昨晚收到客服MM電話,一用戶反饋數據庫響應非常慢,手機收到load異常報警,登上主機後發現大量sql執行非常慢,有的執行時間超過了10s
優化點一:
SELECT * FROM `sitevipdb`.`game_shares_buy_list` WHERE price>='2.00′ ORDER BY tran_id DESC LIMIT 10;
表結構為:
CREATE TABLE `game_shares_buy_list` ( `tran_id` int(10) unsigned NOT NULL AUTO_INCREMENT, `………..' PRIMARY KEY (`tran_id`), KEY `ind_username` (`username`) ) ENGINE=InnoDB AUTO_INCREMENT=3144200 DEFAULT CHARSET=utf8;
執行計劃:
[email protected] : sitevipdb 09:10:22> explain SELECT * FROM `sitevipdb`.`game_shares_buy_list` WHERE price>='2.00′ ORDER BY tran_id DESC LIMIT 10; +—-+————-+———————-+——-+—————+———+———+——+——+————-+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +—-+————-+———————-+——-+—————+———+———+——+——+————-+ | 1 | SIMPLE | game_shares_buy_list | index | NULL | PRIMARY | 4 | NULL | 10 | Using where | +—-+————-+———————-+——-+—————+———+———+——+——+————-+ 1 row in set (0.00 sec)
分析該sql的執行計劃,由於tran_id是表的主鍵,所以查詢根據主鍵降序順序掃描,這樣就可以不用排序,
然後在過濾條件price>2.00的記錄,看上去這個執行計劃貌似非常好,如果查詢掃描到了滿足條件的10條記錄,就會停止掃描;
但是這裡有個問題,如果表中有大量的記錄是不符合2.00的,意味查詢就需要掃描非常多的記錄,才能找到符合條件的10條:
[email protected] : sitevipdb 09:17:23> select price,count(*) as cnt from `game_shares_buy_list` group by price order by cnt desc limit 10; +——-+——-+ | price | cnt | +——-+——-+ | 1.75 | 39101 | | 1.68 | 38477 | | 1.71 | 34869 | | 1.66 | 34849 | | 1.72 | 34718 | | 1.70 | 33996 | | 1.76 | 32527 | | 1.69 | 27189 | | 1.61 | 25694 | | 1.25 | 25450 |
可以看到表中有大量的記錄不是2.00的,所以這個時候不能在根據主鍵順序掃描,在過濾記錄;
那麼是否需要在price建立一個索引:
[email protected] : sitevipdb 09:09:01> select count(*) from `game_shares_buy_list` where price>'2′; +———-+ | count(*) | +———-+ | 4087 | +———-+ [email protected] : sitevipdb 09:17:31> select count(*) from `game_shares_buy_list` ; +———-+ | count(*) | +———-+ | 1572100 |
從上面price的數據分布可以看出,price的分布相對還是比較集中的,如果在price建立索引,mysql也有可能認為由於需要回表的記錄過多,
同時需要額外的排序,而不選擇在price上的索引:
[email protected] : sitevipdb 09:24:53> alter table game_shares_buy_list add index ind_game_shares_buy_list_price(price); Query OK, 0 rows affected (5.79 sec)

可以看到優化器雖然注意到了我們新加的索引,但是最終還是選擇了primary來掃描;
所以這個時候我們加上去的索引沒有產生效果,數據庫負載依然很高,如果強制走price上的索引,效果會這樣:
[email protected] : sitevipdb 09:35:38> SELECT * FROM `sitevipdb`.`game_shares_buy_list` WHERE price>='2.0′ ORDER BY tran_id DESC LIMIT 10; 。。。。。 10 rows in set (7.06 sec) [email protected] : sitevipdb 09:36:00> SELECT * FROM `sitevipdb`.`game_shares_buy_list` force index(ind_game_shares_buy_list_price) WHERE price>='2.0′ ORDER BY tran_id DESC LIMIT 10; 。。。。 10 rows in set (1.01 sec)
可以看到如果強制走索引,時間已經明顯下降了,但是還是有些慢,能不能在快一點?其實我們需要掃描的記錄只有10條,但查詢在取得這10條記錄的時候需要掃描大量無效的記錄
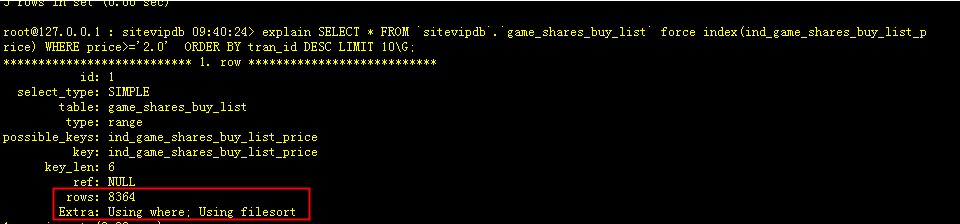
怎麼降低這個數據:其實只要改寫一下sql就可以,我們先從索引中得到滿足條件的10個id,在回表進行關聯:
[email protected] : sitevipdb 09:44:45> select * from game_shares_buy_list t1, -> ( SELECT tran_id FROM sitevipdb.game_shares_buy_list WHERE price>='2.0′ ORDER BY tran_id DESC LIMIT 10) t2 -> where t1.tran_id=t2.tran_id; 10 rows in set (0.00 sec)
可以看到執行時間已經不在秒級別了,和客戶電話溝通後,很願意這樣改寫sql。
—這裡看到是order by tran_id是要額外排序的,索引也可以這樣來建立消除排序(tran_id,price)這樣可以消除排序,同時可以利用order by desc/asc +limit M,N的優化。
優化點二:
CREATE TABLE `game_session` ( `session_id` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT , `session_expires` int(10) unsigned NOT NULL DEFAULT '0′, `client_ip` varchar(16) DEFAULT NULL, `session_data` text, ……………………. PRIMARY KEY (`session_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
查詢為select `session_data`, `session_expires` from `game_session` where session_id='xxx'出現大量等待情況
同時該表的insert,也有等待的現象;
可以看到這個表結構設計是有些問題的,咨詢了客戶後,可以改為下面結構:
CREATE TABLE `game_session` ( id int auto_increment, `session_id` varchar(30) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT , `session_expires` int(10) unsigned NOT NULL DEFAULT '0′, `client_ip` varchar(16) DEFAULT NULL, `session_data` varchar(200), PRIMARY KEY (id), key ind_session_id(session_id,session_data, session_expires) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
小結: