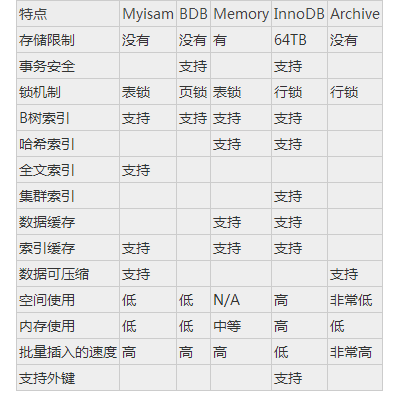
數據庫對象表時存儲和操作數據的邏輯結構,而數據庫對象存儲過程和函數,則是用來實現將一組關於表操作的sql語句當作一個整體來執行。在數據庫系統中,當調用存儲過程和函數時,則會執行這些對象中所設置的sql語句組,從而實現相應功能。
1. 為什麼使用存儲過程和函數的操作
有時針對表的一個完整操作往往不是單條sql語句就可以實現的,而是需要一組sql語句來實現。在具體應用當中,一個完整的操作會包含多條sql語句,在執行過程中需要根據前面sql語句的執行結果有選擇地執行後面sql語句。
存儲過程和函數可以簡單理解為一條或多條sql語句的集合。存儲過程和函數就是事先經過編譯並存儲在數據庫中的一段sql語句集合。
存儲過程和函數有什麼區別呢?這兩者的主要區別在於函數必須有返回值,而存儲過程則沒有。存儲過程的參數類型遠遠多於函數的參數類型。
關於存儲過程和函數的優點如下:
1. 存儲過程和函數允許標准組件式編程,提高了sql語句的重用性、共享性和可移植性。
2. 存儲過程和函數能夠實現較快的執行速度,能夠減少網絡流量。
3. 存儲過程和函數可以作為一種安全機制來利用。
關於存儲過程和函數的缺點如下:
1. 存儲過程和函數的編寫比單句sql語句復雜,需要用戶有更高的技能和更豐富的經驗。
2. 在編寫存儲過程和函數時,需要創建這些數據庫對象的權限。=
2. 創建存儲過程和函數
2.1 創建存儲過程語法形式:
語法形式如下:
create procedure procedure_name([procedure_parameter[,...]]) [characteristic...] routine_body //說明:procedure_name參數表示所要創建的存儲過程的名字,procedure_parameter參數表示存儲過程的參數, characteristic參數表示存儲過程的特性,routine_body參數表示存儲過程的sql語句代碼,可以用begin...end來標志sql語句的開始和結束。 //注意:在具體創建存儲過程時,存儲過程名不能和已經存在的存儲過程名重復,推薦存儲過程名為procedure_xxx或者proce_xxx; //procedure_parameter 中每個參數的語法形式為: [IN|OUT|INOUT] parameter_name type //該語句中每個參數由三部分組成,分別為輸入/輸出類型、參數名和參數類型。
characteristic參數的取值為:
language sql
|[not] deterministic
|{constains sql | no sql | reads sql data|modifies sql data}
|sql security {definer | invoker}
|comment 'string'
1. language sql,表示存儲過程的routine_body部分由sql語言的語句組成。為mysql軟件所有默認的語句。
2. [not] deterministic,表示存儲過程的執行結果是否確定。如果值是deterministic表示執行結果是確定的。即每次執行存儲過程時,如果輸入相同的參數將得到相同的輸出;如果值為not deterministic,表示執行結果不確定,即相同的輸入可能得到不同的輸出。默認值為deterministic。
3. {contains sql|no sql|reads sql data|modifies sql data},表示sql語句的限制,如果值為contains sql表示可以包含sql語句,但不包含讀或寫數據的語句;如果值為no sql表示不包含sql語句;如果值為reads sql data表示包含讀數據的語句;如果值為modifies sql data表示包含讀數據的語句。默認值為contains sql。
4. sql security{definer|invoker},設置誰有權限來執行。如果值為definer,表示只有定義者才能執行,如果值為invoker表示調用者可以執行。默認值為definer。
5. comment ‘string', 表示注釋語句。
2.2 創建函數語法形式:
語法形式如下:
create function function_name([function_parameter[,...]]) [characteristic...] routine_body
上述語句中,function_name參數表示所要創建的函數的名字;function_parameter參數表示函數的參數,characteristic參數表示函數的特性,該參數的取值與存儲過程中的取值相同。routine_body參數表示函數的sql語句代碼,可以用begin…end來表示sql語句的開始和結束。
function_parameter中每個參數的語法形式如下:
parameter_name type
在上述語句中每個參數由兩部分組成,分別為參數名和參數類型。parameter_name表示參數名。type表示參數類型。
2.3 創建簡單的存儲過程和函數:
//查詢雇員表中所有雇員工資的存儲過程:
示例:
mysql> delimiter $$
mysql> delimiter $$ create procedure proce_employee_sal()
comment '查詢所有雇員的工資'
begin
select sal from t_employee;
end $$
dilimiter ;
通常在創建存儲過程時,通過命令delimiter && 將sql語句的結束符由“;”符號修改成兩個美元符號。這主要是因為sql語句中默認語句結束符為分好(;),即存儲過程中的sql語句也需要用分號來結束,將結束符號修改成兩個美元符之後,就可以在執行過程中避免沖突。不過最後不要忘記將通過命令“delimiter ;”將結束符修改為sql語句中默認的結束符號。
創建函數示例:
delimiter $$ create function func_employee_sal (empno int(11)) returns double(10,2) comment '查詢某個雇員的工資' begin return ( select sal from t_employee where t_employee.empno=empno; ) end$$ delimiter ;
創建了一個名為func_employee_sal的函數,該函數擁有一個類型為int(11),名為empno的參數,返回值為double(10,2)類型。select語句從t_employee表中查詢empnoo字段值等於所傳入參數empno值的記錄,同時將該條記錄的sal字段的值返回。
3. 關於存儲過程和函數的表達式
3.1 操作變量:
變量是表達式語句中最基本的元素,可以用來臨時存儲數據。可以通過變量存儲從表中查詢到的數據。
3.1.1 聲明變量:
語法形式如下:
declare var_name[,...] type [default value]
在上述語句中,var_name參數表示要聲明的變量的名字;參數type表示所要聲明變量的類型;default value用來實現設置變量的默認值,如果無該語句默認值為null。在具體聲明變量時,可以同時定義多個變量。
3.1.2 賦值變量:
語法形式如下:
語法一:
set var_name=expr[,...]
語法二:
select filed_name[,...] into var_name[,...]
from table_name
where condition
var_name參數表示所要賦值變量名字,參數expr是關於變量的賦值表達式。在為變量賦值時,可以同時為多個變量賦值,各個變量的賦值語句之間用逗號隔開。
語法二中將查詢到的結果賦值給變量,參數filed_name表示查詢的字段名,參數var_name表示變量名。將查詢結果賦值給變量,該查詢語句的返回結果只能是單行。
示例:
declare employee_sal int default 1000; declare employee_sal int default 1000; set employee_sal = 3500; select sal into employee_sal from t_employee where empno=7556;
3.2 操作條件:
3.2.1 定義條件:
語法形式如下:
declare condition_name condition for condition_value condition_value: sqlstate[value] sqlstate_value |mysql_error_code
condition_name參數表示所要定義的條件名稱;參數condition_value用來實現設置條件的類型;參數sqlstate_value和mysql_error_code用來設置條件的錯誤。
3.2.2 定義處理程序:
語法形式為:
declare handler_type handler for condition_value[,...] sp_statement handler_type: continue |exit |undo condition_value: sqlstate[value] sqlstate_value |condition_name |sqlwarning |not found |sqlexception |mysql_error_code
這個語句指定每個可以處理一個或多個條件的處理程序。如果產生一個或多個條件,指定的語句被執行。對一個continue處理程序,當前子程序的執行處理程序語句之後繼續。對於exit處理程序,當前begin…end復合語句的執行被終止。undo處理程序類型語句還不被支持。
1. sqlwarning是對所有以01開頭的sqlstate代碼的速記。
2. not found是對所有以02開頭的sqlstate代碼的速記。
3. sqlexception 是對所有沒有被sqlwarning或not found捕獲的sqlstate代碼的速記。
3.3 使用游標:
mysql的查詢語句可以返回多條記錄結果,那麼在表達式中如何遍歷這些記錄結果呢?mysql提供了游標來實現。通過指定由select語句返回的行集合(包括滿足該語句的where子句所列條件的所有行),由該語句返回完整的行集合叫結果集。應用程序需要一種機制來一次處理結果集中的一行或連續的幾行,而游標通過每次指定一條記錄完成與應用程序的交互。
游標可以看做一種數據類型,可以用來遍歷結果集,相當是指針或數組的下標。處理結果集的方法可以通過游標定位到結果集的某一行,從當前結果集的位置搜索一行或者一部分行或者結果集中的當前行進行數據修改。
3.3.1 聲明游標:
語法形式如下:
declare cursor_name cursor for select_statement;
上述語句中,cursor_name參數表示有游標的名稱,參數select_statement表示select語句。因為游標需要遍歷結果集中的每一行,增加了服務器的負擔,導致游標的效率並不高。如果游標操作的數據超過1萬行,那麼應該采用其他方式,另外如果使用了游標,還應盡量避免在游標循環中進行表連接操作。
3.3.2 打開游標:
語法形式為:
open cursor_name
//注意,打開一個游標時,游標並不指向第一條記錄,而是指向第一條記錄的前邊。
3.3.3 使用游標:
語法形式如下:
fetch cursor_name into var_name [,var_name] ...
3.3.4 關閉游標:
語法形式如下:
close cursor_name
4. 修改存儲過程和函數
對於已經創建好的存儲過程和函數,當使用一段時間後,就會需要進行一些定義上的修改。可以通過alter procedure語句實現修改存儲過程,通過alter function語句實現修改函數。
4.1 修改存儲過程:
語法形式如下:
alter procedure procedure_name [characteristic...]
procedure_name參數表示所要修改存儲過程的名字,而characteristic參數指定修改後存儲過程的特性,與定義存儲過程的該參數相比,取值只能是如下值:
|(contains sql|no sql|reads sql data|modifys sql data)
|sql security {definer|invoker}
|comment ‘string'
)
4.2 修改函數:
語法形式如下:
alter function function_name [characteristic...]
function_name參數表示所要修改函數的名字,而characteristic參數指定修改後的函數特性,與定義函數的該參數相比,取值只能是如下值:
|(contains sql|no sql|reads sql data|modifys sql data)
|sql security {definer|invoker}
|comment ‘string'
5. 刪除存儲過程和函數
5.1 通過drop語句刪除存儲過程:
語法形式如下:
drop prcedure proce_name;
5.2 通過drop function語句刪除函數:
語法形式如下:
drop function func_name;
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持。