場景
產品中有一張圖片表pics,數據量將近100萬條,有一條相關的查詢語句,由於執行頻次較高,想針對此語句進行優化
表結構很簡單,主要字段:
復制代碼 代碼如下:
user_id 用戶ID
picname 圖片名稱
smallimg 小圖名稱
一個用戶會有多條圖片記錄,現在有一個根據user_id建立的索引:uid,查詢語句也很簡單:取得某用戶的圖片集合:
復制代碼 代碼如下:
select picname, smallimg from pics where user_id = xxx;
優化前
執行查詢語句(為了查看真實執行時間,強制不使用緩存,為了防止在測試時因為讀取了緩存造成對時間上的差別)
復制代碼 代碼如下:
select SQL_NO_CACHE picname, smallimg from pics where user_id=17853;
執行了10次,平均耗時在40ms左右
使用explain進行分析:
復制代碼 代碼如下:
explain select SQL_NO_CACHE picname, smallimg from pics where user_id=17853

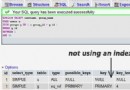
使用了user_id的索引,並且是const常數查找,表示性能已經很好了
優化後
因為這個語句太簡單,sql本身沒有什麼優化空間,就考慮了索引
修改索引結構,建立一個(user_id,picname,smallimg)的聯合索引:uid_pic
重新執行10次,平均耗時降到了30ms左右
使用explain進行分析

看到使用的索引變成了剛剛建立的聯合索引,並且Extra部分顯示使用了'Using Index'
總結
‘Using Index'的意思是“覆蓋索引”,它是使上面sql性能提升的關鍵
一個包含查詢所需字段的索引稱為“覆蓋索引”
MySQL只需要通過索引就可以返回查詢所需要的數據,而不必在查到索引之後進行回表操作,減少IO,提高了效率
例如上面的sql,查詢條件是user_id,可以使用聯合索引,要查詢的字段是picname smallimg,這兩個字段也在聯合索引中,這就實現了“覆蓋索引”,可以根據這個聯合索引一次性完成查詢工作,所以提升了性能。
擴展研究
一、Mysql緩存,SQL_NO_CACHE和SQL_CACHE 的區別
上邊在進行測試的時候,為了防止讀取緩存造成對實驗結果的影響使用到了SQL_NO_CACHE這個功能,對於SQL_NO_CACHE的介紹官網如下:
復制代碼 代碼如下:
SQL_NO_CACHE means that the query result is not cached. It does not mean that the cache is not used to answer the query.
You may use RESET QUERY CACHE to remove all queries from the cache and then your next query should be slow again. Same effect if you change the table, because this makes all cached queries invalid.
當我們想用SQL_NO_CACHE來禁止結果緩存時發現結果和我們的預期不一樣,查詢執行的結果仍然是緩存後的結果。其實,SQL_NO_CACHE的真正作用是禁止緩存查詢結果,但並不意味著cache不作為結果返回給query。
在說白點就是,不是本次查詢不使用緩存,而是本次查詢結果不做為下次查詢的緩存。
還有就是,mysql本身是有對sql語句緩存的機制的,合理設置我們的mysql緩存可以降低數據庫的io資源,因此,這裡我們有必要再看一下如何控制這個比較安逸的功能。
看圖如下:
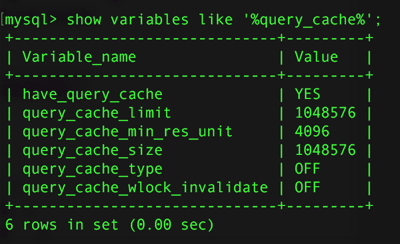
其中各項的含義為:
1、have_query_cache
是否支持查詢緩存區 “YES”表是支持查詢緩存區
2、query_cache_limit
可緩存的Select查詢結果的最大值 1048576 byte /1024 = 1024kB 即最大可緩存的select查詢結果必須小於 1024KB
3、query_cache_min_res_unit
每次給query cache結果分配內存的大小 默認是 4096 byte 也即 4kB
4、query_cache_size
如果你希望禁用查詢緩存,設置 query_cache_size=0。禁用了查詢緩存,將沒有明顯的開銷
5、query_cache_type
查詢緩存的方式(默認是 ON)
1、完整查詢的過程如下
當查詢進行的時候,Mysql把查詢結果保存在qurey cache中,但是有時候要保存的結果比較大,超過了query_cache_min_res_unit的值 ,這時候mysql將一邊檢索結果,一邊進行慢慢保存結果,所以,有時候並不是把所有結果全部得到後再進行一次性保存,而是每次分配一塊query_cache_min_res_unit 大小的內存空間保存結果集,使用完後,接著再分配一個這樣的塊,如果還不不夠,接著再分配一個塊,依此類推,也就是說,有可能在一次查詢中,mysql要進行多次內存分配的操作,而我們應該知道,頻繁操作內存都是要耗費時間的。
2、內存碎片的產生
當一塊分配的內存沒有完全使用時,MySQL會把這塊內存Trim掉,把沒有使用的那部分歸還以重復利用。比如,第一次分配4KB,只用了3KB,剩1KB,第二次連續操作,分配4KB,用了2KB,剩2KB,這兩次連續操作共剩下的1KB+2KB=3KB,不足以做個一個內存單元分配,這時候,內存碎片便產生了。
3.內存塊的概念
先看下這個:
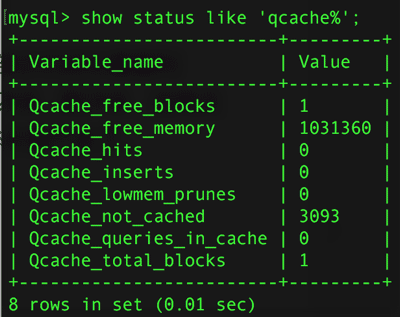
Qcache_total_blocks 表示所有的塊
Qcache_free_blocks 表示未使用的塊
這個值比較大,那意味著,內存碎片比較多,用flush query cache清理後,為被使用的塊其值應該為1或0 ,因為這時候所有的內存都做為一個連續的快在一起了.
Qcache_free_memory 表示查詢緩存區現在還有多少的可用內存
Qcache_hits 表示查詢緩存區的命中個數,也就是直接從查詢緩存區作出響應處理的查詢個數
Qcache_inserts 表示查詢緩存區此前總過緩存過多少條查詢命令的結果
Qcache_lowmem_prunes 表示查詢緩存區已滿而從其中溢出和刪除的查詢結果的個數
Qcache_not_cached 表示沒有進入查詢緩存區的查詢命令個數
Qcache_queries_in_cache 查詢緩存區當前緩存著多少條查詢命令的結果
優化提示:
如果Qcache_lowmem_prunes 值比較大,表示查詢緩存區大小設置太小,需要增大。
如果Qcache_free_blocks 較多,表示內存碎片較多,需要清理,flush query cache
關於query_cache_min_res_unit大小的調優,書中給出了一個計算公式,可以供調優設置參考:
復制代碼 代碼如下:
query_cache_min_res_unit = (query_cache_size - Qcache_free_memory) /Qcache_queries_in_cache
還要注意一點的是,FLUSH QUERY CACHE 命令可以用來整理查詢緩存區的碎片,改善內存使用狀況,但不會清理查詢緩存區的內容,這個要和RESET QUERY CACHE相區別,不要混淆,後者才是清除查詢緩存區中的所有的內容。
可以在 SELECT 語句中指定查詢緩存的選項,對於那些肯定要實時的從表中獲取數據的查詢,或者對於那些一天只執行一次的查詢,我們都可以指定不進行查詢緩存,使用 SQL_NO_CACHE 選項。
對於那些變化不頻繁的表,查詢操作很固定,我們可以將該查詢操作緩存起來,這樣每次執行的時候不實際訪問表和執行查詢,只是從緩存獲得結果,可以有效地改善查詢的性能,使用 SQL_CACHE 選項。
下面是使用 SQL_NO_CACHE 和 SQL_CACHE 的例子:
復制代碼 代碼如下:
mysql> select sql_no_cache id,name from test3 where id < 2;
mysql> select sql_cache id,name from test3 where id < 2;
注意:查詢緩存的使用還需要配合相應得服務器參數的設置。
二、覆蓋索引(偷懶整理一下,來自百度百科)
理解方式一:就是select的數據列只用從索引中就能夠取得,不必讀取數據行,換句話說查詢列要被所建的索引覆蓋。
理解方式二:索引是高效找到行的一個方法,但是一般數據庫也能使用索引找到一個列的數據,因此它不必讀取整個行。畢竟索引葉子節點存儲了它們索引的數據;當能通過讀取索引就可以得到想要的數據,那就不需要讀取行了。一個索引包含了(或覆蓋了)滿足查詢結果的數據就叫做覆蓋索引。
理解方式三:是非聚集復合索引的一種形式,它包括在查詢裡的Select、Join和Where子句用到的所有列(即建索引的字段正好是覆蓋查詢條件中所涉及的字段,也即,索引包含了查詢正在查找的數據)。
作用:
如果你想要通過索引覆蓋select多列,那麼需要給需要的列建立一個多列索引,當然如果帶查詢條件,where條件要求滿足最左前綴原則。
Innodb的輔助索引葉子節點包含的是主鍵列,所以主鍵一定是被索引覆蓋的。
(1)例如,在sakila的inventory表中,有一個組合索引(store_id,film_id),對於只需要訪問這兩列的查 詢,MySQL就可以使用索引,如下:
復制代碼 代碼如下:
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G
(2)再比如說在文章系統裡分頁顯示的時候,一般的查詢是這樣的:
復制代碼 代碼如下:
SELECT id, title, content FROM article ORDER BY created DESC LIMIT 10000, 10;
通常這樣的查詢會把索引建在created字段(其中id是主鍵),不過當LIMIT偏移很大時,查詢效率仍然很低,改變一下查詢:
復制代碼 代碼如下:
SELECT id, title, content FROM article
INNER JOIN (
SELECT id FROM article ORDER BY created DESC LIMIT 10000, 10
) AS page USING(id)
此時,建立復合索引”created, id”(只要建立created索引就可以吧,Innodb是會在輔助索引裡面存儲主鍵值的),就可以在子查詢裡利用上Covering Index,快速定位id,查詢效率嗷嗷的
注:本文是參考《Mysql性能優化案例 - 覆蓋索引》 的一篇文章借題發揮,參考了原文的知識點,自己做了一點的發揮和研究,原文被多次轉載,不知作者何許人也,也不知出處在哪個,如需原文請自行搜索。