一、find操作
MongoDB中使用find來進行查詢,通過指定find的第一個參數可以實現全部和部分查詢。
1、查詢全部
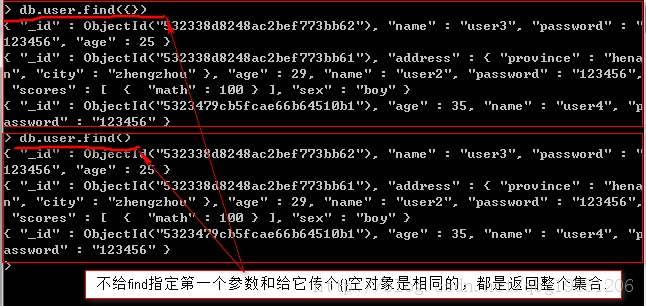
空的查詢文檔{}會匹配集合的全部內容。如果不指定查詢文檔,默認就是{}。
2、部分查詢
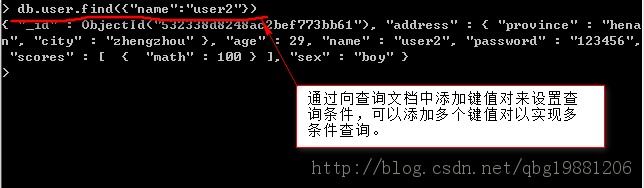
3、鍵的篩選
鍵的篩選是查詢時只返回自己感興趣的鍵值,通過指定find的第二個參數來實現。這樣可以節省傳輸的數據量,又能節省客戶端解碼文檔的時間和內存消耗。
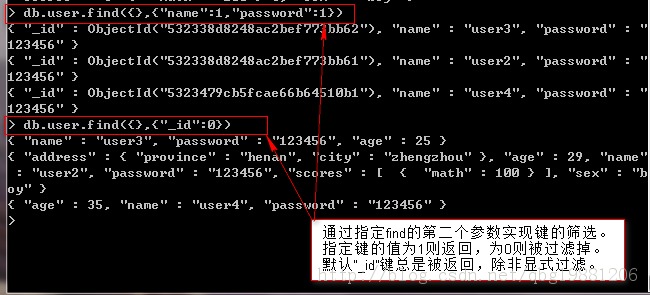
查詢時,數據庫所關心的查詢文檔的值必須是常量。
二、查詢條件
1、比較查詢
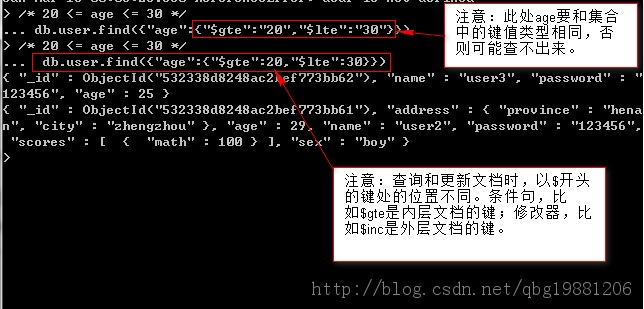
$lt,$lte,$gt,$gte,$ne和<,<=,>,>=,!=是一一對應的,它們可以組合起來以查找一個范圍內的值。
2、關聯查詢
$in用於查詢一個鍵的多個值,$nin將返回與篩選數組中所有條件都不匹配的文檔。將$in與$not組合可以實現$nin相同的效果。
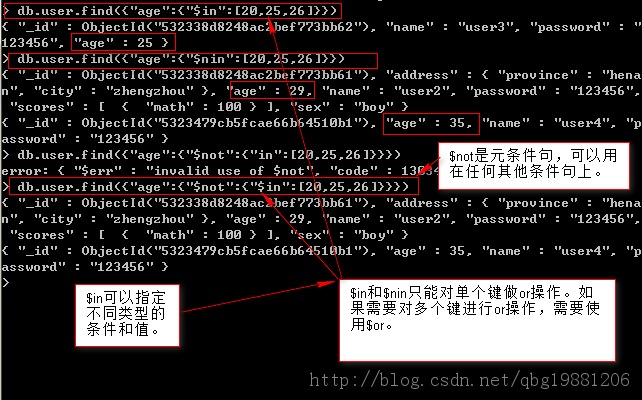
$or用於對多個鍵做or查詢。

三、特定類型的查詢
1、null查詢
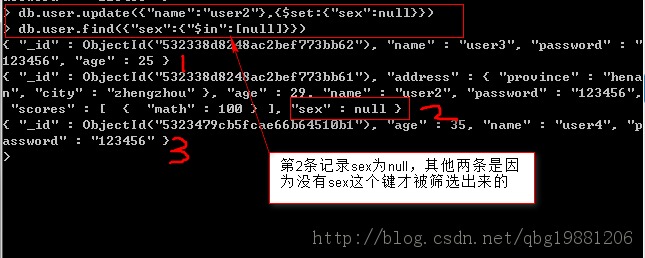
null不僅能匹配自身,還能匹配鍵不存在的文檔。
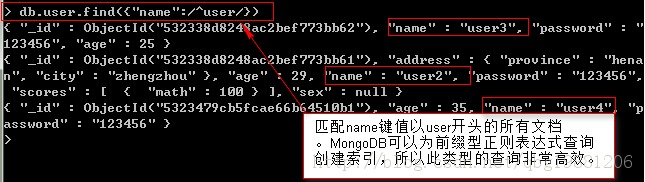
2、正則表達式
3、數組查詢
$all:通過多個元素來匹配數組。
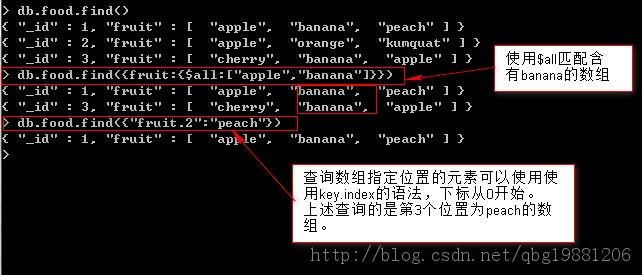
$size:查詢指定長度的數組。

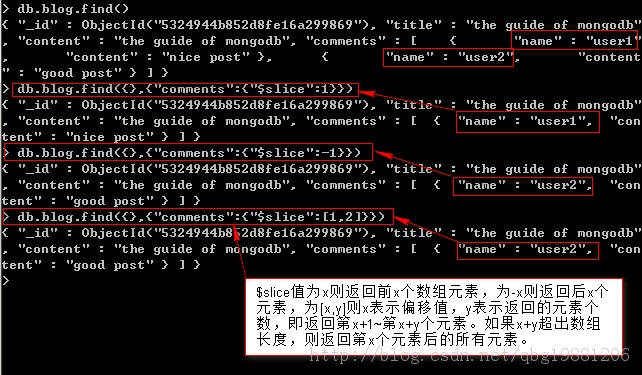
$slice:返回數組的一個子集合。
4、內嵌文檔查詢

四、$where查詢
$where查詢是MongoDB的高級查詢部分,可以執行任意JavaScript作為查詢的一部分,是其他查詢方式的一個補充。
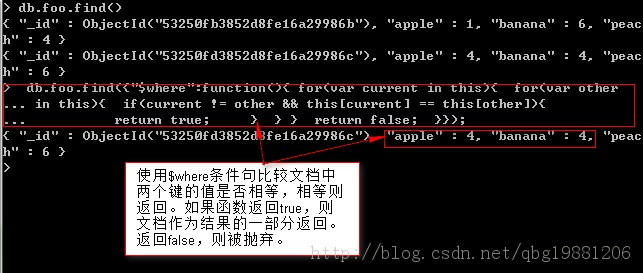
$where查詢需要將每個文檔從BSON轉換為JavaScript對象,然後通過$where的表達式來運行,該過程不能利用索引,所以查詢速度較常規查詢慢很多。如果必須使用時,可以將常規查詢作為前置過濾,能夠利用索引的話可以使用索引根據非$where子句進行過濾,最後使用$where對結果進行調優。另一種方式采用映射化簡-MapReduce.
五、游標
游標是很有用的東西,MongoDB數據庫使用游標來返回find的執行結果。客戶端使用游標可以對最終結果進行有效的控制,比如分頁,排序。
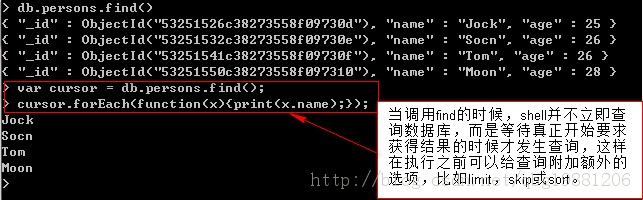
1、limit,skip和sort
limit:限制結果數量,限制的是上限。
skip:略過匹配到的前n個文檔,然後返回余下的文檔。skip略過過多的文檔時會產生性能問題,建議盡量避免。
sort:按照指定的鍵對文檔進行排序,1為升序,-1為降序。
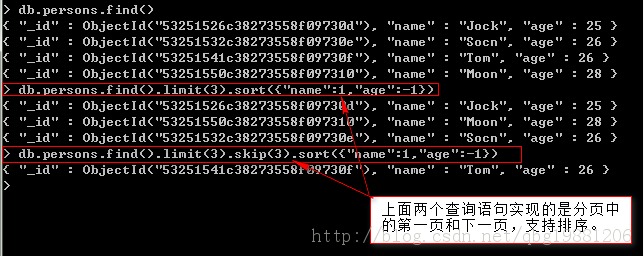
2、高級查詢選項
包裝查詢:使用sort,limit或skip對最終結果進行進一步的控制。
有用的配置選項:
$maxscan:integer,指定查詢最多掃描的文檔數量。
$min:document,查詢的開始條件。
$max:document,查詢的結束條件。
$hint:document,指定服務器使用哪個索引進行查詢。
$explain:boolean,獲取查詢執行的細節(用到的索引,結果數量,耗時等),而並非真正執行查詢。
$snapshot:boolean,確保查詢的結果是在查詢執行那一刻的一致快照,用於避免不一致讀取。
包裝查詢會將查詢條件包裝到一個更大的查詢文檔中,比如執行如下查詢時:
db.foo.find({"name":"bar"}).sort("x":1)shell會把查詢從{"name":"bar"}轉換成{"$query":{"name":"bar"},"$orderby":{"x":1}},而不是直接將{"name":"bar"}作為查詢文檔發送給數據庫。
3、游標內幕
看待游標的兩種角度:客戶端的游標及客戶端游標表示的數據庫游標(服務器端)。
在服務器端,游標消耗內存和其他資源,所以在合理的情況下需要盡快釋放。服務器端導致游標終止的情況如下:
1、游標完成匹配結果的迭代時自動清除。
2、游標在客戶端已不在作用域內的情況下,驅動會向服務器發送專門的消息,讓其銷毀游標。
3、超時銷毀,可以使用immortal函數關閉游標超時時間,采用此操作一定要在迭代完結果後將游標關閉。
六、總結
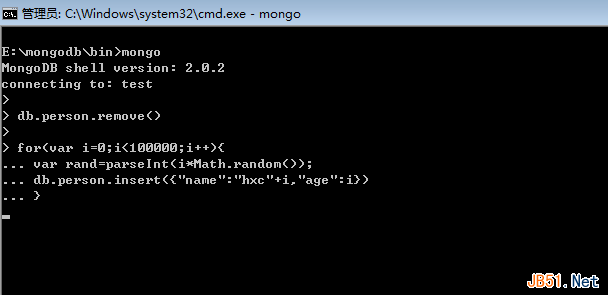
使用MongoDB需要對文檔結構進行合理的設計,以滿足某些特定需求。比如隨機選取文檔,使用skip跳過隨機個文檔就沒有在文檔中加個隨機鍵,然後使用某個隨機數對文檔進行查詢高效,隨機鍵還能添加索引,效率更高。合理選擇,合理設計。