用於備份和恢復的數據結構
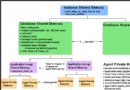
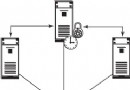
Oracle(大型網站數據庫平台) 和 DB2 UDB 都有一組組成備份和恢復機制的組件。您在 圖 1和 圖 2 中看到的體系結構圖對提供 Oracle(大型網站數據庫平台) 和 DB2 的備份和恢復的主要組件進行了概述。
圖 1. Oracle(大型網站數據庫平台) 體系結構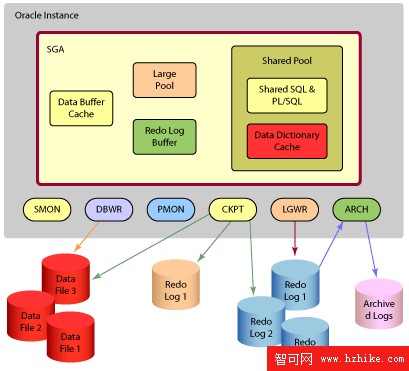
Oracle(大型網站數據庫平台) 的內存結構
Oracle(大型網站數據庫平台) 後台進程
Oracle(大型網站數據庫平台) 數據庫結構
接下來我們將看到 DB2 UDB 體系結構和結構。
圖 2. DB2 UDB 體系結構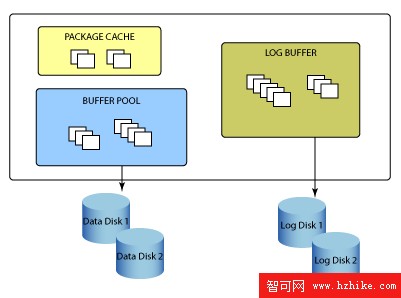
DB2 UDB 內存結構
圖 3. DB2 UDB 數據庫結構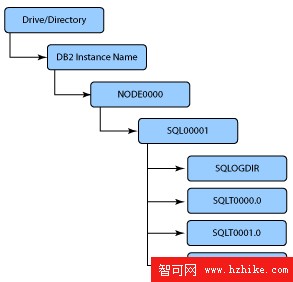
備份和恢復選擇
對於 Oracle(大型網站數據庫平台) 和 DB2 UDB 數據庫,有兩種備份和恢復模式:脫機和聯機。可以用任何一種模式來進行完全和不完全恢復。
脫機備份要求所有應用程序斷開與數據庫的連接,聯機備份允許在備份的過程中繼續執行事務。在選定備份模式的恢復方面,存在隱含關系,因為備份模式決定了恢復模式。
顧名思義,完全恢復能夠完全地恢復所有提交的事務,而不完全恢復在恢復事務時會丟失一些數據。Oracle(大型網站數據庫平台) 和 DB2 UDB 都能讓您恢復到當前時間,而且沒有數據丟失,或者恢復到當前時間以前的時間,但要丟失一些數據。
通常,恢復的目標是用選定的恢復模式在業務需求與操作需求之間達成某種妥協。例如,如果數據庫不是任務關鍵型和 24X7 型的,那麼停機上一段時間和丟失一些數據可能是可以接受的,對於媒介錯誤,重新鍵入數據也可能是一種可以接受的方法。采用什麼樣的恢復取決於可用的備份和可用的日志,可能有時候除了執行不完全恢復以外別無選擇。
有兩種類型的 DB2 日志記錄,每種日志記錄方法支持特定的恢復選項。這兩種類型的日志記錄是 循環和 歸檔日志記錄。當選擇使用循環日志記錄(默認情況下選擇這種日志記錄)時,惟一的選擇是執行脫機備份和版本恢復。如果您選擇使用歸檔日志記錄,並執行聯機備份和前滾恢復,那麼您可以恢復到數據丟失最少的那個時間點,或者恢復到結束日志的時候。
數據結構自測試題(節選章節)
*******************************************************************
第一章、概論 試題 參考答案 第二章、線性表 試題 參考答案 第三 章、棧和隊列 試題 參考答案 第六章、樹和二叉樹 試題 參考答案 第七章、圖 試題 參考答案 第九章、集合 試題 參考答案 第十章、排序 試題 參考答案 全真模擬試題(一) 參考答案 全真模擬試題(二) 參考答案 全真試題(一) 全真試題(二) 全真試題(三) 全真試題(四) 全真試題(五) 全真試題(六)Sp課程代碼:7399
一、單項選擇題(在每小題列出的四個選項中只有一個選項是符合題目要求的,請將正確選項前的字母填在題後的括號內。每小題2分,共40分)
1、串的長度是()。
A、串中不同字母的個數
B、串中不同字符的個數
C、串中所含字符的個數,且大於0
D、串中所含字符的個數
2、若用數組S[1..n]作為兩個棧S1和S2的共同存儲結構,對任何一個棧,只有當S全滿時才不能作入棧操作。為這兩個棧分配空間的最佳方案是()。
A、S1的棧底位置為0,S2的棧底位置為n+1
B、S1的棧底位置為0,S2的棧底位置為n/2
C、S1的棧底位置為1,S2的棧底位置為n
D、S1的棧底位置為1,S2的棧底位置為n/2
3、隊列操作的原則是()。
A、先進先出
B、後進先出
C、只能進行插入
D、只能進行刪除
4、有64個結點的完全二叉樹的深度為()(根的層次為1)。
A、8 B、7 C、6 D、5
5、在有n個結點的二叉鏈表中,值為非空的鏈域的個數為()。
A、n-1
B、2n-1
C、n+1
D、2n+1
6、帶權有向圖G用鄰接矩陣A存儲,則頂點i的人度等於A中()。
A、第i行非∞的元素之和
B、第i列非∞的元素之和
C、第i行非∞且非0的元素個數
D、第i列非∞且非0的元素個數
7、在有n個結點且為完全二叉樹的二叉排序樹中查找一個鍵值,其平均比較次數的數量級為()。
A、0(n)
B、0(log2n)
C、0(nolg2n)
D、0(n2)
8、若表R在排序前已按鍵值遞增順序排列,則()算法的比較次數最少。
A、直接插入排序
B、快速排序
C、歸並排序
D、選擇排序
9、下列排序算法中,()排序在某趟結束後不一定選出一個元素放到其最終的位置上。
A、選擇
B、冒泡
C、歸並
D、堆
10、若線性表最常用的操作是存取第i個元素及其前趨的值,則采用()存儲方式節省時間。
A、單鏈表
B、雙鏈表
C、單循環鏈表
D、順序表
11、對二叉樹從1開始進行連續編號,要求每個結點的編號大於其左右孩子的編號,同一個結點的左右孩子中,其左孩子的編號小於其右孩子的編號,則可采用()遍歷實現編號。
A、無序
B、中序
C、後序
D、從根開始的層次遍歷
12、某二叉樹的中序序列和後序序列正好相反,則該二叉樹一定是()的二叉樹。
A、空或只有一個結點
B、高度等於其結點數
C、任一結點無左孩子
D、任一結點無右孩子
13、下列排序算法中,時間復雜度不受數據初始狀態影響,恆為0(log2n)的是()
A、堆排序
B、冒泡排序
C、直接選擇排序
D、快速排序
14、下列排序算法中,()算法可能會出現下面情況:初始數據有序時,花費的時間反而最多。
A、堆排序
B、冒泡排序
C、快速排序
D、SHELL排序
15、一個棧的輸入序列為1 2 3 4 5,則下列序列中不可能是棧的輸出序列的是()。
A、2 3 4 1 5
B、5 4 1 3 2
C、2 3 1 4 5
D、1 5 4 3 2
16、設循環隊列中數組的下標范圍是1-n,其頭尾指針分別為f和r,則其元素個數為()。
A、r-f
B、r-f+1
C、(r-f) mod n+1
D、(r-f+n) mod n
17、若某鏈表最常用的操作是在最後一個結點之後插入一個結點刪除最後一個結點,則采用()存儲方式最節省時間。
A、單鏈表
B、雙鏈表
C、帶頭結點的雙循環鏈表
D、單循環鏈表
18、一棵非空的二叉樹的先序序列和後序序列正好相同,則該二叉樹一定滿足()。
A、其中任意一結點均無左孩子
B、其中任意一結點均無右孩子
C、其中只有一個結點
D、是任意一棵二叉樹
19、一棵左右子樹均不空的二叉樹在先序線索化後,其空指針域數為()。
A、0 B、1 C、2 D、不確定
20、數組A[1..5,1..6]每個元素占5個單元,將其按行優先次序存儲在起始地址為1000的連續的內存單元中,則元素A[5,5]的地址為()。
A、1140 B、1145 C、1120 D、1125
二、判斷題(對的打“√”,錯的打“×”。每小題1分,共10分)
1、線性表的唯一存儲形式是鏈表。()
2、已知指針P指向鍵表L中的某結點,執行語句P:=P∧.next不會刪除該鏈表中的結點。()
3、在鏈隊列中,即使不設置尾指針也能進行入隊操作。()
4、如果一個串中的所有字符均在另一串中出現,則說前者是後者的子串。()
5、設與一棵樹T所對應的二叉樹為BT,則與T中的葉子結點所對應的BT中的結點也一定是葉子結點。()
6、9階B樹中,除根以外的任何一個非葉子結點中的關鍵字數目均在5-9之間。()
7、任一AOE網中至少有一條關鍵路徑,且是從源點到匯點的路徑中最長的一條。()
8、若圖G的最小生成樹不唯一,則G的邊數一定多於n-1,並且權值最小的邊有多條(其中n為G的頂點數)。()
9、給出不同的輸入序列建造二叉排序樹,一定得到不同的二叉排序樹。()
10、由於希爾排序的最後一趟與直接插入排序過程相同,因此前者一定比後者花費的時間多。()
三、填空題(每空2分,共20分)
1、已知二叉樹中葉子數為50,僅一個孩子的結點數為30,則總結點數____。
2、直接選擇排序算法在最好情況下所作的交換元素的次數為____。
3、有n個頂點的連通圖至少有____條邊。
4、取出廣義表A=(x,(a,b,c,d))中原子a的函數是____。
5、在雙循環鏈表中,刪除指針P所指結點的語句序列是____。
6、隊列的特性是____。
7、若某串的長度小於一個常數,則采用____存儲方式最節省空間。
8、在有n個葉子結點的哈夫曼樹中,總結點數是____。
9、在有序表A[1..18]中,采用二分查找算法查找元素值等於A[7]的元素,所比較過的元素的下標依次為____。
10、求最短路徑的FLOYD算法的時間復雜度為____。
四、簡答題(每小題5分,共15分)
1、對下面數據表,寫出采用冒泡算法排序的前三趟的結果。
(25 10 20 31 5 44 16 61 100 3)
2、已知下面二叉排序樹的各結點的值依次為1-9,寫出該二叉樹的層次遍歷結果。
3、對下面的遞歸算法,寫出調用P(4)的執行結果。
procedure p (w:Integer);
begin
if w>0 then
begin write(W);
P(w-1);
P(w-1)
end
end;
五、綜合應用題(共15分)
1、采用直接插入排序算法,對關鍵字序列(46,32,55,81,65,11,25,43)按從小到大的次序進行排序,寫出每趟排序的結果。(滿分6分)
2、已知帶頭結點的單循環鏈表L中至少有一個元素,設計算法判斷L中各元素的值是否均是其序號的兩倍,若滿足,返回true。否則返回false,同時返回該鏈表中的結點序號。(滿分9分)
一、課程性質與教學目的
用計算機解決任何問題都需要進行數據表示和數據處理,而數據表示和數據處理正是《數據結構》要研究的內容。《數據結構》是計算機科學中一門綜合性的專業基礎課。主要介紹如何合理地組織數據、有效地存儲和處理數據,正確地設計算法以及對算法的分析和評價。通過本課程的學習,使學生深透地理解數據結構的邏輯結構和物理結構的基本概念以及有關算法,培養基本的、良好的程序設計技能,編制高效可靠的程序,為學習操作系統、編譯原理和數據庫等課程奠定基礎。
二、基本要求
1. 了解數據結構及其分類、數據結構與算法的密切關系。
2. 熟悉各種基本數據結構及其操作,學會根據實際問題要求來選擇數據結構。
3. 掌握設計算法的步驟和算法分析方法。
4. 掌握數據結構在排序和查找等常用算法中的應用。
5. 初步掌握文件組織方法和索引技術。
三、教學內容
1. 引論
數據、數據元素、數據結構、數據類型、抽象數據類型的概念;算法、算法描述與算法分析。
2. 線性表
線性表的邏輯結構定義、基本操作和在兩種存儲結構中基本操作的實現;鏈表;用線性表表示一元多項式及實現稀疏多項式的相加等運算。
3. 棧和隊列
棧和隊列的結構特性、基本操作及在兩種存儲結構上基本操作的實現;棧和隊列的應用、遞歸算法的設計。
4. 串
串的邏輯結構定義、串的基本運算及其實現;串的匹配算法。
5. 數組和廣義表
數組的邏輯結構定義和存儲方法;特殊矩陣和稀疏矩陣的壓縮存儲方法;廣義表的邏輯結構和存儲結構以及廣義表運算的遞歸算法。
6. 樹和二叉樹
樹的基本概念;二叉樹的定義、性質、存儲表示;二叉樹的遍歷;線索二叉樹;森林和二叉樹的相互轉換;樹的應用;哈夫曼樹及哈夫曼編碼。
7. 圖
圖的基本概念、存儲表示(鄰接矩陣、鄰接表、十字鏈表,鄰接多重表);圖的遍歷、圖的連通性問題;拓撲排序、關鍵路徑;最短路徑。
8. 動態存儲管理
內存的"分配"和"回收"策略;可利用空間表及分配方法;邊界標識法和伙伴系統。
9. 查找
查找表是集合類型的數據結構,其操作借助靜態查找表、動態查找表、哈希表實現;
10. 排序
排序分為內部排序和外部排序。
內部排序介紹插入排序、快速排序(交換排序)、選擇排序、歸並排序;排序的基本思想和算法分析。
外部排序介紹外存儲器(磁帶、磁盤)簡介;多路平衡歸並、置換選擇排序、最佳歸並樹及磁帶歸並排序。
11. 文件
基本概念;文件組織;順序文件、隨機文件、索引文件、倒排文件。
四、學分及學時分配
學分:4
學時:課程講授學時64,上機學時16,合計80學時,建議分配如下。
序 號
內 容
學 時
1
引論
2
2
線性表
6
3
棧和隊列
6
4
串
4
5
數組和廣義表
4
6
樹和二叉樹
8
7
圖
10
8
動態存儲管理
2
9
查找
8
10
排序
12
11
文件
2
合計
64
五、參考書目
1.嚴蔚敏等著 《數據結構》 清華大學出版社 1997
2.范策等著 《算法與數據結構》 機械工業出版社 2004
3. 謝楚屏等編著 《數據結構》 人民郵電出版社
4. 徐緒松等著 《數據結構與算法導論》 電子工業出版社
5. D.E.Knuth著 《計算機程序設計技巧》第一、三卷 管紀文譯 國防出版社
6. FULLS HORO-WITZ&SARTAJ SAHNT《FUNDAMENTALS OF DATA STRUCTURES》
《數據結構基礎》(中譯本)程惟寧譯 新時代出版社
湖南大學 2003 年招收攻讀碩士學位研究生
入學考試命題專用紙
招生專業:計算機應用技術、計算機軟件與理論、軟件工程碩士
考試科目:數據結構 試題編號:418(450)
注: 答題(包括填空題、選擇題)必須答在專用答題紙上,否則無效
一、單項選擇題(每小題1分,共15分)
1.兩個各有n個元素的有序列表並成一個有序表,其最少的比較次數是
。
A.n B.2n-1 C.2n D.n-1
2.設循環隊列中數組的下標范圍是0~ n-1,f表示隊首元素的前驅位置,r表示隊尾元素的位置,則隊列中元素個數為 。
A.r-f B.r-f 1 C.(r-f 1)mod n D.(r-f n)mod n
3.一個5行6列的二維數組s采用從最後一行開始,每一行的元素從右至左的方式映射到一維數組a中,s和a的下標均從0開始,則s[3][3]在a中的下標是 。
A.7 B. 8 C. 9 D. 10
4.設只含根結點的二叉樹的高度為1,則高度為n的二叉樹中所含葉子結點的個數最多為 個。
A.2n B.n C.2n -1 D.2n-1
5.設高度為h的二叉樹上只有度為0和度為2的結點,則此二叉樹中所包含的結點數至少為個(設只含根結點的二叉樹的高度為1)。
A.2h B 2h-1 C.2h 1 D.h 1
6.對一棵二叉檢索樹進行 得到的結點序列是一個有序序列。
A.前序周游 B. 中序周游 C.後序周游 D. 層次周游
7.一棵前序序列為1,2,3,4的二叉樹,其中序序列不可能是 。
A.4,1,2,3 B.4,3,2,1 C.2,4,3,1 D.3,4,2,1
8.下列編碼中 不是前綴碼。
A.{00,01,10,11} B.{0,1,00,11}
C.{0,10,110,111} D.{10,110,1110,1111}
9.在含n個頂點和e條邊的有向圖的鄰接矩陣中,零元素的個數為 .
A.e B.2e C.n2-e D.n2-2e
10.具有n個頂點和e條邊的圖的深度優先搜索算法的時間復雜度為 A.O(n) B.O(n3) C.O(n2) D.O(n e)
11.如果具有n個頂點的圖是一個環,則它有 棵生成樹。
A.n B.n l C.n-l D.2n
12堆排序算法在平均情況下的時間復雜度為 。 A.O(n) B.O(nlogn) C.O(n2) D.O(logn)
13.在待排序數據已基本有序的前提下,下述排序方法中效率最高的是 。 A.直接插入排序 B.直接選擇排序 C.快速排序 D.歸並排序
14.在理想情況下,散列表中查找元素所需的比較次數為 。
A.n B.O C.n/2 D.1
15.在一棵m階B樹中,若在某結點中插入一個新關鍵字而引起該結點分裂,則此結點中原有的關鍵字的個數是 。
A.m B.m 1 C.m—l D.m/2
二、判斷題(判斷下列各題是否正確,若正確,在括號內打“√”,否則打“╳”;每小題1分,共10分)
1.已知指針curr指向鏈表中的某結點,執行語句curr=curr->next;不會刪除該鏈表中的結點。 ( )
2.若二叉樹的葉結點數為1,則其高度等於結點數(僅含根結點的二叉樹高度 為1)。 ( )
3.按中序周游二叉樹時,某個結點的直接後繼是它的右子樹中第一個被訪問 的結點。 ( )
4.完全二叉樹的某結點若無左孩子,則它必是葉結點。 ( )
5.向二叉檢索樹中插入一個新結點,需要比較的次數不可能大於此二叉樹的高度。 ( )
6.對一個堆按層次周游,一定能得到一個有序序列。 ( )
7.一棵樹中的葉子結點數一定等於其對應的二叉樹中的葉子結點數。 ( )
8.將一棵樹轉換為二叉樹表示後,該二叉樹的根結點沒有右子樹。 ( )
9.任何有向圖的結點都可以排成拓撲序列,而且拓撲序列不唯一。 ( )
10.快速排序在最差情況下的時間復雜度是0(n2),此時它的性能並不比冒泡排序更好。 ( )
三、填空題(每空2分,共20分)
1.具有100個結點的完全二叉樹的葉子結點樹為 。
2.由權值分別為3,9,6,2,8的葉子結點生成一棵哈夫曼樹,它的外部帶權路徑長度為___。
3.對含n個結點的完全二叉樹按自上而下,從左到右的順序結點編號(從0
開始),則編號最小的葉子結點的編號是 。
4.n個頂點的連通無向圖的鄰接矩陣至少有 個非零元素。
5.在有序表A[1..20]中,若需查找的元素位於A[12],則采用折半查找算法所比較的元素的下標依次為
6.要將序列{60,10,8,40,90,70,100}建成堆,只需把8與 相
交換。
7.從一維數組a[n]中順序查找出一個最大值元素的時間復雜度為 。
8.已知廣義表L=((a,b,c),(d,e,f)),則運算head(tail(head(tail(L))))
的結果是 .
9.模式串P=“abaa”的next函數值序列為 。
10.一個兩層100階的B 樹,最多可以有 條記錄
四、解析題(共55分)
1.對二叉樹中結點進行按層次順序(每一層從左至右)的訪問操作稱為二叉樹的層次遍歷,遍歷所得到的結點序列稱為二叉樹的層次序列。現已知一棵二叉樹的層次序列為ABCDEFGHIJ,中序序列為DBGEHJACIF,請畫出該二叉樹。
(7分)
2.證明若二叉排序樹中的一個結點存在兩個孩子,則 (8分)
①它的中序後繼結點沒有左孩子。
②它的中序前趨結點沒有右孩子。
3.對下面的帶權無向圖采用prim算法從頂點①開始構造最小生成樹。(寫出假如生成樹頂點集合S和選擇邊Edge的順序) (10分)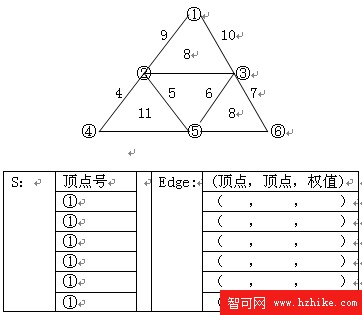
4.已知一組關鍵字序列為:(17,31,13,11,20,35,25,8,4,11,24,40, 27),按照依次插入結點的方法生成一棵平衡二叉排序樹。 (10分)
5.設散列函數為H(k)=k%13,散列表的地址空間為0到12,用線性探查法解覺沖突,將關鍵字(18,22,78,205,40,16,35,104,61)依次存入該散列表中,試構造散列表,並計算在等概率下的搜索成功的平均搜索長度ASL(搜索成功的平均搜索長度 ASLsucc 是指搜索到表中己有表項的平均探查次數。它是找到表中各個己有表項的探查次數的平均值) (10分)
6.給出一組關鍵字T=(20,3,18,40,9,30,5,11,32,7,28),設內存工作區可容納4個記錄,寫出用置換-選擇排序得到的全部初始歸並段。若某文件經內排序後得到50個初始歸並段(初始順串),若使用多路歸並排序算法算法,並要求三趟歸並完成排序,歸並路數最少為多少? (10分)
五、算法設計題(共50分)
1.請寫一算法,在順序表中查找指定的數據,查找成功則將該記錄放到順序表的最前面,而把其他記錄後退到有個位置。 (10分)
2.有一個由自然數構成的序列采用單鏈表存儲,試編寫算法判斷該序列是否是fibonacci序列(fibonacci序列是1,1,2,3,5,8,13,21,34,…)。
(10分)
3.定義二叉樹中兩個結點之間的最小距離為:這兩個結點的最近公共祖先結點分別到這兩個結點的路徑長度之和。請設計一個算法,找出給定二叉樹中任意兩個結點之間的最小距離。 (15分)
4.設有n個待排序元素存放在一個不帶表頭結點的單鏈表中,每個鏈表結點只存放一個元素,頭指針為head。試設計一個算法,對其進行自然歸並排序(按照下面的提示進行)。要求不移動個結點中的元素,只修改結點中的指針。排序完成後,head仍指示結果鏈表的第一個結點。 (15分)
提示:先對待排序的單鏈表進行一次掃描,將它劃分為若干有序的子鏈
表,然後反復進行二路歸並,直到將所有子鏈表歸並為一個有序鏈表為止。 線索化二叉樹
這是數據結構課程裡第一個碰到的難點,不知道你是不是這樣看,反正我當初是費了不少腦細胞——當然,惱人的矩陣壓縮和相關的加法乘法運算不在考慮之列。我費了不少腦細胞是因為思考:他們干什麼呢?很欣喜的看到在這本黃皮書上,這章被打了*號,雖然我不確定作者是不是跟我一個想法——線索化二叉樹在現在的PC上是毫無用處的!——不知我做了這個結論是不是會被人罵死,^_^。
為了證明這個結論,我們來看看線索化二叉樹提出的緣由:第一,我們想用比較少的時間,尋找二叉樹某一個遍歷線性序列的前驅或者後繼。當然,這樣的操作很頻繁的時候,做這方面的改善才是有意義的。第二,二叉樹的葉子節點還有兩個指針域沒有用,可以節省內存。說真的,提出線索化二叉樹這樣的構思真的很精巧,完全做到了“廢物利用”——這個人真應該投身環保事業。但在計算機這個死板的東西身上,人們的精巧構思往往都是不能實現的——為了速度,計算機的各個部件都是整齊劃一的,而構思的精巧往往都是建立在組成的復雜上的。
我們來看看線索化二叉樹究竟能不能達到上面的兩個目標。
求遍歷後的線性序列的前驅和後繼。前序線索化能依次找到後繼,但是前驅需要求雙親;中序線索化前驅和後繼都不需要求雙親,但是都不很直接;後序線索化能依次找到前驅,但是後繼需要求雙親。可以看出,線索化成中序是最佳的選擇,基本上算是達到了要求。
節省內存。添加了兩個標志位,問題是這兩個位怎麼儲存?即使是在支持位存儲的CPU上,也是不能拿位存儲器來存的,第一是因為結構體成員的地址是在一起的,第二是位存儲器的數目是有限的。因此,最少需要1個字節來儲存這兩個標志位。而為了速度和移植,一般來說,內存是要對齊的,實際上根本就沒節省內存!然而,當這個空間用來儲存雙親指針時,帶來的方便絕對不是線索化所能比擬的,前面已經給出了無棧的非遞歸遍歷。並且,在線索化二叉樹上插入刪除操作附加的代價太大。
綜上,線索化最好是中序線索化(前序後序線索化後還得用棧,何必要線索化呢),附加的標志域空間至少1個字節,在32位的CPU會要求對齊到4字節,還不如存儲一個雙親指針,同樣能達到中序線索化的目的,並且能帶來其他的好處。所以,線索化二叉樹在現在的PC上是毫無用處的!
棧的應用很廣泛,原書只講解了表達式求值,那我也就只寫這些。其實,棧的最大的用途是解決回溯問題,這也包含了消解遞歸;而當你用棧解決回溯問題成了習慣的時候,你就很少想到用遞歸了,比如迷宮求解。另外,人的習慣也是先入為主的,比如樹的遍歷,從學的那天開始,就是遞歸算法,雖然書上也教了用棧實現的方法,但應用的時候,你首先想到的還是遞歸;當然了,如果語言本身不支持遞歸(如BASIC),那棧就是唯一的選擇了——好像現在的高級語言都是支持遞歸的。
如下是表達式類的定義和實現,表達式可以是中綴表示也可以是後綴表示,用頭節點數據域裡的type區分,這裡有一點說明的是,由於單鏈表的賦值函數,我原來寫的時候沒有復制頭節點的內容,所以,要是在兩個表達式之間賦值,頭節點裡存的信息就丟了。你可以改寫單鏈表的賦值函數來解決這個隱患,或者你根本不不在兩個表達式之間賦值也行。
#ifndef Expression_H
#define Expression_H
#include "List.h"
#include "Stack.h"
#define INFIX 0
#define POSTFIX 1
#define OPND 4
#define OPTR 8
template class ExpNode
{
public:
int type;
union { Type opnd; char optr;};
ExpNode() : type(INFIX), optr('=') {}
ExpNode(Type opnd) : type(OPND), opnd(opnd) {}
ExpNode(char optr) : type(OPTR), optr(optr) {}
};
這些天參與了CSDN論壇的討論,改變了我以前的一些看法。回頭看我以前的東西,我雖對這本書很不滿,但我還是按照它的安排在一點點的寫;這樣就導致了,我過多的在意書中的偏漏,我寫的更多是說“這本書怎樣”,而偏離了我寫這些的初衷——給正在學習數據結構的人一些幫助。正像我在前面所說的,雖然現有的教科書都不是很合理,但如果僅僅是抱怨這點,那無異於潑婦罵街。雖然本人的水平連初級都夠不上,但至少先從我做一點嘗試,以後這門課的教授方法必將一點點趨於合理。
因此,後面不在按照書上的次序,將本著“實際應用(算法)決定數據結構”的思想來講解,常見教科書上有的,基本不再重點敘述(除了重點,例如AVL樹的平衡旋轉),——因此,在看本文的同時,一定要有一本教科書。這只是一個嘗試,希望大家多提寶貴意見。
樹
因為現實世界中存在這“樹”這種結構——族譜、等級制度、目錄分類等等,而為了研究這類問題,必須能夠將樹儲存,而如何儲存將取決於所需要的操作。這裡有個問題,是否允許存在空樹。有些書認為樹都是非空的,因為樹表示的是一種現實結構,而0不是自然數;我用過的教科書都是說可以有空樹,當然是為了和二叉樹統一。這個沒有什麼原則上的差別,反正就是一種習慣。
二叉樹
二叉樹可以說是人們假想的一個模型,因此,允許有空的二叉樹是無爭議的。二叉樹是有序的,左邊有一個孩子和右邊有一個的二叉樹是不同的兩棵樹。做這個規定,是因為人們賦予了左孩子和右孩子不同的意義,在二叉樹的各種應用中,你將會清楚的看到。下面只講解鏈式結構。看各種講數據結構的書,你會發現一個有趣的現象:在二叉樹這裡,基本操作有計算樹高、各種遍歷,就是沒有插入、刪除——那樹是怎麼建立起來的?其實這很好理解,對於非線性的樹結構,插入刪除操作不在一定的法則規定下,是毫無意義的。因此,只有在具體的應用中,才會有插入刪除操作。