前言
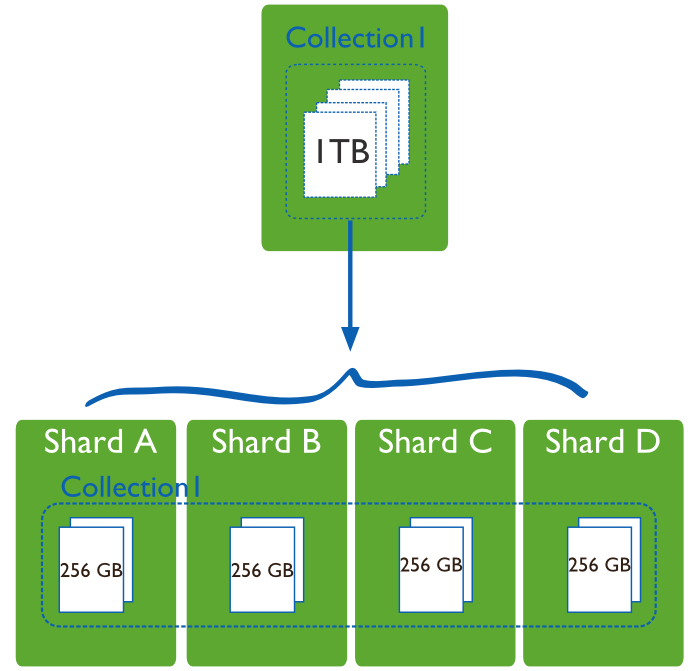
在MongoDB(版本 3.2.9)中,分片集群(sharded cluster)是一種水平擴展數據庫系統性能的方法,能夠將數據集分布式存儲在不同的分片(shard)上,每個分片只保存數據集的一部分,MongoDB保證各個分片之間不會有重復的數據,所有分片保存的數據之和就是完整的數據集。分片集群將數據集分布式存儲,能夠將負載分攤到多個分片上,每個分片只負責讀寫一部分數據,充分利用了各個shard的系統資源,提高數據庫系統的吞吐量。
數據集被拆分成數據塊(chunk),每個數據塊包含多個doc,數據塊分布式存儲在分片集群中。MongoDB負責追蹤數據塊在shard上的分布信息,每個分片存儲哪些數據塊,叫做分片的元數據,保存在config server上的數據庫 config中,一般使用3台config server,所有config server中的config數據庫必須完全相同。通過mongos能夠直接訪問數據庫config,查看分片的元數據;mongo shell 提供 sh 輔助函數,能夠安全地查看分片集群的元數據信息。
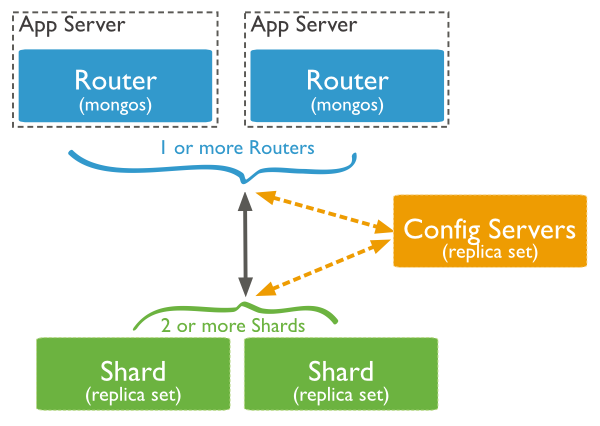
對任何一個shard進行查詢,只會獲取collection在當前分片上的數據子集,不是整個數據集。Application 只需要連接到mongos,對其進行的讀寫操作,mongos自動將讀寫請求路由到相應的shard。MongoDB通過mongos將分片的底層實現對Application透明,在Application看來,訪問的是整個數據集。
一,主分片
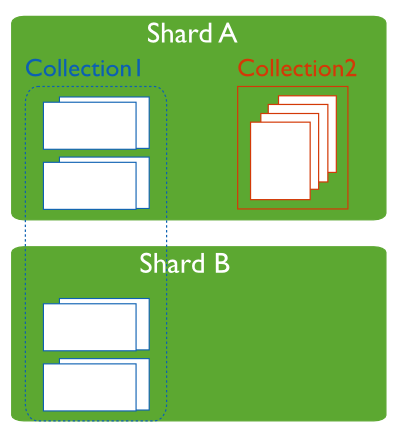
在分片集群中,不是每個集合都會分布式存儲,只有使用sh.shardCollection()顯式將collection分片後,該集合才會分布式存儲在不同的shard中。對於非分片集合(un-sharded collection),其數據只會存儲在主分片(Primary shard)中,默認情況下,主分片是指數據庫最初創建的shard,用於存儲該數據庫中非分片集合的數據。每個數據庫都有一個主分片。
Each database in a sharded cluster has a primary shard that holds all the un-sharded collections for that database. Each database has its own primary shard.
例如,一個分片集群有三個分片:shard1,shard2,shard3,在分片shard1創建一個數據庫blog。如果將數據庫bolg分片,那麼MongoDB會自動在shard2,shard3上創建一個結構相同的數據庫blog,數據庫blog的Primary Shard是Shard1。
圖示,Collection2的主分片是ShardA。
使用 movePrimary命令變更數據庫默認的Primary shard,非分片集合將會從當前shard移動到新的主分片。
db.runCommand( { movePrimary : "test", to : "shard0001" } )
在使用movePrimary命令變更數據庫的主分片之後,config server中的配置信息是最新的,mongos緩存的配置信息變得過時了。MongoDB提供命令:flushRouterConfig 強制mongos從config server獲取最新的配置信息,刷新mongos的緩存。
db.adminCommand({"flushRouterConfig":1})
二,分片的元數據
不要直接到config server上查看分片集群的元數據信息,這些數據非常重要,安全的方式是通過mongos連接到config數據查看,或者使用sh輔助函數查看。
使用sh輔助函數查看
sh.status()
連接到mongos查看config數據庫中的集合
mongos> use config
1,shards 集合保存分片信息
db.shards.find()
shard的數據存儲在host指定的 replica set 或 standalone mongod中。
{
"_id" : "shard_name",
"host" : "replica_set_name/host:port",
"tag":[shard_tag1,shard_tag2]
}
2,databases集合保存分片集群中所有數據庫的信息,不管數據庫是否分片
db.databases.find()
如果在數據庫上執行sh.enableSharding(“db_name”) ,那麼字段partitioned字段值就是true;primary 字段指定數據庫的主分片(primary shard)。
{
"_id" : "test",
"primary" : "rs0",
"partitioned" : true
}
3,collections集合保存所有已分片集合的信息,不包括非分片集合(un-sharded collections)
key是:分片的片鍵
db.collections.find()
{
"_id" : "test.foo",
"lastmodEpoch" : ObjectId("57dcd4899bd7f7111ec15f16"),
"lastmod" : ISODate("1970-02-19T17:02:47.296Z"),
"dropped" : false,
"key" : {
"_id" : 1
},
"unique" : true
}
4,chunks 集合保存數據塊信息,
ns:分片的集合,結構是:db_name.collection_name
min 和 max: 片鍵的最小值和最大值
shard:塊所在的分片
db.chunks.find()
{
"_id" : "test.foo-_id_MinKey",
"lastmod" : Timestamp(1, 1),
"lastmodEpoch" : ObjectId("57dcd4899bd7f7111ec15f16"),
"ns" : "test.foo",
"min" : {
"_id" : 1
},
"max" : {
"_id" : 3087
},
"shard" : "rs0"
}
5,changelog集合記錄分片集群的操作,包括chunk的拆分和遷移操作,Shard的增加或刪除操作
what 字段:表示操作的類型,例如:multi-split表示chunk的拆分,
"what" : "addShard", "what" : "shardCollection.start", "what" : "shardCollection.end", "what" : "multi-split",
6,tags 記錄shard的tag和對應的片鍵范圍
{
"_id" : { "ns" : "records.users", "min" : { "zipcode" : "10001" } },
"ns" : "records.users",
"min" : { "zipcode" : "10001" },
"max" : { "zipcode" : "10281" },
"tag" : "NYC"
}
7,settings 集合記錄均衡器狀態和chunk的大小,默認的chunk size是64MB。
{ "_id" : "chunksize", "value" : 64 }
{ "_id" : "balancer", "stopped" : false }
8,locks 集合記錄分布鎖(distributed lock),保證只有一個mongos 實例能夠在分片集群中執行管理任務。
mongos在擔任balancer時,會獲取一個分布鎖,並向config.locks中插入一條doc。
The locks collection stores a distributed lock. This ensures that only one mongos instance can perform administrative tasks on the cluster at once. The mongos acting as balancer takes a lock by inserting a document resembling the following into the locks collection.
{
"_id" : "balancer",
"process" : "example.net:40000:1350402818:16807",
"state" : 2,
"ts" : ObjectId("507daeedf40e1879df62e5f3"),
"when" : ISODate("2012-10-16T19:01:01.593Z"),
"who" : "example.net:40000:1350402818:16807:Balancer:282475249",
"why" : "doing balance round"
}
三,刪除分片
刪除分片時,必須確保該分片上的數據被移動到其他分片中,對於以分片的集合,使用均衡器來遷移數據塊,對於非分片的集合,必須修改集合的主分片。
1,刪除已分片的集合數據
step1,保證均衡器是開啟的
sh.setBalancerState(true);
step2,將已分片的集合全部遷移到其他分片
use admin
db.adminCommand({"removeShard":"shard_name"})
removeShard命令會將數據塊從當前分片上遷移到其他分片上去,如果分片上的數據塊比較多,遷移過程可能耗時很長。
step3,檢查數據塊遷移的狀態
use admin
db.runCommand( { removeShard: "shard_name" } )
使用removeShard命令能夠查看數據塊遷移的狀態,remaining 字段表示剩余數據塊的數量
{
"msg" : "draining ongoing",
"state" : "ongoing",
"remaining" : {
"chunks" : 42,
"dbs" : 1
},
"ok" : 1
}
step4,數據塊完成遷移
use admin
db.runCommand( { removeShard: "shard_name" } )
{
"msg" : "removeshard completed successfully",
"state" : "completed",
"shard" : "shard_name",
"ok" : 1
}
2,刪除未分片的數據庫
step1,查看未分片的數據庫
未分片的數據庫,包括兩部分:
1、數據庫未被分片,該數據沒有使用sh.enableSharding(“db_name”) ,在數據庫config中,該數據庫的partitioned字段是false
2、數據庫中存在collection未被分片,即當前的分片是該集合的主分片
use config
db.databases.find({$or:[{"partitioned":false},{"primary":"shard_name"}]})
對於partitioned=false的數據庫,其數據全部保存在當前shard中;對於partitioned=true,primary=”shard_name“的數據庫,表示存在未分片(un-sharded collection)存儲在該數據庫中,必須變更這些集合的主分片。
step2,修改數據庫的主分片
db.runCommand( { movePrimary: "db_name", to: "new_shard" })
四,增加分片
由於分片存儲的是數據集的一部分,為了保證數據的高可用性,推薦使用Replica Set作為shard,即使Replica Set中只包含一個成員。連接到mongos,使用sh輔助函數增加分片。
sh.addShard("replica_set_name/host:port")
不推薦將standalone mongod作為shard
sh.addShard("host:port")
五,特大塊
在有些情況下,chunk會持續增長,超出chunk size的限制,成為特大塊(jumbo chunk),出現特大塊的原因是chunk中的所有doc使用同一個片鍵(shard key),導致MongoDB無法拆分該chunk,如果該chunk持續增長,將會導致chunk的分布不均勻,成為性能瓶頸。
在chunk遷移時,存在限制:每個chunk的大小不能超過2.5萬條doc,或者1.3倍於配置值。chunk size默認的配置值是64MB,超過限制的chunk會被MongoDB標記為特大塊(jumbo chunk),MongoDB不能將特大塊遷移到其他shard上。
MongoDB cannot move a chunk if the number of documents in the chunk exceeds either 250000 documents or 1.3 times the result of dividing the configured chunk size by the average document size.
1,查看特大塊
使用sh.status(),能夠發現特大塊,特大塊的後面存在 jumbo 標志
{ "x" : 2 } -->> { "x" : 3 } on : shard-a Timestamp(2, 2) jumbo
2,分發特大塊
特大塊不能拆分,不能通過均衡器自動分發,必須手動分發。
step1,關閉均衡器
sh.setBalancerState(false)
step2,增大Chunk Size的配置值
由於MongoDB不允許移動大小超出限制的特大塊,因此,必須臨時增加chunk size的配置值,再將特大塊均衡地分發到分片集群中。
use config
db.settings.save({"_id":"chunksize","value":"1024"})
step3,移動特大塊
sh.moveChunk("db_name.collection_name",{sharded_filed:"value_in_chunk"},"new_shard_name")
step4,啟用均衡器
sh.setBalancerState(true)
step5,刷新mongos的配置緩存
強制mongos從config server同步配置信息,並刷新緩存。
use admin
db.adminCommand({ flushRouterConfig: 1 } )
六,均衡器
均衡器是由mongos轉變的,就是說,mongos不僅負責將查詢路由到相應的shard上,還要負責數據塊的均衡。一般情況下,MongoDB會自動處理數據均衡,通過config.settings能夠查看balancer的狀態,或通過sh輔助函數查看
sh.getBalancerState()
返回true,表示均衡器在正運行,系統自動處理數據均衡,使用sh輔助函數能夠關閉balancer
sh.setBalancerState(false)
balancer不能立即終止正在運行的塊遷移操作,在mongos轉變為balancer時,會申請一個balancer lock,查看config.locks 集合,
use config
db.locks.find({"_id":"balancer"})
--or
sh.isBalancerRunning()
如果state=2,表示balancer正處於活躍狀態,如果state=0,表示balancer已被關閉。
均衡過程實際上是將數據塊從一個shard遷移到其他shard,或者先將一個大的chunk拆分小的chunk,再將小塊遷移到其他shard上,塊的遷移和拆分都會增加系統的IO負載,最好將均衡器的活躍時間限制在系統空閒時進行,可以設置balancer的活躍時間窗口,限制balancer在指定的時間區間內進行數據塊的拆分和遷移操作。
use config
db.settings.update(
{"_id":"balancer"},
"$set":{"activeWindow":{"start":"23:00","stop":"04:00"}}),
true
)
均衡器拆分和移動的對象是chunk,均衡器只保證chunk數量在各個shard上是均衡的,至於每個chunk包含的doc數量,並不一定是均衡的。可能存在一些chunk包含的doc數量很多,而有些chunk包含的doc數量很少,甚至不包含任何doc。因此,應該慎重選擇分片的索引鍵,即片鍵,如果一個字段既能滿足絕大多數查詢的需求,又能使doc數量均勻分布,那麼該字段是片鍵的最佳選擇。
總結
以上就是這篇文章的全部內容,希望對大家的學習或者工作帶來一定的幫助,如果有疑問的大家可以留言交流。