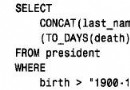
LEFT JOIN的主表
這裡所說的主表是指在連接查詢裡MySQL以哪個表為主進行查詢。比如說在LEFT JOIN查詢裡,一般來說左表就是主表,但這只是經驗之談,很多時候經驗主義是靠不住的,為了說明問題,先來個例子,建兩個演示用的表categories和posts:
CREATE TABLE IF NOT EXISTS `categories` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(15) NOT NULL, `created` datetime NOT NULL, PRIMARY KEY (`id`) ); CREATE TABLE IF NOT EXISTS `posts` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `category_id` int(10) unsigned NOT NULL, `title` varchar(100) NOT NULL, `content` varchar(200) NOT NULL, `created` datetime NOT NULL, PRIMARY KEY (`id`), KEY `category_id` (`category_id`) );
先注意一下每個表的索引情況,以後會用到,記得隨便插入一點測試數據,不用太多,但怎麼也得兩行以上,然後執行以下SQL:
EXPLAIN SELECT * FROM posts LEFT JOIN categories ON posts.category_id = categories.id WHERE categories.id = ‘一個已經存在的ID' ORDER BY posts.created DESC
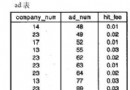
table key Extra categories PRIMARY Using filesort posts category_id Using where
在explain的結果中,第一行表示的表就是主表,所以說在此查詢裡categories是主表,而在我們的經驗裡,LEFT JOIN查詢裡,左表(posts表)才應該是主表,這產生一個根本的矛盾,MySQL之所以這樣處理,是因為在我們的WHERE部分,查詢條件是按照categories表的字段來進行篩選的,而恰恰categories表存在合適的索引,所以在查詢時把categories表作為主表更有利於縮小結果集。
那explain結果中的Using filesort又是為什麼呢?這是因為主表是categories表,從表是posts表,而我們使用從表的字段去ORDER BY,這通常不是一個好選擇,最好改成主表字段,如果鑒於需求所限,無法改成主表的字段,那麼可以嘗試添加如下索引:
ALTER TABLE `posts` ADD INDEX ( `category_id` , `created` );
再運行SQL時就不會有Using filesort了,這是因為主表categories在通過category_id連接從表posts時,可以進而通過索引直接得到排序後的posts結果。
主觀上一旦搞錯了主表,可能怎麼調整索引都得不到高效的SQL,所以在寫SQL時,比如說在寫LEFT JOIN查詢時,如果希望左表是主表,那麼就要保證在WHERE語句裡的查詢條件盡可能多的使用左表字段,進而,一旦確定了主表,也最好只通過主表字段去ORDER BY。
LEFT JOIN查詢效率分析
user表:
id | name --------- 1 | libk 2 | zyfon 3 | daodao user_action表: user_id | action --------------- 1 | jump 1 | kick 1 | jump 2 | run 4 | swim
sql:
select id, name, action from user as u left join user_action a on u.id = a.user_id result: id | name | action -------------------------------- 1 | libk | jump ① 1 | libk | kick ② 1 | libk | jump ③ 2 | zyfon | run ④ 3 | daodao | null ⑤
分析:
注意到user_action中還有一個user_id=4, action=swim的紀錄,但是沒有在結果中出現,
而user表中的id=3, name=daodao的用戶在user_action中沒有相應的紀錄,但是卻出現在了結果集中
因為現在是left join,所有的工作以left為准.
結果1,2,3,4都是既在左表又在右表的紀錄,5是只在左表,不在右表的紀錄
結論:
我們可以想象left join 是這樣工作的
從左表讀出一條,選出所有與on匹配的右表紀錄(n條)進行連接,形成n條紀錄(包括重復的行,如:結果1和結果3),
如果右邊沒有與on條件匹配的表,那連接的字段都是null.
然後繼續讀下一條。
引申:
我們可以用右表沒有on匹配則顯示null的規律, 來找出所有在左表,不在右表的紀錄, 注意用來判斷的那列必須聲明為not null的。
如:
select id, name, action from user as u left join user_action a on u.id = a.user_id where a.user_id is NULL
(注意:1.列值為null應該用is null 而不能用=NULL
2.這裡a.user_id 列必須聲明為 NOT NULL 的)
result: id | name | action -------------------------- 3 | daodao | NULL --------------------------------------------------------------------------------
Tips:
1. on a.c1 = b.c1 等同於 using(c1)
2. INNER JOIN 和 , (逗號) 在語義上是等同的
3. 當 MySQL 在從一個表中檢索信息時,你可以提示它選擇了哪一個索引。
如果 EXPLAIN 顯示 MySQL 使用了可能的索引列表中錯誤的索引,這個特性將是很有用的。
通過指定 USE INDEX (key_list),你可以告訴 MySQL 使用可能的索引中最合適的一個索引在表中查找記錄行。
可選的二選一句法 IGNORE INDEX (key_list) 可被用於告訴 MySQL 不使用特定的索引。
4. 一些例子:
mysql> SELECT * FROM table1,table2 WHERE table1.id=table2.id; mysql> SELECT * FROM table1 LEFT JOIN table2 ON table1.id=table2.id; mysql> SELECT * FROM table1 LEFT JOIN table2 USING (id); mysql> SELECT * FROM table1 LEFT JOIN table2 ON table1.id=table2.id -> LEFT JOIN table3 ON table2.id=table3.id; mysql> SELECT * FROM table1 USE INDEX (key1,key2) -> WHERE key1=1 AND key2=2 AND key3=3; mysql> SELECT * FROM table1 IGNORE INDEX (key3) -> WHERE key1=1 AND key2=2 AND key3=3;