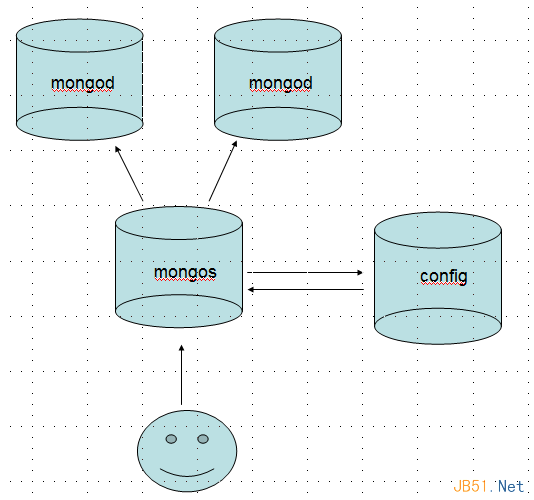
結論:
1、 200w數據,合理使用索引的情況下,單個stationId下4w數據。mongodb查詢和排序的性能理想,無正則時client可以在600ms+完成查詢,qps300+。有正則時client可以在1300ms+完成查詢,qps140+。
2、 Mongodb的count性能比較差,非並發情況下client可以在330ms完成查詢,在並發情況下則需要1-3s。可以考慮估算總數的方法,http://blog.sina.com.cn/s/blog_56545fd30101442b.html
測試環境:mongodb使用 replica set,1主2從,96G內存,版本2.6.5
Mem消耗(4個200w數據的collection):
空間消耗(測試數據最終選定的collection):
Jvm: -Xms2G -Xmx2G
Ping延遲33ms
查詢都使用ReadPreference.secondaryPreferred()
無正則
1、 創建stationId, firmId復合引查詢場景(200w集合,12個字段)
查詢次數:20000
查詢條件:多條件查詢10條記錄,並逐條獲取記錄
String key = "清泉" + r.nextInt(1000);
Pattern pattern = Pattern.compile(key);
BasicDBObject queryObject = new BasicDBObject("stationId",
new BasicDBObject("$in", new Integer[]{20}))
.append("firmId", new BasicDBObject("$gt", 5000))
.append("dealCount", new BasicDBObject("$gt", r.nextInt(1000000))); DBCursor cursor = collection.find(queryObject).limit(10).skip(2);
並發:200
耗時:61566
單次耗時(server):124ms
Qps:324.85
2、 創建stationId, firmId復合引查詢場景(200w集合,12個字段)
查詢次數:20000
查詢條件:多條件查詢10條記錄排序,並逐條獲取記錄
String key = "清泉" + r.nextInt(100);
Pattern pattern = Pattern.compile(key);
BasicDBObject queryObject = new BasicDBObject("stationId",
new BasicDBObject("$in", new Integer[]{4, 20}))
.append("firmId", new BasicDBObject("$gt", 5000))
.append("dealCount", new BasicDBObject("$gt", r.nextInt(1000000))); DBCursor cursor = collection.find(queryObject)
.sort(new BasicDBObject("firmId", 1)).limit(10).skip(2);
並發:200
耗時:63187
單次耗時(server):119ms
Qps:316.52
3、 創建stationId, firmId復合引查詢場景(200w集合,12個字段)
查詢次數:2000
查詢條件:多條件查詢記錄數
String key = "清泉" + r.nextInt(100);
Pattern pattern = Pattern.compile(key);
BasicDBObject queryObject = new BasicDBObject("stationId",
new BasicDBObject("$in", new Integer[]{4, 20}))
.append("firmId", new BasicDBObject("$gt", 5000))
.append("dealCount", new BasicDBObject("$gt", r.nextInt(1000000)));
long count = collection.count(queryObject);
並發:200
耗時:21887
單次耗時(client):280ms
Qps:91.38
有正則
4、 創建stationId, firmId復合引查詢場景(200w集合,12個字段)
查詢次數:20000
查詢條件:多條件查詢10條記錄,並逐條獲取記錄
String key = "清泉" + r.nextInt(1000);
Pattern pattern = Pattern.compile(key);
BasicDBObject queryObject = new BasicDBObject("stationId",
new BasicDBObject("$in", new Integer[]{20}))
.append("firmId", new BasicDBObject("$gt", 5000))
.append ("dealCount", new BasicDBObject("$gt", r.nextInt(1000000)))
.append("firmName", pattern);
DBCursor cursor = collection.find(queryObject).limit(10).skip(2);
並發:200
耗時:137673
單次耗時(server):225ms
Qps:145.27
5、 創建stationId, firmId復合引查詢場景(200w集合,12個字段)
查詢次數:20000
查詢條件:多條件查詢10條記錄排序,並逐條獲取記錄
String key = "清泉" + r.nextInt(1000);
Pattern pattern = Pattern.compile(key);
BasicDBObject queryObject = new BasicDBObject("stationId",
new BasicDBObject("$in", new Integer[]{4, 20}))
.append("firmId", new BasicDBObject("$gt", 5000))
.append ("dealCount", new BasicDBObject("$gt", r.nextInt(1000000)))
.append("firmName", pattern);
DBCursor cursor = collection.find(queryObject)
.sort(new BasicDBObject("firmId", 1)).limit(10).skip(2);
並發:200
耗時:138673
單次耗時(server):230ms
Qps:144.22
6、 創建stationId, firmId復合引查詢場景(200w集合,12個字段)
查詢次數:2000
查詢條件:多條件查詢記錄數
String key = "清泉" + r.nextInt(1000);
Pattern pattern = Pattern.compile(key);
BasicDBObject queryObject = new BasicDBObject("stationId",
new BasicDBObject("$in", new Integer[]{4, 20}))
.append("firmId", new BasicDBObject("$gt", 5000))
.append ("dealCount", new BasicDBObject("$gt", r.nextInt(1000000)))
.append("firmName", pattern);
long count = collection.count(queryObject);
並發:200
耗時:23155
單次耗時(client):330ms
Qps:86.37
MongoDB索引特點
1、 復合索引必須命中首字段,否則無法生效。後面的字段可以不按順序命中。
2、 復合索引字段越多占用空間越大,但對查詢性能影響不大(數組索引除外)。
3、 會根據sort字段選擇索引,優先級超過復合索引中的非首字段。
4、 命中復合索引的情況下,數據量<10w的情況下,過濾非索引字段,效率也比較高。
5、 全文檢索性能比較差,200w數據命中50w的情況下,全文檢索需要10+s,正則需要1s。
MongoDB客戶端配置,可以提出來做成spring注入,設置最大連接數什麼的。
MongoClientOptions options =
MongoClientOptions.builder().maxWaitTime(1000 * 60 * 2)
.connectionsPerHost(500).build();
mongoClient = new MongoClient(Arrays.asList(new ServerAddress("10.205.68.57", 8700),
new ServerAddress("10.205.68.15", 8700),
new ServerAddress("10.205.69.13", 8700)), options);
mongoClient.setReadPreference(ReadPreference.secondaryPreferred());
mongoDB調研_結論.docx為最終場景下的測試數據,分為有正則和無正則。
mongoDB調研_remote.docx為測試驗證過程中的數據,有可能存在緩存等情況,不一定准確,功參考。
關於MongoDB 查詢優化原則的大家了解嗎?下文給大家介紹下,具體內容如下所示:
1.在查詢條件、排序條件、統計條件的字段上選擇創建索引,可以顯著提高查詢效率。
2.用$or時把匹配最多結果的條件放在最前面,用$and時把匹配最 少 結果的條件放在最前面。
3.使用limit()限定返回結果集的大小,減少數據庫服務器的資源消耗,以及網絡傳輸的數據量。
4.盡量少用$in,而是分解成一個一個的單一查詢。尤其是在分片上,$in會讓你的查詢去每一個分片上查一次,如果實在要用的話,先在每個分片上建索引。
5.盡量不用模糊匹配查詢,用其它精確匹配查詢代替,比如$in、$nin。
6.查詢量大、並發大的情況,通過前端加緩存解決。
7.能不用安全模式的操作就不用安全模式,這樣客戶端沒必要等待數據庫返回查詢結果以及處理異常,快了一個數量級。
8.MongoDB的智能查詢優化,判斷粒度為query條件,而skip和limit都不在其判斷之中,當分頁查詢最後幾頁時,先用order反向排序。
9.盡量減少跨分片查詢,balance均衡次數少。
10.只查詢要使用的字段,而不查詢所有字段。
11.更新字段的值時,使用$inc比update效率高。
12.apped collections比普通collections的讀寫效率高。
13.server-side processing類似於SQL查詢的存儲過程,可以減少網絡通訊的開銷。
14.必要時使用hint()強制使用某個索引查詢。
15.如果有自己的主鍵列,則使用自己的主鍵列作為id,這樣可以節約空間,也不需要創建額外的所以。
16.使用explain,根據exlpain plan進行優化。
17.范圍查詢的時候盡量用$in、$nin代替。
18.查看數據庫查詢日志,具體分析的效率低的操作。
19.mongodb有一個數據庫優化工具database profiler,能夠檢測數據庫操作的性能。可以發現query或者write操作中執行效率低的,從而針對這些操作進行優化。
20.盡量把更多的操作放在客戶端,當然這就是mongodb設計的理念之一。