選擇性
如果數據不是均勻分布的,那麼指定選擇性就十分有用。 SELECTIVITY指任何一行滿足謂詞(即為真)的概率。采用具有高度選擇性的謂詞是可取的。這種謂詞將為以後的操作符返回更少的行,從而減少了為滿足查詢所需的 CPU 和 I/O。
例如,對一個有 1,000,000 行的表執行一個選擇性為 0.01 (1%) 的謂詞操作,則意味著大約只有 10,000 行滿足條件,而另外的 990,000 都不滿足條件。
如果不是僅僅使用均勻分布的假設,而是人為地使用一個較低的選擇性的值(例如 0.000001)來“保證”使用那一列上的索引,那麼就可以影響優化器。如果預料到一個表要增長,並且希望確保能夠堅持使用某些特定列上的索引,那麼這一點就十分有用。如果想阻止 DB2 在某一特定列上使用索引,那麼可以將 SELECTIVITY 設為 1。
有了這種技術,使用優化級別 5 (例如 DFT_QUERYOPT=5)就最具有可預測性。而且,首先必須設置注冊表變量 DB2_SELECTIVITY=YES,然後,在使用 SELECTIVITY 子句之前重新啟動實例。
您可以為下列謂詞指定 SELECTIVITY 子句 :
基本謂詞,其中至少有一個表達式包含主機變量/參數標記(基本謂詞包括像 =、<>、< 和 <=, 這樣的簡單的比較符,但是不包括像 IN、BETWEEN 和 IS NULL 這樣的東西。)
其中的 MATCH 表達式、謂詞表達式或換碼表達式中包含主機變量/參數標記的 LIKE 謂詞。
selectivity 的值必須是在 0 到 1 整個范圍內的一個數值常量(numeric literal)值。如果沒有指定 SELECTIVITY,那麼就會使用一個缺省值。如果 SELECTIVITY 的值為 0.01,則意味著該謂詞將過濾掉除表中所有行的 1% 之外的所有其他行。不過應該把提供 SELECTIVITY 看作是最後一招。
例如:
清單 16. 指定 Selectivity 的例子
SELECT c1, c2, c3, FROM T1, T2, T3
WHERE T1.x = T2.x AND
T2.y = T3.y AND
T1.x >= ? selectivity 0.000001 AND
T2.y < ? selectivity 0.5 AND
T3 = ? selectivity 1
DB2 v8 Documentation:
Reference ==> SQL ==> Language elements ==> Predicates ==> Search Conditions
持續維護
接下來的一些技術對於維護數據庫的最佳性能很有用。當您使用一個分了區的數據庫時,應記住命令的作用范圍。例如,RUNSTATS 命令只收集調用該命令時所在數據庫分區上的表的統計信息,而 REORG 則可以操作數據庫分區組中的所有分區。請參閱每個命令的文檔的 鈥楽cope' 部分。
REORG 和 REORGCHK
REORG 將消除溢出的行,並從表和索引中刪除的行那裡收回空間,如果有很多的刪除、更新或插入操作,這一命令就非常有用。該命令還可以用來將一個表放入到某個索引序列中(例如,在對群集索引的支持中就是如此)。REORG 命令可以在線執行和暫停。REORCHK 用於識別那些需要 REORG 的表和索引,也可用於收集數據庫中所有表的統計信息。
收集更新後的統計信息,並標識是否需要重組表或索引:
REORGCHK UPDATE STATISTICS ON TABLE ALL
標識是否需要根據當前統計信息重組表或索引:
REORGCHK CURRENT STATISTICS ON TABLE ALL
標識為需要 REORG 的表將在 REORGCHK 輸出的 reorg 列(F1 到 F8)中顯示一個或多個星號。現在就可以真正地 REORG 被標識出的表。為了 REORG 一個表,不考慮順序,只是簡單地從偽刪除的行收回空間,並消除溢出的行:
REORG TABLE schema.tablename
為了在一個表的所有索引上執行 REORG:
REORG INDEXES ALL FOR TABLE schema.tablename
為了根據特定的索引(ORDER BY 或一個群集索引)按物理序列對一個表排序:
REORG TABLE schema.tablename INDEX schema.indexname
DB2 v8 Documentation:
Reference ==> Commands ==> Command Line Processor (CLP) ==> REORG
Reference ==> Commands ==> Command Line Processor (CLP) ==> REORGCHK
RUNSTATS
REORG(重組)表和索引之後,重新收集表和索引的統計信息總是可取的,這樣優化器就可以創建最合適的訪問計劃。您可能發現執行一次抽樣的 RUNSTATS (對於大型數據庫會有更好的性能)或者執行一次後台運行。
為了標識之前是否已經對表和索引執行過 RUNSTATS:
清單 17. 標識 Runstats 時間
SELECT char(tabname,40)
FROM syscat.tables
WHERE type = 鈥楾'
AND stats_time is null
SELECT char(indname,40)
FROM syscat.indexes
WHERE stats_time is null
Or, to list runstat times (oldest first)
SELECT char(tabname,40), stats_time
FROM syscat.tables
WHERE type = 鈥楾'
ORDER by stats_time
對 System Catalog 表執行 RUNSTATS 也可以為這些表帶來好處。
下面是一些有用的命令:
表 4. 一些有用的 Runstats 命令
命令 描述 RUNSTATS ON TABLE schema.table 收集一個特定表的統計信息 RUNSTATS ON TABLE schema.tableAND INDEXES ALL 收集一個特定表及其所有索引的統計信息 RUNSTATS ON TABLE schema.tableAND SAMPLED DETAILED INDEXES ALL 使用擴展的索引統計信息和 CPU 采樣技術收集關於一個特定表的統計信息,這對於非常大型的索引(1+ 百萬行)十分有用,因為 RUNSTATS 可用的時間是有限的。 RUNSTATS ON TABLE schema.tableWITH DISTRIBUTION 收集關於一個表(或者也可以是特定列)的附加統計信息,當數據不是均勻分布時,這個命令很有用。
使用一條 SELECT 語句創建一個腳本也十分方便,只需將 SELECT 語句的結果通過管道發送到一個文件:
清單 18. 生成一個 Runstats CLP 腳本
SELECT 'RUNSTATS ON TABLE ' || rtrim(tabschema) || '.'
|| char(tabname,40) ||
' AND DETAILED INDEXES ALL;'
FROM syscat.tables
WHERE type = 'T'
ORDER BY tabschema, tabname;
DB2 v8 Documentation:
Reference ==> Commands ==> Command Line Processor (CLP) ==> RUNSTATS
REBIND
執行了 REORG 和 RUNSTATS 之後,您需要 REBIND 所有的數據庫包,以便靜態 SQL 可以利用最新的系統統計信息。使用 DB2RBIND 重新綁定所有的數據庫包:
db2rbind dbname -l logfile.out ALL
可以用 REBIND 來重新綁定單獨的包。
DB2 v8 Documentation:
Reference ==> Commands ==> System ==> db2rbind
Reference ==> Commands ==> Command Line Processor (CLP) ==> REBIND
數據庫分區功能(DPF)性能
DB2 v8.1 ESE 的數據庫分區功能(DPF)允許在一個服務器內或跨越一個群集的服務器給數據庫分區。這為支持非常大型的數據庫、復雜的工作負載和增加的管理任務的並行性提供了更多的可伸縮性。下面的小節包含幫助您獲得 DPF 方面的最佳性能的建議。
何時分區?
在 64 位 DB2 出現以前,分區技術通常用於解決 32 位架構中關於共享內存的限制(大約每個數據庫 2 GB)。利用內存的更好選擇是使用一個大型的 SMP 64 位服務器,因為這種服務器可以避免分區的復雜性和開銷。
然而,在某些情況下,分區也可以大大加快 Select、LOAD、BACKUP 和 RESTORE 的執行。每添加一個分區,就減少了每個分區上處理器要處理的數據量。通常,在分區數不多的小型數據庫中,這種性能上的提高難於見到,因為散列行和發送數據的開銷抵消了因處理更少數據而賺到的性能。
另一個分區的原因是克服對每個分區的一些 Database Manager 限制(例如,對於 4 K 的頁面大小,每個分區上的表最大為 64GB)。
多少個分區?
這個問題難於回答,因為有些系統每個分區 1 個 CPU 的時候運行得最好,而其他一些系統每個分區需要 8 個或更多 CPU。這裡的思想是讓分配給每個分區的 CPU 都忙起來。對於一個給定的 SMP 機器,一開始最好是大約每個分區 4 個 CPU。如果發現 CPU 的利用率一直比較低(例如低於 40%),那麼可能需要考慮增加更多的分區。
一般情況下,每台機器上的分區數越少越好,因為這樣一來更容易本地旁路(local bypass)和並置(後面會解釋)。
選擇一個理想的分區鍵
通過選擇一個適當的分區鍵,有助於確保平衡的數據分布和工作負載以及有效的表並置(table collocation)。
當選擇一個分區鍵時,通常應記住下面幾點:
總是親自指定分區鍵,而不是使用缺省值。
分區鍵必須是主鍵或惟一索引的子集。
有很多獨特值的列是比較好的選擇。如果一個列只有有限的幾種獨特值,那麼就只能生成少量的散列數,這會增加偏差數據和非平衡工作負載出現的機會。
如果分區鍵由太多的列組成(通常指 4 列或更多列),則僅僅是生成散列數這一項就可能導致性能下降。
使用經常要連接的一組相同的列作為分區鍵,以增加合並連接(collocated join)的數量。
使用 Integer 類型的列比使用字符類型的列更有效,後者又比使用小數類型的列更有效。
DB2 v8 Documentation:
Reference ==> SQL ==> Language elements ==> Data types ==> Partition-compatible data types
表並置
表並置允許本地處理查詢(在相同的邏輯分區內),這樣可以避免在參與的各分區間不必要的數據移動。為了幫助確保表並置,使用連接的列作為分區鍵,並將那些連接的表放入到共享相同分區組的表空間中。連接的表的分區鍵應該有相同的列數和相應的數據類型。
如果有些表不能按照跟它們通常連接的表相同的鍵來分區,而那些表的大小適中並且是只讀的,那麼采用復制的物化查詢表或許是提高性能的一個有效的解決辦法。這樣就允許將整個表(或表的一部分)內容復制到數據庫分區組中的每個分區上。然而,如果這個表要頻繁更新,那麼這樣就可能降低性能,因為要增加資源的使用。
為了創建一個簡單的復制的 MQT,使用下列語法:
CREATE TABLE replicated_table AS (SELECT * FROM source_table) DATA INITIALLY DEFERRED REFRESH IMMEDIATE REPLICATED
要了解關於 MQT 的更多信息,請參閱關於對表的討論的適當小節。
如果正在使用 AIX,並且啟用了 DB2 概要注冊表變量 DB2_FORCE_FCM_BP=YES,那麼,當使用多個邏輯分區(即在同一台機器上)時,在分區間傳輸的數據是通過共享內存處理的,這樣就會非常的快。
DB2 v8 Documentation:
Release information ==> Version 8.1 ==> New features ==> Performance enhancements ==> Materialized query tables
Reference ==> SQL ==> Functions ==> Scalar ==> DBPARTITIONNUM
重新平衡數據
使用 REDISTRIBUTE DATABASE PARTITION GROUP 重新平衡各分區間的數據,並更新 hash 分區映射,使其更加平衡。如果已經添加了一個分區,或者發現當前分區之間存在不平衡的數據量,那麼這樣做就比較有用。
您可以使用 HASHEDVALUE 和 DBPARTITIONNUM SQL 函數來確定當前數據在 hash 分區或數據庫分區之間的分布。應避免讓太多的數據集中在一個或多個分區,或者讓太少的數據分布在一個或多個分區。PARTITION 函數返回表中每一行的分區映射索引,而 DBPARTITIONNUM 函數則返回該行所在的分區號。例如,為了發現一個表的當前分布:
SELECT DBPARTITIONNUM( column), COUNT(*) FROM table GROUP BY DBPARTITIONNUM( column)
DB2 v8 Documentation:
Reference ==> Commands ==> Command Line Processor (CLP) ==> REDISTRIBUTE DATABASE PARTITION GROUP
利用率和瓶頸
下面指出處於 DB2 調優領域之外的一些潛在的問題,這些問題同樣能大大降低數據庫的性能。
CPU 利用率
如果一個系統中 CPU 的總利用率(用戶 + 系統)大於 80%,則認為該系統是 CPU 限制的(CPU bound)。經驗法則是,保持 CPU 利用率(大部分情況下)低於 80%,這樣可以為處理突然增加的大量活動預留 CPU 的處理能力。如果系統是 CPU 限制的,那麼就很難總結出問題所在。這可以是從無效率的訪問計劃到需要更多 CPU 資源的並發連接過多的任何問題。
在 Unix 中,用 vmstat (例如 "vmstat 3")進行監視。在 Windows 中,用 Perfmon.exe 或 Task Manager 進行監視。忽略在遇到短的突發事件(1-3 秒)時 100% 運行的 CPU,而關注長期的平均 CPU 利用情況。
清單 19展示了來自 RedHat 8.0 Linux 的某個輸出,其中重要的列用粗體強調。您需要觀察的列是用戶 CPU 利用率(us)和系統 CPU 利用率(sy)。id 列顯示了空閒時間。每次都應該忽略掉第一行。這裡我們看到的系統有相當高的用戶 CPU 利用率,而系統利用率則一般。
清單 19. 示例 vmstat 輸出
[db2inst1@65658161 db2inst1]$ vmstat 3
procs memory swap io system
cpu
r b w swpd free buff cache si so bi bo in
cs us sy id
0 0 0 0 704388 65460 165592 0 0 0 21 20 9
2 2 6
0 1 1 0 642096 65660 206060 0 0 515 2149 911 1047
18 9 72
2 1 0 0 639712 65668 208292 0 0 139 2287 862 938
30 10 60
1 0 0 0 629772 65692 215496 0 0 0 581 568 422
94 1 4
1 0 0 0 625764 65696 218956 0 0 0 1809 612 423
91 1 8
1 0 0 0 623752 65704 220752 0 0 11 1741 712 549
85 8 7
0 0 0 0 633548 65712 217768 0 0 11 1264 728 700
17 4 79
1 0 0 0 633556 65712 217768 0 0 0 87 621 280
5 7 88
0 0 0 0 633556 65712 217768 0 0 0 0 519 150
0 0 100
1 0 0 0 633556 65712 217768 0 0 0 0 523 154
0 0 100
高的 CPU 利用率有時候要歸因於對大型表的過度表掃描或索引掃描。通過分析 "rows read"值(在 SQL 快照中)很高的 SQL 語句,尋找建立索引的可能性。
還可以在進程級上進行監視,以更好地了解是什麼正在消耗 CPU。在 UNIX 上用 ps (例如 "ps uax")進行監視,在 Windows 則用 Perfmon.exe 或 Task Manager 進行監視。忽略掉突發的(1 到 3 秒)100% 利用率的情況,只關注長期的平均值。
例如,在 RedHat Linux 8.0 上,我們可以通過發出 "ps uax" 查看每個進行占用多少的 CPU:
清單 20. 示例 ps 輸出
[db2inst1@65658161 tmp]$ ps uax
user PID
%CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
db2inst1 9967
0.0 2.5 123416 26620 ? S Feb15 0:00 db2agent (idle)
db2inst1 10020
2.1 7.4 435200 76952 ? R Feb15 2:12 db2agent (TEST1)
db2inst1 3643
0.1 3.9 249544 41220 ? S 13:17 0:00 db2loggw (TEST1)
db2inst1 3649
0.0 4.0 249540 41320 ? S 13:17 0:00 db2pclnr
磁盤利用率
如果一個系統中磁盤利用率一般超過 45%,則認為該系統是 I/O 限制的。如果存在磁盤瓶頸,那麼應確保表空間的容器分布在所有可用磁盤上。如果磁盤利用率仍然很高,那麼很可能就需要更多的磁盤。
不幸的是,取決於所使用的操作系統,iostat 有不同格式的輸出。在 UNIX 中,用 iostat (例如 "iOStat 3")進行監視,而在 Windows 中則用 Perfmon.exe 進行監視。忽略掉突發(1-3 秒)的利用率 100% 的情況,只關注長期的平均利用率。
如果使用的是 Linux 操作系統,則使用 "iOStat –d –x 3" 命令以便支持擴展的磁盤信息,並尋找服務時間大於 50 ms(svctm)的磁盤,以及利用率超過 45% 的磁盤。由於格式的關系,下面的輸出中省略了某些數據列。
清單 21. 示例 iOStat 輸出
[db2inst1@65658161 tmp]$ iOStat -d -x 3
Linux 2.4.18-14 (65658161.torolab.ibm.com) 02/18/2004
Device: r/s w/s rsec/s wsec/s rkB/s wkB/s await
svctm %util
/dev/hda 0.01 2.25 0.19 41.81 0.09 20.91 0.60
1.88 0.42
/dev/hda1 0.00 0.00 0.00 0.00 0.00 0.00 277.20
176.86 0.00
/dev/hda2 0.00 0.00 0.00 0.00 0.00 0.00 4.11
4.11 0.00
/dev/hda3 0.01 2.25 0.19 41.81 0.09 20.91 0.58
0.66 0.15
Device: r/s w/s rsec/s wsec/s rkB/s wkB/s await
svctm %util
/dev/hda 0.00 383.67 0.00 5632.00 0.00 2816.00 8.10
1.35 51.97
/dev/hda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00
/dev/hda2 0.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00
/dev/hda3 0.00 383.67 0.00 5632.00 0.00 2816.00 8.10
2.16 82.93
內存和調頁空間的利用率
從 DB2 的角度來看,如果一個系統發生了換頁,則稱該系統是內存限制的(memory bound) 的。一旦開始換頁,性能通常就會急劇下降。
在 UNIX 中,使用 "lsps 鈥揳" 列出調頁空間的特征,並且用 vmstat (例如 "vmstat 3")進行監視。在 Windows 中,用 Perfmon.exe 或 Task Manager 進行監視。
例如,在 RedHat Linux 8.0 中,您需要注意交換(swap)信息。特別地,換入(si)和換出(so)列顯示了從磁盤換入內存的空間大小和從內存換出到磁盤的空間大小,以 KB/sec 為單位(在 AIX 上是以 4K pages/sec 為單位的)。
清單 22. 示例 iOStat 輸出
[db2inst1@65658161 tmp]$ vmstat 3
procs memory
swap io system cpu
r b w swpd free buff cache
si so bi bo in cs us sy id
0 0 0 0 675160 66088 175908
0 0 0 21 22 9 2 2 6
0 0 0 0 675096 66088 175908
0 2 0 37 624 246 5 7 88
2 0 0 0 665376 66088 183408
0 0 11 88 666 826 6 8 85
1 0 0 0 665376 66088 183408
1 0 0 76 623 452 5 8 88
2 0 0 0 654748 66096 191112
0 0 79 48 619 847 2 4 94
3 0 0 0 652760 66096 191192
0 0 15 47 578 791 2 2 96
網絡利用率
雖然通常網絡不是一個重大的瓶頸,但在這方面進行某些調優也可以提高性能。如果一個系統的 CPU 和 I/O 利用率都很低,則認為該系統是網絡限制的(Network bound),並且在通過網絡與 DB2 服務器進行通信時存在性能問題。在一個分了區的數據庫中,如果分區策略產生了一些非合並連接,則可能導致最嚴重的性能下降。
在 UNIX 中可以用 netpmon (例如 "netpmon -O all -o netpmon.out")進行監視,在 Windows 中可以用 Perfmon.exe 進行監視。