事務是一組原子性的SQL查詢語句,也可以被看做一個工作單元。如果數據庫引擎能夠成功地對數據庫應用所有的查詢語句,它就會執行所有查詢,如果任何一條查詢語句因為崩潰或其他原因而無法執行,那麼所有的語句就都不會執行。也就是說,事務內的語句要麼全部執行,要麼一句也不執行。
事務的特性:acid,也稱為事務的四個測試(原子性,一致性,隔離性,持久性)
automicity:原子性,事務所引起的數據庫操作,要麼都完成,要麼都不執行
consisitency:一致性,事務執行前的總和和事務執行後的總和是不變的
isolation:隔離性, 某個事務的結果只有在完成之後才對其他事務可見
durability:持久性,一旦事務成功完成,系統必須保證任何故障都不會引起事務表現出不一致性
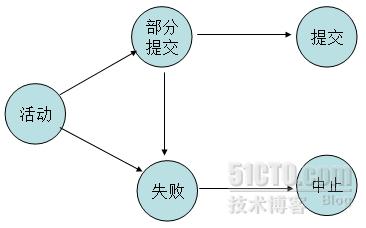
事務的狀態:
活動
部分提交
失敗
中止
提交
事務在某一時刻,一定處於上邊五種狀態中的一種,事務各狀態之間的轉換如下所示:
事務並發導致的問題
髒讀(Drity Read):某個事務已更新一份數據,另一個事務在此時讀取了同一份數據,由於某些原因,前一個RollBack了操作,則後一個事務所讀取的數據就會是不正確的。
不可重復讀(Non-repeatable read):在一個事務的兩次查詢之中數據不一致,這可能是兩次查詢過程中間插入了一個事務更新了原有的數據。
幻讀(Phantom Read):在一個事務的兩次查詢中數據不一致,例如有一個事務查詢了幾列(Row)數據,而另一個事務卻在此時插入了新的幾列數據,先前的事務在接下來的查詢中,就會發現有幾列數據是它先前所沒有的。
並發控制
多版本並發控制: Multiversion concurrency control,MVCC
每個用戶操作數據時都是源數據的時間快照,當用戶操作完成後,依據各快照的時間點在合並到源數據中
鎖:要想實現並發控制,最簡單的實現機制就是鎖(MVCC采用的不是鎖機制)。
讀鎖:共享鎖,由讀表操作加上的鎖,加鎖後其他用戶只能獲取該表或行的共享鎖,不能獲取排它鎖,也就是說只能讀不能寫
寫鎖:獨占鎖,由寫表操作加上的鎖,加鎖後其他用戶不能獲取該表或行的任何鎖
鎖粒度:從大到小,MySQL服務器僅支持表級鎖,行鎖需要存儲引擎完成。
表鎖:鎖定某個表
頁鎖:鎖定某個頁
行鎖:鎖定某行
粒度越精細,並發性越好。即行鎖的並發性最好,但需要存儲引擎的支持。
事務的四種隔離級別
讀未提交(read uncommitted): 允許髒讀,也就是可能讀取到其他會話中未提交事務修改的數據
讀提交(read committed): 只能讀取到已經提交的數據。oracle等多數數據庫默認都是該級別
可重讀(repeatable read): 在同一個事務內的查詢都是事務開始時刻一致的,innodb的默認級別。在SQL標准中,該隔離級別消除了不可重復讀,但是還存在幻象讀
可串行(serializable): 完全串行化的讀,每次讀都需要獲得表級共享鎖,讀寫相互都會阻塞
在MySQL中,在並發控制情況下,不同隔離級別分別有可能產生問題如下所示:
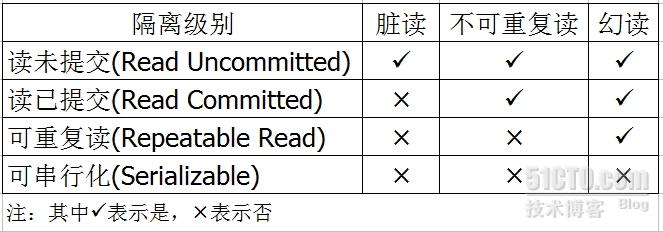
上邊之所以介紹那麼多理論知識,是為了便於理解。在上邊的表格中已經列出來了,在不同隔離級別下,數據的顯示效果可能出現的問題,現在在linux上安裝好mysql,通過我們的實驗來一起看一下在不同隔離級別下數據的顯示效果吧。
實驗環境:
linux系統:RedHat 5.8
linux內核:linux-2.6.18-308.el5
mysql版本:mysql-5.6.10-linux-glibc2.5-i686
本次實驗的所有操作均在虛擬機中完成,通過Xmanager連接虛擬機,然後打開兩個會話連接,在兩個會話中,同時更改隔離級別,然後查看數據的顯示效果。
本次實驗中mysql采用源碼編譯安裝的方式安裝mysql,你也可以使用rpm包的方式直接安裝mysql。具體源碼安裝的方式及過程,這裡不再演示,在前面的博客中,我已經介紹了很多次。如果你采用源碼編譯安裝的方式,不知道如何安裝mysql,可參看我以前寫的博客,裡邊都有介紹。采用源碼編譯安裝的方式,在mysql的配置文件中,最好啟用每表一個表空間。這裡我們直接啟用。
因為是實驗,這裡沒有對mysql設置密碼,因此,我們直接使用命令進入mysql。命令及顯示效果如下:
50[root@mysql ~]# mysql -uroot -p #使用該命令進入mysql,因為沒有設置密碼,在要求輸入密碼時直接按回車鍵即可
Enter password:
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 2
Server version: 5.6.10 MySQL Community Server (GPL)
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql> show variables like '%iso%'; #查看mysql默認的事務隔離級別,默認為可重讀。也可以使用select @@tx_isolation命令查看
+-----------------+------------------+
| Variable_name | Value |
+-----------------+------------------+
| tx_isolation | REPEATABLE-READ |
+-----------------+------------------+
1 row in set (0.36 sec)
mysql> show databases; #查看系統已經存在的數據庫
+---------------------+
| Database |
+---------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+---------------------+
4 rows in set (0.00 sec)
現在導入我們實驗所使用的數據庫。
[root@mysql ~]# mysql < jiaowu.sql #導入實驗所用的jiaowu數據庫
[root@mysql ~]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 7
Server version: 5.6.10 MySQL Community Server (GPL)
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql> show databases; #查看導入的jiaowu數據庫是否存在
+----------------------+
| Database |
+----------------------+
| information_schema |
| jiaowu |
| mysql |
| performance_schema |
| test |
+----------------------+
5 rows in set (0.01 sec)
我們在mysql命令界面下,沒有明確啟用事務時,輸入的每個命令都是直接提交的,因為mysql中有個變量的值,可實現自動提交。也就是說我們每輸入一個語句,都會自動提交,這會產生大量的磁盤IO,降低系統的性能。在我們做實驗時,因為我們要明確使用事務,所以,建議關閉自動提交的功能,如果不關閉也沒有關系,但是如果你沒有明確使用事務,想要做下邊的實驗,那就需要關閉此功能了。這裡,我們明確使用事務,且關閉自動提交功能。假如你關閉了自動提交功能,需明確使用事務,否則你輸入的所有語句會被當成一個事務進行處理。命令如下:
16mysql> select @@autocommit; #查看該值,為1表示啟動自動提交
+--------------+
| @@autocommit |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
mysql> set autocommit=0; #關閉自動提交功能
Query OK, 0 rows affected (0.00 sec)
mysql> select @@autocommit; #重新查看該值,為0表示關閉自動提交功能
+--------------+
| @@autocommit |
+--------------+
| 0 |
+--------------+
1 row in set (0.00 sec)
現在打開兩個會話,在這兩個會話中分別進入mysql,首先記得要就修改兩個回話中的autocommit變量,關閉自動提交功能,然後查看事務的隔離級別,默認為REPEATABLE-READ。在兩個會話中都需要修改隔離級別。我們先從最低的隔離級別開始演示。
30mysql> select @@tx_isolation;
+-------------------+
| @@tx_isolation |
+-------------------+
| REPEATABLE-READ |
+-------------------+
1 row in set (0.00 sec)
mysql> set tx_isolation='read-uncommitted'; #修改隔離級別,將隔離級別可重讀改為讀未提交
Query OK, 0 rows affected (0.00 sec)
mysql> select @@tx_isolation;
+-------------------+
| @@tx_isolation |
+-------------------+
| READ-UNCOMMITTED |
+-------------------+
在兩個回話中,修改完隔離級別後,使用導入的數據庫,用tutors表來驗證顯示效果。
mysql> use jiaowu; #使用jaiowu數據庫
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables; #查看該數據庫中都有那些表
+-------------------+
| Tables_in_jiaowu |
+-------------------+
| courses |
| scores |
| students |
| tutors |
+-------------------+
4 rows in set (0.00 sec)
在會話1中,我們來修改tutors中的數據,在會話2中我們來查看數據,看會是什麼情況。本打算使用tutors表來演示下邊的實驗,但修改完數據截圖時比較麻煩,所以,自己就寫了個腳本,比著tutors表的各字段創建了一個新表teachers。腳本寫的有點拙劣,有興趣可自己動手寫個更好的腳本來實現創建及插入數據。創建表及插入數據的腳本如下:
23#!/bin/bash
#
#Author: hulunbeier, http://lq2419.blog.51cto.com/
#Description: creating table and inserting data
#
let B=0
mysql -e "use jiaowu;create table teachers like tutors;"
read -p "Input a number to create NUMBER data. You choice : " NUM #執行該腳本是,會讓輸入一個數字,因為是實驗,所以我們這裡進插入5行數據,讀者可自行修改
for I in `seq 1 $NUM`; do
NAME=tech$I
A=`echo $RANDOM/365 | bc`
until [ $A -ge 40 ] && [ $A -le 100 ]; do
A=`echo $RANDOM/365 | bc`
done
B=`echo $RANDOM%2 | bc`
if [ $B = 0 ]; then
GD=F
else
GD=M
fi
mysql -e "insert into jiaowu.teachers (Tname,Gender,Age) values ('$NAME','$GD',$A);"
echo "create tech$I success."
done
執行上邊的腳本即可創建相應表及插入數據。查看下我們創建的新表是否成功,裡邊是否有數據。查詢命令及顯示結果如下所示:

創建的新表已經存在,且插入數據也已成功,現在我們就用teachers表來演示以下各實驗。演示實驗從低隔離級別開始,到高隔離級別結束。
Read-uncommitted:讀未提交
首先,修改兩個會話中的自動提交功能,將其關閉,然後修改系統默認的隔離級別,從低級別開始,將默認的可重讀改為讀未提交。
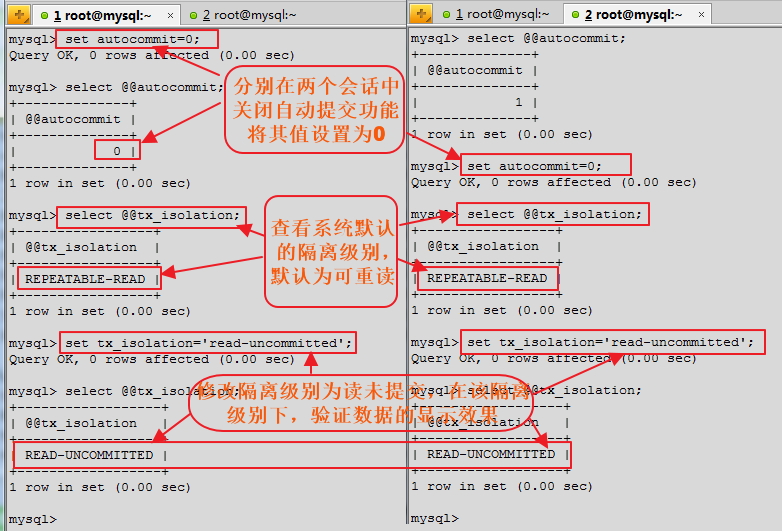
以上修改在兩個會話中完成後,我們明確啟動事務,查詢下表中的所有數據信息,顯示TID為5的老師的年齡為61,然後在會話1中更新teachers表中TID為5的老師的年齡,將原來的61改為50,接著,在兩個會話中在重新查詢下所有的數據,看TID為5的老師的年齡是多少。命令及顯示效果如下所示:
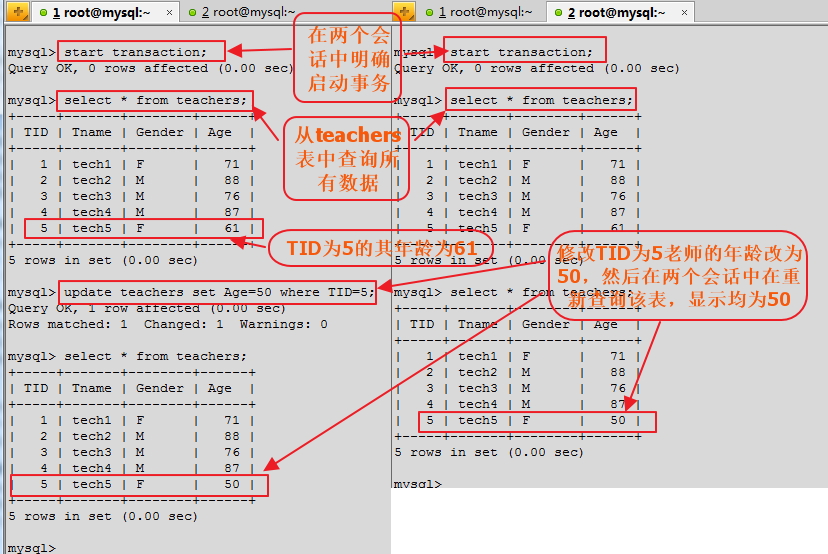
當我們在會話1中使用rollback回滾之後,再在兩個會話中查看數據,發現還是61。從上邊兩個會話的顯示效果,可以看到,在隔離級別為讀未提交時,當我們開啟一個事務時,在該事務中修改了某個數據行的信息,且在該事務中,並未提交,但在另一個事務中,如果都是對同一個數據集的操作,會發現我們前後兩次查詢的結果不一樣了,在同一個事務中,兩次查詢得到的結果不一樣,這種情況是不允許出現。此時就出現了髒讀、不可重復讀及幻讀的現象。
Read-committed:讀提交
首先在上邊修改的基礎上再次修改隔離級別,將讀未提交改為讀提交。然後,我們還去修改TID為5的老師的年齡,將61改為40。接著,在兩個會話中再次查看顯示效果。命令及顯示效果如下所示:
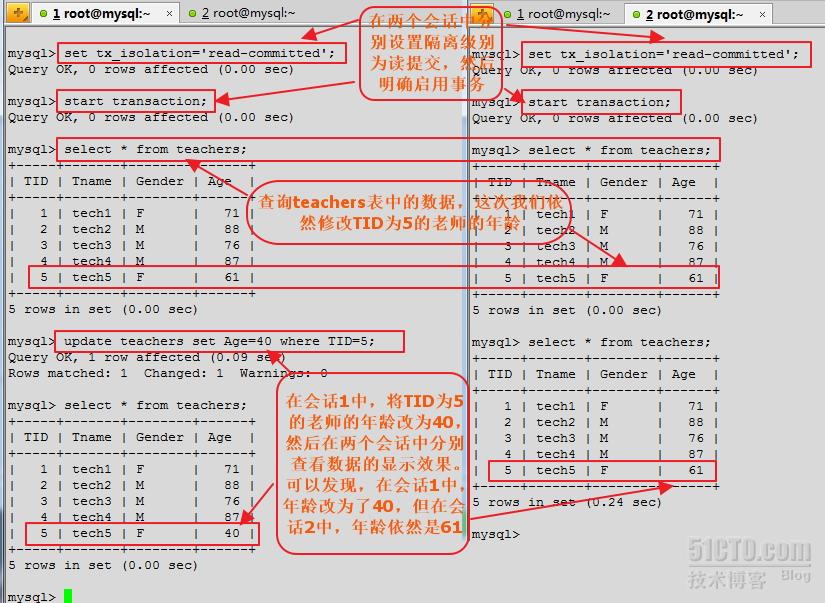
現在,在會話1中,我們使用commit命令提交事務,然後再會話2中,查看下顯示效果,看又是怎麼樣的。結果會發現,在會話2中,TID為5的老師的年齡變成了40。從上邊的顯示效果,會發現,當隔離級別為read-committed(讀提交)時,當我們在會話1中開啟事務,並修改了某一行數據的信息時,在會話1中可以看到修改後的效果,但在會話2中並不會看到修改後的結果。當我們在會話1中提交事務後,在再會話2中查詢,會發現,跟我們上次查詢的不一樣了,顯示的是會話1修改後的結果。在該隔離級別下,雖然可以避免髒讀的現象發生,但還是會出現不可重復讀和幻讀的現象。
Repeatable-read:可重讀
首先修改隔離級別,將讀提交改為可重讀。然後,在會話1中,依然修改TID為5的老師的年齡,將其年齡改為60。最後,兩個會話中再來查看結果。
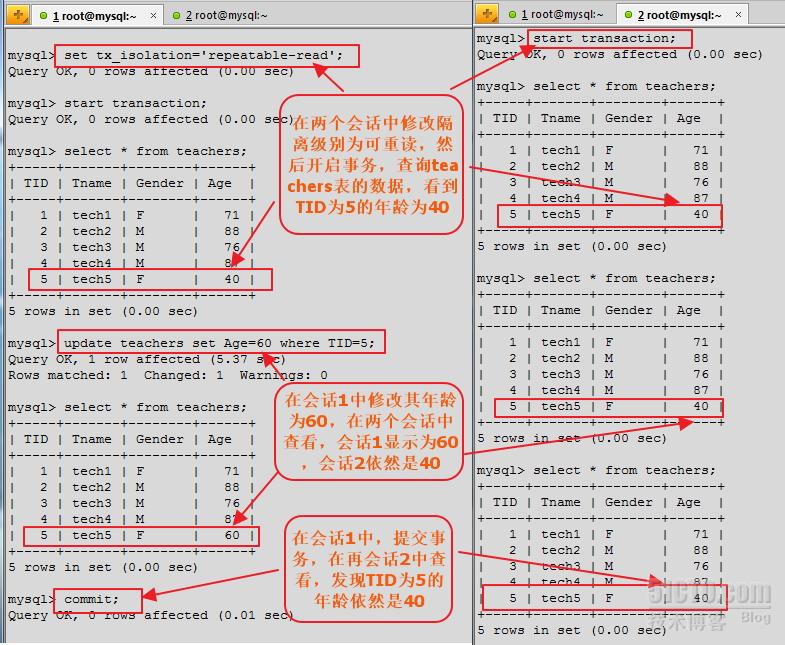
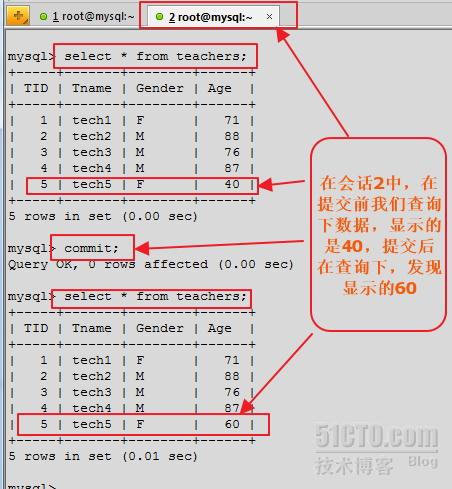
從上邊的顯示結果會發現,在該隔離級別下,當我們在會話1中修改了某個值時,會話1會立即顯示修改後的結果,而會話2中不會顯示。當我們在會話1中提交事務後,得到永久結果,在會話1中在查看,還是修改後的結果,但在會話2中,還是原來的結果。但當我們在會話2中提交事務後,再來查詢,發現是會話1中修改後的結果,在會話2中,我們沒做任何修改,我一提交事務,發現,數據竟然變了。起碼,事務提交前和提交後看到的數據是不一樣的。此時就出現了幻讀的現象。
Serializable:可串行
首先,我們依然修改隔離級別,將可重讀改為可串行。然後再會話1中,啟動事務,並將TID為5的老師的年齡由60改為100,然後,在會話1和2中查看。在沒有啟動事務前,我們先來看下TID為5的老師年齡是多少。
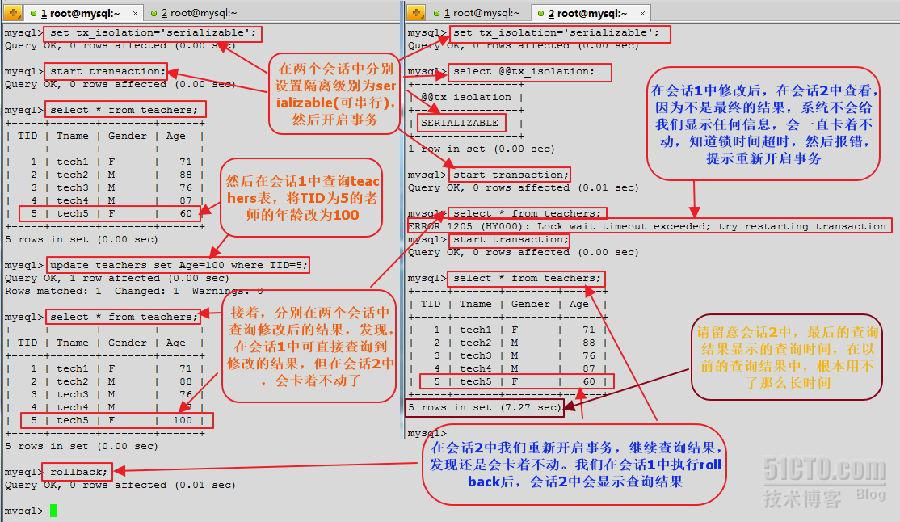
在上邊的顯示效果中,發現,在可串行隔離級別下,當我們啟動兩個事務時,如果在其中一個事務中,修改了某個數據行,在另一個事務中,我們是無法查詢到該數據集的信息的,也就是說系統不會顯示出任何信息,除非在修改的事務中,我們提交了,或者是執行了rollback命令。假如在修改的事務中,我們既沒有執行commit命令提交,也沒有執行rollback命令回滾,那麼,在另一個事務中,當我們查詢時,會一直卡著不動,直到鎖時間超時,然後提示我們重新開啟事務。在上圖中,發現,在會話1中,當我們啟動一個事務,並修改了一個數據後,在會話2中,我們是不能查詢到任何信息的,當我們在會話1中執行了rollback命令後,會話2中才會顯示查詢結果,此時的查詢所用時間會比以前查詢所用時間長很多。因為在可串行級別下,是不允許通知開啟多個事務的,或者說是不允許對同一個數據集執行任何操作的。此時,既不會出現髒讀、不可重復讀,也不會出現幻讀現象。但是此時的並發性會受影響。
綜上所述,在低隔離級別下,當有多個事務並發執行時,雖然會產生很多問題,如髒讀、不可重復讀、幻讀等現象,但事務的並發性較好,可同時執行多個事務;在高隔離級別下,當有多個事務並發執行時,因在高隔離級別下,不支持多事務並發執行,雖然不會出現諸如髒讀、不可重復讀及幻讀等現象,但並發性較低。InnoDB默認的隔離級別是repeatable-read(可重讀),而在大多數的數據庫中,oracle等多數數據庫,一般默認的隔離級別是read-committed(讀提交)。一般來說在實際應用中,除了在銀行、股票等對數據安全要求較高的場景外,必須使用較高隔離級別外,其他對數據要求不高的場合,可采用低隔離級別,以提高並發性。然而,究竟哪種隔離級別更適合,那就需要看你對數據的安全性要求有多高了。