繼續做以下的前期准備工作:
新建一個測試數據庫TestDB;
create database TestDB;
創建測試表table1和table2;
CREATE TABLE table1
(
customer_id VARCHAR(10) NOT NULL,
city VARCHAR(10) NOT NULL,
PRIMARY KEY(customer_id)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
CREATE TABLE table2
(
order_id INT NOT NULL auto_increment,
customer_id VARCHAR(10),
PRIMARY KEY(order_id)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
插入測試數據;
INSERT INTO table1(customer_id,city) VALUES('163','hangzhou');
INSERT INTO table1(customer_id,city) VALUES('9you','shanghai');
INSERT INTO table1(customer_id,city) VALUES('tx','hangzhou');
INSERT INTO table1(customer_id,city) VALUES('baidu','hangzhou');
INSERT INTO table2(customer_id) VALUES('163');
INSERT INTO table2(customer_id) VALUES('163');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('tx');
准備工作做完以後,table1和table2看起來應該像下面這樣:
mysql> select * from table1; +-------------+----------+ | customer_id | city | +-------------+----------+ | 163 | hangzhou | | 9you | shanghai | | baidu | hangzhou | | tx | hangzhou | +-------------+----------+ 4 rows in set (0.00 sec) mysql> select * from table2; +----------+-------------+ | order_id | customer_id | +----------+-------------+ | 1 | 163 | | 2 | 163 | | 3 | 9you | | 4 | 9you | | 5 | 9you | | 6 | tx | +----------+-------------+ 7 rows in set (0.00 sec)
准備工作做的差不多了,開始今天的總結吧。
一個問題
現在需要查詢所有杭州用戶的所有訂單號,這個SQL語句怎麼寫?首先,你可以這麼寫:
select table2.customer_id, table2.order_id from table2 join table1 on table1.customer_id=table2.customer_id where table1.city='hangzhou';
能實現我們需要的結果。但是,我們也可以這麼寫:
select customer_id, order_id from table2 where customer_id in (select customer_id from table1 where city='hangzhou');
呃?在()括號中的的select語句是什麼?問題來了,這到底是什麼語法,怎麼也可以完成任務,那麼這篇博文就圍繞著這個問題開始展開。
啥是子查詢
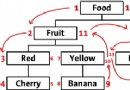
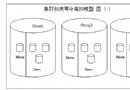
簡單的說,子查詢就是:

如上圖所示,子查詢,有叫內部查詢,相對於內部查詢,包含內部查詢的就稱為外部查詢。子查詢可以包含普通select可以包括的任何子句,比如:distinct、group by、order by、limit、join和union等;但是對應的外部查詢必須是以下語句之一:select、insert、update、delete、set或者do。

我們可以在where和having子句中使用子查詢,將子查詢得到的結果作為判斷的條件。
使用比較進行子查詢
一個子查詢會返回一個標量(就一個值)、一個行、一個列或一個表,這些子查詢稱之為標量、行、列和表子查詢。
當一個子查詢返回一個標量時,我們就可以在where或者having子句中使用比較符與子查詢得到的結果進行直接判斷。比如,我現在要得到比用戶tx訂單數多的customer_id、city和訂單數,這個sql語句怎麼寫。
先來說說,我寫sql的一般步驟:
最終,我會寫出一下的sql語句:
select table1.customer_id,city,count(order_id)
from table1 join table2
on table1.customer_id=table2.customer_id
where table1.customer_id <> 'tx'
group by customer_id
having count(order_id) >
(select count(order_id)
from table2
where customer_id='tx'
group by customer_id);
上面的查詢中使用了子查詢,外部查詢與子查詢得到的結果進行了比較判斷。如果子查詢返回一個標量值(就一個值),那麼外部查詢就可以使用:=、>、<、>=、<=和<>符號進行比較判斷;如果子查詢返回的不是一個標量值,而外部查詢使用了比較符和子查詢的結果進行了比較,那麼就會拋出異常。
使用ANY進行子查詢
上面使用比較符進行子查詢,規定了子查詢只能返回一個標量值;但是,如果子查詢返回的是一個集合,怎麼辦?
沒問題,我們可以使用:any、in、some或者all來和子查詢的返回結果進行條件判斷。這裡先總結使用any進行子查詢。
any關鍵詞必須與上面總結的比較操作符一起使用;any關鍵詞的意思是“對於子查詢返回的列中的任何一個數值,如果比較結果為TRUE,就返回TRUE”。
好比“10 >any(11, 20, 2, 30)”,由於10>2,所以,該該判斷會返回TRUE;只要10與集合中的任意一個進行比較,得到TRUE時,就會返回TRUE。
比如,我現在要查詢比customer_id為tx或者9you的訂單數量多的用戶的id、城市和訂單數量。
我可以得到以下的sql語句來完成需求。
select table1.customer_id,city,count(order_id) from table1 join table2 on table1.customer_id=table2.customer_id where table1.customer_id<>'tx' and table1.customer_id<>'9you' group by customer_id having count(order_id) > any ( select count(order_id) from table2 where customer_id='tx' or customer_id='9you' group by customer_id);
any的意思比較好明白,直譯就是任意一個,只要條件滿足任意的一個,就返回TRUE。
使用IN進行子查詢
使用in進行子查詢,這個我們在日常寫sql的時候是經常遇到的。in的意思就是指定的一個值是否在這個集合中,如何在就返回TRUE;否則就返回FALSE了。
in是“=any”的別名,在使用“=any”的地方,我們都可以使用“in”來進行替換。這裡就不舉例了,盡情的發揮想象,自行發揮吧。
有了in,肯定就有了not in;not in並不是和<>any是同樣的意思,not in和<>all是一個意思,關於all,下面馬上就要總結了。
使用SOME進行子查詢
some是any的別名,用的比較少。只需要理解any的意思就好了,這裡就不做過多的總結。具體請參考上面的any部分的總結。
使用ALL進行子查詢
all必須與比較操作符一起使用。all的意思是“對於子查詢返回的列中的所有值,如果比較結果為TRUE,則返回TRUE”。
好比“10 >all(2, 4, 5, 1)”,由於10大於集合中的所有值,所以這條判斷就返回TRUE;而如果為“10 >all(20, 3, 2, 1, 4)”,這樣的話,由於10小於20,所以該判斷就會返回FALSE。
<>all的同義詞是not in,表示不等於集合中的所有值,這個很容易和<>any搞混,平時多留點心就好了。
標量子查詢
根據子查詢返回值的數量,將子查詢可以分為標量子查詢和多值子查詢。在使用比較符進行子查詢時,就要求必須是標量子查詢;如果是多值子查詢時,使用比較符,就會拋出異常。
多值子查詢
與標量子查詢對應的就是多值子查詢了,多值子查詢會返回一列、一行或者一個表,它們組成一個集合。我們一般使用的any、in、all和some等詞,將外部查詢與子查詢的結果進行判斷。如果將any、in、all和some等詞與標量子查詢,就會得到空的結果。
獨立子查詢
獨立子查詢是不依賴外部查詢而運行的子查詢。什麼叫依賴外部查詢?先看下面兩個sql語句。
sql語句1:獲得所有hangzhou顧客的訂單號。
select order_id
from table2
where customer_id in
(select customer_id
from table1
where city='hangzhou');
sql語句2:獲得城市為hangzhou,並且存在訂單的用戶。
select *
from table1
where city='hangzhou' and exists
(select *
from table2
where table1.customer_id=table2.customer_id);
上面的兩條sql語句,雖然例子舉的有點不是很恰當,但是足以說明這裡的問題了。
對於sql語句1,我們將子查詢單獨復制出來,也是可以單獨執行的,就是子查詢與外部查詢沒有任何關系。
對於sql語句2,我們將子查詢單獨復制出來,就無法單獨執行了,由於sql語句2的子查詢依賴外部查詢的某些字段,這就導致子查詢就依賴外部查詢,就產生了相關性。
對於子查詢,很多時候都會考慮到效率的問題。當我們執行一個select語句時,可以加上explain關鍵字,用來查看查詢類型,查詢時使用的索引以及其它等等信息。比如這麼用:
explain select order_id
from table2
where customer_id in
(select customer_id
from table1
where city='hangzhou');
使用獨立子查詢,如果子查詢部分對集合的最大遍歷次數為n,外部查詢的最大遍歷次數為m時,我們可以記為:O(m+n)。而如果使用相關子查詢,它的遍歷次數可能會達到O(m+m*n)。可以看到,效率就會成倍的下降;所以,大伙在使用子查詢時,一定要考慮到子查詢的相關性。
關於explain的更多解釋,請參考這裡。
相關子查詢
相關子查詢是指引用了外部查詢列的子查詢,即子查詢會對外部查詢的每行進行一次計算。但是在MySQL的內部,會進行動態優化,會隨著情況的不同會有所不同。使用相關子查詢是最容易出現性能的地方。而關於sql語句的優化,這又是一個非常大的話題了,只能通過實際的經驗積累,才能更好的去理解如何進行優化。
關於sql的性能,我這裡不能說什麼,如果只是閱讀其它人的文章來考慮性能問題,其實是沒有任何感覺的,我們需要實際的項目中才能更好的理解。
EXISTS謂詞
EXISTS是一個非常牛叉的謂詞,它允許數據庫高效地檢查指定查詢是否產生某些行。根據子查詢是否返回行,該謂詞返回TRUE或FALSE。與其它謂詞和邏輯表達式不同的是,無論輸入子查詢是否返回行,EXISTS都不會返回UNKNOWN,對於EXISTS來說,UNKNOWN就是FALSE。還是上面的語句,獲得城市為hangzhou,並且存在訂單的用戶。
select *
from table1
where city='hangzhou' and exists
(select *
from table2
where table1.customer_id=table2.customer_id);
使用explain查看一下,就會得到以下內容:

我們可以很明顯的看到,存在一個相關的子查詢(DEPENDENT SUBQUERY)。可以看到EXISTS和IN是非常相似的,那麼它們之間的區別是什麼呢?
關於IN和EXISTS的主要區別在於三值邏輯的判斷上。EXISTS總是返回TRUE或FALSE,而對於IN,除了TRUE、FALSE值外,還有可能對NULL值返回UNKNOWN。但是在過濾器中,UNKNOWN的處理方式與FALSE相同,因此使用IN與使用EXISTS一樣,SQL優化器會選擇相同的執行計劃。
說到了IN和EXISTS幾乎是一樣的,但是,就不得不說到NOT IN和NOT EXISTS,對於輸入列表中包含NULL值時,NOT EXISTS和NOT IN之間的差異就表現的非常大了。輸入列表包含NULL值時,IN總是返回TRUE和UNKNOWN,因此NOT IN就會得到NOT TRUE和NOT UNKNOWN,即FALSE和UNKNOWN。
mysql> select 'c' NOT IN ('a', 'b', NULL)\G;
執行一下上述代碼,看看結果。你就會感到驚訝。
派生表
上面也說到了,在子查詢返回的值中,也可能返回一個表,如果將子查詢返回的虛擬表再次作為FROM子句的輸入時,這就子查詢的虛擬表就成為了一個派生表。語法結構如下:
FROM (subquery expression) AS derived_table_alias
由於派生表是完全的虛擬表,並沒有也不可能被物理地具體化。
總結
總算總結的差不多了,當然了子查詢的東西還是有很多的,不可能一篇文章就能總結的完的,這裡只是把一些基本的概念,常用的知識點進行了總結,關於將子查詢使用到update、delete和insert語句中的用法,我這裡並沒有涉及,大體上都是大同小異的。知識這個東西,展開了,就沒有頭了,還是需要適可而止,適當的進行深度的挖掘,但是深度最好不要超過2,關於這個2如何定義,自行把握。好了,這篇文章就到此為止了,我們下一篇見。