讀者定位為具有一定開發經驗的 DB2 開發經驗的開發人員。
讀者可以從本文學習到如何編寫穩定、高效的存儲過程。並可以直接使用文章中提供的 DB2 代碼,從而節省他們的開發和調試時間,提高效率。
本文以 DB2 開發人員的角度介紹了在 DB2 存儲過程開發中需要注意的事項和技巧。新手如果能夠按照本文介紹的最佳實踐來開發存儲過程,可以避免一些常見的錯誤,從而編寫出高效的程序。本文從初始化參數、游標、異常處理、臨時表的使用以及如何尋找並 rebind 非法存儲過程等常見問題進行了著重討論,並且給出了示例代碼。
在存儲過程中,開發人員能夠聲明和設置 SQL 變量、實現流程控制、處理異常、能夠對數據進行插入、更新或者刪除。同時,客戶應用(這裡指調用存儲過程的應用程序,它可以是 JDBC 的調用,也可以是 ODBC 和 CLI 等)和存儲過程之間可以傳遞參數,並且從存儲過程中返回結果集。其中,使用 SQL 編寫的 DB2 存儲過程是在開發中常見的一種存儲過程。本文主要討論此類存儲過程。
最佳實踐 1:在創建存儲過程語句中提供必要的參數
創建存儲過程語句(CREATE PROCEDURE)可以包含很多參數,雖然從語法角度講它們不是必須的,但是在創建存儲過程時提供它們可以提高執行效率。下面是一些常用的參數
容許 SQL (allowed-SQL)
容許 SQL (allowed-SQL)子句的值指定了存儲過程是否會使用 SQL 語句,如果使用,其類型如何。它的可能值如下所示:
NO SQL: 表示存儲過程不能夠執行任何 SQL 語句。
CONTAINS SQL: 表示存儲過程可以執行 SQL 語句,但不會讀取 SQL 數據,也不會修改 SQL 數據。
READS SQL DATA: 表示在存儲過程中包含不會修改 SQL 數據的 SQL 語句。也就是說該儲存過程只從數據庫中讀取數據。
MODIFIES SQL DATA: 表示存儲過程可以執行任何 SQL 語句。即可以對數據庫中的數據進行增加、刪除和修改。
如果沒有明確聲明 allowed-SQL,其默認值是 MODIFIES SQL DATA。不同類型的存儲過程執行的效率是不同的,其中 NO SQL 效率最好,MODIFIES SQL DATA 最差。如果存儲過程只是讀取數據,但是因為沒有聲明 allowed-SQL 使其被當作對數據進行修改的存儲過程來執行,這顯然會降低程序的執行效率。因此創建存儲過程時,應當明確聲明其 allowed-SQL。
返回結果集個數(DYNAMIC RESULT SETS n)
存儲過程能夠返回 0 個或者多個結果集。為了從存儲過程中返回結果集,需要執行如下步驟:
在 CREATE PROCEDURE 語句的 DYNAMIC RESULT SETS 子句中聲明存儲過程將要返回的結果集的數量(number-of-result-sets)。如果這裡聲明的返回結果集的數量小於存儲過程中實際返回的結果集數量,在執行該存儲過程的時候,DB2 會返回一個警告。
使用 WITH RETURN 子句,在存儲過程體中聲明游標。
為結果集打開游標。當存儲過程返回的時候,保持游標打開。
在創建存儲過程時指定返回結果集的個數可以幫助程序員驗證存儲過程是否返回了所期待數量的結果集,提高了程序的完整性。
最佳實踐 2:對輸入參數進行必要的的檢查和預處理
無論使用哪種編程語言,對輸入參數的判斷都是必須的。正確的參數驗證是保證程序良好運行的前提。同樣的,在 DB2 中對輸入參數的驗證和處理也是很重要的。正確的驗證和預處理操作包括:
如果輸入參數錯誤,存儲過程應返回一個明確的值告訴客戶應用,然後客戶應用可以根據返回的值進行處理,或者向存儲過程提交新的參數,或者去調用其他的程序。
根據業務邏輯,對輸入參數作一定的預處理,如大小寫的轉換,NULL 與空字符串或 0 的轉換等。
在 DB2 儲存過程開發中,如需要遇到對空(NULL)進行初始化,我們可以使用 COALESCE 函數。COALESCE函數返回第一個非空的參數,語法如下:
清單1:COALESCE 函數
.---------------. (1) V |>>-COALESCE-------(--expression----,--expression-+--)----------><
COALESCE函數會依次檢查輸入的參數,返回第一個不是NULL的參數,只有當傳入COALESCE函數的所有的參數都是NULL的時候,函數才會返回NULL。例如, COALESCE(piName,''),如果變量piName為NULL,那麼函數會返回'',否則就會返回piName本身的值。
下面的例子展示了如何對參數進行檢查何初始化。
Person表用來存儲個人的基本信息,其定義如下:
表1: Person
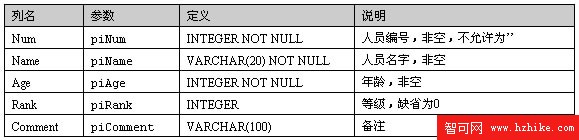
下面是用於向表Person插入數據的存儲過程的參數預處理部分代碼:
SET poGenStatus = 0; SET piName = RTRIM(COALESCE(piName, '')); SET piRank = COALESCE(piRank, 0); -- make sure all required input parameters are not null IF ( piNum IS NULL OR piName = '' OR piAge IS NULL ) THEN SET poGenStatus = 34100; RETURN poGenStatus; END IF;
表Person中num、name和age都是非空字段。對於name字段,多個空格我們也認為是空值,所以在進行判斷前我們調用RTRIM和COALESCE對其進行處理,然後使用 piName = '',對其進行非空判斷;對於Rank字段,我們希望如果用戶輸入的NULL,我們把它設置成"0",對其我們也使用COALESCE進行初始化;對於"Age"和"Num" 我們直接使用 IS NULL進行非空判斷就可以了。
如果輸入參數沒有通過非空判斷,我們就對輸出參數poGenStatus設置一個確定的值(例子中為 34100)告知調用者:輸入參數錯誤。
下面是對參數初始化規則的一個總結,供大家參考:
1. 輸入參數為字符類型,且允許為空的,可以使用COALESCE(inputParameter,'')把NULL轉換成'';
2. 輸入類型為整型,且允許為空的,可以使用COALESCE(inputParameter,0),把空轉換成0;
3. 輸入參數為字符類型,且是非空非空格的,可以使用COALESCE(inputParameter,'')把NULL轉換成'',然後判斷函數返回值是否為'';
4. 輸入類型為整型,且是非空的,不需要使用COALESCE函數,直接使用IS NULL進行非空判斷。
最佳實踐 3:正確設定游標的返回類型
前面我們已經討論了如何聲明存儲過程的返回結果集。這裡我們討論一下結果集返回類型的問題。結果集的返回類型有兩種:調用者(CALLER) 和客戶應用(CLIENT)。首先我們看一下聲明這兩種游標的例子:
CREATE PROCEDURE getPeople(IN piAge INTEGER)DYNAMIC RESULT SETS 2READS SQL DATALANGUAGE SQLBEGIN DECLARE rs1 CURSOR WITH RETURN TO CLIENT FOR SELECT name, age FROM person WHERE age
代碼中rs1游標的DECLAER語句中包含WITH RETURN TO CLIENT子句,表示結果集返回給客戶應用(CLIENT)。rs2游標的DECLARE語句中包含WITH RETURN TO CALLER子句,表示結果集返回給調用者(CALLER)。
游標返回給調用者(CALLER)表示由存儲過程的調用者接收結果集,而不考慮調用者是否是另一個存儲過程,還是客戶應用。圖(1)中存儲過程PROZ如果聲明為WITH RETURN TO CALLER,那麼結果集會返回給存儲過程PROY,ClIEnt Application是不會得到PROZ返回的結果集的。
圖1:存儲過程遞歸調用

游標返回給客戶應用(CLIENT)表示由發出最初 CALL 語句的客戶應用接收結果集,即使結果集由嵌套層次中的 15 層深的嵌套存儲過程發出也是如此。圖1中存儲過程 PROZ 如果聲明為 WITH RETURN TO CLIENT,那麼結果集會返回給 Client Application。返回給客戶應用(CLIENT)的游標聲明是我們經常使用的,也是默認的結果集類型。
在聲明返回類型時,我們要認真考慮一下,我們需要把結果集返回給誰,以免丟失返回集,導致程序錯誤。
最佳實踐 4:異常(condition)處理
在存儲過程執行的過程中,經常因為數據或者其他問題產生異常(condition)。根據業務邏輯,存儲過程應該對異常進行相應處理或直接返回給調用者。此處暫且將condition譯為異常以方便讀者理解。實際上有些異常(condition)並非是由於錯誤引起的,下面將詳細講述。
當存儲過程中的語句返回的SQLSTATE值超過00000的時候,就表明在存儲過程中產生了一個異常(condition),它表示出現了錯誤、數據沒有找到或者出現了警告。為了響應和處理存儲過程中出現的異常,我們必須在存儲過程體中聲明異常處理器(condition handler),它可以決定存儲過程怎樣響應一個或者多個已定義的異常或者預定義異常組。聲明條件處理器的語法如下,它會位於變量聲明和游標聲明之後:
清單2:聲明異常處理器
DECLARE handler-type HANDLER FOR condition handler-action
異常處理器類型(handler-type)有以下幾種:
CONTINUE 在處理器操作完成之後,會繼續執行產生這個異常語句之後的下一條語句。
EXIT 在處理器操作完成之後,存儲過程會終止,並將控制返回給調用者。
UNDO 在處理器操作執行之前,DB2會回滾存儲過程中執行的SQL操作。在處理器操作完成之後,存儲過程會終止,並將控制返回給調用者。
異常處理器可以處理基於特定SQLSTATE值的定制異常,或者處理預定義異常的類。預定義的3種異常如下所示:
NOT FOUND 標識導致SQLCODE值為+100或者SQLSATE值為02000的異常。這個異常通常在SELECT沒有返回行的時候出現。
SQLEXCEPTIOIN 標識導致SQLCODE值為負的異常。
SQLWARNING 標識導致警告異常或者導致+100以外的SQLCODE正值的異常。
如果產生了NOT FOUND 或者SQLWARNING異常,並且沒有為這個異常定義異常處理器,那麼就會忽略這個異常,並且將控制流轉向下一個語句。如果產生了SQLEXCEPTION異常,並且沒有為這個異常定義異常處理器,那麼存儲過程就會失敗,並且會將控制流返回調用者。
以下示例聲明了兩個異常處理器。 EXIT處理器會在出現SQLEXCEPTION 或者SQLWARNING異常的時候被調用。EXIT處理器會在終止SQL程序之前,將名為stmt的變量設為"ABORTED",並且將控制流返回給調用者。UNDO處理器會將控制流返回給調用者之前,回滾存儲過程體中已經完成的SQL操作。
清單3:異常處理器示例
DECLARE EXIT HANDLER FOR SQLEXCEPTION, SQLWARNING SET stmt = 'ABORTED';
DECLARE UNDO HANDLER FOR NOT FOUND;
如果預定義異常集不能滿足需求,就可以為特定的SQLSTATE值聲明定制異常,然後再為這個定制異常聲明處理器。語法如下:
清單4:定制異常處理器
DECLARE unique-name CONDITION FOR SQLSATE 'sqlstate'
處理器可以由單獨的存儲過程語句定義,也可以使用由BEGIN…END塊界定的復合語句定義。注意在執行符合語句的時候,SQLSATE和SQLCODE的值會被改變,如果需要保留異常前的SQLSATE和SQLCODE,就需要在執行復合語句的第一個語句把SQLSATE和SQLCODE賦予本地變量或參數。
通常,我們會為存儲過程定義一個執行狀態的輸出參數(例如:poGenStatus)。
根據這個輸出狀態,可以表明存儲過程是否正確執行完畢。我們需要定義一些異常處理器為這個輸出參數賦值。下面是一個例子:
清單5:定義為輸出參數賦值的異常處理器
-- Generic Handler DECLARE CONTINUE HANDLER FOR SQLEXCEPTION, SQLWARNING, NOT FOUND BEGIN NOT ATOMIC -- Capture SQLCODE & SQLSTATE SELECT SQLCODE, SQLSTATE INTO hSqlcode, hSqlstate FROM SYSIBM.SYSDUMMY1; -- Use the poGenStatus variable to tell the procedure -- what type of error occurred CASE hSqlstate WHEN '02000' THEN SET poGenStatus=5000; WHEN '42724' THEN SET poGenStatus=3; ELSE IF (hSqlCode < 0) THEN SET poGenStatus=hSqlCode; END IF; END CASE; END;
上面的異常處理器會在出現SQLEXCEPTION, SQLWARNING, NOT FOUND異常的時候觸發。異常處理器會取出當前的SQLCODE, SQLSTATE,然後根據它們的值來設置輸出參數(poGenStatus)的值。
我們還可以定制一些異常處理器。例如,我們可以定義一些對參數進行初始化的異常處理器。這裡,異常處理器可以看作是一個供存儲過程自己調用的內部函數。下面是這種情況的一個例子:
清單6:供存儲過程自己調用的內部函數
---------------------- -- CONDITION declaration ----------- -- (80100~80199) SQLCODE & SQLSTATE DECLARE sqlReset CONDITION for sqlstate '80100'; ----------------------------------------------------- -- EXCEPTION HANDLER declaration ----------------------------------------------------- -- Handy Handler DECLARE CONTINUE HANDLER FOR sqlReset BEGIN NOT ATOMIC SET hSqlcode = 0; SET hSqlstate = '00000'; SET poGenStatus = 0; END; ………… ----------------------------------------------------- -- Procedure Body ----------------------------------------------------- SIGNAL sqlreset; -- insert the record …………
上面定制的異常處理器負責對參數hSqlcode,hSqlstate和poGenStatus初始化。當我們在程序中需要對它們初始化時,我們只需要調用SIGNAL sqlreset就可以了。
最佳實踐 5:合理使用臨時表
我們在儲存過程開發中經常使用臨時表。合理的使用臨時表可以簡化程序的編寫,提供執行效率,然而濫用臨時表同樣也會使得程序運行效率降低。
臨時表一般在如下情況下使用:
1. 臨時表用於存儲程序運行中的臨時數據。例如,如果在一個程序中第一條查詢語句執行的結果會被後續的查詢語句用到,那麼我們可以把第一次查詢的結果存儲在一個臨時表中供後續查詢語句使用,而不是在後續查詢語句中重新查詢一次。如果第一條查詢語句非常復雜和耗時,那麼上面的策略是非常有效的。
2. 臨時表可以用於存儲在一個程序中需要返回多次的結果集。例如,程序中有一個很耗資源的多表查詢,同時,該查詢在程序中需要執行多次,那麼就可以把第一次查詢的結果集存儲在臨時保中,後續的查詢只需要查臨時表就可以了。
3. 臨時表也可以用於讓SQL訪問非關系型數據庫。例如,可以編寫程序把非關系型數據庫中的數據插入到一個全局臨時表中,那麼我們就可以對其數據進行查詢。
我們可使用 DECLARE GLOBAL TEMPORARY TABLE 語句來定義臨時表。DB2的臨時表是基於會話的,且在會話之間是隔離的。當會話結束時,臨時表的數據被刪除,臨時表被隱式卸下。對臨時表的定義不會在SYSCAT.TABLES中出現 下面是定義臨時表的一個示例:
清單7:定義臨時表
DECLARE GLOBAL TEMPORARY TABLE gbl_temp LIKE person ON COMMIT DELETE ROWS NOT LOGGED IN usr_tbsp
此語句創建一個名為 gbl_temp 的用戶臨時表。定義此用戶臨時表 所使用的列的名稱和說明與 person 的列的名稱和說明完全相同。
清單8:創建有兩個字段的臨時表
DECLARE GLOBAL TEMPORARY TABLE SESSION.TEMP2 ( ID INTEGER default 3, NAME CHAR(30) ) --WITH REPLACE NOT LOGGED; --IN USER_TEMP_01;
此語句創建了一個有兩個字段的臨時表。
理論上臨時表是不需要顯示DROP的,因為它是基於會話的,當臨時表基於的連接關閉的時候,臨時表也就不存在了。但是在實際開發中會有一些情況需要我們對臨時表加以注意。
一種情況就是被調用的存儲過程的返回值是一個基於臨時表的結果集。當存儲過程執行完畢的時候,臨時表並不會消失,因為返回的結果集相當於一個指針,指向臨時表所在的內存地址,此時臨時表是不會被DROP掉的。這種情況下,既不能在存儲過程中刪除這個臨時表,也不應該由客戶應用顯示的刪除臨時表,這就容易出現一些問題。下面我們通過一個例子來說明這個問題。
下面示例代碼是返回臨時表的存儲過程(get_temp_table):
清單9:返回臨時表的存儲過程
----------------------------------------------------- -- TEMPORARY TABLE & CURSOR declaration ----------------------------------------------------- DECLARE GLOBAL TEMPORARY TABLE SESSION.TEMP ( ID INTEGER, NAME CHAR(30) ) --WITH REPLACE NOT LOGGED; P2: BEGIN DECLARE R_CRSR CURSOR WITH RETURN TO CLIENT FOR SELECT * FROM SESSION.TEMP FOR READ ONLY; INSERT INTO SESSION.TEMP VALUES(1,piName); OPEN R_CRSR; END P2;
存儲過程中聲明了有兩個字段的臨時表TEMP,聲明了一個游標R_CRSR返回臨時表中所有記錄,最後在臨時表中插入兩條記錄。
圖2:程序第一次執行的結果
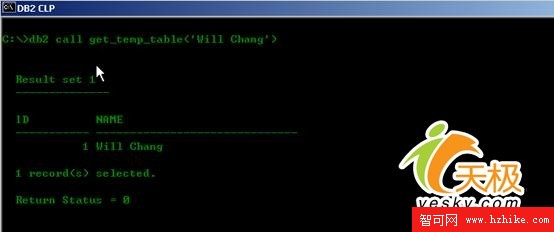
可以從圖中看出,運行結果是我們期望的。那麼如果我們再運行一次,會有什麼結果呢?下圖是其運行結果:
圖3:程序再次執行的結果
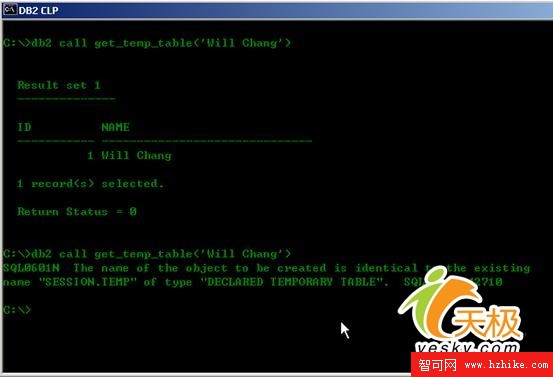
第二次執行的時候程序卻出錯了,這是因為在同一個連接中,臨時表並沒有被DROP掉,所以在第二次調用存儲過程的時候就會出現臨時表已經存在的錯誤。
另外一種情況,就是很多時候例如在websphere中通過JDBC連接數據庫時使用了連接池的技術,這帶來了一些效率的提升,同時在某些情況下也容易讓人誤解。客戶應用程序中關閉了數據庫連接,但是並不一定真正關閉了數據庫連接,如果客戶應用程序使用了臨時表而數據庫連接並沒有關閉,那麼臨時表就不會被DROP。當連接池把這個連接分給另一個客戶程序的時候,新的客戶程序仍然可以使用舊的臨時表,這不是我們希望的。如果想避免上述問題,可以在創建臨時表時,加上WITH REPLACE;或者根據業務邏輯在合適的地方顯示的DROP臨時表。
下面是使用WITH REPLACE創建臨時表的執行情況。
圖4:使用WITH REPLACE創建臨時表
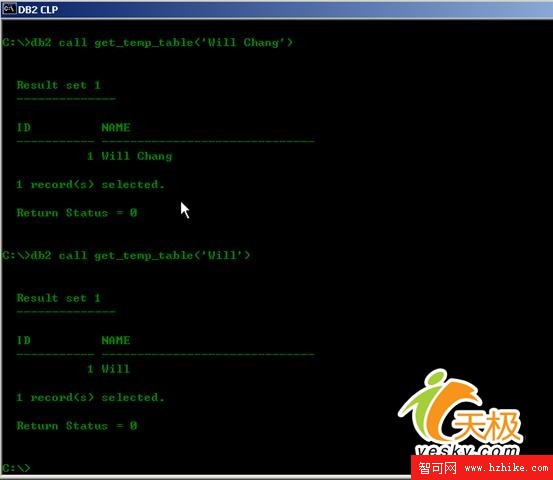
可以看出在一個連接裡面,多次調用存儲過程get_temp_table,也不會出現問題。臨時表在某些情況下也是需要避免使用的。大家知道臨時表是存放在內存中的,如果一個臨時表有上萬或者十幾萬條記錄,同時程序的並發數很大,那麼在內存中建立的臨時表耗費的資源就很龐大,此時數據庫的性能會急劇下降,甚至會導致數據庫崩潰。因此,大家在使用臨時表的時候,需要考慮它對資源的耗費,避免盲目使用臨時表。
最佳實踐 6:尋找並rebind 非法的存儲過程
存儲過程會因為其涉及和引用的對象發生了改變而導致其非法(invalid),例如:修改了表結構,導致引用該表的存儲過程非法,或者重新編譯一個存儲過程,會使調用這個存儲過程的父存儲過程非法。此時我們需要對非法的存儲過程重新編譯(rebind)。但是,對非法的存儲過程進行rebind的時候,需要確定其引用的對象是合法的,否則非法的存儲過程也不能rebind成功。
這裡我們介紹一下發現和rebind非法存儲過程的方法。我們是通過判斷SYSCAT.routines中VALID字段的值來查找非法存儲過程的。下面是查找非法存儲過程的一段代碼:
清單10:查找非法存儲過程
SELECT RTRIM(r.routineschema) || '.' || RTRIM(r.routinename) AS spname , ' ( '|| RTRIM(r.routineschema) || '.' || 'P'||SUBSTR(CHAR(r.lib_id+10000000),2)||' )' FROM SYSCAT.routines r WHERE r.routinetype = 'P' AND ((r.origin = 'Q' AND r.valid != 'Y') OR EXISTS ( SELECT 1 FROM syscat.packages WHERE pkgschema = r.routineschema AND pkgname = 'P'||SUBSTR(CHAR(r.lib_id+10000000),2) AND valid !='Y' ) ) ORDER BY spname;
獲得的結果如下:
清單11:查找非法存儲過程的結果
SPNAME ---------------------------------- TEST.DEMO_INFO_8 (TEST. P3550884)
可以使用下面的命令rebind它們
清單12:Rebind 非法存儲過程語法
rebind package packagename resolve any@
Packagename就是查詢結果中括號裡的值。例如,如果rebind上面查出來的存儲過程。我們只需要執行下面語句
清單13:Rebind 非法存儲過程
rebind package TEST.P3550884 resolve any@
當然,如果此存儲過程程序本身有問題,需要先修改存儲過程代碼後再進行編譯。
類似的,通過下面的代碼可以獲得非法的視圖。
清單14:獲得非法的視圖
SELECT RTRIM(viewschema) || '.' || RTRIM(viewname) AS viewname FROM SYSCAT.views WHERE valid = 'X' ORDER BY vIEwname;
結束語
本文介紹了我們在 DB2 存儲過程開發中經常用到的一些技巧。同時這些技巧也是編寫優秀存儲過程的基本要求。本文介紹的一些技巧只是揭開了高效使用 DB2 的冰山一角。DB2 為我們提供了豐富和強大的功能。在使用 DB2 的時候,我們應當深入理解其原理,找出更多的最佳實踐與大家分享。
參考資料
Red book: IBM DB2 UDB Command Reference Version 8
Red Book:IBM DB2 UDB Application Development Guide