MySQL出現亂碼的原因
要了解為什麼會出現亂碼,我們就先要理解:從客戶端發起請求,到MySQL存儲數據,再到下次從表取回客戶端的過程中,哪些環節會有編碼/解碼的行為。為了更好的解釋這個過程,博主制作了兩張流程圖,分別對應存入和取出兩個階段。
存入MySQL經歷的編碼轉換過程
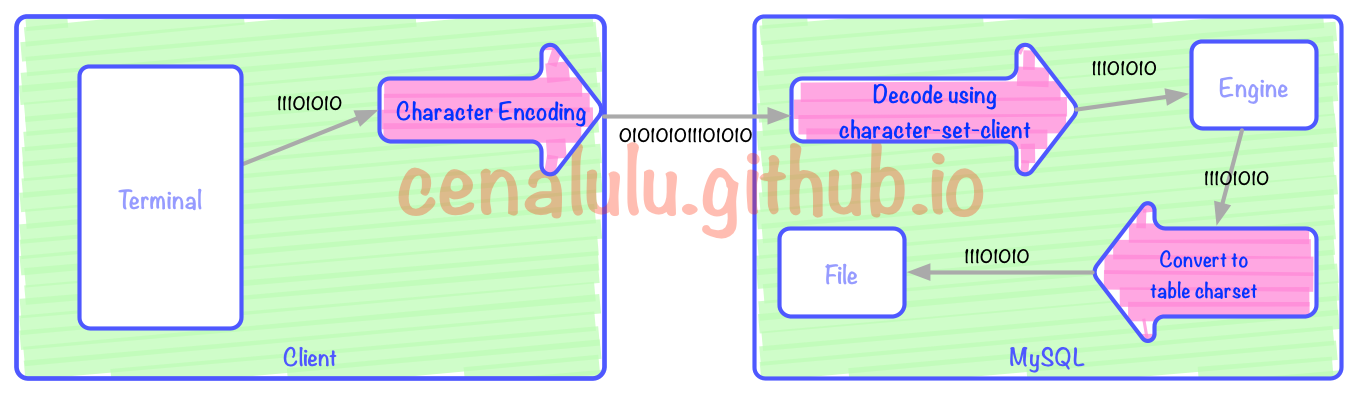
上圖中有3次編碼/解碼的過程(紅色箭頭)。三個紅色箭頭分別對應:客戶端編碼,MySQL Server解碼,Client編碼向表編碼的轉換。其中Terminal可以是一個Bash,一個web頁面又或者是一個APP。本文中我們假定Bash是我們的Terminal,即用戶端的輸入和展示界面。圖中每一個框格對應的行為如下:
從MySQL表中取出數據經歷的編碼轉換過程
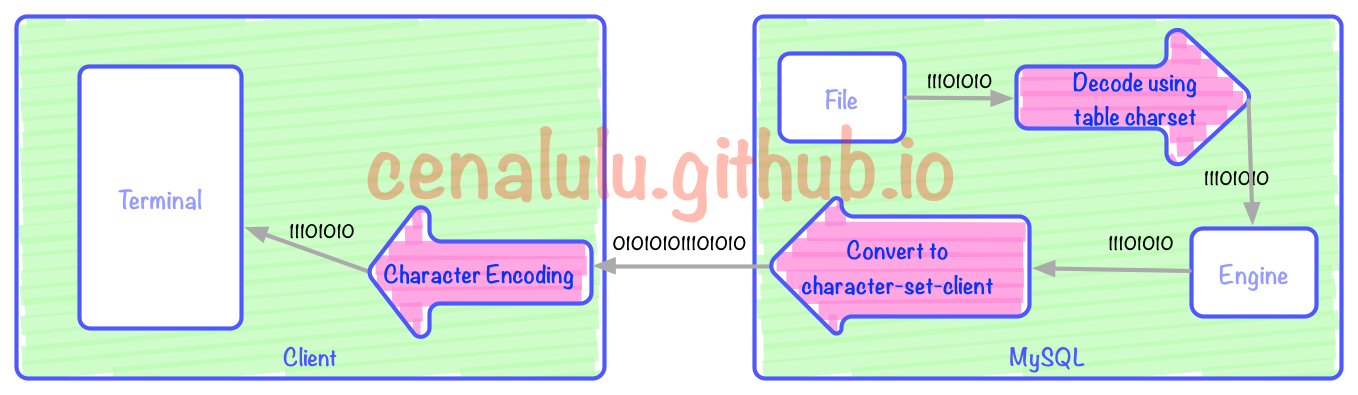
上圖有3次編碼/解碼的過程(紅色箭頭)。上圖中三個紅色箭頭分別對應:客戶端解碼展示,MySQL Server根據character-set-client編碼,表編碼向character-set-client編碼的轉換。
造成MySQL亂碼的原因
1. 存入和取出時對應環節的編碼不一致
這個會造成亂碼是顯而易見的。我們把存入階段的三次編解碼使用的字符集編號為C1,C2,C3(圖一從左到右);取出時的三個字符集依次編號為C1',C2',C3'(從左到右)。那麼存入的時候bash C1用的是UTF-8編碼,取出的時候,C1'我們卻使用了windows終端(默認是GBK編碼),那麼結果幾乎一定是亂碼。又或者存入MySQL的時候set names utf8(C2),而取出的時候卻使用了set names gbk(C2'),那麼結果也必然是亂碼
2. 單個流程中三步的編碼不一致
即上面任意一幅圖中的同方向的三步中,只要兩步或者兩部以上的編碼有不一致就有可能出現編解碼錯誤。如果差異的兩個字符集之間無法進行無損編碼轉換(下文會詳細介紹),那麼就一定會出現亂碼。例如:我們的shell是UTF8編碼,MySQL的character-set-client配置成了GBK,而表結構卻又是charset=utf8,那麼毫無疑問的一定會出現亂碼。
這裡我們就簡單演示下這種情況:
master [localhost] {msandbox} (test) > create table charset_test_utf8 (id int primary key auto_increment, char_col varchar(50)) charset = utf8;
Query OK, 0 rows affected (0.04 sec)
master [localhost] {msandbox} (test) > set names gbk;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into charset_test_utf8 (char_col) values ('中文');
Query OK, 1 row affected, 1 warning (0.01 sec)
master [localhost] {msandbox} (test) > show warnings;
+---------+------+---------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------------------------------------+
| Warning | 1366 | Incorrect string value: '\xAD\xE6\x96\x87' for column 'char_col' at row 1 |
+---------+------+---------------------------------------------------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col from charset_test_utf8;
+----+----------------+----------+
| id | hex(char_col) | char_col |
+----+----------------+----------+
| 1 | E6B6933FE69E83 | ???? |
+----+----------------+----------+
1 row in set (0.01 sec)
關於MySQL的編/解碼
既然系統之間是按照二進制流進行傳輸的,那直接把這串二進制流直接存入表文件就好啦。為什麼在存儲之前還要進行兩次編解碼的操作呢?
在MySQL中最常見的亂碼問題的起因就是把錯進錯出神話。所謂的錯進錯出就是,客戶端(web或shell)的字符編碼和最終表的字符編碼格式不同,但是只要保證存和取兩次的字符集編碼一致就仍然能夠獲得沒有亂碼的輸出的這種現象。但是,錯進錯出並不是對於任意兩種字符集編碼的組合都是有效的。我們假設客戶端的編碼是C,MySQL表的字符集編碼是S。那麼為了能夠錯進錯出,需要滿足以下兩個條件:
編碼無損轉換
那麼什麼是有損轉換,什麼是無損轉換呢?假設我們要把用編碼A表示的字符X,轉化為編碼B的表示形式,而編碼B的字形集中並沒有X這個字符,那麼此時我們就稱這個轉換是有損的。那麼,為什麼會出現兩個編碼所能表示字符集合的差異呢?如果大家看過博主之前的那篇 十分鐘搞清字符集和字符編碼,或者對字符編碼有基礎理解的話,就應該知道每個字符集所支持的字符數量是有限的,並且各個字符集涵蓋的文字之間存在差異。UTF8和GBK所能表示的字符數量范圍如下:
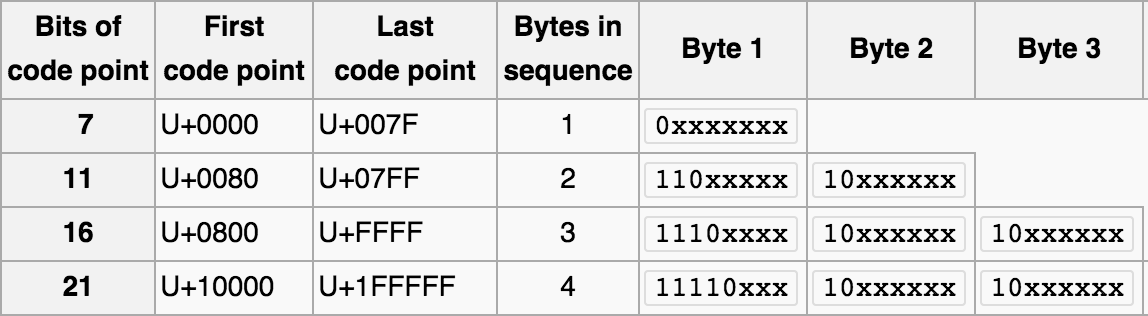
由於UTF-8編碼能表示的字符數量遠超GBK。那麼我們很容易就能找到一個從UTF8到GBK的有損編碼轉換。我們用字符映射器(見下圖)找出了一個明顯就不在GBK編碼表中的字符,嘗試存入到GBK編碼的表中。並再次取出查看有損轉換的行為
字符信息具體是:? GURMUKHI LETTER A Unicode: U+0A05, UTF-8: E0 A8 85
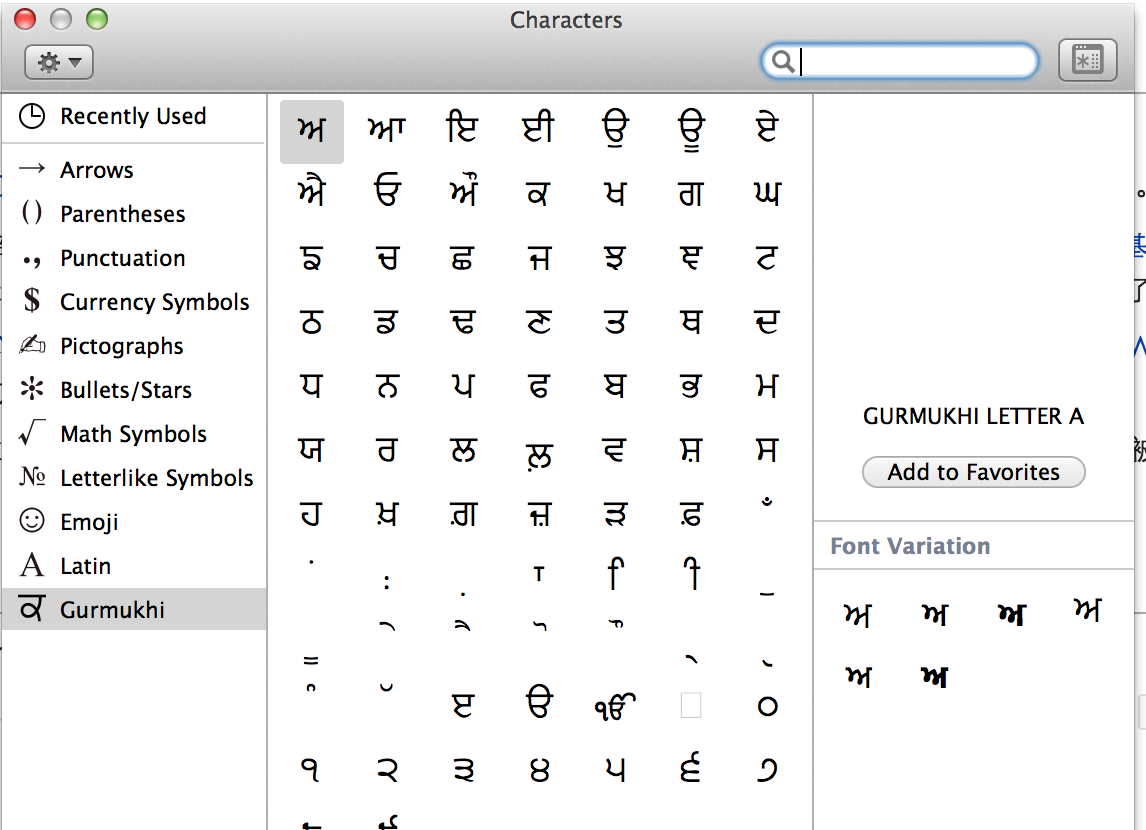
在MySQL中存儲的具體情況如下:
master [localhost] {msandbox} (test) > create table charset_test_gbk (id int primary key auto_increment, char_col varchar(50)) charset = gbk;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > set names utf8;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into charset_test_gbk (char_col) values ('?');
Query OK, 1 row affected, 1 warning (0.01 sec)
master [localhost] {msandbox} (test) > show warnings;
+---------+------+-----------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------+
| Warning | 1366 | Incorrect string value: '\xE0\xA8\x85' for column 'char_col' at row 1 |
+---------+------+-----------------------------------------------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col,char_length(char_col) from charset_test_gbk;
+----+---------------+----------+-----------------------+
| id | hex(char_col) | char_col | char_length(char_col) |
+----+---------------+----------+-----------------------+
| 1 | 3F | ? | 1 |
+----+---------------+----------+-----------------------+
1 row in set (0.00 sec)
出錯的部分是在編解碼的第3步時發生的。具體見下圖
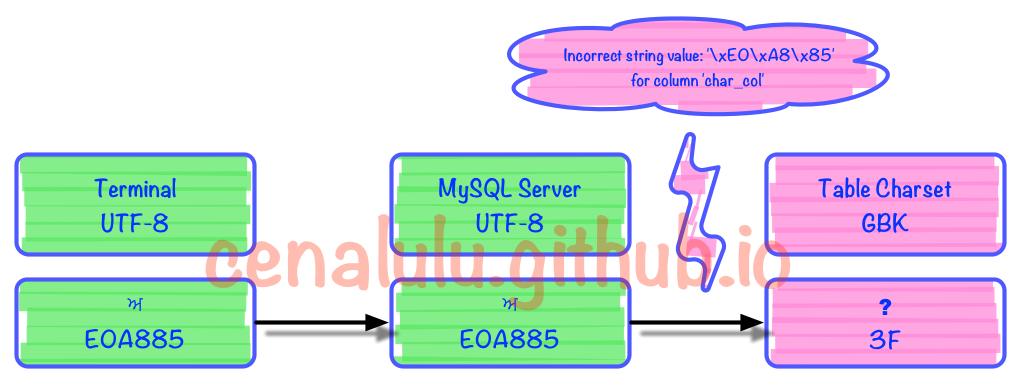
可見MySQL內部如果無法找到一個UTF8字符所對應的GBK字符時,就會轉換成一個錯誤mark(這裡是問號)。而每個字符集在程序實現的時候內部都約定了當出現這種情況時的行為和轉換規則。例如:UTF8中無法找到對應字符時,如果不拋錯那麼就將該字符替換成? (U+FFFD)
那麼是不是任何兩種字符集編碼之間的轉換都是有損的呢?並非這樣,轉換是否有損取決於以下幾點:
關於第一點,剛才已經通過實驗來解釋過了。這裡來解釋下造成有損轉換的第二個因素。從剛才的例子我們可以看到由於GBK在處理自己無法表示的字符時的行為是:用錯誤標識替代,即0x3F。而有些字符集(例如latin1)在遇到自己無法表示的字符時,會保留原字符集的編碼數據,並跳過忽略該字符進而處理後面的數據。如果目標字符集具有這樣的特性,那麼就能夠實現這節最開始提到的錯進錯出的效果。
我們來看下面這個例子:
master [localhost] {msandbox} (test) > create table charset_test (id int primary key auto_increment, char_col varchar(50)) charset = latin1;
Query OK, 0 rows affected (0.03 sec)
master [localhost] {msandbox} (test) > set names latin1;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into charset_test (char_col) values ('中文');
Query OK, 1 row affected (0.01 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col from charset_test;
+----+---------------+----------+
| id | hex(char_col) | char_col |
+----+---------------+----------+
| 2 | E4B8ADE69687 | 中文 |
+----+---------------+----------+
2 rows in set (0.00 sec)
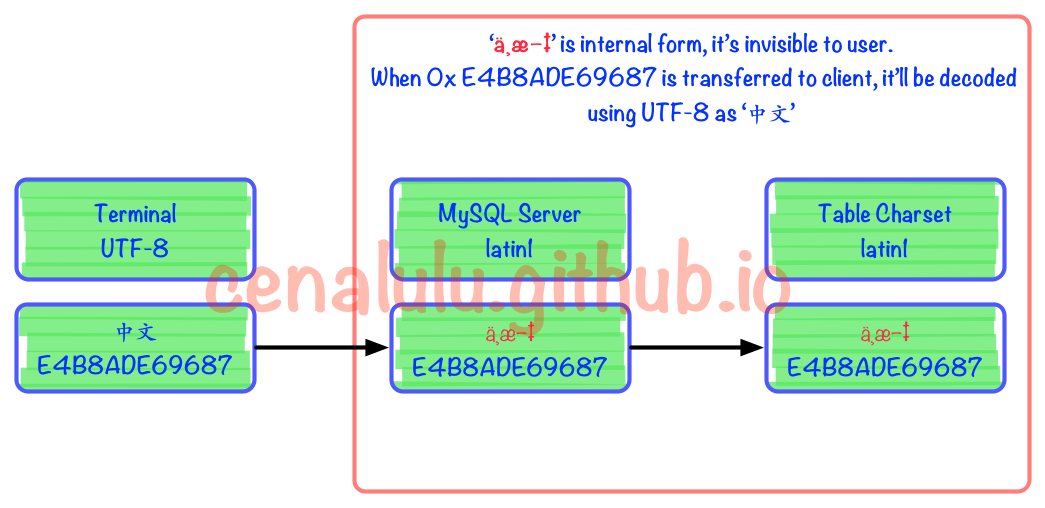
具體流程圖如下。可見在被MySQL Server接收到以後實際上已經發生了編碼不一致的情況。但是由於Latin1字符集對於自己表述范圍外的字符不會做任何處理,而是保留原值。這樣的行為也使得錯進錯出成為了可能。
如何避免亂碼
理解了上面的內容,要避免亂碼就顯得很容易了。只要做到“三位一體”,即客戶端,MySQL character-set-client,table charset三個字符集完全一致就可以保證一定不會有亂碼出現了。而對於已經出現亂碼,或者已經遭受有損轉碼的數據,如何修復相對來說就會有些困難。下一節我們詳細介紹具體方法。
如何修復已經編碼損壞的數據
在介紹正確方法前,我們先科普一下那些網上流傳的所謂的“正確方法”可能會造成的嚴重後果。
錯誤方法一
無論從語法還是字面意思來看:ALTER TABLE ... CHARSET=xxx 無疑是最像包治亂碼的良藥了!而事實上,他對於你已經損壞的數據一點幫助也沒有,甚至連已經該表已經創建列的默認字符集都無法改變。我們看下面這個例子
master [localhost] {msandbox} (test) > show create table charset_test;
+--------------+--------------------------------+
| Table | Create Table |
+--------------+--------------------------------+
| charset_test | CREATE TABLE `charset_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`char_col` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=latin1 |
+--------------+--------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > alter table charset_test charset=gbk;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
master [localhost] {msandbox} (test) > show create table charset_test;
+--------------+--------------------------------+
| Table | Create Table |
+--------------+--------------------------------+
| charset_test | CREATE TABLE `charset_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`char_col` varchar(50) CHARACTER SET latin1 DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=gbk |
+--------------+--------------------------------+
1 row in set (0.00 sec)
可見該語法緊緊修改了表的默認字符集,即只對以後創建的列的默認字符集產生影響,而對已經存在的列和數據沒有變化。
錯誤方法二
ALTER TABLE … CONVERT TO CHARACTER SET … 的相較於方法一來說殺傷力更大,因為從 官方文檔的解釋他的作用就是用於對一個表的數據進行編碼轉換。下面是文檔的一小段摘錄:
To change the table default character set and all character columns (CHAR, VARCHAR, TEXT) to a new character set, use a statement like this:
ALTER TABLE tbl_name CONVERT TO CHARACTER SET charset_name [COLLATE collation_name];
而實際上,這句語法只適用於當前並沒有亂碼,並且不是通過錯進錯出的方法保存的表。。而對於已經因為錯進錯出而產生編碼錯誤的表,則會帶來更糟的結果。
我們用一個實際例子來解釋下,這句SQL實際做了什麼和他會造成的結果。假設我們有一張編碼是latin1的表,且之前通過錯進錯出存入了UTF-8的數據,但是因為通過terminal仍然能夠正常顯示。即上文錯進錯出章節中舉例的情況。一段時間使用後我們發現了這個錯誤,並打算把表的字符集編碼改成UTF-8並且不影響原有數據的正常顯示。這種情況下使用alter table convert to character set會有這樣的後果:
master [localhost] {msandbox} (test) > create table charset_test_latin1 (id int primary key auto_increment, char_col varchar(50)) charset = latin1;
Query OK, 0 rows affected (0.01 sec)
master [localhost] {msandbox} (test) > set names latin1;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > insert into charset_test_latin1 (char_col) values ('這是中文');
Query OK, 1 row affected (0.01 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col,char_length(char_col) from charset_test_latin1;
+----+--------------------------+--------------+-----------------------+
| id | hex(char_col) | char_col | char_length(char_col) |
+----+--------------------------+--------------+-----------------------+
| 1 | E8BF99E698AFE4B8ADE69687 | 這是中文 | 12 |
+----+--------------------------+--------------+-----------------------+
1 row in set (0.01 sec)
master [localhost] {msandbox} (test) > alter table charset_test_latin1 convert to character set utf8;
Query OK, 1 row affected (0.04 sec)
Records: 1 Duplicates: 0 Warnings: 0
master [localhost] {msandbox} (test) > set names utf8;
Query OK, 0 rows affected (0.00 sec)
master [localhost] {msandbox} (test) > select id,hex(char_col),char_col,char_length(char_col) from charset_test_latin1;
+----+--------------------------------------------------------+-----------------------------+-----------------------+
| id | hex(char_col) | char_col | char_length(char_col) |
+----+--------------------------------------------------------+-----------------------------+-----------------------+
| 1 | C3A8C2BFE284A2C3A6CB9CC2AFC3A4C2B8C2ADC3A6E28093E280A1 | è????ˉ??-?–? | 12 |
+----+--------------------------------------------------------+-----------------------------+-----------------------+
1 row in set (0.00 sec)
從這個例子我們可以看出,對於已經錯進錯出的數據表,這個命令不但沒有起到“撥亂反正”的效果,還會徹底將數據糟蹋,連數據的二進制編碼都改變了。
正確的方法一 Dump & Reload
這個方法比較笨,但也比較好操作和理解。簡單的說分為以下三步:
還是用上面那個例子舉例,我們用UTF-8將數據“錯進”到latin1編碼的表中。現在需要將表編碼修改為UTF-8可以使用以下命令
shell> mysqldump -u root -p -d --skip-set-charset --default-character-set=utf8 test charset_test_latin1 > data.sql #確保導出的文件用文本編輯器在UTF-8編碼下查看沒有亂碼 shell> mysql -uroot -p -e 'create table charset_test_latin1 (id int primary key auto_increment, char_col varchar(50)) charset = utf8' test shell> mysql -uroot -p --default-character-set=utf8 test < data.sql
正確的方法二 Convert to Binary & Convert Back
這種方法比較取巧,用的是將二進制數據作為中間數據的做法來實現的。由於,MySQL再將有編碼意義的數據流,轉換為無編碼意義的二進制數據的時候並不做實際的數據轉換。而從二進制數據准換為帶編碼的數據時,又會用目標編碼做一次編碼轉換校驗。通過這兩個特性就相當於在MySQL內部模擬了一次“錯出”,將亂碼“撥亂反正”了。
還是用上面那個例子舉例,我們用UTF-8將數據“錯進”到latin1編碼的表中。現在需要將表編碼修改為UTF-8可以使用以下命令
mysql> ALTER TABLE charset_test_latin1 MODIFY COLUMN char_col VARBINARY(50); mysql> ALTER TABLE charset_test_latin1 MODIFY COLUMN char_col varchar(50) character set utf8;