本文寫作時,一個包含了用正則表達式進行文本處理的Java規范需求(Specification Request)已經得到認可,你可以期待在JDK的下一版本中看到它。 然而,如果現在就需要使用正則表達式,又該怎麼辦呢?你可以從apache(Unix平台最流行的WEB服務器平台).org下載源代碼開放的Jakarta-ORO庫。本文接下來的內容先簡要地介紹正則表達式的入門知識,然後以Jakarta-ORO API為例介紹如何使用正則表達式。
一、正則表達式基礎知識
我們先從簡單的開始。假設你要搜索一個包含字符“cat”的字符串,搜索用的正則表達式就是“cat”。如果搜索對大小寫不敏感,單詞“ctalog”、“Catherine”、“sophisticated”都可以匹配。也就是說:

1.1 句點符號
假設你在玩英文拼字游戲,想要找出三個字母的單詞,而且這些單詞必須以“t”字母開頭,以“n”字母結束。另外,假設有一本英文字典,你可以用正則表達式搜索它的全部內容。要構造出這個正則表達式,你可以使用一個通配符——句點符號“.”。這樣,完整的表達式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,還匹配“t#n”、“tpn”甚至“t n”,還有其他許多無意義的組合。這是因為句點符號匹配所有字符,包括空格、Tab字符甚至換行符:

1.2 方括號符號
為了解決句點符號匹配范圍過於廣泛這一問題,你可以在方括號(“[]”)裡面指定看來有意義的字符。此時,只有方括號裡面指定的字符才參與匹配。也就是說,正則表達式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因為在方括號之內你只能匹配單個字符:
1.3 “或”符號
如果除了上面匹配的所有單詞之外,你還想要匹配“toon”,那麼,你可以使用“|”操作符。“|”操作符的基本意義就是“或”運算。要匹配“toon”,使用“t(a|e|i|o|oo)n”正則表達式。這裡不能使用方擴號,因為方括號只允許匹配單個字符;這裡必須使用圓括號“()”。圓括號還可以用來分組,具體請參見後面介紹。

1.4 表示匹配次數的符號
表一顯示了表示匹配次數的符號,這些符號用來確定緊靠該符號左邊的符號出現的次數:

假設我們要在文本文件中搜索美國的社會安全號碼。這個號碼的格式是999-99-9999。用來匹配它的正則表達式如圖一所示。在正則表達式中,連字符(“-”)有著特殊的意義,它表示一個范圍,比如從0到9。因此,匹配社會安全號碼中的連字符號時,它的前面要加上一個轉義字符“\”。

圖一:匹配所有123-12-1234形式的社會安全號碼
<Html>
<head>
<title>Untitled</title>
</head>
<body>
<?PHP
$in="2344";
if(ereg("^(-{0,1}|\+{0,1})[0-9]+(\.{0,1}[0-9]+)$",$in))
echo "Ok!";
else
echo "Sorry,Please input again!";
?>
<br>很簡單的嘛!
</body>
</Html>
本文全面的詳細的介紹了ASP正則表達式的規范,以及如何建立和使用的注意事項。
什麼是正則表達式
如果原來沒有使用過正則表達式,那麼可能對這個術語和概念會不太熟悉。不過,它們並不是您想象的那麼新奇。
請回想一下在硬盤上是如何查找文件的。您肯定會使用 ? 和 * 字符來幫助查找您正尋找的文件。? 字符匹配文件名中的單個字符,而 * 則匹配一個或多個字符。一個如 'data?.dat' 的模式可以找到下述文件:
data1.dat
data2.dat
datax.dat
dataN.dat
如果使用 * 字符代替 ? 字符,則將擴大找到的文件數量。'data*.dat' 可以匹配下述所有文件名:
data.dat
data1.dat
data2.dat
data12.dat
datax.dat
dataXYZ.dat
盡管這種搜索文件的方法肯定很有用,但也十分有限。? 和 * 通配符的有限能力可以使你對正則表達式能做什麼有一個概念,不過正則表達式的功能更強大,也更靈活。
早期起源
正則表達式的“祖先”可以一直上溯至對人類神經系統如何工作的早期研究。Warren McCulloch 和 Walter Pitts 這兩位神經生理學家研究出一種數學方式來描述這些神經網絡。
1956 年, 一位叫 Stephen Kleene 的數學家在 McCulloch 和 Pitts 早期工作的基礎上,發表了一篇標題為“神經網事件的表示法”的論文,引入了正則表達式的概念。正則表達式就是用來描述他稱為“正則集的代數”的表達式,因此采用“正則表達式”這個術語。
隨後,發現可以將這一工作應用於使用 Ken Thompson 的計算搜索算法的一些早期研究,Ken Thompson 是 Unix 的主要發明人。正則表達式的第一個實用應用程序就是 Unix 中的 qed 編輯器。
如他們所說,剩下的就是眾所周知的歷史了。從那時起直至現在正則表達式都是基於文本的編輯器和搜索工具中的一個重要部分。
使用正則表達式
在典型的搜索和替換操作中,必須提供要查找的確切文字。這種技術對於靜態文本中的簡單搜索和替換任務可能足夠了,但是由於它缺乏靈活性,因此在搜索動態文本時就有困難了,甚至是不可能的。
使用正則表達式,就可以:
•測試字符串的某個模式。例如,可以對一個輸入字符串進行測試,看在該字符串是否存在一個電話號碼模式或一個信用卡號碼模式。這稱為數據有效性驗證。
•替換文本。可以在文檔中使用一個正則表達式來標識特定文字,然後可以全部將其刪除,或者替換為別的文字。
•根據模式匹配從字符串中提取一個子字符串。可以用來在文本或輸入字段中查找特定文字。
例如,如果需要搜索整個 web 站點來刪除某些過時的材料並替換某些HTML 格式化標記,則可以使用正則表達式對每個文件進行測試,看在該文件中是否存在所要查找的材料或 Html 格式化標記。用這個方法,就可以將受影響的文件范圍縮小到包含要刪除或更改的材料的那些文件。然後可以使用正則表達式來刪除過時的材料,最後,可以再次使用正則表達式來查找並替換那些需要替換的標記。
另一個說明正則表達式非常有用的示例是一種其字符串處理能力還不為人所知的語言。VBScript 是 Visual Basic 的一個子集,具有豐富的字符串處理功能。與 C 類似的 Jscript 則沒有這一能力。正則表達式給 JScript 的字符串處理能力帶來了明顯改善。不過,可能還是在 VBScript 中使用正則表達式的效率更高,它允許在單個表達式中執行多個字符串操作。
正則表達式語法
一個正則表達式就是由普通字符(例如字符 a 到 z)以及特殊字符(稱為元字符)組成的文字模式。該模式描述在查找文字主體時待匹配的一個或多個字符串。正則表達式作為一個模板,將某個字符模式與所搜索的字符串進行匹配。
這裡有一些可能會遇到的正則表達式示例:
如果用戶熟悉Linux下的sed、awk、grep或vi,那麼對正則表達式這一概念肯定不會陌生。由於它可以極大地簡化處理字符串時的復雜度,因此現在已經在許多Linux實用工具中得到了應用。千萬不要以為正則表達式只是Perl、Python、Bash等腳本語言的專利,作為C語言程序員,用戶同樣可以在自己的程序中運用正則表達式。
標准的C和C++都不支持正則表達式,但有一些函數庫可以輔助C/C++程序員完成這一功能,其中最著名的當數Philip Hazel的Perl-Compatible Regular Expression庫,許多Linux發行版本都帶有這個函數庫。
編譯正則表達式
為了提高效率,在將一個字符串與正則表達式進行比較之前,首先要用regcomp()函數對它進行編譯,將其轉化為regex_t結構:
int regcomp(regex_t *preg, const char *regex, int cflags);
參數regex是一個字符串,它代表將要被編譯的正則表達式;參數preg指向一個聲明為regex_t的數據結構,用來保存編譯結果;參數cflags決定了正則表達式該如何被處理的細節。
如果函數regcomp()執行成功,並且編譯結果被正確填充到preg中後,函數將返回0,任何其它的返回結果都代表有某種錯誤產生。
匹配正則表達式
一旦用regcomp()函數成功地編譯了正則表達式,接下來就可以調用regexec()函數完成模式匹配:
int regexec(const regex_t *preg, const char *string, size_t nmatch,regmatch_t pmatch[], int eflags);
typedef struct {
regoff_t rm_so;
regoff_t rm_eo;
} regmatch_t;
參數preg指向編譯後的正則表達式,參數string是將要進行匹配的字符串,而參數nmatch和pmatch則用於把匹配結果返回給調用程序,最後一個參數eflags決定了匹配的細節。
在調用函數regexec()進行模式匹配的過程中,可能在字符串string中會有多處與給定的正則表達式相匹配,參數pmatch就是用來保存這些匹配位置的,而參數nmatch則告訴函數regexec()最多可以把多少個匹配結果填充到pmatch數組中。當regexec()函數成功返回時,從string+pmatch[0].rm_so到string+pmatch[0].rm_eo是第一個匹配的字符串,而從string+pmatch[1].rm_so到string+pmatch[1].rm_eo,則是第二個匹配的字符串,依此類推。
釋放正則表達式
無論什麼時候,當不再需要已經編譯過的正則表達式時,都應該調用函數regfree()將其釋放,以免產生內存洩漏。
void regfree(regex_t *preg);
函數regfree()不會返回任何結果,它僅接收一個指向regex_t數據類型的指針,這是之前調用regcomp()函數所得到的編譯結果。
如果在程序中針對同一個regex_t結構調用了多次regcomp()函數,POSIX標准並沒有規定是否每次都必須調用regfree()函數進行釋放,但建議每次調用regcomp()函數對正則表達式進行編譯後都調用一次regfree()函數,以盡早釋放占用的存儲空間。
報告錯誤信息
如果調用函數regcomp()或regexec()得到的是一個非0的返回值,則表明在對正則表達式的處理過程中出現了某種錯誤,此時可以通過調用函數regerror()得到詳細的錯誤信息。
size_t regerror(int errcode, const regex_t *preg, char *errbuf, size_t errbuf_size);
參數errcode是來自函數regcomp()或regexec()的錯誤代碼,而參數preg則是由函數regcomp()得到的編譯結果,其目的是把格式化消息所必須的上下文提供給regerror()函數。在執行函數regerror()時,將按照參數errbuf_size指明的最大字節數,在errbuf緩沖區中填入格式化後的錯誤信息,同時返回錯誤信息的長度。
應用正則表達式
最後給出一個具體的實例,介紹如何在C語言程序中處理正則表達式。
#include <stdio.h>
#include <sys/types.h>
#include <regex.h>
/* 取子串的函數 */
static char* substr(const char*str, unsigned start, unsigned end)
{
unsigned n = end - start;
static char stbuf[256];
strncpy(stbuf, str + start, n);
stbuf[n] = 0;
return stbuf;
}
/* 主程序 */
int main(int argc, char** argv)
{
char * pattern;
int x, z, lno = 0, cflags = 0;
char ebuf[128], lbuf[256];
regex_t reg;
regmatch_t pm[10];
const size_t nmatch = 10;
/* 編譯正則表達式*/
pattern = argv[1];
z = regcomp(®, pattern, cflags);
if (z != 0){
regerror(z, ®, ebuf, sizeof(ebuf));
fprintf(stderr, "%s: pattern '%s' \n", ebuf, pattern);
return 1;
}
/* 逐行處理輸入的數據 */
while(fgets(lbuf, sizeof(lbuf), stdin)) {
++lno;
if ((z = strlen(lbuf)) > 0 && lbuf[z-1] == '\n')
lbuf[z - 1] = 0;
/* 對每一行應用正則表達式進行匹配 */
z = regexec(®, lbuf, nmatch, pm, 0);
if (z == REG_NOMATCH) continue;
else if (z != 0) {
regerror(z, ®, ebuf, sizeof(ebuf));
fprintf(stderr, "%s: regcom('%s')\n", ebuf, lbuf);
return 2;
}
/* 輸出處理結果 */
for (x = 0; x < nmatch && pm[x].rm_so != -1; ++ x) {
if (!x) printf("%04d: %s\n", lno, lbuf);
printf(" $%d='%s'\n", x, substr(lbuf, pm[x].rm_so, pm[x].rm_eo));
}
}
/* 釋放正則表達式 */
regfree(®);
return 0;
}
上述程序負責從命令行獲取正則表達式,然後將其運用於從標准輸入得到的每行數據,並打印出匹配結果。執行下面的命令可以編譯並執行該程序:
# gcc regexp.c -o regexp
# ./regexp 'regex[a-z]*' < regexp.c
0003: #include <regex.h>
$0='regex'
0027: regex_t reg;
$0='regex'
0054: z = regexec(®, lbuf, nmatch, pm, 0);
$0='regexec'
小結
對那些需要進行復雜數據處理的程序來說,正則表達式無疑是一個非常有用的工具。本文重點在於闡述如何在C語言中利用正則表達式來簡化字符串處理,以便在數據處理方面能夠獲得與Perl語言類似的靈活性。摘要:本文給出了在C#下利用正則表達式實現字符串搜索功能的方法,通過對.Net框架下的正則表達式的研究及實例分析,總結了正則表達式的元字符、規則、選項等。
關鍵字:正則表達式、元字符、字符串、匹配
1、正則表達式簡介
正則表達式提供了功能強大、靈活而又高效的方法來處理文本。正則表達式的全面模式匹配表示法可以快速地分析大量的文本以找到特定的字符模式;提取、編輯、替換或刪除文本子字符串;或將提取的字符串添加到集合以生成報告。對於處理字符串(例如 Html 處理、日志文件分析和 HTTP 標頭分析)的許多應用程序而言,正則表達式是不可缺少的工具。
.NET 框架正則表達式並入了其他正則表達式實現的最常見功能,被設計為與 Perl 5 正則表達式兼容,.NET 框架正則表達式還包括一些在其他實現中尚未提供的功能,.Net 框架正則表達式類是基類庫的一部分,並且可以和面向公共語言運行庫的任何語言或工具一起使用。
2、字符串搜索
正則表達式語言由兩種基本字符類型組成:原義(正常)文本字符和元字符。正是元字符組為正則表達式提供了處理能力。當前,所有的文本編輯器都有一些搜索功能,通常可以打開一個對話框,在其中的一個文本框中鍵入要定位的字符串,如果還要同時進行替換操作,可以鍵入一個替換字符串,比如在Windows操作系統中的記事本、Office系列中的文檔編輯器都有這種功能。這種搜索最簡單的方式,這類問題很容易用String類的String.Replace()方法來解決,但如果需要在文檔中識別某個重復的,該怎麼辦?編寫一個例程,從一個String類中選擇重復的字是比較復雜的,此時使用語言就很適合。
一般表達式語言是一種可以編寫搜索表達式的語言。在該語言中,可以把文檔中要搜索的文本、轉義序列和特定含義的其他字符組合在一起,例如序列\b表示一個字的開頭和結尾(子的邊界),如果要表示正在查找的以字符th開頭的字,就可以編寫一般表達式\bth(即序列字符界是-t-h)。如果要搜索所有以th結尾的字,就可以編寫th\b(序列t-h-字邊界)。但是,一般表達式要比這復雜得多,例如,可以在搜索操作中找到存儲部分文本的工具性程序(facility)。
3、.Net 框架的正則表達式類
下面通過介紹 .NET 框架的正則表達式類,熟悉一下.Net框架下的正則表達式的使用方法。
3.1 Regex 類表示只讀正則表達式
Regex 類包含各種靜態方法,允許在不顯式實例化其他類的對象的情況下使用其他正則表達式類。以下代碼示例創建了 Regex 類的實例並在初始化對象時定義一個簡單的正則表達式。請注意,使用了附加的反斜槓作為轉義字符,它將 \s 匹配字符類中的反斜槓指定為原義字符。
Regex r; // 聲明一個 Regex類的變量
r = new Regex("\\s2000"); // 定義表達式
3.2 Match 類表示正則表達式匹配操作的結果
以下示例使用 Regex 類的 Match 方法返回 Match 類型的對象,以便找到輸入字符串中第一個匹配。此示例使用 Match 類的 Match.Success 屬性來指示是否已找到匹配。
Regex r = new Regex("abc"); // 定義一個Regex對象實例
Match m = r.Match("123abc456"); // 在字符串中匹配
if (m.Success)
{
Console.WriteLine("Found match at position " + m.Index); //輸入匹配字符的位置
}
3.3 MatchCollection 類表示非重疊匹配的序列
該集合為只讀的,並且沒有公共構造函數。MatchCollection 的實例是由 Regex.Matches 屬性返回的。使用 Regex 類的 Matches 方法,通過在輸入字符串中找到的所有匹配填充 MatchCollection。下面代碼示例演示了如何將集合復制到一個字符串數組(保留每一匹配)和一個整數數組(指示每一匹配的位置)中。
MatchCollection mc;
String[] results = new String[20];
int[] matchposition = new int[20];
Regex r = new Regex("abc"); //定義一個Regex對象實例
mc = r.Matches("123abc4abcd");
for (int i = 0; i < mc.Count; i++) //在輸入字符串中找到所有匹配
{
results[i] = mc[i].Value; //將匹配的字符串添在字符串數組中
matchposition[i] = mc[i].Index; //記錄匹配字符的位置
}
3.4 GroupCollection 類表示捕獲的組的集合
該集合為只讀的,並且沒有公共構造函數。GroupCollection 的實例在 Match.Groups 屬性返回的集合中返回。下面的控制台應用程序查找並輸出由正則表達式捕獲的組的數目。
using System;
using System.Text.RegularExpressions;
public class RegexTest
{
public static void RunTest()
{
Regex r = new Regex("(a(b))c"); //定義組
Match m = r.Match("abdabc");
Console.WriteLine("Number of groups found = " + m.Groups.Count);
}
public static void Main()
{
RunTest();
}
}
該示例產生下面的輸出:
Number of groups found = 3
3.5 CaptureCollection 類表示捕獲的子字符串的序列
由於限定符,捕獲組可以在單個匹配中捕獲多個字符串。Captures屬性(CaptureCollection 類的對象)是作為 Match 和 group 類的成員提供的,以便於對捕獲的子字符串的集合的訪問。例如,如果使用正則表達式 ((a(b))c)+(其中 + 限定符指定一個或多個匹配)從字符串"abcabcabc"中捕獲匹配,則子字符串的每一匹配的 Group 的 CaptureCollection 將包含三個成員。
下面的程序使用正則表達式 (Abc)+來查找字符串"XYZAbcAbcAbcXYZAbcAb"中的一個或多個匹配,闡釋了使用 Captures 屬性來返回多組捕獲的子字符串。
using System;
using System.Text.RegularExpressions;
public class RegexTest
{
public static void RunTest()
{
int counter;
Match m;
CaptureCollection cc;
GroupCollection gc;
Regex r = new Regex("(Abc)+"); //查找"Abc"
m = r.Match("XYZAbcAbcAbcXYZAbcAb"); //設定要查找的字符串
gc = m.Groups;
//輸出查找組的數目
Console.WriteLine("Captured groups = " + gc.Count.ToString());
// Loop through each group.
for (int i=0; i < gc.Count; i++) //查找每一個組
{
cc = gc[i].Captures;
counter = cc.Count;
Console.WriteLine("Captures count = " + counter.ToString());
for (int ii = 0; ii < counter; ii++)
{
// Print capture and position.
Console.WriteLine(cc[ii] + " Starts at character " +
cc[ii].Index); //輸入捕獲位置
}
}
}
public static void Main() {
RunTest();
}
}
此例返回下面的輸出結果:
Captured groups = 2
Captures count = 1
AbcAbcAbc Starts at character 3
Captures count = 3
Abc Starts at character 3
Abc Starts at character 6
Abc Starts at character 9
3.6 Capture 類包含來自單個子表達式捕獲的結果
在 Group 集合中循環,從 Group 的每一成員中提取 Capture 集合,並且將變量 posn 和 length 分別分配給找到每一字符串的初始字符串中的字符位置,以及每一字符串的長度。
Regex r;
Match m;
CaptureCollection cc;
int posn, length;
r = new Regex("(abc)*");
m = r.Match("bcabcabc");
for (int i=0; m.Groups[i].Value != ""; i++)
{
cc = m.Groups[i].Captures;
for (int j = 0; j < cc.Count; j++)
{
posn = cc[j].Index; //捕獲對象位置
length = cc[j].Length; //捕獲對象長度
}
}
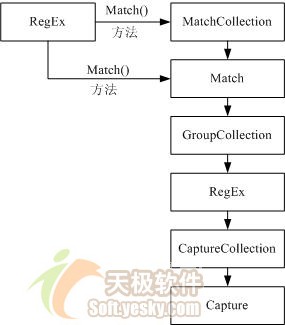
圖1:對象關系
把組合字符組合起來後,每次都會返回一個組對象,就可能並不是我們希望的結果。如果希望把組合字符作為搜索模式的一部分,就會有相當大的系統開銷。對於單個的組,可以用以字符序列"?:"開頭的組禁止這麼做,就像URI樣例那樣。而對於所有的組,可以在RegEx.Matches()方法上指定RegExOptions.ExplicitCapture標志。
正則表達式的用途很廣泛,但要熟練掌握就不是一件容易的事情了。為此,我編寫了這個練習器用來幫助學習。
請多指教!
*********將以下代碼復制到 RegExp.htm 即可 **********
<Html>
<HEAD>
<TITLE>正則表達式練習器</TITLE>
<meta name = 安徽 池州 統計局 徐祖寧 e-mail:czJSz@stats.gov.cn>
<script language="JavaScript">
function OnMove() {
window.status = "("+window.event.clientX+","+window.event.clIEntY+")" + " :: "+document.location
}
</script>
<SCRIPT LANGUAGE="JavaScript1.2">
var re = new RegExp() //建立正則表達式對象
var nextpoint = 0 //匹配時的偏移量
//設置正則表達式
function setPattern(form) {
var mode
if(form.chkmode.checked) mode = "gi" //i:不分大小寫 g:全局,好象沒什麼作用
else mode = "g"
re.compile(form.regexp.value,mode)
nextpoint = 0
form.reglist.value = ""
}
//檢查是否有匹配
function findIt(form) {
setPattern(form)
var input = form.main.value
if (input.search(re) != -1) {
form.output[0].checked = true
} else {
form.output[1].checked = true
}
}
//檢查匹配位置
function locateIt(form) {
setPattern(form)
var input = form.main.value
form.offset.value = input.search(re)
}
//檢查所有的匹配情況
function execIt(form) {
if(nextpoint == 0 || ! form.scankmode.checked) {
findIt(form)
form.reglist.value = ""
}
var key = true
if(form.scankmode.checked) key = false
do {
var input = form.main.value
var matchArray = re.exec(input.substr(nextpoint))
if(matchArray) {
for(var i=1;i<matchArray.length;i++)
matchArray[i] = "$Content$quot;+i+":"+matchArray[i]
form.reglist.value = (nextpoint+matchArray.index)+" => " + matchArray[0] +""+form.reglist.value
form.matchlist.value = ":"+matchArray.join("")
nextpoint = nextpoint + matchArray.index + matchArray[0].length
}else {
if(!key)
form.reglist.value = "沒有找到" + form.reglist.value
form.matchlist.value = " "
nextpoint = 0
key = false
}
}while (key)
}
//設置當前使用的正則表達式
function setregexp(n) {
var s = document.all.regexplist.value.split("")
document.all.regexp.value = s[n*2-1] //.replace("","")
nextpoint = 0
}
//定義選擇監視
var isNav = (navigator.appName == "Netscape")
function showSelection() {
if (isNav) {
var theText = document.getSelection()
} else {
var theText = document.selection.createRange().text
}
if(theText.length>0 && document.all.selechkmode.checked)
document.all.regexp.value = theText
}
if (isNav) {
document.captureEvents(Event.MOUSEUP)
}
document.onmouseup = showSelection
</SCRIPT>
</HEAD>
<BODY style="font-size=9pt;" OnMouseMove=OnMove()>
<FORM><table width=100% cellspacing=0 cellpadding=0><tr><td><font color=red>正規表達式練習器</font></td><td align=right><a href=mailto:czjsz_ah@stats.gov.cn>czJSz_ah@stats.gov.cn</a></td></tr></table>
<table width=100% broder=1 frame=above rules=none style="font-size:9pt;">
<tr><td width=50% valign=top>
輸入一些被尋找的正文:<BR>
<TEXTAREA NAME="main" COLS=58 ROWS=5 WRAP="virtual" style="font-size:9pt;">
09-11-2001 09/11/2001 czJSz_ah@stats.gov.cn
asdff 12345 196.168.1.3 www.sohu.com FTP://www.chinaasp.com 2001.9.11 http://www.active.com.cn/club/bbs/bbsVIEw.ASP http://www.163.com/inden.htm
</TEXTAREA><BR>
進行匹配的正規表達式: 忽略大小寫<INPUT TYPE="checkbox" NAME="chkmode" checked style="font-size:8pt;height:18px"><BR>
<TEXTAREA NAME="regexp" COLS=51 ROWS=5 style="font-size:9pt;"></TEXTAREA>
<INPUT TYPE="button" VALUE="清除" onClick="this.form.regexp.value=‘‘" style="font-size:8pt;height:18px"><BR>
<INPUT TYPE="button" VALUE="能找到嗎?[regexObject.test(string)]" style="font-size:8pt;width:70%;height:18px" onClick="findIt(this.form)">
<INPUT TYPE="radio" NAME="output" style="font-size:8pt;height:18px">Yes
<INPUT TYPE="radio" NAME="output" style="font-size:8pt;height:18px">No <BR>
<INPUT TYPE="button" VALUE="在哪裡?[string.search(regexObject)]" style="font-size:8pt;width:70%;height:18px" onClick="locateIt(this.form)">
<INPUT TYPE="text" NAME="offset" SIZE=4 style="font-size:8pt;height:18px">
</td>
<td valign=top>
測試用正則表達式列表:
使用第<input type=text name=num size=2 value=1 style="font-size:8pt;height:18px">個<input type=button value=Go onClick=setregexp(this.form.num.value) style="font-size:8pt;height:18px">
允許復制<INPUT TYPE="checkbox" NAME="selechkmode" style="font-size:8pt;height:18px">
<textarea NAME="regexplist" cols=58 rows=14 wrap=off style="font-size:9pt;">
1.檢查日期:
(1[0-2]|0?[1-9])[-./](0?[1-9]|[12][0-9]|3[01])[-./](dddd))
2.檢查數字:
([-+]?[0-9]+.?[0-9]+)
3.檢查URL:
((http|FTP)://)?(((([d]+.)+)[d]+(/[w./]+)?)|([a-z]w*((.w+)+))([/][w.~]*)*)
4.檢查E-mail
w+@((w+[.]?)+)
</textarea>
</td></tr>
<tr><td valign=bottom>
<INPUT TYPE="button" VALUE="有哪些?[regexObject.exec(string)]" style="font-size:8pt;width:70%;height:18px" onClick="execIt(this.form)">
單步<INPUT TYPE="checkbox" NAME="scankmode" style="font-size:8pt;height:18px"><BR>
<TEXTAREA NAME="reglist" COLS=58 ROWS=8 style="font-size:9pt;"></TEXTAREA>
</td>
<td valign=bottom>
匹配到的成分:(單步時可見)
<TEXTAREA NAME="matchlist" COLS=58 ROWS=8 style="font-size:9pt;"></TEXTAREA>
</td></tr></table></FORM>
<script>
setregexp(1)
</script>
</BODY>
</Html>
對正則表達式練習器的改進,原貼ID901680
覆蓋原execIt函數
修改後的execIt函數允許對多個正則表達式進行匹配(每個正則表達式一行),並對每一個匹配成分顯示出是第幾個正則表達式匹配的。
這可視為語法分析的雛形,只要對匹配產生相應的動作。
function execIt(form) {
var mode
if(form.chkmode.checked) mode = "gi"
else mode = "g"
var regexpArray = form.regexp.value.split("") //獲取正則表達式到數組
if(nextpoint == 0) form.reglist.value = ""
var key = true
if(form.scankmode.checked) key = false
else nextpoint = 0
do {
var offs = 9999999999
var pos = -1
var input = form.main.value.substr(nextpoint)
//對每個正則表達式進行匹配
for(var i=0;i<regexpArray.length;i++) {
re.compile(regexpArray[i],mode)
var matchArray = re.exec(input)
if(matchArray) {
if(offs > matchArray.index) {
offs = matchArray.index
pos = i //保存距離起始位子最近的匹配
}
}
}
if(pos>=0) {
re.compile(regexpArray[pos],mode)
var matchArray = re.exec(input)
for(var i=1;i<matchArray.length;i++)
matchArray[i] = "$Content$quot;+i+":"+matchArray[i]
form.reglist.value = "["+(pos+1)+"]"+(nextpoint+matchArray.index)+" => " + matchArray[0] +""+form.reglist.value
form.matchlist.value = ":"+matchArray.join("")
nextpoint = nextpoint + matchArray.index + matchArray[0].length
}else {
if(!key)
form.reglist.value = "沒有找到" + form.reglist.value
form.matchlist.value = " "
nextpoint = 0
key = false
}
}while(key)
}
關鍵字:正則表達式,Regular Expression
原著:笑容
創作於:2004年05月03日
最後更新:2004年05月04日 21:12
引用地址:正則表達式(regular expression)
版權聲明:使用創作公用版權協議
前言
正則表達式是煩瑣的,但是強大的,學會之後的應用會讓你除了提高效率外,會給你帶來絕對的成就感。只要認真去閱讀這些資料,加上應用的時候進行一定的參考,掌握正則表達式不是問題。
索引
1._引子
2._正則表達式的歷史
3._正則表達式定義
3.1_普通字符
3.2_非打印字符
3.3_特殊字符
3.4_限定符
3.5_定位符
3.6_選擇
3.7_後向引用
4._各種操作符的運算優先級
5._全部符號解釋
6._部分例子
7._正則表達式匹配規則
7.1_基本模式匹配
7.2_字符簇
7.3_確定重復出現