結構化查詢語言(SQL)對於關系型DBMS是把雙刃劍,利弊參半。因為從關系型數據庫檢索任何數據都需要SQL,本文所要探討的話題就是:不論是終端用戶還是開發人員或是數據庫管理員(DBA),他們將如何訪問一個關系型數據庫。當使用高效的SQL時,系統會變得易於升級、靈活、而且便於管理。當使用低效的SQL時,響應時間和程序運行時間都會延長,並且還會產生應用系統的中斷。鑒於通常的數據庫系統一般要花費90%的處理時間用於從數據庫檢索數據,由此很明顯的可以看出盡可能的保證SQL的高效是多麼的重要。考察通常的SQL語句問題譬如"SELECT*FROM"僅是冰山一角,我們將在本文中探討其他容易確定的普遍的問題。需要記住的是,檢索得到同一數據的SQL語句有很多種殊途同歸的寫法,所以不存在好的查詢語句或是壞的查詢語句,而只有滿足適當需求的查詢語句。各關系型數據庫都有自己的方式來優化和執行查詢語句。因此,各DBMS都擁有自己的最佳性能的查詢技巧。本文將使用Quest軟件中QuestCentralforDB2的例子和概述來集中討論DB2forOS/390和z/0S。
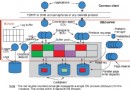
要是在十七年前,這張技巧單會更長,並且會包含對最小化的SELECT場景的矯正方法。每一個新版本的DB2都會增加成千上萬行的新代碼,用以擴展智能優化,和查詢重寫及執行。例如,多年來一種被稱為數據管理器的組件,通常被提供作為"第一階段處理"以增加它的過濾容量一百倍。另一組件是關系型數據服務器,通常被提供作為"第二階段處理"來進行其主函數的查詢重寫和優化。另一關鍵組件就是基於當前的SQL,並使用存取路徑以決定檢索數據的DB2優化器。DB2優化器改善了每一個DB2的版本,考慮到另外的DB2目錄中的統計,可以提供新的和改善過的存取路徑。圖1顯示了這些組件及其他更多的部分,並描述了DB2如何處理數據或SQL的請求。這就是以下DB2SQL性能技巧的來源。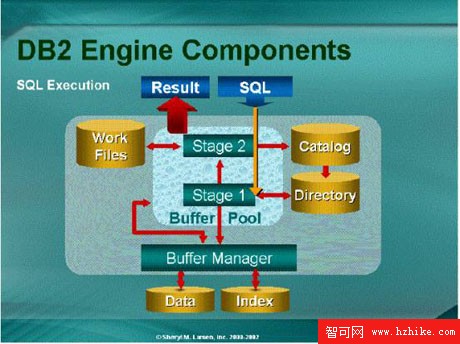
圖1:DB2Engine和一些組件介紹
在這篇文章中,我們將回顧一些更具有代表性的SQL問題,有更多的SQL方面的性能技巧超出了本篇文章描述的范圍。像所有指導方針一樣,所有這些技巧也會有一些例外。
技巧1:核實是否提供了適當的統計:
對於DB2優化器來說,最重要的資源除了SELECT語句本身,就是DB2目錄中創建的統計。優化器基於眾多的選擇而使用這些統計。DB2優化器為了查詢而選擇一條非最佳存取路徑的主要原因,歸結於無效的或缺失的統計。DB2優化器使用以下目錄統計:

圖2:DB2優化器驗證過的列和用來確定的存取路徑
經常的執行"RUNSTATS"命令,用來更新DB2的目錄統計,這樣可以在特別繁忙的生產環境裡中得到全貌。為了使執行"RUNSTATS"命令的影響最小化,可以考慮使用采樣技術。即使取樣10%也夠了。另外"RUNSTATS"命令可以更新統計,DB2給您可以額外更新1,000個條目的能力,以用於不均勻的分類統計。當心隨著每一條目隨著增量的增加,而涉及到對所有參考的綁定時間的影響。
假如當您缺少統計的時候您怎麼知道呢?當目錄或使用工具不能提供這種功能的時候,您可以通過手工執行查詢。當前,DB2優化器不能給缺失的統計提供具體的警告。
技巧2:盡可能的采用階段1和階段2的謂詞:
不論是階段1的數據管理器還是階段2的關系型數據服務器都將處理每一次查詢。當您處理查詢時,使用階段1將會比使用階段2有著巨大的性能優勢。當謂詞確定階段1能夠處理的時候,通常謂詞會限制您只能使用階段1查詢。另外,每一個謂詞都會被檢驗評估是否比另一個謂詞更有資袼作為索引路徑。有一些謂詞不能作為階段1來處理,或是不符合索引的條件。關於您的查詢是否可以被索引並且能夠在階段1被處理,理解這一點是很重要的。下面是文擋化的階段1或Sargable(search+argument-able謂詞是一個可以由數據管理器來值的謂詞)謂詞: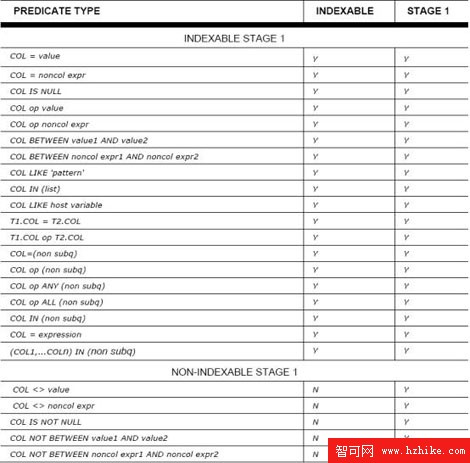
圖3:通常用表單來確定謂詞是否合格
還有一些謂詞不能看作階段1被文檔化,因為他們不能總處於階段1。加入表序列和查詢重寫也能夠影響謂詞被過濾掉的階段。讓我們通過例子查詢來顯示重寫您的SQL的影響。
例子1:COL1和COL1之間的值:
任何類型的謂詞如不能被階段1識別,就是階段2。如下所示就是階段2謂詞。然而,重寫可能促進對可索引階段1的查詢:Value>=COL1ANDvalue<=COL2。
這意味著,優化器也許會在多個索引中選擇一個匹配的索引來使用謂詞。沒有重寫,謂詞的剩余被當作階段2。
例子2:COL3NOTIN(K,S,T):
如果可能,非可索引的階段1的謂詞也應該被重寫。例如,符合以上條件的是階段1,但不是可索引的。括號裡值的列表辨認什麼與COL3不相等。為了確定重寫的可行性,辨認出那些COL3不相等的、更長和更不穩定的表單,就越不具有可行性。如果對面的(K,S,T)是少於200的靜態值,就值得輸入額外的重寫。促進階段1的條件對於可索引的階段1,提供了其它匹配索引選擇的優化器。既使一個可支持的索引在綁定時間不可利用,重寫也將確保查詢具有索引訪問的資格,並且此索引將在以後被創建。一旦一個索引被創建並與COL3合並,重新綁定的事務也許可能獲得匹配的索引訪問,那裡的舊謂詞將不會對重新綁定有影響。
技巧3:僅選擇需要的列:
每一個被選擇的列必須單獨地被傳回到調用程序,除非對整個的DCLGEN定義有精確匹配的。這也可能依賴於您向所有列發出的請求,但是,真正的損失發生在需要排序的時候。每一個被SELECTed的列,和重復的排序列,使得排序文件的寬度更寬。文件越長越寬,排序越慢。例如,100,000個四字節的列可能在大約一秒的時間內完成排序。而只有10,000個五十字節的列可能在同樣時間內完成排序。實際的時間是非常依賴於硬件的。
這個規則的例外是“DisallowSELECT*”,當幾個處理需要一個表中行的不同的部分的時候。通過事務的整合,一次取回所有行,然後單獨處理這些部分。
技巧4:選擇唯一需要的行:
越少的行被檢索,查詢將運行的越快。符合要求的行不得不令自己在存儲器中通過漫長之旅,穿過緩沖池,階段1,階段2,可能的分類和轉換,然後傳遞結果集到調用程序。數據庫管理器管理所有的數據過濾;這對於檢索一行是非常浪費的,測試在程序代碼裡的那一行,然後過濾掉那行。禁止程序自動過濾是一個必須強制執行的鐵的規則。開發商可能選擇使用程序代碼執行所有或部分的數據操作或者他們可能選擇使用SQL。典型地是混合在一起。已知的敘述顯示,過濾器可能被放入DB2engine裡的程序代碼,類似:
IFTABLE-COL4>:VALUE
GETNEXTRESULTROW
技巧5:使用常量和字面值,如果值在以後的3年中不改變(對於靜態查詢):
DB2優化器對所有不均勻的分類統計都充分的使用,並為任何一個列統計提供了不同領域范圍內的值,尤其當沒有主機變量在謂詞中被發現時,(WHERECOL5>'X')。主機變量的目的是使一個事務能適應一個可變化的變量;當一個用戶請求輸入這個值的時候是最經常被使用的。主機變量不需要重新綁定一個程序,當這個變量每一次改變的時候。這種可延伸性能得到優化器准確的耗費。當主機變量剛被發現,(WHERECOL5>:hv5),優化器使用以下的圖表來評估過濾器要素,而不是使用目錄統計:
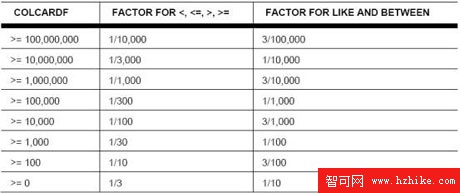
圖4:過濾器要素
列的基數性越高,則謂詞的過濾器要素就越低(保留部分行的預測)。多數時候,這種評估有助於優化器對適當存取路徑的選取。然而,有時謂詞的過濾器要素遠離實際。這就是通常需要對存取路徑進行調優的時候。
解決方案
QuestCentralforDB2是一個集成的控制台,可以提供核心功能,DBA(數據庫管理員)需要執行他們日常的數據庫管理任務,空間管理,SQL調優和分析,並且可以進行性能診斷監視。QuestCentralforDB2是由DB2軟件專家撰寫的,並且提供具豐富的功能,以利於視圖化的用戶界面,並且支持在Unix,Linux,和Windows主機上運行DB2數據庫。DB2的客戶不再被要求用獨立的工具維護和使用他們的主機和分布式的DB2系統。
QuestCentral的SQL調優組件提供一個完整的SQL調優環境。QuestCentral是唯一可以提供完整的SQL調優環境的針對DB2可用的產品。這個環境包括以下部分:
1.調優實驗室:通過場景的使用,一個單獨的SQL語句能夠被改進很多次。然後這些場景能夠立刻被比較以確定哪個SQL語句提供了最有效率的存取路徑。
2.比較:您立刻可以看出對於SQL語句修改的性能改變效果。由於比較多個場景,您能看到對CPU的效果,消耗的時間,I/O和其他更多的統計。另外數據的比較將保證您的SQL語句返回相同的數據子集。
3.建議:由SQL調優組件提供的建議,將會發現所有的在白皮書指定的條件等等。另外,如果一個新場景可以利用,SQL調優組件甚至將會重寫SQL,並綜合選擇的建議。
4.存取路徑和對應的統計:在SQL的上下文中,對於DB2存取路徑,所有適合的統計應被顯示出來。采取推測以設法理解為什麼選擇一個特殊的存取計劃。
QuestCentralforDB2健壯的功能顯現了上述SQL調優中的技巧以及更多。這篇白皮書剩余的部分將證明QuestCentral是由更豐富和更透徹的知識恰當的組成的。QuestCentral不僅可以提高您的SQL語句效率,更可以幫助您全面的提升數據庫的性能。上面描述的各種調優技巧都被QuestCentral所包括。
解決的技巧1:核實特定提供的統計:
一旦一條SQL語句在QuestCentral中被描述,建議欄會提供一整套建議,包括當沒有RUNSTATS時也可以發現的能力。QuestCentral一直以堅定的決心來探究這類建議。每一條建議都有相對應的"建議操作"。這種建議操作會指導如何矯正建議發現的問題。這將會打開一個新的場景由被重寫的SQL或以促進對象分析的腳本組成。在這個例子中,建議顯示,統計的缺失和相對應的建議操作將建立一個腳本,它包含RUNSTATS命令,為了在建議操作的窗口中選擇任何一個對象。
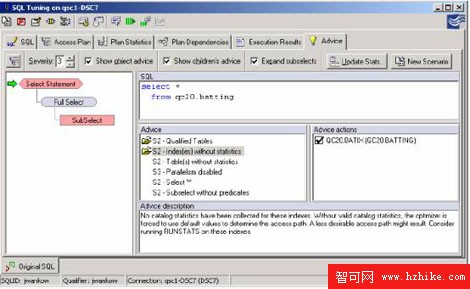
圖5:SQL調優的組件鑒別所有對象缺失的統計,
並且能夠生成必要的命令對所有選擇對象的統計進行更新。
另外,QuestCentralSpace的管理能夠自動的收集、維護和檢驗在表空間裡的統計及表和索引等級。以下的例子顯示了在數據庫裡所有表空間裡的統計檢驗報告。
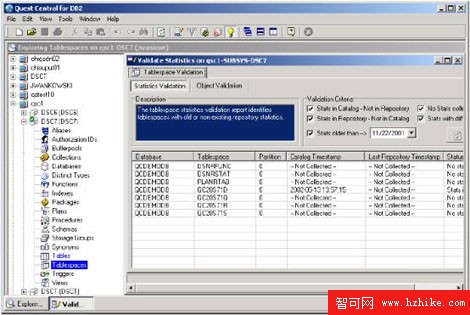
圖6:QuestCentral提供了一套容易使用的圖形界面,以促進RUNSTATS處理的自動化。
解決的技巧2:盡可能的提升階段2和階段1的謂詞:
SQL的調優組件將列出所有的謂詞並指出那些謂詞是否是"Sargable"或"Non-Sargable"。另外,各個謂詞都將被檢查,以確定它是否具有索引存取的資袼。這種單獨的建議可以解決響應時間的問題和在謂詞重寫的期間內得到某些成果。在下面的例子中,一條查詢被看作non-sargable和non-indexable(階段2)。這條最初的查詢被輸入在一個謂詞間。一個新場景被打開了並且謂詞被重寫使用大於,小於符號。這種比較確定了查詢重寫對性能方面的影響。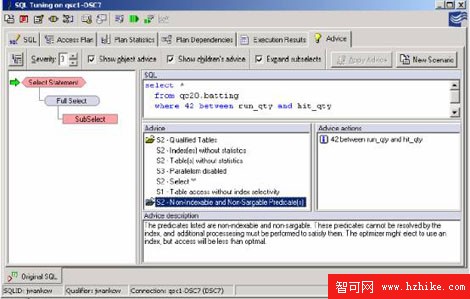
圖7:Querythatisnon-indexableandnon-sargable(stage2)
一個新場景被創建並且查詢被重寫在列值中使用"a>="和"a<="。注意,謂詞現在是可索引的和sargable。記住以上的信息,謂詞現在將由數據管理器(階段1)處理,以減少這次查詢的潛在響應時間。
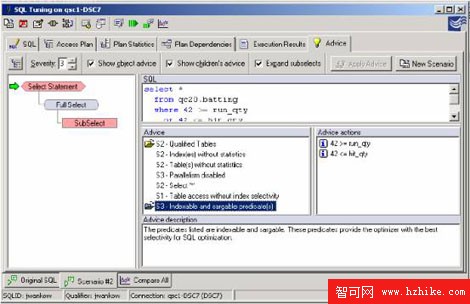
圖8:查詢是indexable和sargable(階段1)
隨後可以使用比較工具來比較他們和"<>"之間的性能,會發現"<>"更有效的減少消耗的時間。
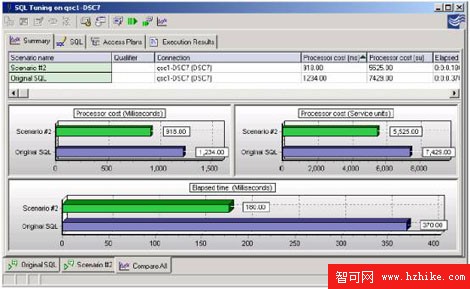
圖9:耗時減半
解決的技巧3:選擇唯一需要的列:
SQL調優的特點不僅是相對於使用"SELECT*"的建議,更提供一個事半功倍的可以令產品自動重寫SQL的特點。建議和相對應的建議操作將提供重寫您SQL的能力,簡單地檢查想要的列並選擇"applyadvice"按鈕,SQL調優將用被選擇的列替換"*"。
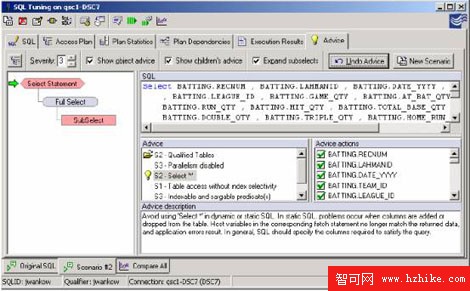
圖10:"applyadvice"的特點是將重寫SQL,並重視選擇的建議操作。
解決的技巧4:選擇唯一需要的行:
越少的行被檢索,查詢將運行的越快。使用QuestCentral能比較您最初的SQL相對於選擇較少行但相同的SQL語句。使用多個場景和利用比較特點,比較那些立刻顯示發生變化的性能影響的場景。在以下例子中,兩張表單的加入,產生了一個有意義的結果集。由於加入了"FetchFirst1RowOnly'"執行時間顯著的減少了。
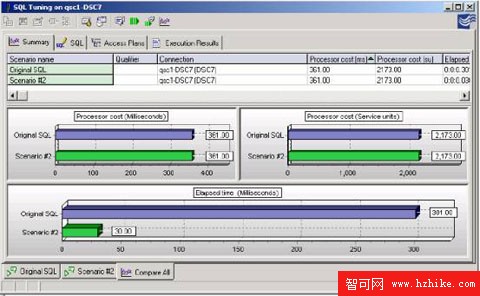
圖12:為了減少行數而修改一個SELECT語句,用來比較確認性能的受益。
解決的技巧5:使用常量和字面值,如果值在以後的3年中不改變(對於靜態查詢):
在這個例子中,讓我們進行一個基於Win2K平台的DB2測試。當使用主機變量時,DB2優化器無法預測謂詞過濾的值。沒有這個值,DB2將默認並使用上面列出的默認的過濾器要素。QuestCentralSQL調優將一直顯示過濾器要素用以幫助了解有多少列將被過濾。
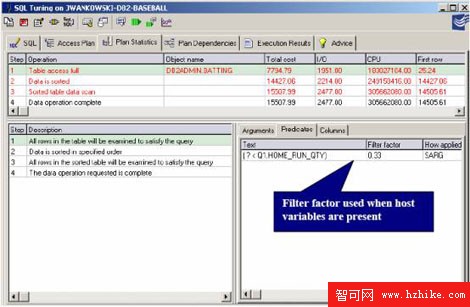
圖12:QuestCentral顯示每個謂詞的過濾器要素