關於 XQuery
XQuery 在很多關鍵方面都與 SQL 有所不同,這很大程度上是因為這兩種語言是針對兩種具有不同特征的數據模型而設計的。XML(標准化越來越近了) 文檔包含層次結構,並且有其固有的順序。而基於 SQL 的數據庫管理系統所支持的表格數據結構是平面的(flat),並且是基於集合的;因此,行之間不存在順序。
這兩種數據模型的不同導致它們各自的查詢語言有很多基本的不同。例如,XQuery 支持路徑表達式,以允許程序員在 xml(標准化越來越近了) 的層次結構中導航,而純 SQL(沒有 xml(標准化越來越近了) 擴展)則不支持。XQuery 支持有類型的和無類型的數據,而 SQL 數據總是以指定類型定義的。XQuery 沒有 null 值,因為 xml(標准化越來越近了) 文檔會忽略缺失的或未知的數據。當然,SQL 使用 null 來表示缺失的或未知的數據值。XQuery 返回一系列的 XML(標准化越來越近了) 數據,而 SQL 則返回各種 SQL 數據類型的結果集。
這只是 XQuery 和 SQL 之間的基本不同點中的一部分。提供一份詳盡的列表超出了本文的范圍,不過即將發表的 IBM Systems Journal 將更詳細地討論這些語言的不同。現在我們就探索一下 XQuery 語言的一些基本方面,並看看如何使用它來查詢 DB2 Viper 中的 XML(標准化越來越近了) 數據。
樣本數據庫
本文中的查詢訪問在 “DB2 Viper 快速入門”(developerWorks,2006 年 4 月)中創建的樣本表。清單 1 給出了樣本數據庫中 “items” 和 “clIEnts” 表的定義:
清單 1. 表定義
create table items (
id int Prima(最完善的虛擬主機管理系統)ry key not null,
brandname varchar(30),
itemname varchar(30),
sku int,
srp decimal(7,2),
comments XML(標准化越來越近了)
)
create table clIEnts(
id int Prima(最完善的虛擬主機管理系統)ry key not null,
name varchar(50),
status varchar(10),
contactinfo XML(標准化越來越近了)
)
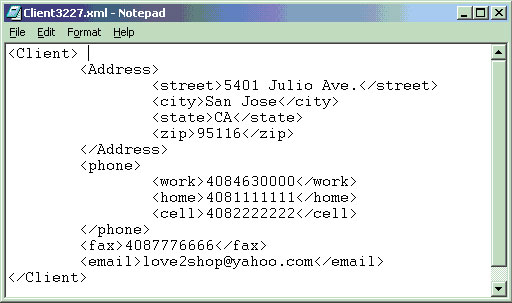
圖 1 中顯示了 “items.comments” 列中包含的樣本 xml(標准化越來越近了) 數據,而 圖 2 中則顯示了 “clIEnts.contactinfo” 列中包含的樣本 xml(標准化越來越近了) 數據。隨後的例子查詢將引用這兩個 XML(標准化越來越近了) 文檔中的一個或兩個中的特定元素。
圖 1. 存儲在 “items” 表的 “comments” 列中的樣本 XML(標准化越來越近了) 文檔
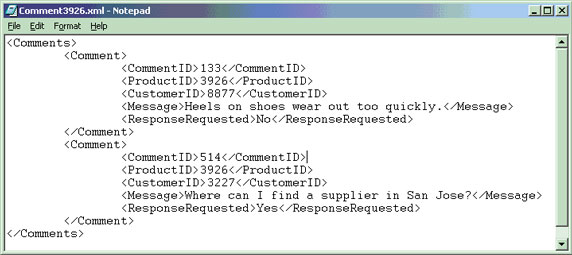
圖 2. 存儲在 “clIEnts” 表的 “contactinfo” 列中的樣本 XML(標准化越來越近了) 文檔
查詢環境
本文中的所有查詢都是通過交互方式發出的。這可以通過 DB2 命令行處理器或 DB2 Control Center 的 DB2 Command Editor 來完成。本文中的屏幕圖像和說明主要使用後一種方式。(DB2 Viper 還附帶了一個基於 Eclipse 的 Developer Workbench,它可以幫助程序員以圖形化的方式構造查詢。本文不討論應用程序開發問題和 Developer Workbench。)
要使用 DB2 Command Editor,啟動 Control Center,並選擇 Tools -> Command Editor。這時將出現如 圖 3 所示的窗口。在上面的面板中輸入查詢,單擊左上角的綠色箭頭運行該查詢,然後可以在下面的面板中或者在 “Query Results” 選項卡中查看輸出。
圖 3. DB2 Command Editor,可以從 DB2 Control Center 中啟動
XQuery 例子
與在 “用 SQL 查詢 DB2 xml(標准化越來越近了) 數據” 中一樣,本文將逐步講解一些常見的業務場景,並展示如何使用 XQuery 來滿足對 XML(標准化越來越近了) 數據的請求。本文還探索了需要將 SQL 嵌入在 XQuery 中的更復雜的情景。
XQuery 提供了一些不同類型的表達式,這些表達式可以隨意組合。每個表達式返回一系列的值,這些值又可以作為其他表達式的輸入。最外面的表達式的結果就是查詢的結果。
本文主要討論兩種重要的 XQuery 表達式:“FLWOR” 表達式和路徑表達式。FLWOR 表達式非常像 SQL 中的 SELECT-FROM-WHERE 表達式 —— 它用於對由多項組成的一個列表進行迭代,並且可以選擇返回通過在每一項上進行計算得到的值。而路徑表達式則可以在分層的 XML(標准化越來越近了) 元素之間進行導航,並返回在路徑末端找到的元素。
與 SQL 中的 SELECT-FROM-WHERE 表達式類似,XQuery FLWOR 表達式可以包含數個以某個關鍵詞開頭的子句。在 FLWOR 表達式中,有以下用於作為子句開頭的關鍵字:
- for:對輸入序列進行迭代,依次將一個變量綁定到每個輸入項
- let:聲明一個變量並為之賦值,可能是一個包含多項的列表
- where:指定過濾查詢結果的標准
- order by:指定結果的排序順序
- return:定義所返回的結果
XQuery 中的路徑表達式由一系列的 “步(step)” 組成,之間以斜槓隔開。在最簡單的形式中,每一步在 xml(標准化越來越近了) 層次中向下導航,以發現由前一步返回的元素的孩子。路徑表達式中的每一步還可以包含一個謂詞,用於過濾該步返回的元素,只保留滿足某種條件的元素。例如,假設變量 $clients 被綁定到包含 <ClIEnt> 元素的 XML(標准化越來越近了) 文檔的一個列表,則 4 步路徑表達式 $clients/ClIEnt/Address[state = "CA"]/zip 將返回居住在加利福尼亞的客戶的郵政編碼。
在很多情況下,可以任意使用 FLWOR 表達式或路徑表達式編寫查詢。
使用 DB2 XQuery 作為頂層查詢語言
要在 DB2 Viper 中直接執行 XQuery(而不是將它嵌入在 SQL 語句中),必須以關鍵字 xquery 作為查詢的開頭。這個關鍵字將指示 DB2 調用它的 XQuery 解析器來處理請求。注意,只有在使用 XQuery 作為最外層(頂層)語言的時候才需要這麼做。如果是將 XQuery 表達式嵌入在 SQL 中,則不需要在語句之前加上 xquery 關鍵字。但是,本文使用 XQuery 作為基本語言,因此所有查詢之前都加上 xquery。
當 XQuery 被作為頂層語言時,它需要一個輸入數據的源。XQuery 獲得輸入數據的一種方式是調用一個名為 db2-fn:xml(標准化越來越近了)column 的函數,調用時帶一個參數,表明 DB2 表中 xml(標准化越來越近了) 列所在的表名和該列的列名。db2-fn:xml(標准化越來越近了)column 函數返回存儲在給定列中的一系列的 xml(標准化越來越近了) 文檔。例如,下面的查詢返回一系列包含客戶聯系方式信息的 XML(標准化越來越近了) 文檔:
清單 2. 返回客戶聯系方式數據的簡單 XQuery
xquery db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')
您可能還記得,在我們的數據庫模式中(參見 “樣本數據庫” 小節),我們將那些 XML(標准化越來越近了) 文檔存儲在 “clIEnts” 表的 “contactinfo” 列中。注意,這裡的列名和表名是大寫的。這是因為表名和列名在被寫入到 DB2 的內部編目之前通常要換成大寫形式。由於 XQuery 是大小寫敏感的,因此小寫的表名和列名不能與 DB2 編目中的大寫名稱相匹配。
檢索特定的 XML(標准化越來越近了) 元素
首先我們來看一個基本的任務。假設您要檢索所有提供了有關傳真信息的客戶的傳真號。清單 3 給出了編寫該查詢的一種方式:
清單 3. 檢索客戶傳真數據的 FLWOR 表達式
xquery
for $y in db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt/fax
return $y
第一行指示 DB2 調用它的 XQuery 解析器。接下來的一行指示 DB2 對包含在 CLIENTS.CONTACTINFO 列中的 ClIEnt 元素的 fax 子元素進行迭代。每個 fax 元素被依次與變量 $y 綁定。第三行指出在每次迭代中返回 $y 的值。結果為一系列的 XML(標准化越來越近了) 元素,如 清單 4 所示:
清單 4. 上述查詢的示例輸出
<fax>4081112222</fax>
<fax>5559998888</fax>
隨便提一下,這裡的輸出還將包含與本文關系不大的一些信息:xml(標准化越來越近了) 版本和編碼數據,例如 <?xml(標准化越來越近了) version="1.0" encoding="Windows-1252" ?>,以及 xml(標准化越來越近了) 名稱空間信息,例如 <fax xml(標准化越來越近了)ns:xsi="http://www.w3.org/2001/xml(標准化越來越近了)Schema-instance">。為了使輸出更簡單,本文省略了這些信息。然而,對於很多 xml(標准化越來越近了) 應用程序來說這些信息可能很重要。如果使用 DB2 命令行處理器來運行查詢,那麼可以使用 -d 選項來省略 XML(標准化越來越近了) 聲明信息,還可以使用 -i 選項以一種美觀的方式打印結果。
清單 3 中顯示的查詢也可以用一種更簡單的三步路徑表達式來表達,如 清單 5 所示:
清單 5. 檢索客戶傳真數據的路徑表達式
xquery
db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt/fax
路徑表達式的第一步調用 db2-fn:xml(標准化越來越近了)column 函數從 CLIENTS 表的 CONTACTINFO 列獲得一個 XML(標准化越來越近了) 文檔的列表。第二步返回這些文檔中的所有 Client 元素,第三步則返回嵌入在這些 ClIEnt 元素中的 fax 元素。
如果您無興趣通過查詢獲得 xml(標准化越來越近了) 片段,而只想要符合條件的 XML(標准化越來越近了) 元素值的文本表示,那麼可以在 return 子句中調用 text() 函數,如 清單 6 所示:
清單 6. 兩個用於檢索客戶傳真數據的文本表示的查詢
xquery
for $y in db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt/fax
return $y/text()
(or)
xquery
db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt/fax/text()
上述查詢的輸出如 清單 7 所示:
清單 7. 上述查詢的示例輸出
4081112222
5559998888
這些示例查詢的結果都相當簡單,因為 fax 元素是基於基本數據類型的。當然,元素也可能基於復雜的數據類型 —— 即包含子元素(或嵌套層次結構)。例如客戶聯系方式信息中的 Address 元素就是這樣。根據 “DB2 Viper 快速入門”(developerWorks,2006 年 4 月)中定義的模式,該元素包含街道地址、門牌號、所在城市、州、國家以及郵政編碼。考慮清單 8 中的 XQuery 將返回什麼結果:
清單 8. 檢索復雜 XML(標准化越來越近了) 類型的 FLWOR 表達式
xquery
for $y in db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt/Address
return $y
如果您猜到返回的結果是包含 Address 元素及其所有子元素的一系列的 XML(標准化越來越近了) 片段,那就對了。清單 9 給出了一個例子:
清單 9. 上述查詢的示例輸出
<Address>
<street>5401 Julio Ave.</street>
<city>San Jose</city>
<state>CA</state>
<zip>95116</zip>
</Address>
. . .
<Address>
<street>1204 Meridian Ave.</street>
<apt>4A</apt>
<city>San Jose</city>
<state>CA</state>
<zip>95124</zip>
</Address>
注意: 為了易於閱讀,這裡的示例輸出作了格式上的調整。DB2 Command Editor 是在一行中顯示每個客戶地址記錄的。
過濾 XML(標准化越來越近了) 元素值
您可以修改上述 XQuery 例子,縮小選擇范圍。例如,我們來看看如何返回居住在郵政編碼為 95116 的地區的所有客戶的郵遞地址。
與您想像的一樣,通過 XQuery where 子句可以根據 XML(標准化越來越近了) 文檔中 zip 元素的值來過濾結果。清單 10 說明了如何在 清單 8 中的 FLWOR 表達式中添加一個 where 子句,以獲得您感興趣的地址信息:
清單 10. 帶有 “where” 子句的 FLWOR 表達式
xquery
for $y in db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt/Address
where $y/zip="95116"
return $y
這裡添加的 where 子句很容易理解。for 子句依次將變量 $y 綁定到每個地址。where 子句包含一個小型的路徑表達式,該表達式從每個地址向下定位到其內嵌的 zip 元素。只有當這個 zip 元素等於 95116 時,where 子句才為 true(相應的地址被保留)。
通過在路徑表達式中添加一個謂詞也可以得到相同的結果,如 清單 11 所示:
清單 11. 帶附加過濾謂詞的路徑表達式
xquery
db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt/Address[zip="95116"]
當然,您可以根據郵政編碼的值進行過濾,返回與街道地址無關的元素。而且,還可以在單個查詢中根據多個 XML(標准化越來越近了) 元素值進行過濾。下面的查詢返回居住在紐約市具有特定郵政編碼(10011)的地區或聖何塞(San Jose)任何地方的客戶的電子郵件信息。
清單 12. 在 FLWOR 表達式中根據多個 XML(標准化越來越近了) 元素值過濾
xquery
for $y in db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt
where $y/Address/zip="10011" or $y/Address/city="San Jose"
return $y/email
注意,我們更改了 for 子句,從而將變量 $y 綁定到 Client 元素,而不是綁定到 Address 元素。這樣一來便可以根據 ClIEnt 元素的一部分子樹(Address)過濾該元素,而返回另一部分子樹(email)。where 子句和 return 子句中的路徑表達式必須相對被綁定到變量(這裡是 $y)的元素來編寫。
通過路徑表達式可以更簡單地表達相同的查詢:
清單 13. 使用路徑表達式根據多個 XML(標准化越來越近了) 元素值進行過濾
xquery
db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt[Address/zip="10011"
or Address/city="San Jose"]/email;
仔細觀察該查詢的兩種不同形式,其中比較隱蔽的一點是,與 SQL 程序員的預期相比,返回的結果在兩個方面存在不同之處:
- 返回的結果中不包含那些符合條件但是沒有提供電子郵件地址的客戶的 XML(標准化越來越近了) 數據。換句話說,如果有 1000 個客戶居住在聖河塞或郵政編碼為 10011 的地區,其中有 700 個客戶提供了電子郵件地址,那麼返回的將是這 700 個電子郵件地址。這是由於前面提到的 XQuery 與 SQL 之間存在的基本差異 —— XQuery 不使用 null。
- 您無法知道哪些電子郵件地址來自同一個 XML(標准化越來越近了) 文檔。換句話說,如果有 700 個居住在聖河塞或郵政編碼為 10011 的地區的客戶,並且每個客戶提供了兩個電子郵件地址,那麼返回的結果是 1400 個 email 元素組成的列表。您得到的不是 一個包含 700 個記錄、每個記錄由兩個電子郵件地址組成的序列。
這兩點在某些情況下是可以的,在另外一些情況下又可能不可取。例如,如果需要通過電子郵件將一個通知發送給每個符合條件的有記錄的帳戶,那麼很容易在應用程序中對 XML(標准化越來越近了) 格式的客戶電子郵件地址列表進行迭代。然而,如果對每個客戶只發送一次通知,包括那些沒有提供街道地址的客戶,那麼上述 XQuery 就不能滿足要求了。
有多種方法來修改這個查詢,使返回的結果以某種方式表示缺失的信息,並且在有多個電子郵件地址來自相同客戶記錄(即相同的 XML(標准化越來越近了) 文檔)的情況下作出說明。讓我們簡要地探索一下其中一種方法。不過,如果只是要檢索一個列表,其中對於每個符合條件的客戶包含一個電子郵件地址,那麼只需對之前查詢中的 return 子句略作修改:
清單 14. 只檢索每個客戶的第一個 email 元素
xquery
for $y in db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt
where $y/Address/zip="10011" or $y/Address/city="San Jose"
return $y/email[1]
該查詢導致 DB2 返回它在每個符合條件的 XML(標准化越來越近了) 文檔(客戶聯系方式記錄)中找到的第一個電子郵件元素。如果對於一個符合條件的客戶,DB2 沒有找到電子郵件地址,那麼對於這個客戶就不返回任何信息。
轉換 XML(標准化越來越近了) 輸出
XQuery 的一個強大的方面是可以將 xml(標准化越來越近了) 輸出從一種格式轉換成另一種格式。例如,可以使用 XQuery 檢索所有或部分存儲的 xml(標准化越來越近了) 文檔,並將輸出轉換成 HTML,以便在 Web 浏覽器中顯示。下面 清單 15 中的查詢檢索客戶的地址,按照郵政編碼對結果排序,並將輸出轉換成 XML(標准化越來越近了) 元素,作為一個無序的 Html 列表中的一部分:
清單 15. 查詢 DB2 XML(標准化越來越近了) 數據並以 Html 格式返回結果
xquery
<ul> {
for $y in db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt/Address
order by $y/zip
return <li>{$y}</li>
} </ul>
該查詢首先以 xquery 關鍵字開頭,告訴 DB2 解析器 XQuery 是頂層語言。第二行將表示無序列表的 Html 標記(<ul>)包括在結果中。它還包含本查詢中使用的一對花括號中的左括號。花括號指示 DB2 計算和處理其中的表達式,而不是將其當作文字字符串。
第三行對客戶地址進行迭代,依次將變量 $y 綁定到每個 address 元素。第四行包括一個新的 order by 子句,指出結果必須按照客戶郵政編碼(綁定到 $y 的每個 address 元素的 zip 子元素)升序排列。return 子句表明 Address 元素在返回之前要用 HTML 列表 item 標記括起來。最後一行結束查詢,並結束 Html 無序列表標記。
輸出將類似 清單 16 所示:
清單 16. 上述查詢的示例 Html 輸出
<ul>
<li>
<Address>
<street>9407 Los Gatos Blvd.</street>
<city>Los Gatos</city>
<state>CA</state>
<zip>95032</zip>
</Address>
</li>
<li>
<Address>
<street>4209 El Camino Real</street>
<city>Mountain VIEw</city>
<state>CA</state>
<zip>95033</zip>
</Address>
</li>
. . .
</ul>
我們來考慮之前遇到的一個話題:當需要在返回結果中表明缺失的值,以及表明單個 xml(標准化越來越近了) 文檔(例如單個客戶記錄)包含重復的元素(例如多個 email 地址)時,如何編寫 XQuery。一種方法是將返回的輸出封裝在一個新的 XML(標准化越來越近了) 元素中,如下面 清單 17 中的查詢所示:
清單 17. 在 XQuery 結果中表明缺失的值和重復的元素
xquery
for $y in db2-fn:XML(標准化越來越近了)column('CLIENTS.CONTACTINFO')/ClIEnt
where $y/Address[zip="10011"] or $y/Address[city="San Jose"]
return <emailList> {$y/email} </emailList>
該查詢將返回一個 “emailList” 元素序列,每個符合條件的客戶記錄對應一個元素。每個 emailList 元素將包含 e-mail 數據。如果 DB2 在客戶的記錄中只發現一個 e-mail 地址,它將返回那個元素和它的值。如果 DB2 發現多個 e-mail 地址,它將返回所有 e-mail 元素和它們的值。最後,如果 DB2 沒有發現 e-mail 地址,那麼它將返回一個空的 emailList 元素。因此,輸出如下所示:
清單 18. 上述查詢的示例輸出
<emailList>
<email>
[email protected]</email>
</emailList>
<emailList/>
<emailList>
<email>
[email protected]</email>
<email>
[email protected]</email>
</emailList>
. . .
使用條件邏輯 XQuery 的 xml(標准化越來越近了) 輸出轉換功能可以與它內置的對條件邏輯的支持相結合,以減少應用程序代碼的復雜性。“items” 表中包括一個 XML(標准化越來越近了) 列,該列包含客戶對產品作出的評論。有些客戶要求對他們的評論作出響應,對於這些用戶,需要創建新的 “action” 元素,其中包含產品 ID、客戶 ID 和評語,以便將這些信息發送給適當的個人進行處理。但是,那些不要求響應的評論在商業上也是非常重要的信息,您不想忽視它們。所以,創建一個 “info” 元素,其中只包含產品 ID 和評語。下面展示了如何使用 XQuery if-then-else 表達式來完成這項任務:
清單 19. 在 XQuery 中使用 “if-then-else” 表達式
xquery
for $y in db2-fn:XML(標准化越來越近了)column('ITEMS.COMMENTS')/Comments/Comment
return (
if ($y/ResponseRequested = 'Yes')
then <action>
{$y/ProductID,
$y/CustomerID,
$y/Message}
</action>
else ( <info>
{$y/ProductID,
$y/Message}
</info>
)
)
現在您應該對這個查詢的大部分感到熟悉,所以我們只關注條件邏輯。if 子句判斷一條給定評論的 ResponseRequested 子元素的值是否等於 “Yes”。如果是,那麼執行 then 子句,導致 DB2 返回一個新元素(“action”),其中包含三個子元素:ProductID、CustomerID 和 Message。否則,執行 else 子句,DB2 返回一個 “info” 元素,其中只包含產品 ID 和評語數據。
使用 “let” 子句 您已經看到了如何使用 FLWOR 表達式的所有部分,除了一個部分:let 子句。該子句用於將一個值(可能包含一個由多項組成的列表)賦給一個變量,這個變量可以在 FLWOR 表達式的其他子句中使用。
假設您想得到一份列表,統計出每種產品收到的評論數量。那麼可以使用以下查詢:
清單 20. 使用 “let” 子句
xquery
for $p in distinct-values
(db2-fn:XML(標准化越來越近了)column('ITEMS.COMMENTS')/Comments/Comment/ProductID)
let $pc := db2-fn:XML(標准化越來越近了)column('ITEMS.COMMENTS')
/Comments/Comment[ProductID = $p]
return
<product>
<id> { $p } </id>
<comments> { count($pc) } </comments>
</product>
for 子句中的 distinct-values 函數返回一個列表,其中包含在 ITEMS 表的 COMMENTS 列中的所有 Comment 中發現的所有不同的 ProductID 值。for 子句依次將變量 $p 綁定到每個 ProductID 值。對於 $p 的每個值,let 子句再次掃描 ITEMS 列,並將變量 $pc 綁定到一個列表,列表中包含所有 ProductID 與 $p 中的 ProductID 相匹配的評論。return 子句為每個不同的 ProductID 值構造一個新的 “product” 元素。每個 “product” 元素包含兩個子元素:一個包含 ProductID 值的 “id” 元素,和一個包含給定產品上所收到的評論的數量的 “comments” 元素。
這個例子查詢的結果如下:
清單 21. 上述查詢的示例輸出
<product>
<id>3926</id>
<comments>28</comments>
</product>
<product>
<id>4097</id>
<comments>13</comments>
</product>
帶嵌入式 SQL 的 XQuerIEs
至此,您已經看到了如何編寫 XQuery 來檢索 xml(標准化越來越近了) 文檔片段,創建新格式的 xml(標准化越來越近了) 輸出,以及根據查詢中指定的條件返回不同的輸出。簡言之,您已經學會了使用 XQuery 查詢存儲在 DB2 中的 XML(標准化越來越近了) 數據的幾種方法。
顯然,除了本文介紹的內容外,關於 XQuery 還有更多要學的東西。但是我們不能忽略了我們還沒有講到的一個大話題:如何在 XQuery 中嵌入 SQL。如果需要編寫根據 xml(標准化越來越近了) 和非 XML(標准化越來越近了) 列的值過濾數據的查詢,那麼這樣做很有用。
您可能還記得,文章 “用 SQL 查詢 DB2 xml(標准化越來越近了) 數據” 描述了如何將簡單的 XQuery 表達式嵌入在 SQL 語句中,以便完成這樣的任務。這裡,我們來看看如何反過來做:將 SQL 嵌入在 XQuery 中,從而根據傳統的 SQL 數據值和特定的 XML(標准化越來越近了) 元素值對結果進行限制。
您可以使用 db2-fn:sqlquery 函數替代 db2-fn:xml(標准化越來越近了)column 函數,後者返回一個表的一個列中所有 xml(標准化越來越近了) 數據,而前者執行一個 SQL 查詢,並且只返回所選擇的數據。傳遞給 db2-fn:sqlquery 函數的 SQL 查詢必須返回 xml(標准化越來越近了) 數據。然後 XQuery 可以進一步處理這種 XML(標准化越來越近了) 數據。
清單 22 中的查詢檢索關於評論的信息,評論所涉及的產品是建議零售價("srp")大於 $100 的產品,並且在評論中客戶請求響應。您應該記得,價格數據存儲在一個十進制數類型的 SQL 列中,而客戶評論則存儲為 XML(標准化越來越近了)。對於存儲在數據庫中的每條符合條件的評論,返回的數據(包括產品 ID、客戶 ID 和客戶評論)被包括在一個 XML(標准化越來越近了) “action” 元素中。
清單 22. 將 SQL 嵌入在 XQuery 中
xquery
for $y in
db2-fn:sqlquery('select comments from items where srp > 100')/Comments/Comment
where $y/ResponseRequested="Yes"
return (
<action>
{$y/ProductID,
$y/CustomerID,
$y/Message}
</action>
)
同樣,這個查詢的大部分對於您來說應該比較熟悉了,所以我們只關注這裡出現的新函數:db2-fn:sqlquery。DB2 處理提供給該函數的 SQL SELECT 語句,以確定哪些行包含關於定價超過 $100 的產品的信息。存儲在這些行中的文檔作為一個路徑表達式的輸出,該路徑表達式返回所有內嵌的 Comment 元素。該查詢中隨後的部分使用 XQuery where 子句進一步過濾返回的數據,並將選中的評論的一些部分轉換成新的 XML(標准化越來越近了) 片段。
清楚這些之後,讓我們考慮如何解決一個稍微不同的問題。假設您需要一份列表,其中包含居住在聖河塞的 “Gold” 客戶的所有 e-mail 地址。而且,如果一個客戶有多個 e-mail 地址,那麼您希望將這些 e-mail 地址都包括在輸出中,作為單個客戶記錄的一部分。最後,如果某個符合條件的 “Gold” 客戶沒有提供 e-mail 地址,那麼需要檢索他或她的郵遞地址。清單 23 展示了編寫該查詢的一種方法:
清單 23. 將 SQL 嵌入在包含條件邏輯的 XQuery 中
xquery
for $y in
db2-fn:sqlquery('select contactinfo from clients where status=''Gold'' ')/ClIEnt
where $y/Address/city="San Jose"
return (
if ($y/email) then <emailList>{$y/email}</emailList>
else $y/Address
)
這個查詢有兩個方面要解釋一下。首先,嵌入在第二行的 SELECT 語句包含一個基於 “status” 列的查詢謂詞,它將這個 VARCHAR 列與字符串 "Gold" 相比較。在 SQL 中,這樣的字符串放在單引號裡面。注意,雖然這個例子看上去使用了雙引號,但實際上它是在比較值("Gold")前後使用了兩個單引號。“額外” 的那個單引號是換碼符。如果在基於字符串的查詢謂詞周圍使用雙引號,而不是單引號,就會收到語法錯誤。
此外,這個查詢中的 return 子句包含一個條件邏輯,用於判斷給定客戶的記錄中是否存在 e-mail 元素。如果存在,那麼該查詢將返回一個新的 “emailList” 元素,其中包含客戶的所有 e-mail 地址(也就是那個客戶的所有 e-mail 元素)。如果不存在,那麼該查詢將返回客戶的郵遞地址(也就是那個客戶的 Address 元素)。
索引
最後,值得注意的是,您可以專門創建 xml(標准化越來越近了) 索引來加快對存儲在 XML(標准化越來越近了) 列中的數據的訪問速度。由於本文只是一篇介紹性的文章,而且樣本數據偏小,因此這裡不打算就此話題展開討論。但是在生產環境中,定義適當的索引對於取得最佳性能是非常關鍵的。請參閱 參考資料 了解關於 DB2 新的索引技術的更多信息。
結束語 XQuery 與 SQL 之間有一些很大的不同點,本文談到了其中的一些不同點。了解更多關於該語言的知識將有助於判斷該語言在什麼情況下對您的工作最有好處,並且有助於理解在什麼情況下將 XQuery 與 SQL 相結合會比較有用。在將來的文章中,我們將深入研究另一個有趣的話題:如何開發利用 DB2 XML(標准化越來越近了) 功能的 Java 應用程序。本文提供了一個 簡單的 Java 例子,其中描述了如何在 Java 應用程序中嵌入 XQuery。