簡介
關系模型是一件美好事物。對它妥協是牽強附會,就象給米開朗琪羅的大衛扣上一頂棒球帽一樣。然而,不屬於純關系模型的事物可能最終出現在您的數據庫或應用程序中。如果您以修道士般的嚴肅態度看待關系誓約,那麼不必繼續閱讀本文。對那些可能希望享受在狂野地帶漫步的人而言,本文將帶您到 RDBMS 的紅燈區。請繼續閱讀本文以發現如何:
這些技術中的一些技術可以改進性能,就象您可能在 RDBMS 參考手冊中看到的實用建議,它建議您使數據符合第四范式,然後在實現設計前做一些妥協以取得需要的性能。其它一些技術會使應用程序程序員的工作更簡單,並且帶來性能上意想不到的效果。
派生值
您可能在關於關系數據庫的大學課程中的某處學到不要存儲派生值。畢竟,可以在組裝結果集時計算這些值,從而避免數據庫中的冗余數據,並獲得正確答案。DB2 在版本 7 中引入生成的列有以下幾個原因。
create table employee
(name char(10), salary dec(10,2), commission dec(10,2),
compensation dec(11,2)
generated always as (commission + salary)) 通過下面的 SQL 語句來保持 COMPENSATION 列的准確性:
insert into employee (name, salary, commission) values ('Blair',5,10)update employee set salary=0區分大小寫
區分大小寫是功能強大的,而且如果 RDBMS 知道 Greenland 與 greenland 不匹配,它會搜索得更快。然而,用戶如果提交對“Macinnis”的搜索,他們可能實際上希望您的應用程序返回“MacInnis”。對於名稱搜索,您可能要考慮在 NAME 列上創建一個索引。然而,DB2 索引中的值也是區分大小寫的。讓 MacInnis=Macinnis 很簡單,只要使用 UPPER 或 UCASE 函數即可:
SELECT NAME FROM EMPLOYEE WHERE UPPER(NAME) = 'MacINNIS'但是,這會強制進行表掃描,而且您得不到索引的好處。這就是引入生成的列的用途所在:如果標准訪問方法是關於名稱的搜索,那麼使用生成的列來以大寫格式存儲名稱:
CREATE TABLE EMPLOYEE (NAME VARCHAR(10),
NAME_UP
GENERATED ALWAYS AS (UPPER(name))) 現在在這個列的大寫版本上創建索引:
CREATE INDEX NAME_IND ON EMPLOYEE ( NAME_UP )該查詢可以獲得索引的好處,並避免了表掃描:
SELECT NAME FROM EMPLOYEE WHERE UPPER(NAME) = 'MacINNIS'讓我們看看如何用生成的列來枚舉行。我們為什麼要給行編號?關系理論告訴我們行與列沒有內在的順序:您可以在請求數據時指定順序。但人們喜歡給事物編號,從書中的頁號到運動衫上的號碼。您可能知道在計算機科學中數據被看成表格式關系模型。您的用戶有多少學會查看 Lotus 和 Excel 電子表格中的表格式數據(屏幕左邊有向下遞增的行號)呢?大多數關系數據庫管理系統都有內部 RID(行標識)或 TID(元組標識)。OS/390® 上的 DB2 和 Oracle(大型網站數據庫平台) 將這一點具體化,使程序無需知道內容就可以方便地標識行。我們沒有具體化 Windows/UNIX/OS/2 上 DB2 的行標識,因為我們允許它改變:潛在主鍵中的一個危險特性。DB2 的確有其它方法將一列作為人工主鍵使用。
在您借助任何這些唯一標識每一行的基本方法之前,請盡力找到真實的主鍵:問自己這個問題:“如果我們把每一行都寫在紙上,應如何唯一標識它;假定客戶或供應商打電話詢問狀態 — 我們怎樣才能找到他們所詢問的數據?”如果您在每張紙上都打上日期和時間戳記,那麼這就是主鍵。
生成行標識
讓我們從由其它數據庫遷移到 DB2 的應用程序開始。如果移自 SQL Server(Windows平台上強大的數據庫平台),您可能厭倦了關於關系純潔性的說教並希望了解 IDENTITY。下面是如何用 DB2 v7 創建 IDENTITY 列:
CREATE TABLE T1
(C1 DECIMAL(15,0) GENERATED BY DEFAULT AS IDENTITY
(START WITH 10),
C2 INTEGER) 還有在內存中高速緩存標識值的選項,這使插入更快,但如果您的系統在生成 IDENTITY 值時遭受硬件或軟件崩潰,那麼將在標識序列中留下間隔。缺省情況是一次增加整數 1,但您也可以按其它值(2 和 10 等)增加。插入後,您會對生成的值自然地產生好奇。為了應用程序的下一段邏輯,您可能需要知道這個值。在發行說明(Windows 上 x:\sqllib\release.txt)中記錄的名為 IDENTITY_VAL_LOCAL() 的函數可為您檢索這個值。
IDENTITY 在每個表中是唯一的。那些 Oracle(大型網站數據庫平台) 迷將很高興得知 DB2 的版本 7,修訂包 3 將把 SEQUENCE 列帶入 DB2。序列在整個數據庫中是獨一無二的 — 這對於在多個表中使用的值很有用。您也可以在序列中循環以重用這些值。SEQUENCE 和 IDENTITY 不是數據類型:它們使用象 SMALLINT、INTEGER 或小數位是零的 DEC 那樣的現有數據類型。INT 和 BIGINT 是最好的選擇,它們能給您良好的性能和適當的數值范圍。還允許負值。
生成人工主鍵還有其它方法。如果一次只有一位用戶訪問表(並且一次只插入一行),則觸發器很不錯。將您的主鍵列定義為缺省非空值,這樣當在 INSERT 中沒有指定它時,它就得到一個虛設的值(觸發器將重寫這個虛設的值):
CREATE TRIGGER AutoIncrement NO CASCADE BEFORE
INSERT ON Foobar
REFERENCING NEW AS n
FOR EACH ROW MODE DB2SQL SET (n.col1) =
(SELECT COALESCE(MAX(col1),0) + 1 FROM Foobar ) DB2 還有一個名為 GENERATE_UNIQUE 的函數。這個函數將節點號(用於多分區數據庫)與時間戳記結合,因此它可以與企業擴展版本(EEE)一起使用。IDENTITY 和 SEQUENCE 在 DB2 的下一個主要版本出現前還不能與 EEE 一起使用。GENERATE_UNIQUE 有兩個缺點:數據類型(CHAR(13) FOR BIT DATA)不是按順序遞增,並且不象數值數據類型那樣易於使用。
更簡單的解決方案是標量子查詢表達式:
INSERT INTO Foobar (key_col, ...)
VALUES (COALESCE((SELECT MAX(key_col) FROM Foobar) +1, 0) ...) 獲得一屏數據
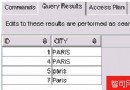
這些方法對於那些在數據庫和應用程序投入生產以前有機會進行一些設計工作的模式和應用程序來說是不錯的。但您還記得那兩個以 A(ARIES(航班訂票環境仿真)和 ACID(原子性、一致性、隔離和持久性))開頭的 4.5 字母單詞嗎?如果您預定了航班,那麼您希望他們在您到達機場時記得這回事。這就是持久性:有用的數據是持久的。這意味著即使您定義了一個好的主鍵,有些人可能會查詢結果集的“前二十行”,而不管結果集中有多少行。更糟的情況是有人要求您顯示第 21 行到 40 行。但等一下,您會提出異議,關系表中的行沒有順序!對於希望在他們的 Netscape 浏覽器中一次看到二十行的用戶而言,您就好象在說冰島語。DB2 允許您實時地給結果集排序,並可以從該結果集的開始或結尾部分提取任意數量的行:
SELECT NAME FROM ADDRESS
ORDER BY NAME
FETCH FIRST 10 ROWS ONLY SELECT NAME FROM ADDRESS
ORDER BY NAME DESC
FETCH FIRST 10 ROWS ONLY ORDER BY 將強制在內存中對整個結果集進行排序,所以,為了提高 DB2 服務器性能,我們不這麼做(盡管只向客戶機發送 10 行可能會提高網絡性能)。如果您不關心順序並且只想知道至少有 10 行符合結果集,則清除 ORDER BY 以省去 DB2 服務器上的排序:
SELECT NAME FROM ADDRESS
FETCH FIRST 10 ROWS ONLY 於是現在我們已看到您給行編號並且任意選擇了一個子集。假設我們因某些性能上的好處而給行編號,這必將破壞關系模型。我們幾乎完全妥協了,並且已經犯了關系七宗罪中的六宗。還有一條關系誓約您沒有觸犯:讓我們實時地給行編號,犧牲掉性能和關系純潔性吧。我們如何證明這樣做的正確性呢?在因特網上譴責它吧。