當使用來自於不同供應商的不同數據庫系統時,用戶和數據庫管理員將不可避免地碰到在這些產品中各不相同的特性和功能。通常,可在以下方面發現這些差異:
◆受支持的SQL方言中的不同語法。
◆數據庫管理器應用程序界面。
◆不同的管理工具及其用法。
為了使得將數據庫和應用程序從Oracle、Sybase或Microsoft SQL Server等數據庫產品遷移到IBM DB2,Universal Database(UDB)更容易,本文將展示一些可行的DB2 UDB功能實現,而且這些功能在其他數據庫系統中也可獲得。這些實現將涉及創建存儲過程和用戶定義函數(UDF)以實現那些常常被請求的功能。
在“下載”小節中,您將找到這些過程和函數的源代碼以及包含了create PROCEDURE和create FUNCTION語句的SQL腳本。如果您對確切的實現細節很感興趣,就請查閱這些代碼。一旦編譯並鏈接了源代碼(或安裝了預編譯的庫)以及在數據庫中注冊了這些過程和函數之後,您就可以按本文實例所演示的那樣來使用它們了。另外值得注意的是,這些過程和函數可用於DB2 UDB版本7和版本8。
清除表
當從Oracle遷移到DB2時,所碰到的一個普遍問題就是truncate命令。在Oracle中執行時,該命令不用借助一個或多個delete操作就可快速地清除表中所有內容,delete操作需要進行大量的日志記錄。
DB2的IMPORT功能提供了完成相同功能的方法,只要使用REPLACE INTO子句以及將一個空文件指定為數據源。在該情況下,表中所有的行都將被快速清除並且只使用一條日志記錄,接著就從給定的文件中導入新的數據。而對於一個空文件,就不會導入任何內容,從而在該操作結束時清除了該表。
要實現該功能,我們可以利用DB2定義的叫做 sqluimpr() 的CAPI函數來以程序的方式將數據導入數據庫的表中。我們將這個API包裝到存儲過程中,以便可通過SQL接口用於所有的應用程序,而無需考慮編程的語言。清單1中展示了存儲過程truncate_TABLE的簽名。
清單1. 過程truncate_TABLE的簽名 >>--truncate_TABLE--(--schema_name--,--table_name--)--------><
VARchar(130)類型的參數schema_name指定模式,用以在其中找到表。如果模式名外加了雙引號,就將其看成定界名稱(混合大小寫的和特殊的字符)。如果模式名為 空 ,即未指定模式,那麼則要查閱CURRENT SCHEMA專用寄存器來確定所要使用的模式。VARchar(130)類型的參數table_name指定將被清除的表的未限定名稱。加上顯式或隱式定義的模式名就可惟一地識別出表。如果表名外加了雙引號,就將其看成定界名稱(混合大小寫的和特殊的字符)。
如果輸入參數schema_name為空,則由該過程的邏輯來確定默認模式。否則,就刪除現有模式名上的雙引號,或者將未加引號的模式名轉換為大寫體。對於表名同樣如此,比如最後表名上的雙引號會被刪除,或者未加引號的表名會被轉換為大寫體。接著,我們通過查詢DB2目錄視圖SYSCAT.TABLES來證實該表是否存在。現在就可以啟動導入了。先准備好必要的參數,其中使用的文件是/dev/null(Windows上的NUL文件),因為它總是存在並且不包含任何內容,也就是可用作數據源的空文件。同樣,/dev/null(Windows上的NUL文件)將用於進行導入所需的消息文件。如果成功地啟動了導入,該過程就會成功返回。如果碰到錯誤,則與消息文本一起返回SQLSTATE以指示錯誤。清單2演示了過程truncate_TABLE的執行。可以在“下載”小節中找到該腳本(truncate_example.db2)的源代碼。
/*createandinsertsomevaluesintothetabletab1*/
createTABLEtab1(col1INTEGERNOTNULLPRIMARYKEY,col2VARchar(15))
DB20000ITheSQLcommandcompletedsuccessfully.
insertINTOtab1VALUES(1,’somedata’),(2,NULL)
DB20000ITheSQLcommandcompletedsuccessfully.
/*verifythecurrentcontentsoftabletab1*/
select*FROMtab1
COL1COL2
--------------------------
somedata
-
record(s)selected.
/*CallthetruncatestoredprocedurefortheDB2INST1schema,andthetabletab1*/
CALLtruncate(’DB2INST1’,’tab1’)
ReturnStatus=0
/*Verifythatthetablecontentshavebeentruncated.*/
select*FROMtab1
COL1COL2
--------------------------
record(s)selected.
/*insertsomenewvaluesintothetab1table*/
insertINTOtab1VALUES(2,’somenewdata’),(3,NULL)
DB20000ITheSQLcommandcompletedsuccessfully.
select*FROMtab1
COL1COL2
--------------------------
somenewdata
-
record(s)selected.
/*CallthetruncateprocedurewithaNULLschema*/
CALLtruncate(NULL,’tab1’)
ReturnStatus=0
/*Verifythatthetablecontentshavebeentruncated.*/
select*FROMtab1
COL1COL2
--------------------------
record(s)selected.
Sybase的host_name函數
Sybase數據庫中的host_name( ) 函數返回的是客戶機進程(非 Adaptive Server 進程)的當前主機名,也就是運行該應用程序的計算機的主機名而非數據庫服務器的主機名。
清單3.中展示了用戶定義函數HOST_NAME的簽名。
>>--HOST_NAME--()-------------><
該函數訪問存儲在DBINFO結構中的應用程序ID並解碼客戶機的IP地址(它是應用程序ID的一部分)。然後便使用C庫函數“gethostbyaddr”來解析該IP地址的名稱,該函數在必要時將訪問名稱服務器或其他源(比如 /etc/hosts)。
IP地址是應用程序ID中前面8字節的編碼,或者使用"*LOCAL"來代表本地連接。對於本地連接,解析的是IP地址為127.0.0.1的主機名。
注意:
由於DRDA的需求,如果非本地IP地址的第一個字符初始為‘0’到‘9’,就將之映射到字母‘G’到‘P’。而在該名稱查找之前,要將該映射反過來進行。
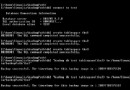
單4.演示了HOST_NAME函數的執行。可以在“下載”小節中找到該腳本host_name_example.db2的源代碼。
清單4.測試函數HOST_NAME( )
下面這個例子測試演示了用以獲取本地連接主機名的函數的執行。
在該場景中DB2數據庫駐留在一個本地AIX機器上。
地址127.0.0.1 在 /etc/hosts文件中被映射到計算機名demoaix
:/*connecttothelocaldatabase*/
connecttosample
DatabaseConnectionInformation
Databaseserver=DB2/60008.1.2
SQLauthorizationID=DB2INST1
Localdatabasealias=SAMPLE
/*executethehost_namefunction*/
valueshost_name()"
1
------------------------------------------------
demoaix
1record(s)selected.
下一個例子測試演示了遠程連接上的函數的執行。
在該場景中,DB2數據庫與上面一樣駐留在同一 AIX 機器上。
到AIX上數據庫的連接是由一個Windows 2000客戶機建立的;
該客戶機的名字為mycomputer。
/*ThedatabasesamplaixisanaliasfortheSAMPLEdatabaSEOnAIX*/
connecttosamplaix
DatabaseConnectionInformation
Databaseserver=DB2/60008.1.2
SQLauthorizationID=DB2INST1
Localdatabasealias=SAMPLAIX
/*executethehost_nameUDFagainsttheremotedatabase钬?
itreturnsthenameofthecomputeroftheclIEntconnection*/
valueshost_name()
1
------------------------------------------------
mycomputer
通過觸發器或用戶定義函數調用存儲過程的UDF
當遷移到DB2時,碰到的另一個普遍問題就是其他RDBMS可以通過觸發器或函數調用存儲過程。雖然DB2已經承諾在未來版本中包含該功能,但是我們將展示如何使用DB2的當前版本來實現該功能,即通過創建一個將對存儲過程發出調用的UDF來實現。
清單5.中展示了用於該目的的用戶定義函數CALL_PROCEDURE的簽名。
清單5.用戶定義函數CALL_PROCEDURE的簽名
>>--CALL_PROCEDURE--(--procedure_name--,--parameter_list--,----->
>-----database_name--,--user_name--,--passWord--)-------------><
VARchar(257)類型的參數procedure_name指定要被調用的存儲過程的全限定名—— 在傳遞多個參數時,要用逗號進行分隔。該字符串將被粘貼到用於調用過程的CALL語句中,因此其語法需要符合SQL CALL語句的要求。VARchar(8)類型的參數database_name指定要執行該存儲過程的數據庫的別名。存儲過程不一定要駐留在同一數據庫中。VARchar(128) 類型的參數user_name和VARchar(200)類型的參數passWord用於確定連接數據庫以及執行該過程時所使用的注冊信息。
該函數調用當前數據庫中的存儲過程。它建立新的連接之後就通過過程名和作為輸入參數而提供的參數來執行CALL語句。該UDF返回0(零)表明CALL語句(以及相應的CONNECT和CONNECT RESET語句)執行成功。否則,將返回DB2命令行處理器(Command Line Processor,CLP)的返回碼和一條提供了更多信息的出錯消息。清單6演示了函數 create_PROCEDURE的執行。可以在“下載”小節中找到該腳本(trig_calls_proc.db2)的源代碼。
清單6.測試函數create_PROCEDURE( )
下面這個例子測試演示了從觸發器調用包含一個參數的存儲過程。
在該示例中,我們創建t1和t2這兩個表,帶有一個輸入參數(p)的過程(abc)以及一個觸發器(ins)。在執行觸發器時,它將調用該過程。然後,過程將會將num列的新值(NEW.coll)插入到表t1中。這可以通過以下操作來測試:在表t2上執行插入後對t1發出select來檢驗該表內容 —— 進而檢驗該過程是否成功執行。
createtablet1(col1int)
DB20000ITheSQLcommandcompletedsuccessfully.
createtablet2(col1int)
DB20000ITheSQLcommandcompletedsuccessfully.
createprocedureabc(inpint)begininsertintot1values(p);end
DB20000ITheSQLcommandcompletedsuccessfully.
createtriggerinsafterinsertont2referencingNEWasnewforEACHROWMODE
DB2SQLBEGINATOMICvalues(call_procedure(’DB2INST1.ABC’,char(new.col1*2),
’SAMPLE’,’DB2INST1’,’db2inst1’));END
DB20000ITheSQLcommandcompletedsuccessfully.
insertintot2values20
DB20000ITheSQLcommandcompletedsuccessfully.
/*validatethatthetriggerhasfired-itshouldupdatet1*/
select*fromt1
COL1
-----------
40
1record(s)selected.
下一個例子演示了在UDF中調用包含了兩個參數的存儲過程。在該例中,我們創建表( c ),帶有兩個輸入參數的存儲過程( abc )以及帶有兩個參數(parm1,parm2)的 UDF( udf_withcall )。當執行該UDF時,它將調用存儲過程,然後,該存儲過程會將由UDF傳遞給它的值插入表c。對表c進行select將驗證表c的內容以及存儲過程是否執行成功。可以在“下載”小節中找到該腳本( udf_calls_proc.db2)的源代碼。
createtablec(aintcheck(a<>8),a1int)
DB20000ITheSQLcommandcompletedsuccessfully.
createprocedureabc(inpint,inp2int)begininsertintocvalues(p,p2);end
DB20000ITheSQLcommandcompletedsuccessfully.
createfunctionudf_withcall(parm1int,parm2int)
returnsint
LanguageSQL
notdeterministic
externalaction
returncall_procedure(’DB2INST1.ABC’,char(parm1)||’,’||char(parm2),’SAMPLE’,’DB2INST1’,’db2inst1’))
DB20000ITheSQLcommandcompletedsuccessfully.
selectudf_withcall(30,40)fromsysibm.sysdummy1
1
-----------
0
1record(s)selected.
/*verifythattheUDFhascalledtheprocedureandupdatedthetable*/
select*fromc
AA1
----------------------
1020
3040
2record(s)selected.
構建例程
為了構建C例程(UDF 或 存儲過程),必須首先對其進行預編譯、編譯以及鏈接。該過程可通過批文件bldrtn (UNIX/LINUX 上)或 bldrtn.bat (Windows 上)自動完成,該文件包含在隨DB2一同安裝的樣本中。可以在UNIX/Linux上的/sqllib/samples/c目錄或Windows上的
bldrtn[dbnameuseridpassWord]
如果未提供dbname,那麼批文件會將之默認為SAMPLE ,而userid和passWord則被默認為當前會話的用戶ID和口令。