一、 MySQL建表,字段需設置為非空,需設置字段默認值。
二、 MySQL建表,字段需NULL時,需設置字段默認值,默認值不為NULL。
三、 MySQL建表,如果字段等價於外鍵,應在該字段加索引。
四、 MySQL建表,不同表之間的相同屬性值的字段,列類型,類型長度,是否非空,是否默認值,需保持一致,否則無法正確使用索引進行關聯對比。
五、 MySQL使用時,一條SQL語句只能使用一個表的一個索引。所有的字段類型都可以索引,多列索引的屬性最多15個。
六、 如果可以在多個索引中進行選擇,MySQL通常使用找到最少行的索引,索引唯一值最高的索引。
七、 建立索引index(part1,part2,part3),相當於建立了 index(part1),index(part1,part2)和index(part1,part2,part3)三個索引。
八、 MySQL針對like語法必須如下格式才使用索引:
SELECT * FROM t1 WHERE key_col LIKE 'ab%' ;
九、 SELECT COUNT(*) 語法在沒有where條件的語句中執行效率沒有SELECT COUNT(col_name)快,但是在有where條件的語句中執行效率要快。
十、 在where條件中多個and的條件中,必須都是一個多列索引的key_part屬性而且必須包含key_part1。各自單一索引的話,只使用遍歷最少行的那個索引。
十一、 在where條件中多個or的條件中,每一個條件,都必須是一個有效索引。
十二、 ORDER BY 後面的條件必須是同一索引的屬性,排序順序必須一致(比如都是升序或都是降序)。
十三、 所有GROUP BY列引用同一索引的屬性,並且索引必須是按順序保存其關鍵字的。
十四、 JOIN 索引,所有匹配ON和where的字段應建立合適的索引。
十五、 對智能的掃描全表使用FORCE INDEX告知MySQL,使用索引效率更高。
十六、 定期ANALYZE TABLE tbl_name為掃描的表更新關鍵字分布 。
十七、 定期使用慢日志檢查語句,執行explain,分析可能改進的索引。
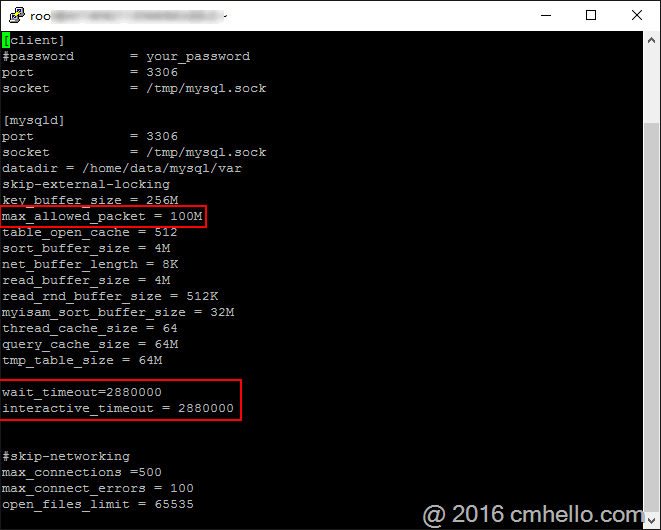
十八、 條件允許的話,設置較大的key_buffer_size和query_cache_size的值(全局參數),和sort_buffer_size的值(session變量,建議不要超過4M)。
備注
主鍵的命名采用如下規則:
主鍵名用pk_開頭,後面跟該主鍵所在的表名。主鍵名長度不能超過30個字符。如果過長,可對表名進行縮寫。縮寫規則同表名的縮寫規則。主鍵名用小寫的英文單詞來表示。
外鍵的命名采用如下規則:
外鍵名用fk_開頭,後面跟該外鍵所在的表名和對應的主表名(不含t_)。子表名和父表名自己用下劃線(_)分隔。外鍵名長度不能超過30個字符。如果過長,可對表名進行縮寫。縮寫規則同表名的縮寫規則。外鍵名用小寫的英文單詞來表示。
索引的命名采用如下規則:
1)索引名用小寫的英文字母和數字表示。索引名的長度不能超過30個字符。
2)主鍵對應的索引和主鍵同名。
3)唯一性索引用uni_開頭,後面跟表名。一般性索引用ind_開頭,後面跟表名。
4)如果索引長度過長,可對表名進行縮寫。縮寫規則同表名的縮寫規則
index 相關語法
例:
CREATE INDEX log_url ON logaudit_log(url);
show index from logaudit_log
drop index log_request_time on logaudit_log
sql執行效率檢測 mysql explain
explain顯示了mysql如何使用索引來處理select語句以及連接表。可以幫助選擇更好的索引和寫出更優化的查詢語句。
使用方法,在select語句前加上explain就可以了:
如:explain select surname,first_name form a,b where a.id=b.id
分析結果形式如下:
table | type | possible_keys | key | key_len | ref | rows | Extra
EXPLAIN列的解釋:
table
顯示這一行的數據是關於哪張表的
type
這是重要的列,顯示連接使用了何種類型。從最好到最差的連接類型為const、eq_reg、ref、range、indexhe和ALL
possible_keys
顯示可能應用在這張表中的索引。如果為空,沒有可能的索引。可以為相關的域從WHERE語句中選擇一個合適的語句
key
實際使用的索引。如果為NULL,則沒有使用索引。很少的情況下,MYSQL會選擇優化不足的索引。這種情況下,可以在SELECT語句中使用USE
INDEX(indexname)來強制使用一個索引或者用IGNORE INDEX(indexname)來強制MYSQL忽略索引
key_len
使用的索引的長度。在不損失精確性的情況下,長度越短越好
ref
顯示索引的哪一列被使用了,如果可能的話,是一個常數
rows
MYSQL認為必須檢查的用來返回請求數據的行數
Extra
關於MYSQL如何解析查詢的額外信息。將在表4.3中討論,但這裡可以看到的壞的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,結果是檢索會很慢
extra列返回的描述的意義
Distinct
一旦MYSQL找到了與行相聯合匹配的行,就不再搜索了
Not exists
MYSQL優化了LEFT JOIN,一旦它找到了匹配LEFT JOIN標准的行,
就不再搜索了
Range checked for each
Record(index map:#)
沒有找到理想的索引,因此對於從前面表中來的每一個行組合,MYSQL檢查使用哪個索引,並用它來從表中返回行。這是使用索引的最慢的連接之一
Using filesort
看到這個的時候,查詢就需要優化了。MYSQL需要進行額外的步驟來發現如何對返回的行排序。它根據連接類型以及存儲排序鍵值和匹配條件的全部行的行指針來排序全部行
Using index
列數據是從僅僅使用了索引中的信息而沒有讀取實際的行動的表返回的,這發生在對表的全部的請求列都是同一個索引的部分的時候
Using temporary
看到這個的時候,查詢需要優化了。這裡,MYSQL需要創建一個臨時表來存儲結果,這通常發生在對不同的列集進行ORDER BY上,而不是GROUP BY上
Where used
使用了WHERE從句來限制哪些行將與下一張表匹配或者是返回給用戶。如果不想返回表中的全部行,並且連接類型ALL或index,這就會發生,或者是查詢有問題
不同連接類型的解釋(按照效率高低的順序排序)
system
表只有一行:system表。這是const連接類型的特殊情況
const
表中的一個記錄的最大值能夠匹配這個查詢(索引可以是主鍵或惟一索引)。因為只有一行,這個值實際就是常數,因為MYSQL先讀這個值然後把它當做常數來對待
eq_ref
在連接中,MYSQL在查詢時,從前面的表中,對每一個記錄的聯合都從表中讀取一個記錄,它在查詢使用了索引為主鍵或惟一鍵的全部時使用
ref
這個連接類型只有在查詢使用了不是惟一或主鍵的鍵或者是這些類型的部分(比如,利用最左邊前綴)時發生。對於之前的表的每一個行聯合,全部記錄都將從表中讀出。這個類型嚴重依賴於根據索引匹配的記錄多少—越少越好
range
這個連接類型使用索引返回一個范圍中的行,比如使用>或
FAQ
1
表中包含 10 萬條記錄,有一個 datetime 類型的字段。
取數據的語句:
SELECT * FROM my_table WHERE created_at < '2010-01-20';
用 EXPLAIN 檢查,發現 type 是 ALL, key 是 NULL,根本沒用上索引。
可以確定的是,created_at 字段設定索引了。
什麼原因呢?
用 SELECT COUNT(*) 看了一下符合 WHERE 條件的記錄總數,居然是 6W 多條!!
難怪不用索引,這時用索引毫無意義,就好像 10 萬條記錄的用戶表,有個性別字段,不是男就是女,在這種字段設置索引是錯誤的決定。
稍微改造一下上述語句:
SELECT * FROM my_table WHERE created_at BETWEEN '2009-12-06' AND '2010-01-20';
這回問題解決!
符合條件的記錄只有幾百條,EXPLAIN 的 type 是 range,key 是 created_at,Extra 是 Using where 。
自己總結個准則,索引的目的就是盡量縮小結果集,這樣才能做到快速查詢。
6萬條記錄符合條件,已經超出總記錄數的一半,這時索引已經沒有意義了,因此 MySQL 放棄使用索引。
這與設置 gender 字段,並加上索引的情況相似,當你要把所有男性記錄都選取出來,符合條件的記錄數約占總數的一半,MySQL 同樣不會使用這個索引。
唯一值越多的字段,使用索引的效果越好。
設置聯合索引時,唯一值越多的,越應該放在“左側”。