關於編寫空間 SQL 語句的提示和技巧
SQL 的范例是,用戶(或應用程序)只需告訴數據庫系統要 做什麼,系統自己就會得出 如何做 這件事的最佳方法。因此,SQL 是一種純描述性語言。DB2 優化器盡力實現這個理想,通常做得也很好。但是,還存在一些特殊情況,在這些情況下,用戶的干預可以改善性能。因此,我們描述一些您應該記住的用於空間查詢和空間 DML 語句的概念。
處理多個行
一開始,SQL (現在也仍然)是一種面向集合的語言,而不是過程語言。這意味著同時處理一個集合中相關的行,而不是一個接一個地處理每一行。一個很好的例子就是 INSERT 語句:如果需要將多個行插入到相同的表中,那麼是在一條 SQL 語句中處理所有那些行,而不是觸發多條語句。這一事實對於空間數據尤其有意義,因為幾乎所有空間函數的實現都使得在同一條 SQL 語句中多次執行一個函數可以得到性能好處。在第一次調用函數時,函數的內部處理執行一些必要的初始化,例如設置計算所需的內存區域,隨後的調用則利用這個已建立好的基礎設施,直到在這條語句的作用域內最後一次調用函數時銷毀這個基礎設施。
所以,如果為每個要插入的行單獨執行一條 INSERT 語句,那麼前面提到的基礎設施的初始化和銷毀將每執行一次就重復一次,即對於每一行都重復一次。而將這些語句組合成一條單獨的語句可以避免重復的初始化和銷毀步驟,從而提升總體性能。此外,同時處理多個行還可以提高性能,因為減少了應用程序(DB2 客戶機)與數據庫引擎之間的交互次數。
讓我們通過一個簡單的例子來展示上述效果,在這個例子中,我們插入 50 個不同的行。首先,像清單 12 顯示的第 1 個語句那樣,使用 SQL 分別插入所有的行。清單 12 中的第 2 個語句將所有 50 行組合到一個單獨的插入操作中。其思想是,在一個描述性級別上,在 FROM 子句中建立一個臨時表,這個表由在調用任何空間函數之前導入的數據組成。接著,掃描那個臨時表中的所有行,並應用空間函數,從而構建一個新的表,最終這個表中的數據被插入 tab 表中。
對 INSERT 語句的這些考慮同樣適用於 SELECT 或 UPDATE 語句。例如,DB2 Spatial Extender 存儲過程 ST_run_gc 對一組行進行地理編碼(geocode)。如果為提交范圍指定一個值,那麼該過程可能不會立即處理所有受影響的行,但是其間它必須為這些行計數,並執行一個 COMMIT。初級的方法是使用一個游標對表進行掃描,並為每一行執行一個定位的更新語句。然而,定位更新會碰到我們剛才討論的一個問題,那就是必須一次又一次地初始化地理編碼器。
如果地理編碼不僅僅是構造一個 linestring,而是執行更復雜的功能,那麼對性能的影響將會更加顯著。所以,如果在表中找到一個標識列,例如主鍵,則可以找到一種不同的解決方案。我們使用 DB2 OLAP 函數 row_number() 將一個惟一的數值賦給每個受影響的列,然後運行一個 block-wise 搜索更新,之後執行一次 COMMIT。清單 13 闡釋了這一點。最裡邊的子查詢找出所有需要更新的行;用戶可能已經給出了一些條件來限制這些行。此外,每個行被賦予一個行號。下一步則根據行號過濾出那些屬於將被地理編碼的當前塊的行。最後,最外面的 UPDATE 在相同的 SQL 作用域內將那些行逐個提供給地理編碼器函數。這樣,地理編碼器只需為一個塊進行初始化,而不必為每一行進行初始化。
清單 13. 為地理編碼使用搜索更新
UPDATE <user_table>
SET location = <geocoder_function> ( <parameters> )
WHERE id IN ( SELECT t.id
FROM ( SELECT id, ROW_NUMBER OVER ( ORDER BY id ) AS rn
FROM <user_table>
WHERE <geocoding_selection> ) AS t
WHERE t.rn BETWEEN <first_row_num> AND <last_row_num> )@
減少對空間函數的調用
當看到我們在本文前面使用的空間查詢時,您會注意到,為了重疊測試,一個新的幾何圖形被構造成參數。現在,ST_LineString 構造函數是一個沒有任何副作用的確定性的函數。DB2 優化器知道那些條件,它可以斷定多次調用那個函數不會有害。取決於您的系統和查詢,這可能是一個聰明的選擇,但是也可能不是最佳的選擇。例如,在使用 DPF 特性的分區環境中,在每個分區上構造 linestring,與在單獨一個分區上構造幾何圖形,然後通過表隊列將它分布到其他需要這個值的分區上相比,可能要好得多。在另一種場景中,為將進行空間重疊測試的每一行生成 linestring 又可能產生完全不同的結果。因此,可能有必要使用公共表表達式重新構造空間查詢,以確保只調用一次構造函數。在清單 14 中,首先可以看到原有的查詢,後面有一個重新構造的查詢。這裡執行的 SQL 腳本可以在 下載 一節中找到。這兩個查詢都表達了相同的語義,但是在我們的系統和數據庫配置中,第二個查詢運行起來要快 9%。
清單 14. 重構空間查詢
$ db2batch -d testdb -f test_cte.sql -i complete -s on
---------------------------------------------
Statement number: 1
SELECT id
FROM roads2
WHERE db2gse.ST_Intersects(shape, db2gse.ST_LineString(
'linestring(10 50, 20 40)', 1003)) = 1
Prepare Time is: 0.000 seconds
Execute Time is: 0.819 seconds
Fetch Time is: 0.000 seconds
Elapsed Time is: 0.819 seconds
---------------------------------------------
Statement number: 2
WITH t(g) AS
( VALUES ( db2gse.ST_LineString('linestring(10 50, 20 40)', 1003) ) )
SELECT r.id
FROM roads2 AS r, t
WHERE db2gse.ST_Intersects(r.shape, t.g) = 1
Prepare Time is: 0.000 seconds
Execute Time is: 0.744 seconds
Fetch Time is: 0.000 seconds
Elapsed Time is: 0.745 seconds
---------------------------------------------
使用空間網格索引
至此,我們討論了很多提高空間操作性能的不同方面。現在我們將討論最顯著的一個方面,也就是對空間索引的使用。這裡我們解釋您應該做些什麼,以便讓 DB2 優化器選擇使用一個空間索引。索引本身的調優在 下一節 中解釋。
空間索引是建立在 DB2 可擴展索引框架(請參閱 參考資料 一節,找到關於 Index Extensions 的那篇文章)之上的一種擴展的索引。由於空間數據的多維特性,DB2 通常使用的 B* 樹並不是很合適,因此 DB2 Spatial Extender 提供了專門的索引機制。DB2 索引擴展由三個部分組成:
用於在 INSERT 和 UPDATE 操作中構造索引鍵的鍵生成器函數。
用於定義在查詢執行期間空間索引的搜索范圍的范圍生成器函數。
告訴 DB2 優化器在哪些條件下可以使用空間索引的空間謂詞。
DB2 Spatial Extender 已經定義了所有這些部分。除了真正創建一個空間索引外,您還必須熟悉最後一個部分。空間謂詞是與比較兩個幾何圖形的函數(即 ST_Contains、ST_Within、ST_Intersects、ST_Crosses、ST_Overlaps、ST_Touches、ST_EnvIntersects、ST_MBRIntersects、ST_Equals 和 ST_Distance)相關的謂詞。其他任何空間函數都不能使用網格索引。而且,只有當上述函數中的一個函數出現在查詢的 WHERE 子句中,並且該函數至少有一個參數標識出定義了網格索引的列的時候,才能使用空間網格索引。這聽起來好像有一大堆的條件,但還是比較簡單的:通過使用列可以找到索引,通過使用函數可以知道空間謂詞。
此外,DB2 要求遵從基本的語法規則,以檢測潛在的對空間謂詞的使用。函數調用必須發生在針對值 1 進行的相等比較式的左邊。一個例外是 ST_Distance 函數,它必須出現在針對一個任意距離的小於比較式中。清單 15 給出了這兩種正確的規范形式。
清單 15. 使用空間索引的語法規則
SELECT ...
FROM <user_table>
WHERE ST_Intersects(<indexed_shape_column>, ...) = 1@
SELECT ...
FROM <user_table>
WHERE ST_Distance(..., <indexed_shape_column>) < <some_distance>@
如果所有條件都符合,同時也符合簡單的語法規則,那麼還不能保證可以使用空間網格索引來滿足查詢。DB2 優化器計算不同的訪問計劃,並試圖找出總執行成本最低的計劃。為檢查在查詢時是否真正使用了一個空間網格索引,應該查看一下訪問計劃。可以通過 db2expln 命令行工具,或者在 DB2 Control Center 中右鍵單擊數據庫並選擇 Explain SQL 選項來收集訪問計劃。不管使用哪種方法,都可以生成和顯示訪問計劃。圖 3 描繪了我們在本文前面多次使用的查詢的訪問計劃。如果計劃包括對擴展索引的一個掃描,您將發現 EISCAN(在圖 3 中高亮顯示)。此外,您將在 EISCAN 下面發現網格索引的名稱。
圖 3. 帶有網格索引掃描的空間查詢訪問計劃
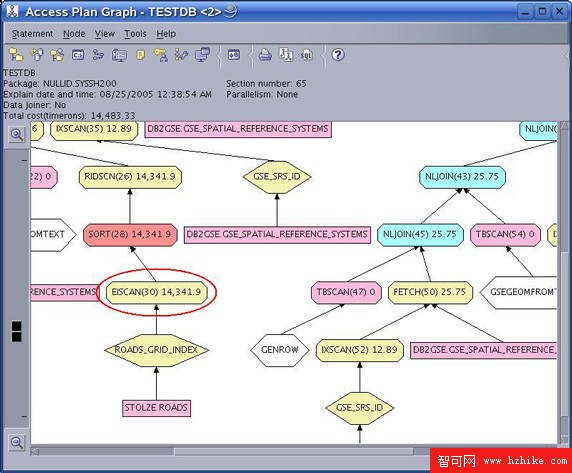
前面我們解釋過,DB2 優化器不完全知道空間網格索引的細節。而且,優化器很難判斷那樣的索引掃描的成本和選擇性。DB2 開發小組目前選擇的解決方案使用戶可以提供對空間謂詞選擇性的估計。為此,可以在 WHERE 子句中將關鍵字 SELECTIVITY 放在謂詞的後面,後面帶一個 0 到 1 之間的對選擇性的估計值。這個值越低,優化器就越有可能選擇掃描網格索引。清單 16 給出了一個查詢例子,在這個查詢中,向優化器提示空間謂詞只有很少的符合條件的行。
清單 16. 為空間謂詞指定選擇性
SELECT ...
FROM <user_table>
WHERE ST_Intersects(<indexed_shape_column>, ...) = 1 SELECTIVITY 0.000001@
調優空間網格索引
spatial extender 提供了一個 index advisor,以幫助您調優空間索引。index advisor 可以通過命令行工具 gseidx 訪問,它的語法比較羅嗦,這一點跟 SQL 本身一樣。該工具不僅可用於獲得關於各種不同網格大小的建議,還可以用於收集一個已有的或計劃中的(虛)索引的統計信息。所以,可以提取關於在選擇某種網格大小時在哪個網格層次上將生成多少索引項的信息,而不必真正創建和物化索引。您應該注意到,Index Advisor 提供的建議可以作為索引優化的出發點。
清單 17. Spatial Extender index advisor 的示例輸出
$ gseidx "CONNECT TO testdb GET GEOMETRY STATISTICS FOR COLUMN roads(shape)
USING GRID SIZES (0.5) SHOW HISTOGRAM WITH 10 BUCKETS"
Number of Rows: 110979
Number of non-empty GeometrIEs: 110979
Number of empty GeometrIEs: 0
Number of null values: 0
Extent covered by data:
Minimum X: -31.257690
Maximum X: 66.074104
Minimum Y: 34.824085
Maximum Y: 72.000000
Grid Level 1
------------
Grid Size : 0.5
Number of GeometrIEs : 110973
Number of Index EntrIEs : 147461
Number of occupIEd Grid Cells : 6596
Index Entry/Geometry ratio : 1.328801
Geometry/Grid Cell ratio : 16.824287
Maximum number of GeometrIEs per Grid Cell: 257
Minimum number of GeometrIEs per Grid Cell: 1
Index EntrIEs : 1 2 3 4 10
--------------- ------ ------ ------ ------ ------
Absolute : 82240 24962 236 3361 174
Percentage (%): 74.11 22.49 0.21 3.03 0.16
Grid Level X
------------
Number of GeometrIEs : 6
Number of Index EntrIEs : 6
Histogram:
----------
MBR Size Geometry Count
-------------------- --------------------
0.340000 105777
0.680000 4750
1.020000 334
1.360000 80
1.700000 22
2.040000 4
2.380000 5
2.720000 5
3.400000 2
$ gseidx "CONNECT TO testdb GET GEOMETRY STATISTICS FOR COLUMN roads(shape)
ADVISE GRID SIZES"
Query Window Size: Suggested Grid Sizes: Index Entry Cost:
-------------------- ----------------------------- ----------------------
0.01: 0.27, 0.54, 1.6 8.3
0.02: 0.27, 0.54, 1.6 8.7
0.05: 0.27, 0.54, 1.6 9.9
0.1: 0.27, 0.54, 1.6 12
0.2: 0.17, 0.51, 1.8 17
0.5: 0.17, 0.51, 1.8 40
1: 0.27, 0.68, 1.7 100
2: 0.43, 1.1, 2.2 290
5: 0.68, 2.4, 4.8 1300
10: 1.1, 5, 0 4500
20: 1.7, 10, 0 15000
如果您熟悉空間數據和網格索引,那麼結果就無需解釋了。關於空間網格索引機制和 Index Advisor 的更多細節可以在 DB2 Spatial Extender User's Guide and Reference(請參閱 參考資料 一節)中找到。值得一提的是,過去的經驗表明,與精細調優的網格索引相比,根據空間屬性聚集數據和使用一個適當定義的緩沖池更能對空間性能產生顯著的影響 —— 只要索引的參數大致在適當的范圍內。
選擇表空間類型
如果有很多數據修改操作,而查詢較少,那麼應該將注意力放在好的寫性能上。DB2 將數據庫中的所有數據都放在表空間中。管理員可以選擇表空間的類型和組成表空間的容器的類型。表空間的類型可以是 database managed(DMS)或 system managed(SMS),表空間類型的選擇對空間數據的寫性能有一定的影響。
建議為 LONG 數據選擇 DMS 類型的表空間,換句話說,選擇存放 LOB 的表空間。這樣做的效果是,大對象化的空間數據將被放入到那個表空間。做出這一決定的原因在於 DB2 的內部工作原理。這可以以一種更異步的方式將 LOB 寫到 DMS 表空間中,而將 LOB 寫到 SMS 表空間則要求同步的文件 I/O。
一旦將數據放在 DMS 表空間上,就可以根據表空間的容器進一步選擇是使用原始設備還是文件系統。對於大對象化的空間數據,通常使用文件系統更好一些。理由是:對基於容器的文件系統的訪問要經過操作系統內核,而操作系統帶有一個文件系統緩存,可以加快對文件的重復訪問。而對原始設備的訪問則沒有緩存,導致物理設備上的直接讀寫操作。現在,對於一般的數據庫操作,不必考慮文件系統緩存,因為 DB2 實現了緩沖池,這些緩沖池已經做了必要的緩存。但是對於 LOB 情況又不同了。由於不同的內部存儲模型和潛在的巨大對象(大到 2GB),這裡沒有緩沖池。所以文件系統緩存可以很大程度上幫助避免對磁盤的讀寫操作。
性能比較
清單 18 展示了不同表空間類型的影響。首先在一個 SMS 表空間上執行導入操作,一次使用一個較小的 inline length,一次使用都以內聯形式存儲的空間值,然後在一個 DMS 表空間上再次使用不同的 inline length 設置重復上述過程。可以使用 tableCreationParameters 選項指定目標表空間。最後,在兩個表(使用較小的 inline length)上運行空間查詢,以顯示查詢性能不受表空間的影響。
清單 18. SMS 與 DMS 表空間的性能比較
$ time db2se import_shape testdb -fileName /home/stolze/europe/roads
-srsName WGS84_SRS_1003 -tableName roads_sms
-tableCreationParameters "IN userspace1" -createTableFlag 1
-spatialColumn shape -typeName ST_LineString -inlineLength 292
-idColumn id -commitScope 1500
GSE0000I The Operation was completed successfully.
real 3m5.618s
user 0m0.056s
sys 0m0.026s
$ time db2se import_shape testdb -fileName /home/stolze/europe/roads
-srsName WGS84_SRS_1003 -tableName roads_sms
-tableCreationParameters "IN userspace1" -createTableFlag 1
-spatialColumn shape -typeName ST_LineString -inlineLength 2000
-idColumn id -commitScope 1500
GSE0000I The Operation was completed successfully.
real 1m56.643s
user 0m0.049s
sys 0m0.026s
$ time db2se import_shape testdb -fileName /home/stolze/europe/roads
-srsName WGS84_SRS_1003 -tableName roads_dms
-tableCreationParameters "IN dms" -createTableFlag 1
-spatialColumn shape -typeName ST_LineString -inlineLength 292
-idColumn id -commitScope 1500
GSE0000I The Operation was completed successfully.
real 0m49.310s
user 0m0.053s
sys 0m0.028s
$ time db2se import_shape testdb -fileName /home/stolze/europe/roads
-srsName WGS84_SRS_1003 -tableName roads_dms
-tableCreationParameters "IN dms" -createTableFlag 1
-spatialColumn shape -typeName ST_LineString -inlineLength 2000
-idColumn id -commitScope 1500
GSE0000I The Operation was completed successfully.
real 0m38.766s
user 0m0.054s
sys 0m0.024s
$ db2batch -d testdb -f test_tablespace.sql -i complete -s on
---------------------------------------------
Statement number: 1
SELECT id
FROM roads_sms
WHERE db2gse.ST_Intersects(shape, db2gse.ST_LineString(
'linestring(10 50, 20 40)', 1003)) = 1
Prepare Time is: 0.000 seconds
Execute Time is: 0.942 seconds
Fetch Time is: 0.000 seconds
Elapsed Time is: 0.943 seconds
---------------------------------------------
Statement number: 2
SELECT id
FROM roads_dms
WHERE db2gse.ST_Intersects(shape, db2gse.ST_LineString(
'linestring(10 50, 20 40)', 1003)) = 1
Prepare Time is: 0.000 seconds
Execute Time is: 0.953 seconds
Fetch Time is: 0.000 seconds
Elapsed Time is: 0.954 seconds
---------------------------------------------
與 SMS 表空間相比,將數據插入 DMS 表空間上的表中花費的時間大約只有四分之一。在解釋這些數值的時候,必須記住 DMS 和 SMS 表空間之間的基本不同點。DMS 表空間是在創建表空間時預先分配的。這意味著存放數據的頁是已經存在的。而 SMS 表空間是在運行時動態伸縮的,導入操作會導致很多新的頁被分配,同時表空間(和它的文件)也隨之增長。所以,性能提升的很大一部分要歸功於 DMS 上頁的預先分配。但是,當比較使用不同 inline length 取得的運行時間時,我們發現,如果使用較小的 inline length(即更多的大對象化幾何圖形),那麼將 SMS 換成 DMS 可以獲得 73% 的性能提升。如果使用較大的 inline length,則性能提升只有 66%。所以附加的性能提升顯然源自對大對象化數據更好的處理。
結束語
在本文中,我們展示了一些提升空間數據庫性能的重要技巧。文中談到了各種調優步驟,包括基本的系統調優,設置空間數據的 inline length,根據空間屬性聚集一個表中的行,調優空間網格索引,以及選擇適當的表空間類型。我們還解釋了一些決策的原因,並給出了通用的指導原則。此外,我們還在一個非常簡單的場景中演示了各個選項的效果。應用建議的指導原則所得到的結果取決於數據庫中實際的數據,以及整個系統和數據庫的配置。