今天跟大家分享一下mongodb中比較好玩的知識,主要包括:聚合,游標。
一: 聚合
常見的聚合操作跟sql server一樣,有:count,distinct,group,mapReduce。
<1> count
count是最簡單,最容易,也是最常用的聚合工具,它的使用跟我們C#裡面的count使用簡直一模一樣。
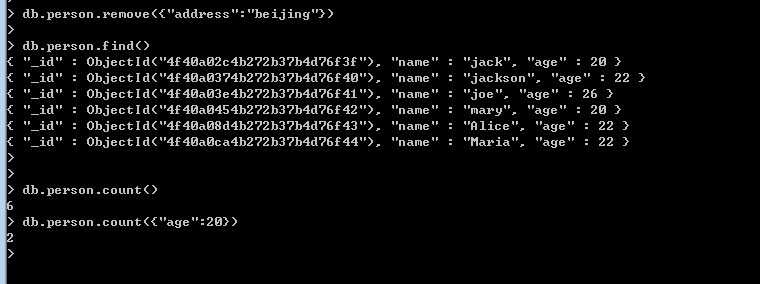
<2> distinct
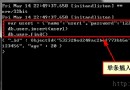
這個操作相信大家也是非常熟悉的,指定了誰,誰就不能重復,直接上圖。
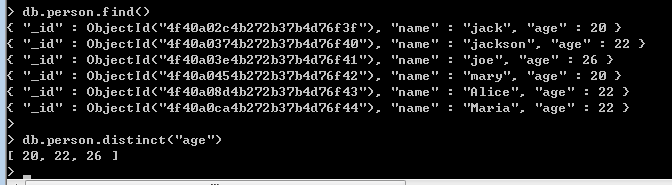
<3> group
在mongodb裡面做group操作有點小復雜,不過大家對sql server裡面的group比較熟悉的話還是一眼
能看的明白的,其實group操作本質上形成了一種“k-v”模型,就像C#中的Dictionary,好,有了這種思維,
我們來看看如何使用group。
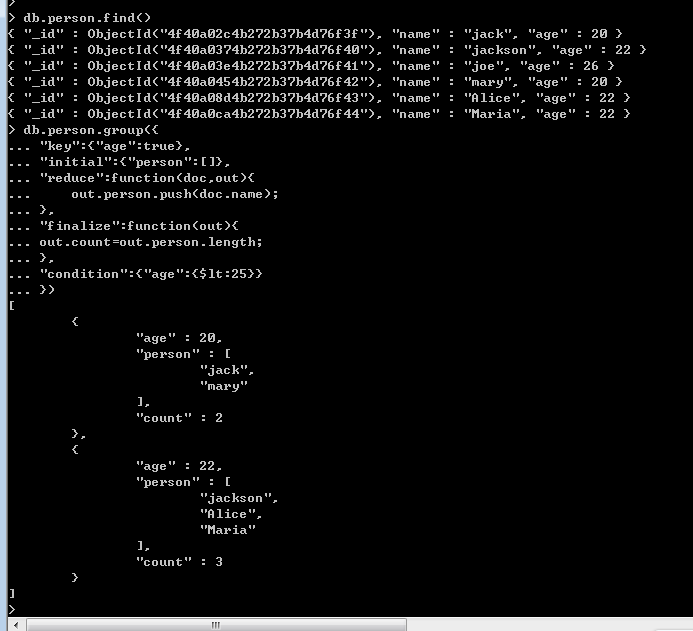
下面舉的例子就是按照age進行group操作,value為對應age的姓名。下面對這些參數介紹一下:
key: 這個就是分組的key,我們這裡是對年齡分組。
initial: 每組都分享一個”初始化函數“,特別注意:是每一組,比如這個的age=20的value的list分享一個
initial函數,age=22同樣也分享一個initial函數。
$reduce: 這個函數的第一個參數是當前的文檔對象,第二個參數是上一次function操作的累計對象,第一次
為initial中的{”perosn“:[]}。有多少個文檔, $reduce就會調用多少次。
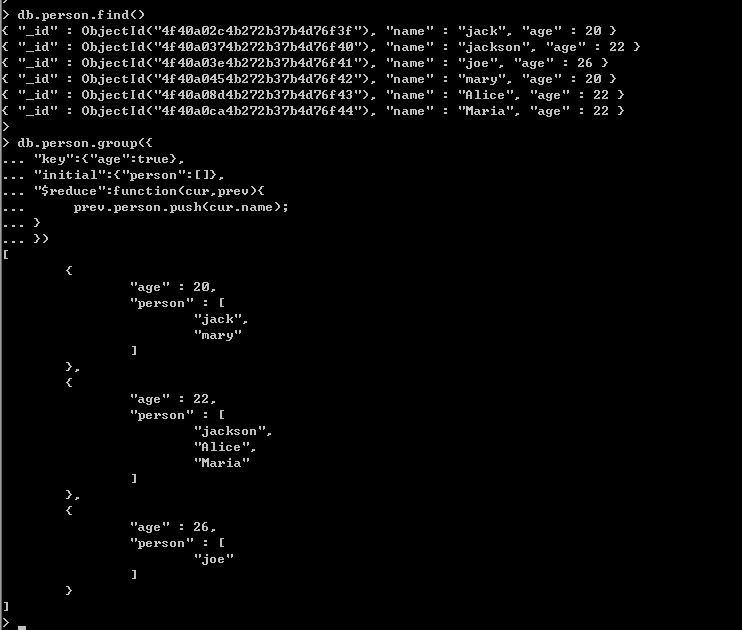
看到上面的結果,是不是有點感覺,我們通過age查看到了相應的name人員,不過有時我們可能有如下的要求:
①:想過濾掉age>25一些人員。
②:有時person數組裡面的人員太多,我想加上一個count屬性標明一下。
針對上面的需求,在group裡面還是很好辦到的,因為group有這麼兩個可選參數: condition 和 finalize。
condition: 這個就是過濾條件。
finalize:這是個函數,每一組文檔執行完後,多會觸發此方法,那麼在每組集合裡面加上count也就是它的活了。
<4> mapReduce
這玩意算是聚合函數中最復雜的了,不過復雜也好,越復雜就越靈活。
mapReduce其實是一種編程模型,用在分布式計算中,其中有一個“map”函數,一個”reduce“函數。
① map:
這個稱為映射函數,裡面會調用emit(key,value),集合會按照你指定的key進行映射分組。
② reduce:
這個稱為簡化函數,會對map分組後的數據進行分組簡化,注意:在reduce(key,value)中的key就是
emit中的key,vlaue為emit分組後的emit(value)的集合,這裡也就是很多{"count":1}的數組。
③ mapReduce:
這個就是最後執行的函數了,參數為map,reduce和一些可選參數。具體看圖可知:
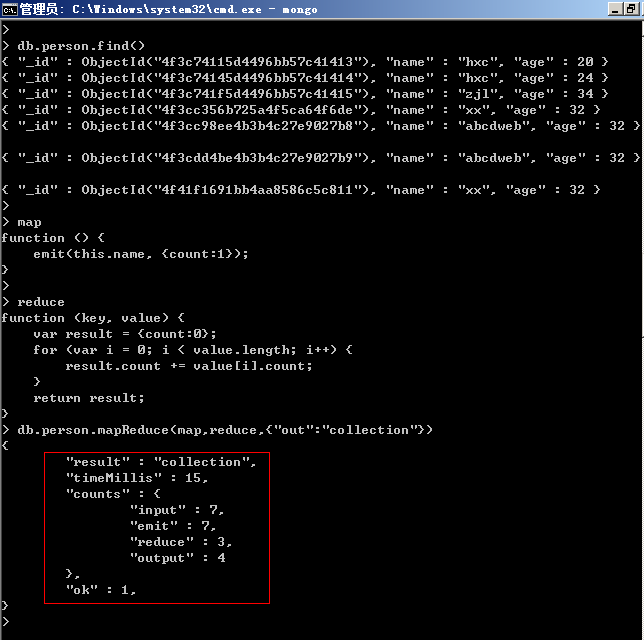
從圖中我們可以看到如下信息:
result: "存放的集合名“;
input:傳入文檔的個數。
emit:此函數被調用的次數。
reduce:此函數被調用的次數。
output:最後返回文檔的個數。
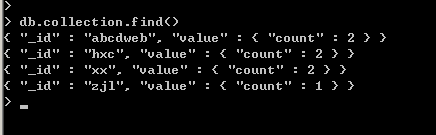
最後我們看一下“collecton”集合裡面按姓名分組的情況。
二:游標
mongodb裡面的游標有點類似我們說的C#裡面延遲執行,比如:
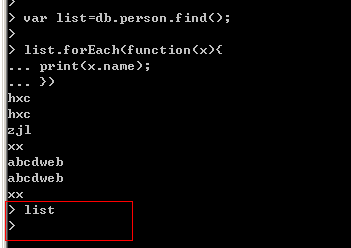
var list=db.person.find();
針對這樣的操作,list其實並沒有獲取到person中的文檔,而是申明一個“查詢結構”,等我們需要的時候通過
for或者next()一次性加載過來,然後讓游標逐行讀取,當我們枚舉完了之後,游標銷毀,之後我們在通過list獲取時,
發現沒有數據返回了。
當然我們的“查詢構造”還可以搞的復雜點,比如分頁,排序都可以加進去。
var single=db.person.find().sort({"name",1}).skip(2).limit(2);
那麼這樣的“查詢構造”可以在我們需要執行的時候執行,大大提高了不必要的花銷。