上篇文章給大家介紹了Mongodb中MapReduce實現數據聚合方法詳解,我們提到過Mongodb中進行數據聚合操作的一種方式——MapReduce,但是在大多數日常使用過程中,我們並不需要使用MapReduce來進行操作。在這邊文章中,我們就簡單說說用自帶的聚合函數進行數據聚合操作的實現。
MongoDB除了基本的查詢功能之外,還提供了強大的聚合功能。Mongodb中自帶的基本聚合函數有三種:count、distinct和group。下面我們分別來講述一下這三個基本聚合函數。
(1)count
作用:簡單統計集合中符合某種條件的文檔數量。
使用方式:db.collection.count(<query>)或者db.collection.find(<query>).count()
參數說明:其中<query>是用於查詢的目標條件。如果出了想限定查出來的最大文檔數,或者想統計後跳過指定條數的文檔,則還需要借助於limit,skip。
舉例:
復制代碼 代碼如下:
db.collection.find(<query>).limit();
db.collection.find(<query>).skip();
(2)distinct
作用:用於對集合中的文檔針進行去重處理
使用方式:db,collection.distinct(field,query)
參數說明:field是去重字段,可以是單個的字段名,也可以是嵌套的字段名;query是查詢條件,可以為空;
舉例:
db.collection.distinct("user",{“age":{$gt:28}});//用於查詢年齡age大於28歲的不同用戶名
除了上面的用法外,還可以使用下面的另外一種方法:
db.runCommand({"distinct":"collectionname","key":"distinctfied","query":<query>})
collectionname:去重統計的集合名,distinctfield:去重字段,,<query>是可選的限制條件;
舉例:
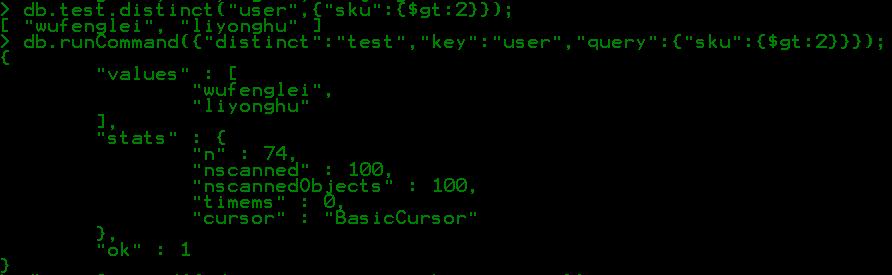
這兩種方式的區別:第一種方法是對第二種方法的封裝,第一種只返回去重統計後的字段值集合,但第二種方式既返回字段值集合也返回統計時的細節信息。
(3)group
作用:用於提供比count、distinct更豐富的統計需求,可以使用js函數控制統計邏輯
使用方式:db.collection.group(key,reduce,initial[,keyf][,cond][,finalize])
備注說明:在2.2版本之前,group操作最多只能返回10000條分組記錄,但是從2.2版本之後到2.4版本,mongodb做了優化,能夠支持返回20000條分組記錄返回,如果分組記錄的條數大於20000條,那麼可能你就需要其他方式進行統計了,比如聚合管道或者MapReduce;
上面對Mongodb中自帶的三種三種聚合函數進行了簡單的描述,並對需要注意的地方進行了簡單的說明,如果需要深入使用,可以進入Mongodb官網查看相關細節信息,謝謝。