關於副本集
副本集是一種在多台機器同步數據的進程。
副本集體提供了數據冗余,擴展了數據可用性。在多台服務器保存數據可以避免因為一台服務器導致的數據丟失。
也可以從硬件故障或服務中斷解脫出來,利用額外的數據副本,可以從一台機器致力於災難恢復或者備份。
在一些場景,可以使用副本集來擴展讀性能。客戶端有能力發送讀寫操作給不同的服務器。
也可以在不同的數據中心獲取不同的副本來擴展分布式應用的能力。
mongodb副本集是一組擁有相同數據的mongodb實例,主mongodb接受所有的寫操作,所有的其他實例可以接受主實例的操作以保持數據同步。
主實例接受客戶可的寫操作,副本集只能有一個主實例,因為為了維持數據一致性,只有一個實例可寫,主實例的日志保存在oplog。
Client Application Driver
Writes Reads
| |
Primary
|Replication|Replication
Secondary Secondary
二級節點復制主節點的oplog然後在自己的數據副本上執行操作,二級節點是主節點數據的反射,如果主節點不可用,會選舉一個新的主節點。默認讀操作是在主節點進行的,但是可以指定讀取首選項參數來指定讀操作到副本節點。
可以添加一個額外的仲裁節點(不擁有被選舉權),使副本集節點保持奇數,確保可以選舉出票數不同的直接點。仲裁者並不需要專用的硬件設備。
仲裁者節點一直會保存仲裁者身份。
1.異步復制
副本節點同步直接點操作是異步的,然而會導致副本集無法返回最新的數據給客戶端程序。
2.自動故障轉移
如果主節點10s以上與其他節點失去通信,其他節點將會選舉新的節點作為主節點。
擁有大多數選票的副節點會被選舉為主節點。
副本集提供了一些選項給應用程序,可以做一個成員位於不同數據中心的副本集。
也可以指定成員不同的優先級來控制選舉。
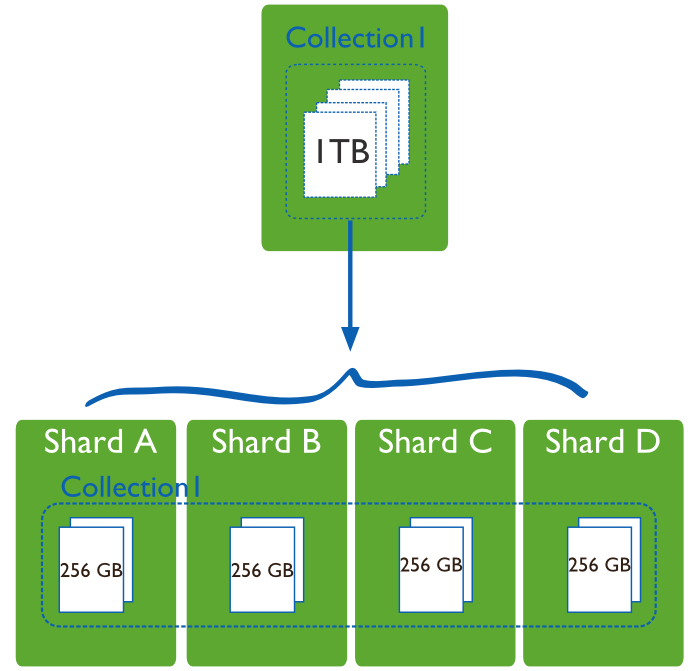
sharding轉換一個副本集為分片集群
1. 部署一個測試副本集
創建第一個副本集實例,名稱為firstset:
1.1 創建副本集並且插入數據如下:
/data/example/firstset1 /data/example/firstset2 /data/example/firstset3
創建目錄:
mkdir -p /data/example/firstset1 /data/example/firstset2 /data/example/firstset3
1.2 在其他終端啟動三個mongodb實例,如下:
mongod --dbpath /data/example/firstset1 --port 10001 --replSet firstset --oplogSize 700 --rest --fork --logpath /data/example/firstset1/firstset1.log --logappend --nojournal --directoryperdb mongod --dbpath /data/example/firstset2 --port 10002 --replSet firstset --oplogSize 700 --rest --fork --logpath /data/example/firstset2/firstset2.log --logappend --nojournal --directoryperdb mongod --dbpath /data/example/firstset3 --port 10003 --replSet firstset --oplogSize 700 --rest --fork --logpath /data/example/firstset3/firstset3.log --logappend --nojournal --directoryperdb
--oplog選項強制每個mongodb實例操作日志為700M,不使用該參數則默認為分區空間的5%,限制oplog的大小,可以使每個實例啟動的快一點。
1.3 連接一個mongodb實例的shell
mongo mongo01:10001/admin
如果是運行在生產環境下,或者不同主機名或IP的機器上,需要修改mongo01為指定名稱。
1.4 在mongo shell上初始化副本集
var config = {
"_id" : "firstset",
"members" : [
{"_id" : 0, "host" : "mongo01:10001"},
{"_id" : 1, "host" : "mongo01:10002"},
{"_id" : 2, "host" : "mongo01:10003"},
]
}
rs.initiate(config);
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}
或
db.runCommand(
{"replSetInitiate" :
{"_id" : "firstset",
"members" : [
{"_id" : 0, "host" : "mongo01:10001"},
{"_id" : 1, "host" : "mongo01:10002"},
{"_id" : 2, "host" : "mongo01:10003"}
]
}
}
)
1.5 在mongo shell中創建並插入數據:
use mydb
switched to db mydb
animal = ["dog", "tiger", "cat", "lion", "elephant", "bird", "horse", "pig", "rabbit", "cow", "dragon", "snake"];
for(var i=0; i<100000; i++){
name = animal[Math.floor(Math.random()*animal.length)];
user_id = i;
boolean = [true, false][Math.floor(Math.random()*2)];
added_at = new Date();
number = Math.floor(Math.random()*10001);
db.test_collection.save({"name":name, "user_id":user_id, "boolean": boolean, "added_at":added_at, "number":number });
}
上面的操作會向集合test_collection插入100萬條數據,根據系統不同,可能會花費幾分鐘的時間。
腳本會加入如下格式的文檔:
2. 部署一個分片設施
創建三個配置服務器來保存集群的元數據。
對於開發或者測試環境下,一個配置服務器足夠了,在生產環境下,需要三天配置服務器,因為它們只需要占用很少的資源來保存元數據。
2.1 創建配置服務器的數據文件保存目錄:
/data/example/config1 /data/example/config2 /data/example/config3
創建目錄:
mkdir -p /data/example/config1 /data/example/config2 /data/example/config3
2.2 在另外的終端下,啟動配置服務器:
mongod --configsvr --dbpath /data/example/config1 --port 20001 --fork --logpath /data/example/config1/config1.log --logappend mongod --configsvr --dbpath /data/example/config2 --port 20002 --fork --logpath /data/example/config2/config2.log --logappend mongod --configsvr --dbpath /data/example/config3 --port 20003 --fork --logpath /data/example/config3/config3.log --logappend
2.3 在另外的終端下,啟動mongos實例:
mongos --configdb mongo01:20001,mongo01:20002,mongo01:20003 --port 27017 --chunkSize 1 --fork --logpath /data/example/mongos.log --logappend如果使用的是以前創建的表或者測試環境下,可以使用最小的chunksize(1M),默認chunksize為64M意味著在mongodb自動分片啟動前,集群必須擁有64MB的數據文件。
在生產環境下是不能使用很小的分片大小的。
configdb選項指定了配置服務器。mongos實例運行在默認的mongodb27017端口。
2.4 可以在mongos添加第一個分片,在新的終端執行以下命令:
2.4.1 連接mongos實例
mongo mongo01:27017/admin
2.4.2 使用addShard命令添加第一個分片
db.runCommand( { addShard : "firstset/mongo01:10001,mongo01:10002,mongo01:10003" } )
2.4.3 出現以下信息,表示成功:
{ "shardAdded" : "firstset", "ok" : 1 }
3. 部署另一個測試副本集
創建另外一個副本集實例,名稱為secondset:
3.1 創建副本集並且插入數據如下:
/data/example/secondset1 /data/example/secondset2 /data/example/secondset3
創建目錄:
mkdir -p /data/example/secondset1 /data/example/secondset2 /data/example/secondset3
3.2 在其他終端啟動三個mongodb實例,如下:
mongod --dbpath /data/example/secondset1 --port 30001 --replSet secondset --oplogSize 700 --rest --fork --logpath /data/example/secondset1/secondset1.log --logappend --nojournal --directoryperdb mongod --dbpath /data/example/secondset2 --port 30002 --replSet secondset --oplogSize 700 --rest --fork --logpath /data/example/secondset2/secondset2.log --logappend --nojournal --directoryperdb mongod --dbpath /data/example/secondset3 --port 30003 --replSet secondset --oplogSize 700 --rest --fork --logpath /data/example/secondset3/secondset3.log --logappend --nojournal --directoryperdb
3.3 連接一個mongodb實例的shell
mongo mongo01:20001/admin
3.4 在mongo shell上初始化副本集
db.runCommand(
{"replSetInitiate" :
{"_id" : "secondset",
"members" : [
{"_id" : 0, "host" : "mongo01:30001"},
{"_id" : 1, "host" : "mongo01:30002"},
{"_id" : 2, "host" : "mongo01:30003"}
]
}
}
)
3.5 將該副本集加入分片集群
db.runCommand( { addShard : "secondset/mongo01:30001,mongo01:30002,mongo01:30003" } )
返回成功信息:
{ "shardAdded" : "firstset", "ok" : 1 }
3.6 通過運行listShards命令證實分片都添加成功。如下:
db.runCommand({listShards:1})
{
"shards" : [
{
"_id" : "firstset",
"host" : "firstset/mongo01:10001,mongo01:10002,mongo01:10003"
},
{
"_id" : "secondset",
"host" : "secondset/mongo01:30001,mongo01:30002,mongo01:30003"
}
],
"ok" : 1
}