一個線上項目報的死鎖,簡要說明一下產生原因、處理方案和相關的一些點.
1、背景
這是一個類似數據分析的項目,數據完全通過LOAD DATA語句導入一個InnoDB表中。為方便描述,表結構簡化為如下:
Create table tb(id int primary key auto_increment, c int not null) engine=innodb;
導入數據的語句對應為
Load data infile ‘data1.csv' into table tb; Load data infile ‘data2.csv' into table tb;
cat Data1.csv 1 100 2 100 3 100 Cat data2.csv 10 100 11 100 12 100
產生死鎖的證據是在show engine innodb status的LATEST DETECTED DEADLOCK段中看到死鎖信息,簡化為如下:
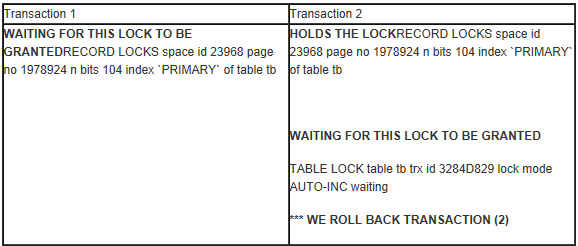
說明
從上面表格中看出,事務1在等待某一行的鎖。而事務2持有這行的鎖,但等待表的自增鎖(AUTO_INC),判斷為死鎖,事務回滾。
這裡事務1沒有寫出來,但是可以推斷,事務1持有這個表的自增鎖(否則就不是死鎖了)。
2、背景知識1:AUTO_INC lock 及其選項
在InnoDB表中,若存在自增字段,則會維護一個表級別的鎖,這裡稱為自增鎖。每次插入新數據,或者update語句修改了此字段,都會需要獲取這個鎖
由於一個事務可能包含多個語句,而並非所有的語句都與自增字段有關,因此InnoDB作了一個特殊的處理,自增鎖在一個語句結束後馬上被釋放。之所以說是特殊處理,是因為普通的鎖,都是在事務結束後釋放。
若一個表有自增字段,一個insert語句不指定該字段的值,或指定為NULL時,InnoDB會給它賦值為當前的AUTO_INCREMENT的值,然後AUTO_INCREMENT加1。
與這個自增鎖相關的一個參數是innodb_autoinc_lock_mode. 默認值為1,可選為0,1,2。
我們先來看當這個值設置為0時,一個有自增字段的表,插入一行數據時的行為:
1) 申請AUTO_INC鎖
2) 得到當前AUTO_INCREMNT值n,給AUTO_INCREMENT 加1
3) 執行插入操作,並將n填入新增的行對應字段中
4) 釋放AUTO_INC鎖
我們看到這個過程中,雖然InnoDB為了減少鎖粒度,在語句執行完成就馬上釋放,但這鎖還是太大了――它包括了插入操作的時間。這就導致了兩個insert語句,實際上沒辦法並行。
沒有這個參數之前,行為就是與設置為0相同,0這個選項就是留著兼容的。
很容易想到設置為1的時候,應該是將3) 和 4)對調。但是本文還是要討論為0的情況,因為我們的前提是LOAD語句,而LOAD語句這類插入多行的語句中(包括insert …select …),即使設置為1也沒用,會退化為0的模式。
3、背景知識2:LOAD DATA語句的主從行為
為什麼插入多行的語句要即使將innodb_autoinc_lock_mode設置為1,也會用0的模式呢?
主要原因還是為了主從一致性。設想binlog_format='statement',一個LOAD DATA語句在主庫的binlog直接記錄為語句本身,那從庫如何重放:
1) 將load data用到的文件發給slave,slave將文件保存在臨時目錄。
2) 在slave也執行一次LOAD DATA語句。
其間有一個問題:slave怎麼保證load data語句的自增id字段與master相同?
為了解決這個問題,主庫的binlog中還有一個set SET INSERT_ID命令,表明這個LOAD DATA語句插入的第一行的自增ID值。這樣slave在執行load data之前,先執行了這個set SET INSERT_ID語句,用於保證執行結果與主庫一模一樣。
上述的機制能保證主從數據一致的前提是:主從庫上LOAD DATA語句生成的自增ID值必須是連續的。
4、背景知識1+2:分析
回到前面說的模式0和1的區別,我們看到,如果AUTO_INC鎖在整個語句開始之前就獲取,在語句結束之後才釋放,這樣就能保證整個語句生成的id連續――模式0的保證。
對於1,每次拿到下一個值就釋放,插入數據後,若需要再申請,則不連續。
這就是為什麼,即使設置為1,對於多行操作,會退化成0。
至此我們知道這個死鎖出現的原因,是這兩個LOAD DATA語句不僅會訪問相同的記錄,還會訪問同一個AUTO_INC鎖,造成互相等待。
到此沒完,因為我們知道雖然兩個線程訪問兩個鎖可能造成死鎖,但是死鎖還有另外一個條件,與申請順序有關。既然AUTO_INC是一個表鎖,不論誰先拿到,會阻塞其他同表的LOAD DATA的執行,又為什麼會在某個記錄上出現鎖等待?
5、背景知識3:AUTO_INC的加鎖時機
前面我們說到每次涉及到插入新數據,就會要求對AUTO_INC加鎖,並列出了流程。但這個流程是對於需要從InnoDB中得到自增值來設置列值的情況。另一種情況是在語句中已經指定了該列的值。
比如對於這個表,執行 insert into tb values(9,100). 此時id的值已經明確是9,雖然不需要取值來填,但是插入這行後有可能需要改變AUTO_INCREMENT的值(若原來是<10,則應該改為10),所以這個鎖還是省不了。流程變成:
1) 插入數據
2) 若失敗則流程結束
3) 若成功,申請AUTO_INC鎖
4) 調用set_max….函數,如有必要則修改AUTO_INCREMENT
5) 語句結束時釋放AUTO_INC鎖。
6、為什麼修改AUTO_INC順序
這麼調整的好處是什麼? 主要是為了減少不必要的鎖訪問。若在插入數據期間發生錯誤,比如其他字段造成DUPLICATE KEY error,這樣就不用訪問AUTO_INC鎖。
7、死鎖過程復現
必須強調是“語句結束時”。這樣我們來看一個每行都已經指定了自增列值的LOAD DATA語句的流程(也就是本文例子的情況):
1) 插入第一條數據
2) 申請AUTO_INC鎖
3) 插入第二條
4) 申請AUTO_INC 鎖(因為已經是自己的,直接成功)
5) 。。。。。。插入剩余所有行
6) 釋放AUTO_INC鎖。
所以這個流程就簡單描述為:插入第一行,申請AUTO_INC鎖,然後插入剩下的所有行後再釋放。
我們前面提到過,插入第一條數據時可能需要訪問的記錄鎖,是要等到整個事務結束後才釋放的.
有了上面的這些背景知識,我們來復現一下死鎖出現的過程
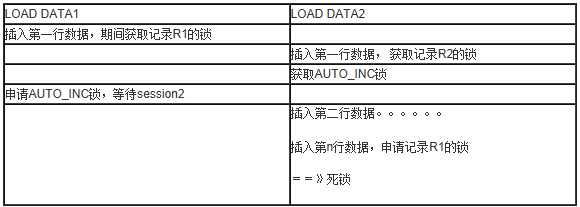
可以看到觸發條件還是比較苛刻的,尤其是session2要剛好要用到session1鎖住的那個記錄鎖。需要說明,由於InnoDB內部對記錄的表示,同一個記錄鎖並不表示主鍵值一定相同。
8、解決方案1:去掉不必要的AUTO_INCREMENT字段
在這個業務中,由於所有的數據都是通過LOAD DATA進去,而且都已經指定了自增字段的值,因此這個AUTO)INCREMENT屬性是不需要的。
少了一個,就死鎖不了了。
9、解決方案2:強制模式1
前面我們說到innodb_autoinc_lock_mode這個參數的可選值有0、1、2。當設置為1的時候,在LOAD DATA語句會退化為模式0。但若設置為2,則無論如何都會使用模式1。
我們前面說到使用模式1會導致LOAD DATA生成的自增id值不連續,這樣會導致在binlog_format是1時主從不一致,因此設置為2的前提,是binlog_format 是row.
在binlog_format='row'時,設置innodb_autoinc_lock_mode為2是安全的。
若允許,方案2比方案1更輕量些,不需要修改數據和表結構。