雖然 DB2 的混合體系結構與之前的版本有很大的不同,但是要利用它的新 xml(標准化越來越近了) 功能並不難。如果您已經熟悉 SQL,那麼很快就可以將這方面的技能轉化到對存儲在 DB2 中的本地 XML(標准化越來越近了) 數據的處理上。通過本文就可以知道如何實現這一點。
DB2 Viper(就是DB2 9)中的 xml(標准化越來越近了) 特性包括新的存儲管理、新的索引技術以及對查詢語言的支持。在本文中,學習如何使用 SQL 或帶 xml(標准化越來越近了) 擴展的 SQL(SQL/xml(標准化越來越近了))查詢 DB2 XML(標准化越來越近了) 列中的數據。接下來的文章將討論 DB2 中新引入的對新興的業界標准 XQuery 的支持,並探索 XQuery 在什麼時候最有用。
您也許會感到驚訝,DB2 還支持雙語查詢 —— 即組合了來自 SQL 和 XQuery 的表達式的查詢。至於應該使用哪種語言(或兩種語言結合使用)取決於應用程序的需要,同時也取決於您本身所掌握的技能。其實,將兩種查詢語言中的元素組合到一個查詢中並沒有您想像的那麼難。這樣做還可以為搜索和集成傳統 SQL 和 XML(標准化越來越近了) 數據提供強大的能力。
Sample 數據庫
本文中的查詢將訪問在 “DB2 Viper 快速入門”(developerWorks,2006 年 4 月)中創建的 sample 數據庫。這裡我們簡短地回顧一下,sample 數據庫中 "items" 和 "clIEnts" 表的定義:
清單 1. 表的定義
create table items (
id int Prima(最完善的虛擬主機管理系統)ry key not null,
brandname varchar(30),
itemname varchar(30),
sku int,
srp decimal(7,2),
comments XML(標准化越來越近了)
)
create table clIEnts(
id int Prima(最完善的虛擬主機管理系統)ry key not null,
name varchar(50),
status varchar(10),
contactinfo XML(標准化越來越近了)
)
圖 1 顯示了 "items.comments" 列中的示例 xml(標准化越來越近了) 數據,圖 2 顯示了 "clIEnts.contactinfo" 列中的示例 xml(標准化越來越近了) 數據。隨後的查詢例子將引用其中某個 XML(標准化越來越近了) 文檔或這兩個文檔中某些特定的元素。
圖 1. 存儲在 "items" 表 "comments" 列的示例 XML(標准化越來越近了) 文檔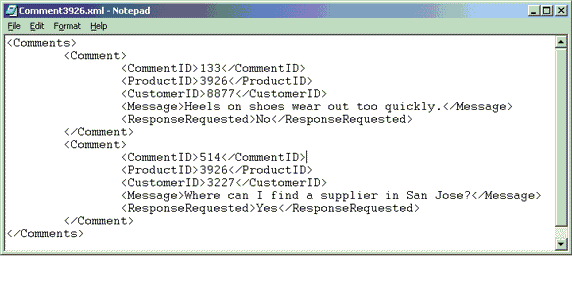
查詢環境
本文中的所有查詢都是交互式地發出的,您可以通過 DB2 命令行處理器或 DB2 Control Center 中的 DB2 Command Editor 發出查詢。本文中的屏幕圖像和說明主要基於後一種方式。(DB2 Viper 還附帶了一個基於 Eclipse 的 Developer Workbench,它可以幫助程序員圖形化地構造查詢。但是,本文不討論應用開發問題或 Developer Workbench。)
要使用 DB2 Command Editor,需啟動 Control Center 並選擇 Tools > Command Editor。這時將彈出如 圖 3 所示的窗口。在上面的面板中輸入查詢,單擊左上角的綠色箭頭運行查詢,然後在下面的面板或 "Query results" 標簽頁中查看輸出。
圖 3. DB2 Command Editor,可以從 DB2 Control Center 啟動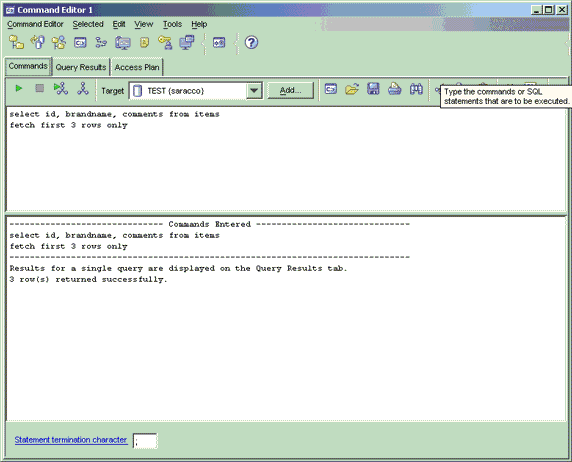
純 SQL 查詢
即使您對 SQL 所知有限,也仍然可以很輕松地查詢 xml(標准化越來越近了) 數據。例如,下面的查詢選擇 "clIEnts" 表中的全部內容,包括存儲在 "contactinfo" 列的 XML(標准化越來越近了) 信息:
清單 2. 簡單的 SELECT 語句
select * from clIEnts
當然也可以編寫更具選擇性的 SQL 查詢,使之包含關系投影和限制操作。下面的查詢檢索所有具有 "Gold" 狀態的客戶的 ID、姓名和聯系方式。請注意,"contactinfo" 列包含 xml(標准化越來越近了) 數據,而其他兩列不包含 XML(標准化越來越近了) 數據:
清單 3. 帶投影和限制的簡單 SELECT 語句
select id, name, contactinfo
from clIEnts
where status = 'Gold'
正如您所預料,您可以基於這樣的查詢創建視圖,下面的 "goldvIEw" 可以說明這一點:
清單 4. 創建包含 XML(標准化越來越近了) 列的視圖
create view goldvIEw as
select id, name, contactinfo
from clIEnts
where status = 'Gold'
不幸的是,很多事情光用 SQL 是無法解決的。通過純 SQL 語句可以檢索整個 xml(標准化越來越近了) 文檔(剛才已證明這一點),但是卻不能指定基於 xml(標准化越來越近了) 的查詢謂詞,也不能檢索 xml(標准化越來越近了) 文檔的某一部分或者 xml(標准化越來越近了) 文檔中特定的元素值。換句話說,使用純 SQL 不能對 xml(標准化越來越近了) 文檔中的片段進行投影、限制、連接、聚集或排序操作。例如,您不能單獨檢索 Gold 客戶的 email 地址或居住在郵政編碼為 "95116" 的地區的客戶的姓名。為了表達這些類型的查詢,需要使用帶 xml(標准化越來越近了) 擴展的 SQL(SQL/XML(標准化越來越近了))、XQuery 或結合使用這兩種查詢語言。
下一節將探討 SQL/XML(標准化越來越近了) 的幾個基本特性。在接下來的文章中,我們將學習如何編寫 XQuery 以及如何將 XQuery 與 SQL 結合使用。
SQL/XML(標准化越來越近了) 查詢
顧名思義,SQL/xml(標准化越來越近了) 被設計用來為 SQL 和 xml(標准化越來越近了) 兩者之間搭一座橋。它首先是 SQL 標准的一部分,經過演化現在包括將 XQuery 或 XPath 表達式嵌入 SQL 語句的規范。XPath 是用於導航 XML(標准化越來越近了) 文檔以便發現元素或屬性的一種語言。XQuery 包括對 XPath 的支持。
請務必注意,XQuery(和 XPath)表達式是大小寫敏感的。例如,引用 xml(標准化越來越近了) 元素 "zip" 的 XQuery 並不適用於名為 "ZIP" 或 "Zip" 的 XML(標准化越來越近了) 元素。SQL 程序員有時候很難記住大小寫敏感這一點,因為 SQL 查詢語法允許使用 "zip"、"ZIP" 和 "Zip" 來引用同一個列名。
DB2 Viper 提供了超過 15 個 SQL/xml(標准化越來越近了) 函數,通過這些函數可以搜索 xml(標准化越來越近了) 文檔中的特定數據,將傳統數據轉換成 xml(標准化越來越近了),將 xml(標准化越來越近了) 數據轉換成關系數據,以及執行其他有用的任務。本文不討論 SQL/xml(標准化越來越近了) 的所有方面,而只是談到幾種常見的查詢挑戰,以及一些關鍵的 SQL/XML(標准化越來越近了) 函數如何解決這些挑戰。
根據 XML(標准化越來越近了) 元素值 “限制” 結果
SQL 程序員常常編寫根據某種條件限制從 DBMS 返回的行的查詢。例如,清單 3 中的 SQL 查詢限制從 "clIEnts" 表中檢索的行,使之只包括那些具有 "Gold" 狀態的客戶。在這個例子中,客戶的狀態可在 SQL VARCHAR 列中捕捉。但是,如果您想根據某種應用於 xml(標准化越來越近了) 列中數據的條件對搜索進行限制,那麼應該怎麼做呢?SQL/xml(標准化越來越近了) 的 XML(標准化越來越近了)Exists 函數為完成該任務提供了一種手段。
通過 xml(標准化越來越近了)Exists 可以在 xml(標准化越來越近了) 文檔中找到一個元素,並測試它是否滿足某個特定的條件。如果用在 WHERE 子句中,則 xml(標准化越來越近了)Exists 可以限制返回的結果,使之只包括那些包含具有特定 xml(標准化越來越近了) 元素值的 XML(標准化越來越近了) 文檔的行(換句話說,指定的值等於 "true")。
讓我們看看早先遇到的一個查詢問題。假如您想找到居住在具有特定郵政編碼的地區的所有客戶的姓名。您也許還記得,"clIEnts" 表的一個 xml(標准化越來越近了) 列中存儲了客戶的地址(包括郵政編碼)。(見 圖 2。)通過使用 xml(標准化越來越近了)Exists,可以從 xml(標准化越來越近了) 列中搜索目標郵政編碼,並相應地限制返回的結果集。下面的 SQL/XML(標准化越來越近了) 查詢返回居住在郵政編碼為 95116 的地區的客戶的姓名:
清單 5. 根據 XML(標准化越來越近了) 元素值限制結果
select name from clIEnts
where XML(標准化越來越近了)exists('$c/ClIEnt/Address[zip="95116"]'
passing clIEnts.contactinfo as "c")
第一行是一個 SQL 子句,指定僅檢索 "clients" 表 "name" 列中的信息。WHERE 子句調用 xml(標准化越來越近了)Exists 函數,指定一個 XPath 表達式,這個表達式使 DB2 找到 "zip" 元素並檢查元素值是否為 95116。"$c/Client/Address" 子句表明 DB2 用於定位 "zip" 元素的 xml(標准化越來越近了) 文檔層次結構中的路徑。通過使用可以從節點 "$c"(稍後將會解釋)訪問的數據,DB2 將從 "Client" 元素中找到它的子元素 "Address",以便檢查郵政編碼("zip" 值)。最後一行決定 "$c" 的值:它是 "clients" 表的 "contactinfo" 列。因此,DB2 檢查 "contactinfo" 列中的 xml(標准化越來越近了) 數據,從根元素 "ClIEnt" 深入到 "Address" 子元素再找到 "zip" 子元素,然後判斷客戶是否居住在目標地區。如果客戶住在目標地區,則 XML(標准化越來越近了)Exists 函數的返回值為 "true",DB2 將返回與那一行相關的客戶的姓名。
在使用 XML(標准化越來越近了)Exists 查詢謂詞時經常會出現一個錯誤,如 清單 6 所示。
清單 6. 根據 XML(標准化越來越近了) 元素值限制結果時采用的不正確語法
select name from clIEnts
where XML(標准化越來越近了)exists('$c/ClIEnt/Address/zip="95116" '
passing clIEnts.contactinfo as "c")
雖然這個查詢也可以成功地執行,但是它不能限制結果,使之僅包含居住在郵政編碼為 95116 的地區的客戶。(這是由於標准中規定的語義造成的,而且這並不是 DB2 所特有的。)為了限制結果,使之僅包含居住在郵政編碼為 95116 的地區的客戶,需要使用前面 清單 5 中展示的語法。
您可能很想知道如何在應用程序中包括限制 XML(標准化越來越近了) 數據的查詢。雖然本文不詳細討論應用開發話題,但還是提供了一個 簡單的 Java 例子,這個例子在一條 SQL/XML(標准化越來越近了) 語句中使用一個參數標記位將輸出限制為居住在給定地區的客戶的信息。
“投影” XML(標准化越來越近了) 元素值
現在讓我們考慮一種稍微有些不同的情景,假設您想將 xml(標准化越來越近了) 值投影到返回的結果集。換句話說,我們要從 xml(標准化越來越近了) 文檔中檢索一個或多個元素值。有很多方法可以做這件事。首先我們使用 xml(標准化越來越近了)Query 函數來檢索一個元素的值,然後使用 XML(標准化越來越近了)Table 函數來檢索多個元素的值,然後將這些映射到一個 SQL 結果集的列。
我們來考慮如何解決之前擺在我們面前的一個問題:如何創建一個列出 Gold 客戶的 email 地址的報告。下面 清單 7 中的查詢調用 XML(標准化越來越近了)Query 函數來完成這項任務:
清單 7. 檢索符合條件的客戶的 email 信息
select XML(標准化越來越近了)query('$c/ClIEnt/email'
passing contactinfo as "c")
from clIEnts
where status = 'Gold'
第一行指定要返回根元素 "Client" 的 "email" 子元素的值。第二行和第三行表明 DB2 在哪裡可以找到該信息 —— 在 "clIEnts" 表的 "contactinfo" 列中。第四行進一步限制查詢,表明您只對 Gold 客戶的 email 地址感興趣。這個查詢將返回一組 XML(標准化越來越近了) 元素和值。例如,如果有 500 名 Gold 客戶,每個客戶有一個 email 地址,那麼輸出將是一個單列的結果集,一共有 500 行,如 清單 8 所示:
清單 8. 之前查詢的示例輸出
1
--------------------------------------------
<email>[email protected]</email>
. . .
<email>[email protected]</email>
如果每個 Gold 客戶有多個 email 地址,那麼需要指示 DB2 只返回首要的地址(也就是在客戶的 "contactinfo" 文檔中找到的第一個 email 地址)。為此,可以修改查詢的第一行中的表達式:
清單 9. 檢索每個符合條件的客戶的第一個 email 地址
select XML(標准化越來越近了)query('$c/ClIEnt/email[1]'
passing contactinfo as "c")
from clIEnts
where status = 'Gold'
最後,如果有些 Gold 客戶沒有 email 地址,那麼可能要編寫一個查詢從結果集中排除 null 值。為此可以修改之前的查詢,添加另一個謂詞到 WHERE 中,以測試是否缺少 email 信息。您已經熟悉了一個可以幫您實現這一點的 SQL/xml(標准化越來越近了) 函數 —— 那就是 xml(標准化越來越近了)Exists。清單 10 展示了如何重新編寫之前的查詢,以便過濾掉那些聯系方式(存儲為 XML(標准化越來越近了) 文檔)中缺少 email 地址的 Gold 客戶的行:
清單 10. 對於至少有一個 email 地址的客戶,檢索每個符合條件的客戶的第一個 email 地址
select XML(標准化越來越近了)query('$c/ClIEnt/email[1]'
passing contactinfo as "c")
from clIEnts
where status = 'Gold'
and XML(標准化越來越近了)exists('$c/ClIEnt/email' passing contactinfo as "c")
現在我們考慮一個稍微不同的情景,假設您要檢索多個 xml(標准化越來越近了) 元素值。xml(標准化越來越近了)Table 可以從 xml(標准化越來越近了) 列中的數據生成標量輸出,可以為程序員提供 xml(標准化越來越近了) 數據的 “關系” 視圖,因此非常有用。與 xml(標准化越來越近了)Exists 和 xml(標准化越來越近了)Query 一樣,xml(標准化越來越近了)Table 函數使 DB2 在 xml(標准化越來越近了) 文檔層次結構中定位到感興趣的數據。然而,xml(標准化越來越近了)Table 還包括一些子句,用於將目標 XML(標准化越來越近了) 數據映射到 SQL 數據類型的結果集列。
考慮以下查詢(清單 11),該查詢投影存儲在 "items" 表中的關系數據和 xml(標准化越來越近了) 數據。(關於 "items" 表請查看 圖 1)。評論 ID、客戶 ID 和評語存儲在 "comments" 列中的 XML(標准化越來越近了) 文檔中。商品名稱存儲在一個 SQL VARCHAR 列中。
清單 11. 檢索多個 XML(標准化越來越近了) 元素並將每個元素轉換成傳統的 SQL 數據類型
select t.Comment#, i.itemname, t.CustomerID, Message from items i,
XML(標准化越來越近了)table('$c/Comments/Comment' passing i.comments as "c"
columns Comment# integer path 'CommentID',
CustomerID integer path 'CustomerID',
Message varchar(100) path 'Message') as t
第一行指定將包含在結果集中的列。查詢中後面的幾行表明,用引號括起來、並且以變量 "t" 為前綴的列是基於 xml(標准化越來越近了) 元素值的列。第二行調用 xml(標准化越來越近了)Table 函數指定包含目標數據("i.comments")的 DB2 xml(標准化越來越近了) 列和在該列的 xml(標准化越來越近了) 文檔中的路徑,通過該路徑可以定位感興趣的元素(在根元素 "Comments" 的子元素 "Comment" 中)。第 3 到 5 行的 "columns" 子句標識出將被映射到第一行指定的 SQL 結果集中的輸出列的特定 xml(標准化越來越近了) 元素。這個映射需要指定 xml(標准化越來越近了) 元素值將被轉換成的數據類型。在這個例子中,所有 XML(標准化越來越近了) 數據被轉換成傳統的 SQL 數據類型。
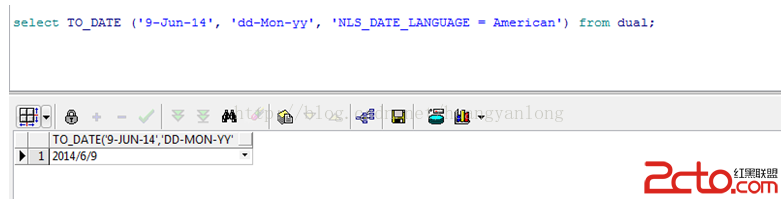
圖 4 展示了運行該查詢得到的示例結果。可以看到,輸出是一個簡單的 SQL 結果集。注意,列名已經被變成大寫形式 —— 這在 SQL 中是很常見的。
圖 4. 使用 XML(標准化越來越近了)Table 函數的查詢的示例輸出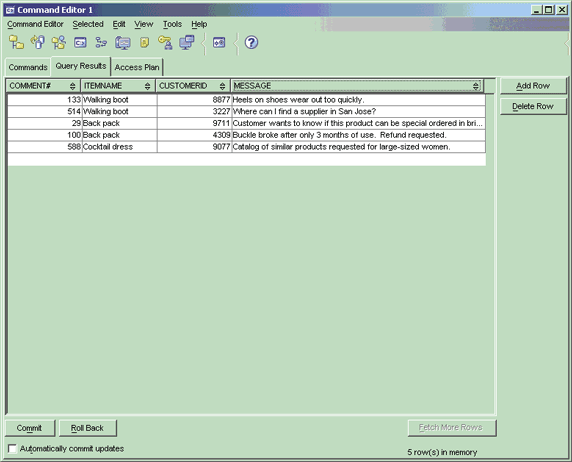
如果需要的話,還可以使用 xml(標准化越來越近了)Table 創建包含 xml(標准化越來越近了) 文檔的結果集。例如,以下語句產生類似於上述結果的結果集,不同的是 "Message" 數據被包含在一個 XML(標准化越來越近了) 列中,而不是包含在一個 SQL VARCHAR 列中。
清單 12. 檢索多個 xml(標准化越來越近了) 元素並將它們轉換成傳統的 SQL 或 XML(標准化越來越近了) 數據類型
select t.Comment#, i.itemname, t.CustomerID, Message from items i,
XML(標准化越來越近了)table('$c/Comments/Comment' passing i.comments as "c"
columns Comment# integer path 'CommentID',
CustomerID integer path 'CustomerID',
Message XML(標准化越來越近了) by ref path 'Message') as t
創建 XML(標准化越來越近了) 數據的關系視圖
正如您可能想像到的那樣,SQL/xml(標准化越來越近了) 函數可用於定義視圖。如果要為 SQL 應用程序的程序員提供本地 XML(標准化越來越近了) 數據的關系模型,那麼這種功能特別有用。
為 xml(標准化越來越近了) 列中的數據創建關系視圖並不比投影 xml(標准化越來越近了) 元素值復雜多少。您只需編寫一個 SQL/xml(標准化越來越近了) SELECT 語句,在語句中調用 xml(標准化越來越近了)Table 函數,並以此作為視圖定義的基礎。下面 清單 13 中的例子基於 "items" 表的 xml(標准化越來越近了) 列和非 XML(標准化越來越近了) 列中的信息創建一個視圖。(這類似於 清單 11 中的查詢。)
清單 13. 基於 XML(標准化越來越近了)Table 的輸出創建視圖
create view commentvIEw(itemID, itemname, commentID, message, mustrespond) as
select i.id, i.itemname, t.CommentID, t.Message, t.ResponseRequested from items i,
XML(標准化越來越近了)table('$c/Comments/Comment' passing i.comments as "c"
columns CommentID integer path 'CommentID',
Message varchar(100) path 'Message',
ResponseRequested varchar(100) path 'ResponseRequested') as t;
雖然在 xml(標准化越來越近了) 列中的數據上創建關系視圖很容易,但是用起來要小心。在對那樣的視圖發出查詢時,DB2 不使用 xml(標准化越來越近了) 列索引。因此,如果以 ResponseRequested 列為索引,並發出一條將 "mustrespond" 列的結果限制為某個特定值的 SQL 查詢,那麼 DB2 將讀取所有的 xml(標准化越來越近了) 文檔,並搜索適當的 "ResponseRequested" 值。除非數據量不大,否則這樣做會降低運行時性能。然而,如果在那些視圖上運行的查詢還包含有嚴格限制性的謂詞,且參與索引的項中有傳統的 SQL 類型的項(在這個例子中可以是 "i.id" 或 "i.itemname"),那麼可以緩解潛在的運行時性能問題。DB2 使用關系索引將符合條件的行過濾到一個較小的量,然後在返回最終結果之前,將更多的 XML(標准化越來越近了) 查詢謂詞應用到這些臨時的結果上。
連接 XML(標准化越來越近了) 數據和關系數據
現在,您可能想知道如何連接 xml(標准化越來越近了) 數據和非 xml(標准化越來越近了) 數據(例如基於傳統 SQL 類型的關系數據)。DB2 使您可以僅用一條 SQL/XML(標准化越來越近了) 語句來做到這一點。有很多方法可用來制定那樣的連接,這取決於數據庫模式和工作負載需求,不過這裡我們只談論一個例子。您也許會感到驚訝,其實您已經知道足夠多關於 SQL/XML(標准化越來越近了) 的東西,完全可以實現這種連接。
還記得嗎,"items" 表中的 xml(標准化越來越近了) 列包含一個 "CustomerID" 元素。這可以作為與 "clIEnts" 表中基於整數的列 "id" 的一個連接鍵。因此,如果要獲得一個報告,其中列出對您的一件或多件產品發表了評論的客戶的姓名和狀態,那麼需要將一個表中的 xml(標准化越來越近了) 元素值與來自另一個表中的 SQL 整數值相連接。實現這一點的一種方法是使用 XML(標准化越來越近了)Exists 函數,如 清單 14 所示:
清單 14. 連接 xml(標准化越來越近了) 數據和非 XML(標准化越來越近了) 數據
select clients.name, clients.status from items, clIEnts
where XML(標准化越來越近了)exists('$c/Comments/Comment[CustomerID=$p]'
passing items.comments as "c", clIEnts.id as "p")
第一行標識出要包括在查詢結果集中的 SQL 列以及查詢中所引用的源表。第二行包括了連接子句。這裡,xml(標准化越來越近了)Exists 決定在一個目標源中的 "CustomerID" 值是否等於來自另一個目標源的值。第三行指定這兩個源:第一個目標源是 "items" 表中的 xml(標准化越來越近了) 列 "comments",第二個目標源是 "clients" 表中的整數列 "id"。因此,如果客戶對任何產品發表了評論,並且 "clIEnts" 表中存在關於該客戶的信息,那麼 XML(標准化越來越近了)Exists 表達式將等於 "true",報告中將包括該客戶的姓名和狀態。
使用 SQL/XML(標准化越來越近了) 中的 "FLWOR" 表達式
雖然我們只討論了幾個函數,其實 SQL/xml(標准化越來越近了) 為查詢 xml(標准化越來越近了) 數據和將 XML(標准化越來越近了) 數據與關系數據集成提供了很多強大的功能。實際上,您已經看到了這方面的一些例子,但是這裡我們還要再討論一些例子。
通過 xml(標准化越來越近了)Exists 和 xml(標准化越來越近了)Query 函數都可以將 XQuery 嵌入到 SQL 中。前面的例子展示了如何使用這些函數和簡單的 XPath 表達式訪問 XML(標准化越來越近了) 文檔中感興趣的某個部分。現在我們考慮一個簡單的例子,這個例子將 XQuery 包括在 SQL 查詢中。
XQueries 可以包含 "for"、"let"、"where" "、"order by" 和 "return" 子句中的一些或者全部。這些子句一起形成了 FLWOR (發音為 flower)表達式。SQL 程序員會發現,將 XQuerIEs 嵌入到 SELECT 列表中以便將 xml(標准化越來越近了) 文檔的片段提取(或投影)到結果集是很方便的。雖然 XML(標准化越來越近了)Query 函數的用法不止於此,不過本文只討論這種情況。(將來的文章將更深入地討論 XQuery。)
假設您要檢索 "Gold" 客戶的姓名和首要 email 地址。在某些方面,這個任務類似於我們前面在探索如何投影 xml(標准化越來越近了) 元素值的時候完成過的一個任務(參見 清單 9)。而在這裡,我們將 XQuery (帶有 "for" 和 "return" 子句)作為 XML(標准化越來越近了)Query 函數的輸入:
清單 15. 使用 XQuery 的 "for" 和 "return" 檢索 XML(標准化越來越近了) 數據
select name, XML(標准化越來越近了)query('for $e in $c/ClIEnt/email[1] return $e'
passing contactinfo as "c")
from clIEnts
where status = 'Gold'
第一行指定結果集中將包括客戶姓名和 xml(標准化越來越近了)Query 函數的輸出。第二行表明將返回 "ClIEnt" 元素的第一個 "email" 子元素。第三行標識出 XML(標准化越來越近了) 數據的源 —— "contactinfo" 列。第四行說明這個列在 "clIEnts" 表中,最後,第五行表明我們只對 "Gold" 客戶感興趣。
因為這個例子很簡單,在這裡您可以這樣編寫這個查詢。不過,也可以用一種更緊湊的方式編寫這個查詢:
清單 16. 以更緊湊的方式重寫查詢
select name, XML(標准化越來越近了)query('$c/ClIEnt/email[1]'
passing contactinfo as "c")
from clIEnts
where status = 'Gold'
不過,通過 XQuery 的 return 子句可以按照需要轉換 XML(標准化越來越近了) 輸出。例如,您可以提取 email 元素值並將它們發布為 HTML。下面的查詢將產生一個結果集,其中每個 Gold 客戶的第一個 email 地址以 Html 段落的形式返回。
清單 17. 檢索 XML(標准化越來越近了) 並將其轉換成 Html
select XML(標准化越來越近了)query('for $e in $c/ClIEnt/email[1]/text()
return <p>{$e}</p>'
passing contactinfo as "c")
from clIEnts
where status = 'Gold'
第一行表明您只對符合條件的客戶的第一個 email 地址的文本表示形式感興趣。第二行指定該信息在返回之前需要用 Html 段落標記括起來。具體來說,花括號({ })指示 DB2 計算被括起來的表達式(在這裡是 "$e")的值,而不是將其視作一個文字字符串。如果省略了花括號,對於每個符合條件的客戶記錄,DB2 將返回一個包含 "<p>$e</p>" 的結果。
將關系數據發布為 XML(標准化越來越近了)
到到目前為止,我們一直都在著重討論查詢、提取或轉換存儲在 DB2 xml(標准化越來越近了) 列中的數據的方法。而且您已經看到,這些功能都可以通過 SQL/XML(標准化越來越近了) 提供。
SQL/xml(標准化越來越近了) 還提供了其他非常方便的特性。其中一個特性是將關系數據轉換或發布為 xml(標准化越來越近了)。本文只討論這方面的三個 SQL/xml(標准化越來越近了) 函數:xml(標准化越來越近了)Element、xml(標准化越來越近了)Agg 和 XML(標准化越來越近了)Forest。
通過 xml(標准化越來越近了)Element 可以將存儲在傳統的 SQL 列中的數據轉換成 xml(標准化越來越近了) 片段。也就是說,可以基於基本的 SQL 數據構造 xml(標准化越來越近了) 元素(帶 xml(標准化越來越近了) 屬性或者不帶 xml(標准化越來越近了) 屬性)。下面的例子嵌入了 XML(標准化越來越近了)Element 函數來創建一系列的 item 元素,每個 item 元素包含一些子元素,分別存放從 "items" 表獲得的 ID、品牌和庫存單位("sku")值:
清單 18. 使用 xml(標准化越來越近了)Element 將關系數據發布為 XML(標准化越來越近了)
select XML(標准化越來越近了)element (name "item",
XML(標准化越來越近了)element (name "id", id),
XML(標准化越來越近了)element (name "brand", brandname),
XML(標准化越來越近了)element (name "sku", sku) ) from items
where srp < 100
運行該查詢將產生類似以下的結果:
清單 19. 上述查詢的示例輸出
<item>
<id>4272</id>
<brand>Classy</brand>
<sku>981140</sku>
</item>
. . .
<item>
<id>1193</id>
<brand>Natural</brand>
<sku>557813</sku>
</item>
可以將 xml(標准化越來越近了)Element 與其他 SQL/xml(標准化越來越近了) 發布函數結合使用來構造 xml(標准化越來越近了) 值以及將這些值分組,使它們嵌套成一定的層次結構。清單 20 中的例子使用 xml(標准化越來越近了)Element 創建 customerList 元素,該元素的內容按照 "status" 列中的值分組。對於每個 "customerList" 記錄,XML(標准化越來越近了)Agg 函數返回一系列的 customer 元素,每個 customer 元素包含基於 "name" 和 "status" 列的子元素。而且可以看到,customer 元素的值是按照客戶姓名排序的。
清單 20. 聚集數據和對數據分組
select XML(標准化越來越近了)element(name "customerList",
xml(標准化越來越近了)agg (XML(標准化越來越近了)element (name "customer",
XML(標准化越來越近了)forest (name as "fullName", status as "status") )
order by name ) )
from clIEnts
group by status
假設 "clIEnts" 表包含三個不同的 "status" 值:"Gold"、"Silver" 和 "Standard"。運行上述查詢將導致 DB2 返回三個 customerList 元素,每個 customerList 元素可能包含多個 customer 子元素,每個 customer 子元素又進一步包含姓名和狀態信息。因此,輸出將類似於以下內容:
清單 21. 上述查詢的輸出
<customerList>
<customer>
<fullName>Chris Bontempo</fullname>
<status>Gold</status>
</customer>
<customer>
<fullName>Ella Kimpton</fullName>
<status>Gold</status>
</customer>
. . .
</customerList>
<customerList>
<customer>
<fullName>Lisa Hansen</fullName>
<status>Silver</status>
</customer>
. . .
</customerList>
<customerList>
<customer>
<fullName>Rita Gomez</fullName>
<status>Standard</status>
</customer>
. . .
</customerList>
更新和刪除操作
雖然本文的重點是使用 SQL 搜索和檢索存儲在 xml(標准化越來越近了) 列中的數據,不過這裡仍然值得花一點時間考慮一下另外兩項常見的任務:更新和刪除 XML(標准化越來越近了) 列中的數據。
DB2 允許用戶使用 SQL 和SQL/xml(標准化越來越近了) 語句更新和刪除 XML(標准化越來越近了) 數據。實際上,由於 XQuery 標准的初稿沒有解決這些問題,DB2 用戶必須依賴 SQL 來完成這些任務。
更新 XML(標准化越來越近了) 數據
DB2 允許用 SQL UPDATE 語句或通過使用系統提供的存儲過程(DB2xml(標准化越來越近了)FUNCTIONS.xml(標准化越來越近了)UPDATE)來更新 xml(標准化越來越近了) 列。不管使用哪種方式,對 xml(標准化越來越近了) 列的更新都發生在元素級。然而,使用存儲過程更新 xml(標准化越來越近了) 數據的程序員不需要提供整個 xml(標准化越來越近了) 文檔給 DB2;他們只需指定要更新的 XML(標准化越來越近了) 元素。發出 UPDATE 語句的程序員則需要指定整個文檔(而不僅僅是要更改的元素)。
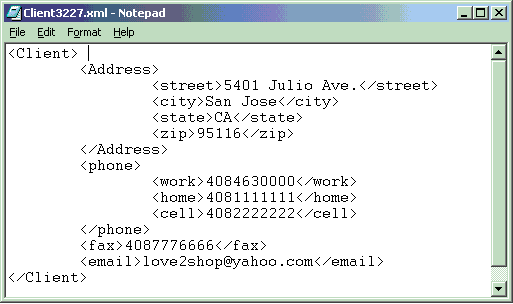
例如,如果要發出一條 UPDATE 語句來更改某個特定客戶的聯系方式信息中的 email 地址,就必須在 XML(標准化越來越近了) 列中提供全部聯系方式信息,而不僅僅是新的 email 元素值。根據 圖 2,提供的信息將包括 "Address" 信息、"phone" 信息、"fax" 信息和 "email" 信息。
考慮以下語句:
清單 22. 示例 UPDATE 語句
update clIEnts set contactinfo=(
XML(標准化越來越近了)parse(document '<email>[email protected]</email>' ) )
where id = 3227
回憶一下在 “DB2 Viper 快速入門” 中我們是如何插入 xml(標准化越來越近了) 數據的,這裡的語句大部分仍然是類似的。與任何 SQL UPDATE 語句一樣,這個例子首先標識出要更新的表和列。由於目標列包含 xml(標准化越來越近了) 數據,因此需要提供一個格式良好的 xml(標准化越來越近了) 文檔作為新的目標值。雖然大多數生產環境在應用程序中使用主機變量或參數標記位來更新 xml(標准化越來越近了) 數據,但是在這裡我展示了用一種簡單的方式來交互式地完成該任務。第二行使用 xml(標准化越來越近了)Parse 函數將輸入字符串轉換成 xml(標准化越來越近了)。對於 beta 版的 Viper,需要顯式地調用 XML(標准化越來越近了)Parse。當 Viper 變得普遍可用時,顯式調用應該只是成為一種選擇。最後一行是一個標准的 SQL 子句,規定只更新表中特定的一行。
如果執行上述 UPDATE 語句,則客戶 3227 的 "contactinfo" 列將只包含 email 信息,如 清單 23 所示:
清單 23. 執行上述 UPDATE 語句的效果
<email>[email protected]</email>
這位客戶的地址、電話號碼和傳真號碼(如 圖 2 所示)將丟失。而且,之前編寫的用於提取客戶的 email 地址的那些查詢也無法恢復這些信息。為什麼?之前的那些查詢包括 XPath 或 XQuery 表達式,這些表達式在一個特定的文檔層次結構中導航,而在這個結構中 ClIEnt 是根元素,email 是一個子元素。在像上面這樣更新該文檔之後,email 將變成這個客戶的 XML(標准化越來越近了) 記錄的根元素;因此,在這個層次結構中再也不能在預期的位置上找到它的值。
如果要交互式地更新這個客戶的 email 地址,並且保留所有其他已有的聯系方式信息,應該像 清單 24 中那樣重寫查詢:
清單 24. 修改後的 UPDATE 語句
update clIEnts set contactinfo=
(XML(標准化越來越近了)parse(document
'‘<ClIEnt>
<Address>
<street>5401 Julio Ave.</street>
<city>San Jose</city>
<state>CA</state>
<zip>95116</zip>
</Address>
<phone>
<work>4084633000</work>
<home>4081111111</home>
<cell>4082222222</cell>
</phone>
<fax>4087776666</fax>
<email>[email protected]</email>
</ClIEnt>' ) )
where id = 3227
也許您想知道是否可以通過一個視圖進行更新,從而避免提供整個 xml(標准化越來越近了) 文檔。例如,清單 13 中定義的 commentvIEw 使用 xml(標准化越來越近了)Table 函數提取 xml(標准化越來越近了) 文檔中的某些元素,並將這些元素轉換成視圖中的 SQL 列。那麼,是否可以更新這些 SQL 列中某個列的值,並將結果寫回到初始的 xml(標准化越來越近了) 文檔的適當子元素中呢?答案是否定的。在 DB2 中,基於 SQL 類型的視圖列與從一個函數(在這裡是 XML(標准化越來越近了)Table 函數)得到的視圖列是有區別的。對後者的更新不受支持。
刪除 XML(標准化越來越近了) 數據
刪除包含 xml(標准化越來越近了) 列的行很簡單。SQL DELETE 語句允許通過 WHERE 子句識別(或限制)要刪除的行。該子句可以包括簡單的謂詞來標識非 xml(標准化越來越近了) 列值或包括 SQL/xml(標准化越來越近了) 函數來標識包含在 xml(標准化越來越近了) 列中的 XML(標准化越來越近了) 元素值。
例如,下面展示了如何刪除客戶 ID 為 3227 的客戶的所有信息:
清單 25. 刪除一個特定客戶的數據
delete from clIEnts
where id = 3227
還記得怎樣限制 SQL SELECT 語句,使之僅返回居住在郵政編碼為 95116 的地區的客戶的行嗎?如果還記得的話,很容易知道如何刪除與那些客戶相關的行。下面看看如何使用 XML(標准化越來越近了)Exists 來做這件事:
清單 26. 刪除居住在特定地區的客戶的數據
delete from clIEnts
where XML(標准化越來越近了)exists('$c/ClIEnt/Address[zip="95116"]'
passing clIEnts.contactinfo as "c");
建立索引
最後,值得注意的是,您可以創建專門的 xml(標准化越來越近了) 索引來加快對 XML(標准化越來越近了) 列中的數據的訪問。由於本文是介紹性的文章,並且示例數據量比較少,所以本文不討論這個話題。但是,在生產環境中,定義適當的索引對於取得最佳性能是非常重要的。本文的 參考資料 小節可以幫助您了解更多關於新的 DB2 索引技術的知識。
結束語
本文談到了很多基礎知識,提到了 SQL/xml(標准化越來越近了) 的幾個關鍵方面,並展示了如何使用 SQL/xml(標准化越來越近了) 查詢 xml(標准化越來越近了) 列中的數據。當然,除了這裡討論的用法外,用 SQL 和 SQL/XML(標准化越來越近了) 函數還可以做更多的事。本文給出了一個 簡單的 Java 例子,這個例子解釋了如何使用參數標記位和 SQL/xml(標准化越來越近了) 來查詢 XML(標准化越來越近了) 列中的數據。在將來的文章中我們將更詳細地討論應用程序開發。但是,接下來的文章將探索 DB2 Viper 支持的一種新的查詢語言,即 XQuery 的一些有趣的方面。