union和join是需要聯合多張表時常見的關聯詞,具體概念我就不說了,想知道上網查就行,因為我也記不准確。
先說差別:union對兩張表的操作是合並數據條數,等於是縱向的,要求是兩張表字段必須是相同的(Schema of both sides of union should match.)。也就是說如果A表中有三條數據,B表中有兩條數據,那麼A union B就會有五條數據。說明一下union 和union all的差別,對於union如果存在相同的數據記錄會被合並,而union all不會合並相同的數據記錄,該有多少條記錄就會有多少條記錄。例如在mysql下執行以下語句:
select * from tmp_libingxue_a; name number libingxue 1001 yuwen 1002 select * from tmp_libingxue_b; name number libingxue 1001 feiyao 1003 select * from tmp_libingxue_a union select * from tmp_libingxue_b; libingxue 1001 yuwen 1002 feiyao 1003 select * from tmp_libingxue_a union all select * from tmp_libingxue_b; libingxue 1001 yuwen 1002 libingxue 1001 feiyao 1003
但是這樣在hive裡面是不能執行的,執行select * from tmp_libingxue_a union all select * from tmp_libingxue_b;會failed,hive中union必須在子查詢中進行。如
select * from (select * from tmp_yuwen_a union all select * from tmp_yuwen_b) t1;
注意,必須是union all,單獨用union它會提示你缺少ALL,而且後面的t1必須寫,你可以寫成a或者b,但是一定要寫,不寫會出錯。
而join則是偏於橫向的聯合,僅僅是偏向於,等下詳細說明。join跟union比起來顯得更寬松,對兩個表的字段不做要求,沒有限制條件的join等於兩個表的笛卡爾乘積,所有join需要有限制條件來約束,經過限制的join就是橫向的擴張了。對於滿足限制條件的join會被提取出來,不滿足的直接過濾掉。用法可以很靈活,下面有兩個簡單的例子:
select * from (select * from tmp_yuwen_a)t1 join (select * from tmp_yuwen_b) t2; select * from tmp_yuwen_a t1 join (select * from tmp_yuwen_b) t2;
left outer join和right outer join用法類似,區別就是left outer join會把左邊表的字段全部選擇出來,右邊表的字段把符合條件的也選擇出來,不滿足的全部置空,也就是說以左邊表為參照。right outer join同理以右邊表為參照。這三個join之間的差別說過很多次,網上也有更詳細的解釋,不再贅述。
相同點:在某些特定的情況下,可以用join實現union all的功能,這種情況是有條件的,當出現這種情況的時候選擇union all還是group by就可以看情況或者看兩者的消耗而決定。sql雖然就在那麼幾個關鍵詞,但變化多端、功能強大,只要能實現想要的功能,怎麼用隨便你。需求情況sql簡單重現如下
drop table tmp_libingxue_resource; create external table if not exists tmp_libingxue_resource( user_id string, shop_id string, auction_id string, search_time string )partitioned by (pt string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as sequencefile; drop table tmp_libingxue_result; create external table if not exists tmp_libingxue_result( user_id string, shop_id string, auction_id string, search_time string )partitioned by (pt string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as sequencefile; insert overwrite table tmp_libingxue_result where(pt=20041104) select * from tmp_libingxue_resource;
sudo -u taobao hadoop dfs -rmr /group/tbads/warehouse/tmp_libingxue_result/pt=20041104 sudo -u taobao hadoop jar /home/taobao/dataqa/framework/DailyReport.jar com.alimama.loganalyzer.tool.SeqFileLoader tmp_libingxue_resource.txt hdfs://v039182.sqa.cm4:54310/group/tbads/warehouse/tmp_libingxue_result/pt=20041104/part-00000
hive> select * from tmp_libingxue_resource;
OK 2001 0 11 101 20041104 2002 0 11 102 20041104
hive> select * from tmp_libingxue_result;
OK 2001 0 12 103 20041104 2002 0 12 104 20041104
select user_id,shop_id,max(auction_id),max(search_time) from (select * from tmp_libingxue_resource union all select * from tmp_libingxue_result )t1 group by user_id,shop_id;
2001 0 12 103 2002 0 12 104
select t1.user_id,t1.shop_id,t2.auction_id,t2.search_time from (select * from tmp_libingxue_resource) t1 join (select * from tmp_libingxue_result) t2 on t1.user_id=t2.user_id and t1.shop_id=t2.shop_id;
2001 0 12 103 2002 0 12 104
假定有兩個表Table3和Table4,其包含的列和數據分別如下所示。
Table1數據庫表

Table2數據庫表

Table1表和Table2表具有相同的列結構,因此可以使用UNION運算符連接兩個表的記錄集,得到的連接結果如下表所示。
使用UNION連接Table3表和Table4表的記錄
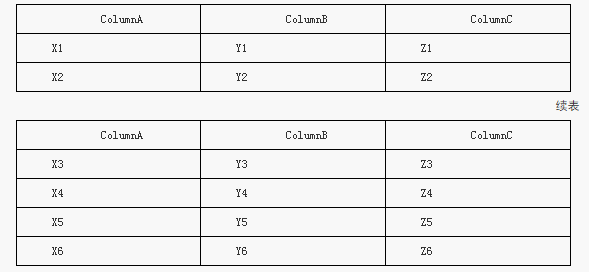
上述連接過程的實現代碼可表示如下:
SELECT * FROM Table1 UNION SELECT * FROM Table2