前言
排序是數據庫中的一個基本功能,MySQL也不例外。用戶通過Order by語句即能達到將指定的結果集排序的目的,其實不僅僅是Order by語句,Group by語句,Distinct語句都會隱含使用排序。本文首先會簡單介紹SQL如何利用索引避免排序代價,然後會介紹MySQL實現排序的內部原理,並介紹與排序相關的參數,最後會給出幾個“奇怪”排序例子,來談談排序一致性問題,並說明產生現象的本質原因。
1.排序優化與索引使用
為了優化SQL語句的排序性能,最好的情況是避免排序,合理利用索引是一個不錯的方法。因為索引本身也是有序的,如果在需要排序的字段上面建立了合適的索引,那麼就可以跳過排序的過程,提高SQL的查詢速度。下面我通過一些典型的SQL來說明哪些SQL可以利用索引減少排序,哪些SQL不能。假設t1表存在索引key1(key_part1,key_part2),key2(key2)
a.可以利用索引避免排序的SQL
SELECT * FROM t1 ORDER BY key_part1,key_part2; SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2; SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC; SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2;
b.不能利用索引避免排序的SQL
//排序字段在多個索引中,無法使用索引排序 SELECT * FROM t1 ORDER BY key_part1,key_part2, key2; //排序鍵順序與索引中列順序不一致,無法使用索引排序 SELECT * FROM t1 ORDER BY key_part2, key_part1; //升降序不一致,無法使用索引排序 SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC; //key_part1是范圍查詢,key_part2無法使用索引排序 SELECT * FROM t1 WHERE key_part1> constant ORDER BY key_part2;
2.排序實現的算法
對於不能利用索引避免排序的SQL,數據庫不得不自己實現排序功能以滿足用戶需求,此時SQL的執行計劃中會出現“Using filesort”,這裡需要注意的是filesort並不意味著就是文件排序,其實也有可能是內存排序,這個主要由sort_buffer_size參數與結果集大小確定。MySQL內部實現排序主要有3種方式,常規排序,優化排序和優先隊列排序,主要涉及3種排序算法:快速排序、歸並排序和堆排序。假設表結構和SQL語句如下:
CREATE TABLE t1(id int, col1 varchar(64), col2 varchar(64), col3 varchar(64), PRIMARY KEY(id),key(col1,col2)); SELECT col1,col2,col3 FROM t1 WHERE col1>100 ORDER BY col2;
a.常規排序
(1).從表t1中獲取滿足WHERE條件的記錄
(2).對於每條記錄,將記錄的主鍵+排序鍵(id,col2)取出放入sort buffer
(3).如果sort buffer可以存放所有滿足條件的(id,col2)對,則進行排序;否則sort buffer滿後,進行排序並固化到臨時文件中。(排序算法采用的是快速排序算法)
(4).若排序中產生了臨時文件,需要利用歸並排序算法,保證臨時文件中記錄是有序的
(5).循環執行上述過程,直到所有滿足條件的記錄全部參與排序
(6).掃描排好序的(id,col2)對,並利用id去撈取SELECT需要返回的列(col1,col2,col3)
(7).將獲取的結果集返回給用戶。
從上述流程來看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,col2)對,這個buffer的大小由sort_buffer_size參數控制。此外一次排序需要兩次IO,一次是撈(id,col2),第二次是撈(col1,col2,col3),由於返回的結果集是按col2排序,因此id是亂序的,通過亂序的id去撈(col1,col2,col3)時會產生大量的隨機IO。對於第二次MySQL本身一個優化,即在撈之前首先將id排序,並放入緩沖區,這個緩存區大小由參數read_rnd_buffer_size控制,然後有序去撈記錄,將隨機IO轉為順序IO。
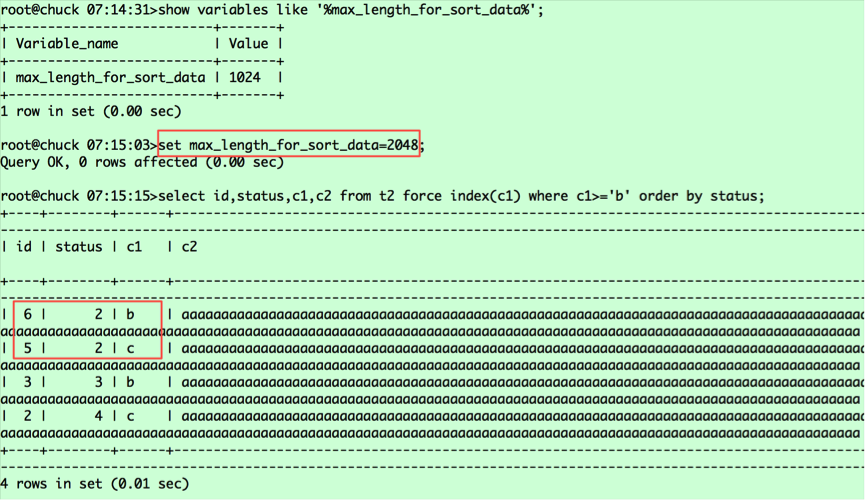
b.優化排序
常規排序方式除了排序本身,還需要額外兩次IO。優化的排序方式相對於常規排序,減少了第二次IO。主要區別在於,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由於sort buffer中包含了查詢需要的所有字段,因此排序完成後可以直接返回,無需二次撈數據。這種方式的代價在於,同樣大小的sort buffer,能存放的(col1,col2,col3)數目要小於(id,col2),如果sort buffer不夠大,可能導致需要寫臨時文件,造成額外的IO。當然MySQL提供了參數max_length_for_sort_data,只有當排序元組小於max_length_for_sort_data時,才能利用優化排序方式,否則只能用常規排序方式。
c.優先隊列排序
為了得到最終的排序結果,無論怎樣,我們都需要將所有滿足條件的記錄進行排序才能返回。那麼相對於優化排序方式,是否還有優化空間呢?5.6版本針對Order by limit M,N語句,在空間層面做了優化,加入了一種新的排序方式--優先隊列,這種方式采用堆排序實現。堆排序算法特征正好可以解limit M,N 這類排序的問題,雖然仍然需要所有元素參與排序,但是只需要M+N個元組的sort buffer空間即可,對於M,N很小的場景,基本不會因為sort buffer不夠而導致需要臨時文件進行歸並排序的問題。對於升序,采用大頂堆,最終堆中的元素組成了最小的N個元素,對於降序,采用小頂堆,最終堆中的元素組成了最大的N的元素。
3.排序不一致問題
案例1
Mysql從5.5遷移到5.6以後,發現分頁出現了重復值。
測試表與數據:
create table t1(id int primary key, c1 int, c2 varchar(128)); insert into t1 values(1,1,'a'); insert into t1 values(2,2,'b'); insert into t1 values(3,2,'c'); insert into t1 values(4,2,'d'); insert into t1 values(5,3,'e'); insert into t1 values(6,4,'f'); insert into t1 values(7,5,'g');
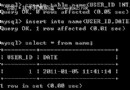
假設每頁3條記錄,第一頁limit 0,3和第二頁limit 3,3查詢結果如下:

我們可以看到 id為4的這條記錄居然同時出現在兩次查詢中,這明顯是不符合預期的,而且在5.5版本中沒有這個問題。產生這個現象的原因就是5.6針對limit M,N的語句采用了優先隊列,而優先隊列采用堆實現,比如上述的例子order by c1 asc limit 0,3 需要采用大小為3的大頂堆;limit 3,3需要采用大小為6的大頂堆。由於c1為2的記錄有3條,而堆排序是非穩定的(對於相同的key值,無法保證排序後與排序前的位置一致),所以導致分頁重復的現象。為了避免這個問題,我們可以在排序中加上唯一值,比如主鍵id,這樣由於id是唯一的,確保參與排序的key值不相同。將SQL寫成如下:
select * from t1 order by c1,id asc limit 0,3; select * from t1 order by c1,id asc limit 3,3;
案例2
兩個類似的查詢語句,除了返回列不同,其它都相同,但排序的結果不一致。
測試表與數據:
create table t2(id int primary key, status int, c1 varchar(255),c2 varchar(255),c3 varchar(255),key(c1));
insert into t2 values(7,1,'a',repeat('a',255),repeat('a',255));
insert into t2 values(6,2,'b',repeat('a',255),repeat('a',255));
insert into t2 values(5,2,'c',repeat('a',255),repeat('a',255));
insert into t2 values(4,2,'a',repeat('a',255),repeat('a',255));
insert into t2 values(3,3,'b',repeat('a',255),repeat('a',255));
insert into t2 values(2,4,'c',repeat('a',255),repeat('a',255));
insert into t2 values(1,5,'a',repeat('a',255),repeat('a',255));
分別執行SQL語句:
select id,status,c1,c2 from t2 force index(c1) where c1>='b' order by status; select id,status from t2 force index(c1) where c1>='b' order by status;
執行結果如下:
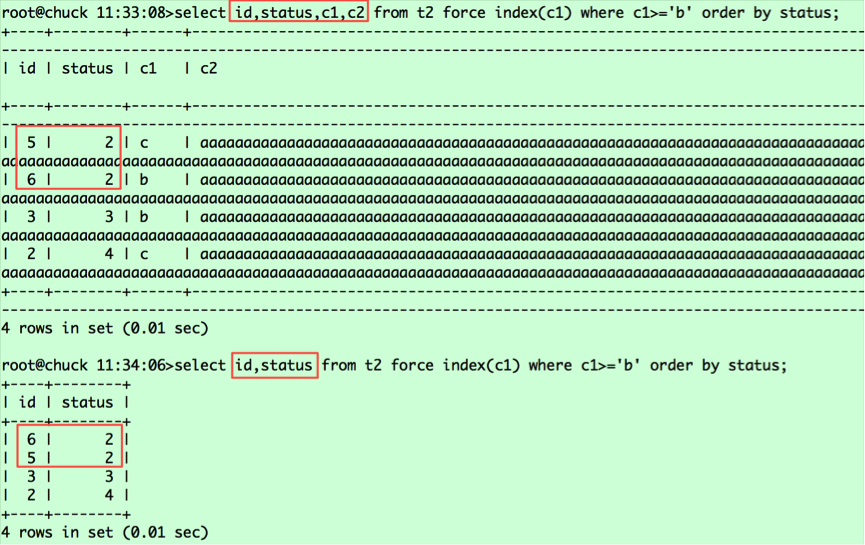
看看兩者的執行計劃是否相同

為了說明問題,我在語句中加了force index的hint,確保能走上c1列索引。語句通過c1列索引撈取id,然後去表中撈取返回的列。根據c1列值的大小,記錄在c1索引中的相對位置如下:
(c1,id)===(b,6),(b,3),(5,c),(c,2),對應的status值分別為2 3 2 4。從表中撈取數據並按status排序,則相對位置變為(6,2,b),(5,2,c),(3,3,c),(2,4,c),這就是第二條語句查詢返回的結果,那麼為什麼第一條查詢語句(6,2,b),(5,2,c)是調換順序的呢?這裡要看我之前提到的a.常規排序和b.優化排序中標紅的部分,就可以明白原因了。由於第一條查詢返回的列的字節數超過了max_length_for_sort_data,導致排序采用的是常規排序,而在這種情況下MYSQL將rowid排序,將隨機IO轉為順序IO,所以返回的是5在前,6在後;而第二條查詢采用的是優化排序,沒有第二次撈取數據的過程,保持了排序後記錄的相對位置。對於第一條語句,若想采用優化排序,我們將max_length_for_sort_data設置調大即可,比如2048。
下面是本人關於mysql 自定義排序(field,INSTR,locate)的一點心得,希望對大家有所幫助
首先說明這裡有三個函數(order by field,ORDER BY INSTR,ORDER BY locate)
原表:
id user pass aaa aaa bbb bbb ccc ccc ddd ddd eee eee fff fff
下面是我執行後的結果:
SELECT * FROM `user` order by field(2,3,5,4,id) asc
id user pass aaa aaa ccc ccc ddd ddd eee eee fff fff bbb bbb
根據結果分析:order by field(2,3,5,4,1,6) 結果顯示順序為:1 3 4 5 6 2
SELECT * FROM `user` order by field(2,3,5,4,id) desc
id user pass bbb bbb aaa aaa ccc ccc ddd ddd eee eee fff fff
根據結果分析:order by field(2,3,5,4,1,6) 結果顯示順序為:2 1 3 4 5 6
SELECT * FROM `user` ORDER BY INSTR( '2,3,5,4', id ) ASC
id user pass aaa aaa fff fff bbb bbb ccc ccc eee eee ddd ddd
根據結果分析:order by INSTR(2,3,5,4,1,6) 結果顯示順序為:1 6 2 3 5 4
SELECT * FROM `user` ORDER BY INSTR( '2,3,5,4', id ) DESC
id user pass ddd ddd eee eee ccc ccc bbb bbb aaa aaa fff fff
根據結果分析:order by INSTR(2,3,5,4,1,6) 結果顯示順序為:4 5 3 2 1 6
SELECT * FROM `user` ORDER BY locate( id, '2,3,5,4' ) ASC
id user pass
aaa aaa fff fff bbb bbb ccc ccc eee eee ddd ddd
根據結果分析:order by locate(2,3,5,4,1,6) 結果顯示順序為:1 6 2 3 5 4
SELECT * FROM `user` ORDER BY locate( id, '2,3,5,4' ) DESC
id user pass ddd ddd eee eee ccc ccc bbb bbb aaa aaa fff fff
根據結果分析:order by locate(2,3,5,4,1,6) 結果顯示順序為:4 5 3 2 1 6
如我想要查找的數據庫中的ID順序首先是(2,3,5,4)然後在是其它的ID順序,你首先要把他降序排即(4 5 3 2),然後在 SELECT * FROM `user` ORDER BY INSTR( '4,5,3,2', id ) DESC limit 0,10 或用 SELECT * FROM `user` ORDER BY locate( id, '4,5,3,2' ) DESC 就得到你想要的結果了。
id user pass bbb bbb ccc ccc eee eee ddd ddd aaa aaa fff fff