接著上一篇學習:http://www.jb51.net/article/70528.htm
七、MySQL數據庫Schema設計的性能優化
高效的模型設計
適度冗余-讓Query盡兩減少Join
大字段垂直分拆-summary表優化
大表水平分拆-基於類型的分拆優化
統計表-准實時優化
合適的數據類型
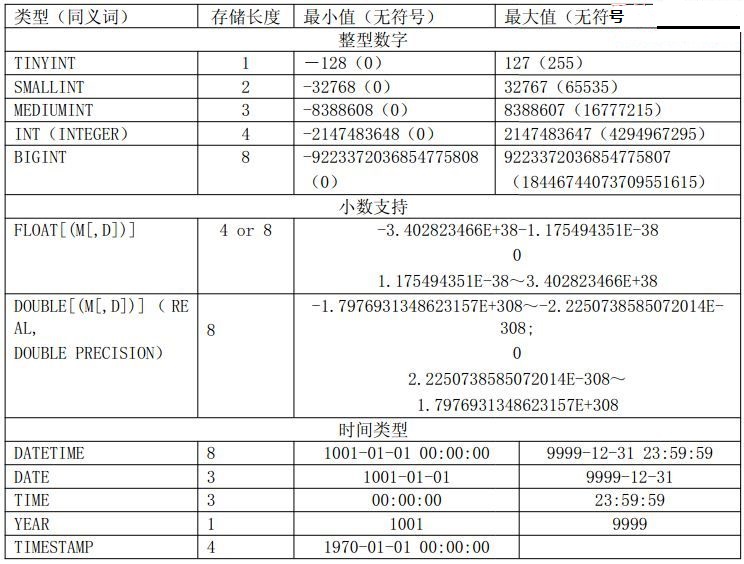
時間存儲格式總類並不是太多,我們常用的主要就是DATETIME,DATE和TIMESTAMP這三種了。從存儲空間來看TIMESTAMP最少,四個字節,而其他兩種數據類型都是八個字節,多了一倍。而TIMESTAMP的缺點在於他只能存儲從1970年之後的時間,而另外兩種時間類型可以存放最早從1001年開始的時間。如果有需要存放早於1970年之前的時間的需求,我們必須放棄TIMESTAMP類型,但是只要我們不需要使用1970年之前的時間,最好盡量使用TIMESTAMP來減少存儲空間的占用。
字符存儲類型

CHAR[(M)]類型屬於靜態長度類型,存放長度完全以字符數來計算,所以最終的存儲長度是基於字符集的,如latin1則最大存儲長度為255字節,但是如果使用gbk則最大存儲長度為510字節。CHAR類型的存儲特點是不管我們實際存放多長數據,在數據庫中都會存放M個字符,不夠的通過空格補上,M默認為1。雖然CHAR會通過空格補齊存放的空間,但是在訪問數據的時候,MySQL會忽略最後的所有空格,所以如果我們的實際數據中如果在最後確實需要空格,則不能使用CHAR類型來存放。
VARCHAR[(M)]屬於動態存儲長度類型,僅存占用實際存儲數據的長度。TINYTEXT,TEXT,MEDIUMTEXT和LONGTEXT這四種類型同屬於一種存儲方式,都是動態存儲長度類型,不同的僅僅是最大長度的限制。
事務優化
1. 髒讀:髒讀就是指當一個事務正在訪問數據,並且對數據進行了修改,而這種修改還沒有提交到數據庫中,這時,另外一個事務也訪問這個數據,然後使用了這個數據。
2. 不可重復讀:是指在一個事務內,多次讀同一數據。在這個事務還沒有結束時,另外一個事務也訪問該同一數據。那麼,在第一個事務中的兩次讀數據之間,由於第二個事務的修改,那麼第一個事務兩次讀到的的數據可能是不一樣的。這樣就發生了在一個事務內兩次讀到的數據是不一樣的,因此稱為是不可重復讀。
3. 幻讀:是指當事務不是獨立執行時發生的一種現象,例如第一個事務對一個表中的數據進行了修改,這種修改涉及到表中的全部數據行。同時,第二個事務也修改這個表中的數據,這種修改是向表中插入一行新數據。那麼,以後就會發生操作第一個事務的用戶發現表中還有沒有修改的數據行,就好象發生了幻覺一樣。
Innodb在事務隔離級別方面支持的信息如下:
1.READ UNCOMMITTED
常被成為Dirty Reads(髒讀),可以說是事務上的最低隔離級別:在普通的非鎖定模式下SELECT的執行使我們看到的數據可能並不是查詢發起時間點的數據,因而在這個隔離度下是非Consistent Reads(一致性讀);
2.READ COMMITTED
這一隔離級別下,不會出現DirtyRead,但是可能出現Non-RepeatableReads(不可重復讀)和PhantomReads(幻讀)。
3. REPEATABLE READ
REPEATABLE READ隔離級別是InnoDB默認的事務隔離級。在REPEATABLE READ隔離級別下,不會出現DirtyReads,也不會出現Non-Repeatable Read,但是仍然存在PhantomReads的可能性。
4.SERIALIZABLE
SERIALIZABLE隔離級別是標准事務隔離級別中的最高級別。設置為SERIALIZABLE隔離級別之後,在事務中的任何時候所看到的數據都是事務啟動時刻的狀態,不論在這期間有沒有其他事務已經修改了某些數據並提交。所以,SERIALIZABLE事務隔離級別下,PhantomReads也不會出現。
八、可擴展性設計之數據切分
數據的垂直切分
數據的垂直切分,也可以稱之為縱向切分。將數據庫想象成為由很多個一大塊一大塊的“數據塊”(表)組成,我們垂直的將這些“數據塊”切開,然後將他們分散到多台數據庫主機上面。這樣的切分方法就是一個垂直(縱向)的數據切分。
垂直切分的優點
◆數據庫的拆分簡單明了,拆分規則明確;
◆應用程序模塊清晰明確,整合容易;
◆數據維護方便易行,容易定位;
垂直切分的缺點
◆部分表關聯無法在數據庫級別完成,需要在程序中完成;
◆對於訪問極其頻繁且數據量超大的表仍然存在性能平靜,不一定能滿足要求;
◆事務處理相對更為復雜;
◆切分達到一定程度之後,擴展性會遇到限制;
◆過讀切分可能會帶來系統過渡復雜而難以維護。
數據的水平切分
數據的垂直切分基本上可以簡單的理解為按照表按照模塊來切分數據,而水平切分就不再是按照表或者是功能模塊來切分了。一般來說,簡單的水平切分主要是將某個訪問極其平凡的表再按照某個字段的某種規則來分散到多個表之中,每個表中包含一部分數據。
水平切分的優點
◆表關聯基本能夠在數據庫端全部完成;
◆不會存在某些超大型數據量和高負載的表遇到瓶頸的問題;
◆應用程序端整體架構改動相對較少;
◆事務處理相對簡單;
◆只要切分規則能夠定義好,基本上較難遇到擴展性限制;
水平切分的缺點
◆切分規則相對更為復雜,很難抽象出一個能夠滿足整個數據庫的切分規則;
◆後期數據的維護難度有所增加,人為手工定位數據更困難;
◆應用系統各模塊耦合度較高,可能會對後面數據的遷移拆分造成一定的困難。
數據切分與整合中可能存在的問題
1.引入分布式事務的問題
完全可以將一個跨多個數據庫的分布式事務分拆成多個僅處於單個數據庫上面的小事務,並通過應用程序來總控各個小事務。當然,這樣作的要求就是我們的俄應用程序必須要有足夠的健壯性,當然也會給應用程序帶來一些技術難度。
2.跨節點Join的問題
推薦通過應用程序來進行處理,先在驅動表所在的MySQLServer中取出相應的驅動結果集,然後根據驅動結果集再到被驅動表所在的MySQL Server中取出相應的數據。
3.跨節點合並排序分頁問題
從多個數據源並行的取數據,然後應用程序匯總處理。
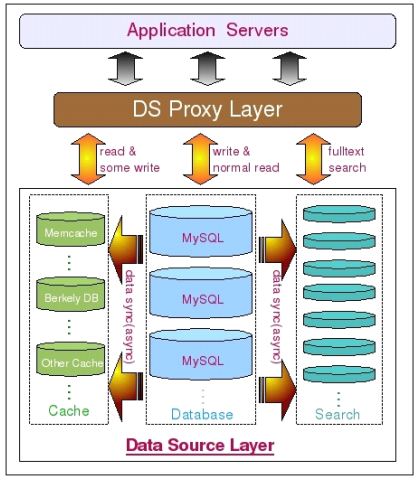
九、可擴展性設計之Cache與Search的利用
通過引入Cache(Redis、Memcached),減少數據庫的訪問,增加性能。
通過引入Search(Lucene、Solr、ElasticSearch),利用搜索引擎高效的全文索引和分詞算法,以及高效的數據檢索實現,來解決數據庫和傳統的Cache軟件完全無法解決的全文模糊搜索、分類統計查詢等功能。
以上就是本文的全部內容,希望大家可以喜歡。