概述
在一般的項目開發中,對數據表的多表查詢是必不可少的。而對於存在大量數據量的情況時(例如百萬級數據量),我們就需要從數據庫的各個方面來進行優化,本文就先從多表查詢開始。其他優化操作,後續另外更新,敬請關注。
數據背景
現假設有一個中學學校,學校中的年級有一年級、二年級、三年級,每個年級有兩個班級。分別為101、102、201、202、301、302.
現在我們要為這個學校建立一個考試成績統計系統。為此,我們對數據庫的設計畫了如下ER圖: 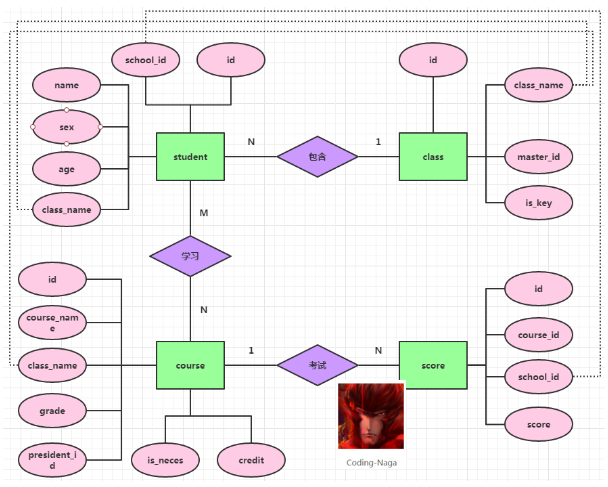
根據ER圖,我們設計了數據表,結構如下:
class 班級表:
+------------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| class_name | int(11) | NO | | NULL | |
| master_id | int(11) | YES | | NULL | |
| is_key | int(11) | NO | | NULL | |
+------------+---------+------+-----+---------+----------------+
student 學生表:
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| school_id | int(11) | NO | | NULL | |
| name | varchar(30) | NO | | NULL | |
| sex | int(11) | NO | | NULL | |
| age | int(11) | NO | | NULL | |
| class_name | int(11) | NO | | NULL | |
+------------+-------------+------+-----+---------+----------------+
course 課程表:
+--------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| course_name | varchar(10) | NO | | NULL | |
| grade | int(11) | NO | | NULL | |
| president_id | int(11) | YES | | NULL | |
| is_neces | int(11) | NO | | NULL | |
| credit | int(11) | NO | | NULL | |
| class_name | int(11) | YES | | NULL | |
+--------------+-------------+------+-----+---------+----------------+
score 成績表:
+-----------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| course_id | int(11) | NO | | NULL | |
| school_id | int(11) | NO | | NULL | |
| score | int(11) | YES | | NULL | |
+-----------+---------+------+-----+---------+----------------+
注:關於本文的數據庫數據大家可以在文章最下方的相關下載中獲取。資源鏈接中有兩個版本的數據庫,school.sql為初始數據庫,school_2.sql為優化後的數據庫。
連接(JOIN)簡介
內連(INNER JOIN)
INNER JOIN 關鍵字在表中存在至少一個匹配時返回行。
我們也用下面的交集維恩圖來描述內連操作:
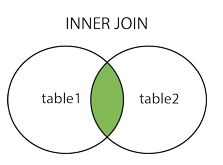
上面的維恩圖只是表達了一個有限制情況(即存在JOIN ON),而對於沒有約束的情況下,其實就是一個笛卡爾積運算。
*注:**INNER JOIN 與 JOIN 是相同的。一般情況下,在SQL語句中可以省略*INNER關鍵字。
左連接(LEFT JOIN)
LEFT JOIN 關鍵字從左表(table1)返回所有的行,即使右表(table2)中沒有匹配。如果右表中沒有匹配,則結果為 NULL。
使用維恩圖描述內連操作:
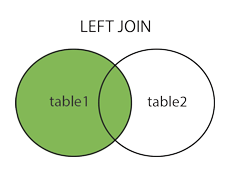
對於上面結果為 NULL的這一條,通過對實際測試的數據表進行操作,得到如下的測試結果:
+------------+-------+
| class_name | name |
+------------+-------+
| 202 | NULL |
| 301 | Bob |
| 302 | Alice |
+------------+-------+
右連接(RIGHT JOIN)
RIGHT JOIN 關鍵字從右表(table2)返回所有的行,即使左表(table1)中沒有匹配。如果左表中沒有匹配,則結果為 NULL。
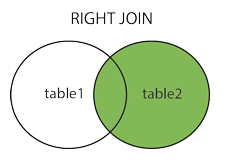
注:右連接可以理解成左連接的對稱互補,詳細說明可參見左連接。
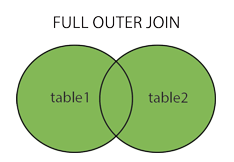
全連(FULL JOIN)
FULL OUTER JOIN 關鍵字只要左表(table1)和右表(table2)其中一個表中存在匹配,則返回行.
FULL OUTER JOIN 關鍵字結合了 LEFT JOIN 和 RIGHT JOIN 的結果。
聯合(UNION)
UNION 操作符用於合並兩個或多個 SELECT 語句的結果集。
請注意,UNION 內部的每個 SELECT 語句必須擁有相同數量的列。列也必須擁有相似的數據類型。同時,每個 SELECT 語句中的列的順序必須相同。
MySQL的JOIN實現原理
在MySQL 中,只有一種Join 算法,就是大名鼎鼎的Nested Loop Join,他沒有其他很多數據庫所提供的Hash Join,也沒有Sort Merge Join。顧名思義,Nested Loop Join 實際上就是通過驅動表的結果集作為循環基礎數據,然後一條一條的通過該結果集中的數據作為過濾條件到下一個表中查詢數據,然後合並結果。如果還有第三個參與Join,則再通過前兩個表的Join 結果集作為循環基礎數據,再一次通過循環查詢條件到第三個表中查詢數據,如此往復。
– 《MySQL性能調優與架構設計》
多表查詢實戰
查詢各個班級的班長姓名
優化分析
對於這個多表的查詢使用where是可以很好地完成查詢,而查詢的結果從表面上看,完全沒什麼問題,如下:
+------------+---------+
| class_name | name |
+------------+---------+
| 101 | William |
| 102 | Peter |
| 201 | Judy |
| 202 | Polly |
| 301 | Grace |
| 302 | Sunny |
+------------+---------+
可是,由於我們使用的是where,這個與內連接在有條件限制的情況下是一樣的,其維恩圖也可以一並參考。可是,如果現在我們假設,有一個新的班級303,或是這個303的班級暫時還沒有班長。這個時候通過where就無法完成查詢了。上面的結果中就已經很好地給出解釋。
這個時候,我們就需要通過外連接中的左連接(如果采用右連接,那麼相應的表位置也要進行替換)來進行查詢了。在左連的查詢中,因為是包含了”左表“的全部行,所以對於未選出班長的303來說,這個很有必要。采用左連操作的結果如下:
+------------+---------+
| class_name | name |
+------------+---------+
| 101 | William |
| 102 | Peter |
| 201 | Judy |
| 202 | Polly |
| 301 | Grace |
| 302 | Sunny |
| 303 | NULL |
+------------+---------+
SQL展示
樸素的WHERE
SELECT cl.class_name, st.name FROM class cl, student st WHERE cl.master_id=st.school_id;
INNER JOIN
SELECT cl.class_name, st.name FROM class cl JOIN student st ON cl.master_id=st.school_id;
LEAF JOIN
SELECT cl.class_name, st.name FROM class cl LEFT JOIN student st ON cl.master_id=st.school_id;
RIGHT JOIN
SELECT cl.class_name, st.name FROM student st RIGHT JOIN class cl ON cl.master_id=st.school_id;
利用 EXPLAIN 檢查優化器
通過EXPLAIN我們分別檢查上面WHERE語句和LEFT JOIN的優化過程。結果如下:
WHERE
+----+-------------+-------+------+---------------+------+---------+------+------+--------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+--------------------------------+
| 1 | SIMPLE | cl | ALL | NULL | NULL | NULL | NULL | 7 | |
| 1 | SIMPLE | st | ALL | NULL | NULL | NULL | NULL | 301 | Using where; Using join buffer |
+----+-------------+-------+------+---------------+------+---------+------+------+--------------------------------+
LEFT JOIN
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | cl | ALL | NULL | NULL | NULL | NULL | 7 | |
| 1 | SIMPLE | st | ALL | NULL | NULL | NULL | NULL | 301 | |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
對於上面的兩個結果,我們可以看到有一個很明顯的區別在於Extra。
Using where說明進行了where的過濾操作,Using join buffer說明進行join緩存。
從上面的結果中,還可以看到每種情況的兩種查詢操作都是經過了全表掃描。而這對於大量數據而言是很不利的。
現在,我們可以為被驅動表的join字段添加索引,再對其進行EXPLAIN檢查。
添加索引
ALTER TABLE student ADD INDEX index_school_id (school_id);
通過EXPLAIN我們分別檢查上面WHERE語句和LEFT JOIN的優化過程。結果如下:
WHERE
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
| 1 | SIMPLE | cl | ALL | NULL | NULL | NULL | NULL | 7 | |
| 1 | SIMPLE | st | ref | index_school_id | index_school_id | 4 | school.cl.master_id | 1 | |
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
LEFT JOIN
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
| 1 | SIMPLE | cl | ALL | NULL | NULL | NULL | NULL | 7 | |
| 1 | SIMPLE | st | ref | index_school_id | index_school_id | 4 | school.cl.master_id | 1 | |
+----+-------------+-------+------+-----------------+-----------------+---------+---------------------+------+-------+
現在,可以很明顯地看出rows列的數值,在被驅動表處都是1,這大降低了查詢的復雜度。而且對於type列,也從一開始的ALL變成了現在的ref。還有一些其他的列也被修改了。
查詢番外
根據學號查詢一個學生的成績單
WHERE 查詢
EXPLAIN SELECT st.name, co.course_name, sc.score FROM student st, score sc, course co WHERE sc.school_id=st.school_id AND co.id=sc.course_id AND st.school_id=100005;
JOIN 查詢
EXPLAIN SELECT st.name, co.course_name, sc.score FROM student st JOIN score sc ON sc.school_id=st.school_id JOIN course co ON co.id=sc.course_id WHERE st.school_id=100005;
結果
+----+-------------+-------+--------+---------------------------------------+--------------------+---------+---------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------------------------------+--------------------+---------+---------------------+------+-------+
| 1 | SIMPLE | st | ref | index_school_id | index_school_id | 4 | const | 1 | |
| 1 | SIMPLE | sc | ref | index_school_id_sc,index_course_id_sc | index_school_id_sc | 4 | const | 3 | |
| 1 | SIMPLE | co | eq_ref | PRIMARY | PRIMARY | 4 | school.sc.course_id | 1 | |
+----+-------------+-------+--------+---------------------------------------+--------------------+---------+---------------------+------+-------+
優化總結
SQL語句表
創建數據庫
CREATE DATABASE school;
創建數據表
學生表
CREATE TABLE student( id INT NOT NULL AUTO_INCREMENT, /* 學生表id */ school_id INT(11) NOT NULL, /* 學號 */ name VARCHAR(30) NOT NULL, /* 姓名 */ sex INT NOT NULL, /* 性別 */ age INT NOT NULL, /* 年齡 */ class_name INT NOT NULL, /* 班級名稱 */ PRIMARY KEY (id) /* 學生表主鍵 */ ); INSERT INTO student(school_id, name, sex, age, class_name) VALUES(100005, 'Bob', 1, 17, 301);
班級表
CREATE TABLE class( id INT NOT NULL AUTO_INCREMENT, /* 班級表id */ class_name INT NOT NULL, /* 班級名稱 */ master_id INT, /* 班長id */ is_key INT NOT NULL, /* 是否重點班級 */ PRIMARY KEY (id) /* 班級表主鍵 */ ); INSERT INTO class(class_name, master_id, is_key) VALUES(301, 100001, 1);
課程表
CREATE TABLE course(
id INT NOT NULL AUTO_INCREMENT, /* 課程表id */
course_name VARCHAR(10) NOT NULL, /* 課程名稱 */
grade INT NOT NULL, /* 當前課程所屬年級 */
president_id INT, /* 課代表id */
is_neces INT NOT NULL, /* 是否必修課 */
credit INT NOT NULL, /* 學分 */
PRIMARY KEY (id) /* 課程表主鍵 */
);
INSERT INTO course(course_name, grade, president_id, is_neces, credit) VALUES('math', 3, 100214, 1, 4);
ALTER table course ADD column class_name INT;
成績表
CREATE TABLE score( id INT NOT NULL AUTO_INCREMENT, /* 成績表id */ course_id INT NOT NULL, /* 課程id */ school_id INT NOT NULL, /* 學號 */ score INT, /* 考試成績 */ PRIMARY KEY (id) /* 成績表主鍵 */ ); INSERT INTO score(course_id, school_id, score) VALUES(1, 100005, 88);
導入導出
/* 導出數據庫 */ MYSQLDUMP -u root -p school > F:/Data/MySQL/school.sql /* 導入數據庫 */ SOURCE /root/upload/school.sql;
索引操作
/* 添加索引 */ ALTER TABLE class ADD INDEX index_master_id (master_id); /* 刪除索引 */ DROP INDEX index_name ON talbe_name;
查詢實戰
查詢所有課程名稱
SELECT course_name FROM course GROUP BY course_name;
查詢一個學生全部課程
/* 子查詢 */ SELECT course_name FROM course WHERE id in (SELECT course_id FROM score WHERE school_id=100005);
統計每個班級有多少學生
SELECT class_name, count(*) FROM student GROUP BY class_name;
根據學號查詢一個學生的成績單
/* WHERE */ SELECT st.name, co.course_name, sc.score FROM student st, score sc, course co WHERE sc.school_id=st.school_id AND co.id=sc.course_id AND st.school_id=100005; /* JOIN */ SELECT st.name, co.course_name, sc.score FROM student st JOIN score sc ON sc.school_id=st.school_id JOIN course co ON co.id=sc.course_id AND st.school_id=100005;
查詢各個班級的班長姓名
/* WHERE */ SELECT cl.class_name, st.name FROM class cl, student st WHERE cl.master_id=st.school_id; /* 子查詢 */ SELECT st.class_name, st.name FROM student st WHERE st.school_id in (SELECT master_id FROM class); /* JOIN */ SELECT cl.class_name, st.name FROM class cl JOIN student st ON cl.master_id=st.school_id; /* LEFT JOIN */ SELECT cl.class_name, st.name FROM class cl LEFT JOIN student st ON cl.master_id=st.school_id; /* RIGHT JOIN */ SELECT cl.class_name, st.name FROM student st RIGHT JOIN class cl ON cl.master_id=st.school_id;
其他查詢
SELECT name, class_name FROM student GROUP BY class_name UNION ALL SELECT id, class_name FROM class;
原文鏈接:http://blog.csdn.net/lemon_tree12138/article/details/50921193
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持。